 電子發燒友App
電子發燒友App


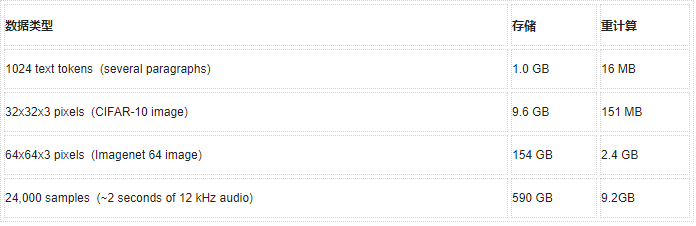
谷歌在2017年發布Transformer架構的論文時,論文的標題是:Attention Is All You Need。重點說明了這個架構是基于注意力機制的。
一
什么是注意力機制
在深入了解Transformer的架構原理之前,我們首先要了解下,什么是注意力機制。 人類的大腦對于信息的獲取也存在注意力機制,下面我舉幾個簡單的例子:

從上面的圖片中,我們可能更容易關注,顏色更深的字、字號更大的字,另外像“震驚”這種吸引人眼球的文案也非常容易吸引人的關注。 我們知道在海量的互聯網信息中,往往那些起著“標題黨”的文章更能吸引人的注意,從而達到吸引流量的目的,這是一種簡單粗暴的方式。另外在大量的同質化圖片中,如果有一張圖片它的色彩、構圖等都別出一格,那你也會一眼就能注意到它,這也是一種簡單的注意力機制。 假設有以下這兩段文字,需要翻譯成英文:
1、我在得物上買了最新款的蘋果,體驗非常好。 2、我在得物上買了阿克蘇的蘋果,口感非常好。 我們人類能很快注意到第一段文字中的蘋果是指蘋果手機,那么模型在翻譯時就需要把他翻譯成iPhone,而第二段文字中的蘋果就是指的蘋果這種水果,模型翻譯時就需要將他翻譯成apple。 人類的大腦為什么能分辨出這兩個蘋果是指代的不同的意思呢?原因就是人類的大腦能從上下文中獲取到關鍵信息,從而幫助我們理解每種蘋果是什么意思。 其實說到這里,我們就已經揭開了Transformer架構的核心,即注意力機制的原理:從文本的上下文中找到需要注意的關鍵信息,幫助模型理解每個字的正確含義。但是實際的實現方式又是非常復雜的。 接下來讓我們一起深入理解下Transformer的架構原理。
二
Transformer架構設計
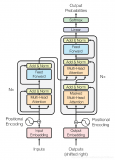
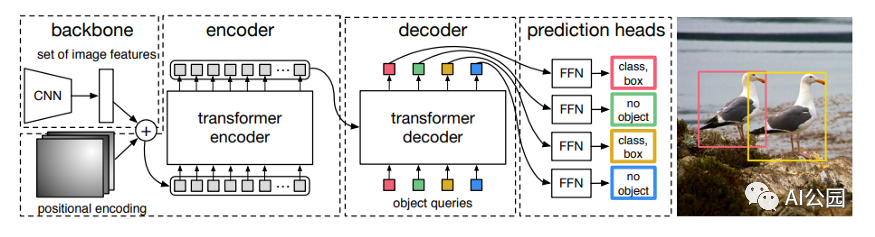
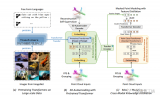
Transformer的架構設計如下圖所示:
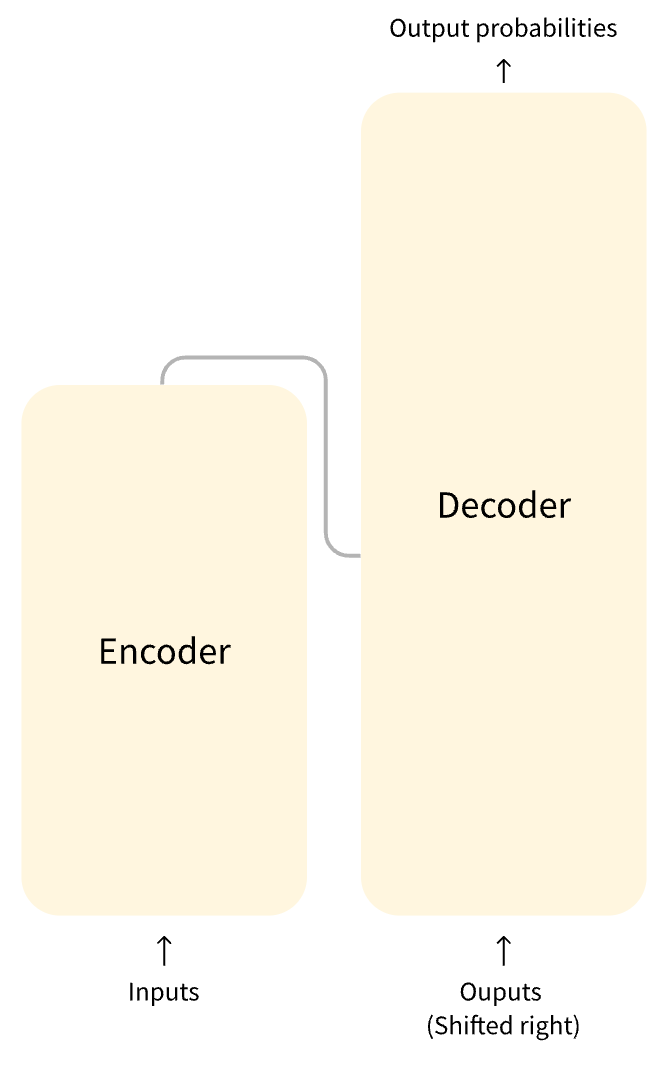
?
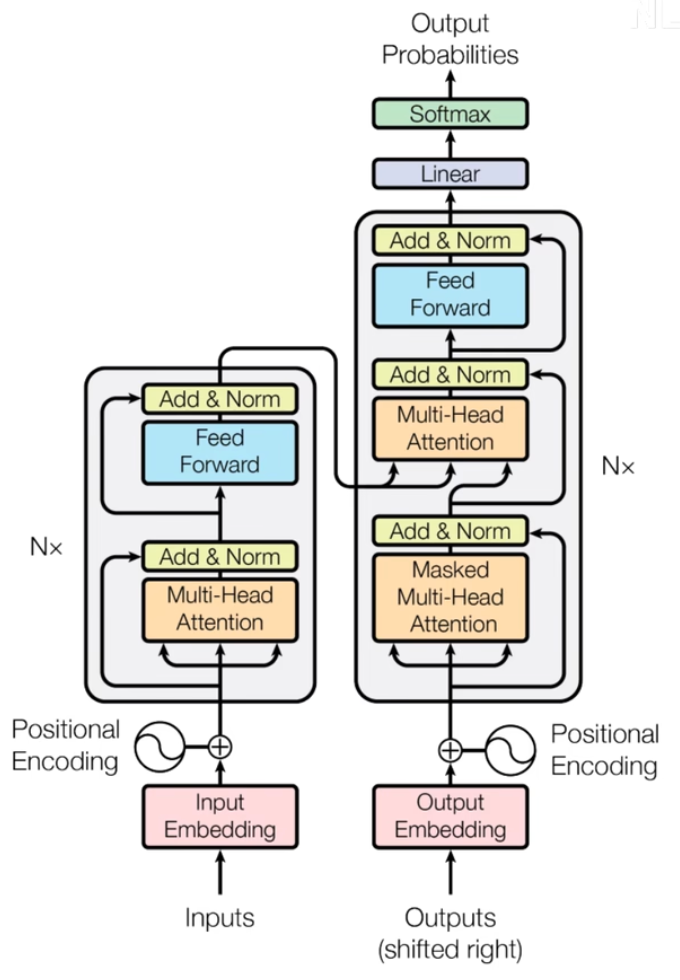
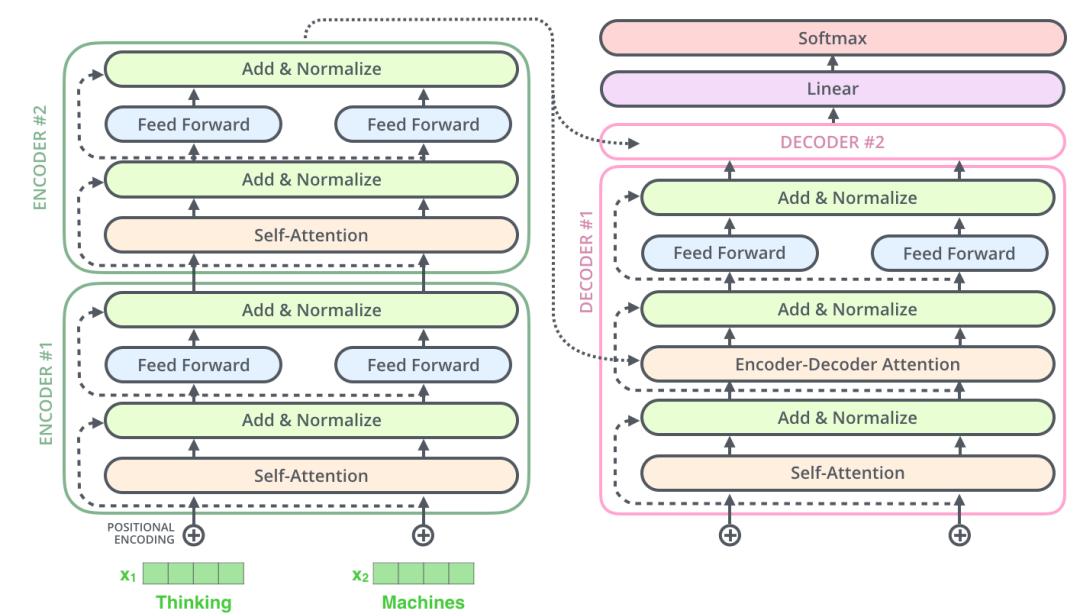
Transformer架構中有兩個核心的組件Encoder和Decoder,左邊的這張圖是Transformer架構的一個簡單表示形式,右邊的這張圖是Transformer架構的一個完整表示形式,其中有一個重要的Multi-Head Attention組件,稱為注意力層。 Transformer架構中的兩個核心的組件Encoder和Decoder,每個組件都可以單獨使用,具體取決于任務的類型:
Encoder-only models: 適用于需要理解輸入的任務,如句子分類和命名實體識別。
Decoder-only models: 適用于生成任務,如文本生成。
Encoder-decoder models 或者 sequence-to-sequence models: 適用于需要根據輸入進行生成的任務,如翻譯或摘要。
三
理解Transformer中的Token
因為模型是無法直接處理文本的,只能處理數字,就跟ASCII碼表、Unicode碼表一樣,計算機在處理文字時也是先將文字轉成對應的字碼,然后為每個字碼編寫一個對應的數字記錄在表中,最后再處理。
將文本拆分成token
所以模型在處理文本時,第一步就是先將文本轉換成對應的字碼,也就是大模型中的token,但是怎么將文本轉換成對應的token卻是一個復雜的問題,在Transformers(HuggingFace提供的一個對Transformer架構的具體實現的組件庫)中提供了專門的Tokenizer分詞器來實現這個任務,一般來說有以下幾種方式: ? ?
基于單詞的分詞器
第一種標記器是基于單詞的(word-based)。它通常很容易設置和使用,只需幾條規則,并且通常會產生不錯的結果。例如,在下圖中,目標是將原始文本拆分為單詞,并為每個單詞找到一個映射的數字表達: 將文本拆分成單詞,也有很多不同的方式,比如通過空格來拆分、通過標點符號來拆分。
如果我們想使用基于單詞的標記器(tokenizer)完全覆蓋一種語言,我們需要為語言中的每個單詞都創建一個數字標記,這將生成大量的標記。除此之外,還可能存在一些無法覆蓋的單詞,因為單詞可能存在很多的變種情況,比如:dogs是dog的變種,running是run的變種。如果我們的標識符中沒有覆蓋所有的單詞,那么當出現一個未覆蓋的單詞時,標記器將無法準確知道該單詞的數字標記是多少,進而只能標記為未知:UNK。如果在文本轉換的過程中有大量的文本被標記為UNK,那么也將影響后續模型推理。 ? ?
基于字符的標記器
為了減少未知標記數量的一種方法是使用更深一層的標記器(tokenizer),即基于字符的(character-based)標記器(tokenizer)。 基于字符的標記器(tokenizer)將文本拆分為字符,而不是單詞。這有兩個主要好處:
詞匯量要小得多。
未知的標記(token)要少得多,因為每個單詞都可以從字符構建。
但是這里也出現了一些關于空格和標點符號的問題:

這種方法也不是完美的。由于現在表示是基于字符而不是單詞,因此人們可能會爭辯說,從直覺上講,它的意義不大:每個字符本身并沒有多大意義,而單詞就是這種情況。然而,這又因語言而異;例如,在中文中,每個字符比拉丁語言中的字符包含更多的信息。 另一件要考慮的事情是,我們的模型最終會處理大量的詞符(token):雖然使用基于單詞的標記器(tokenizer),單詞只會是單個標記,但當轉換為字符時,它很容易變成 10 個或更多的詞符(token)。 為了兩全其美,我們可以使用結合這兩種方法的第三種技術:子詞標記化(subword tokenization)。 ? ?
基于子詞的標記器
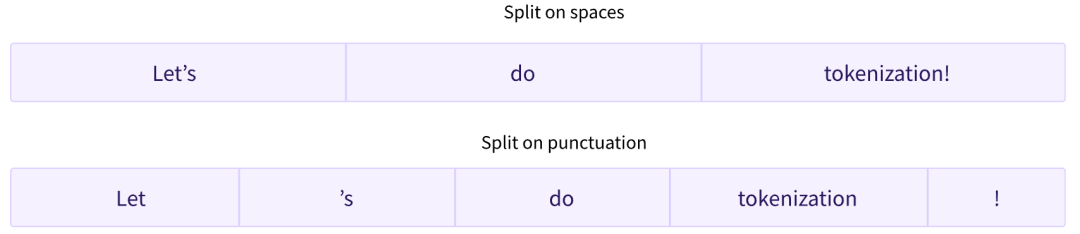
子詞分詞算法依賴于這樣一個原則,即不應將常用詞拆分為更小的子詞,而應將稀有詞分解為有意義的子詞。 例如,“annoyingly”可能被認為是一個罕見的詞,可以分解為“annoying”和“ly”。這兩者都可能作為獨立的子詞出現得更頻繁,同時“annoyingly”的含義由“annoying”和“ly”的復合含義保持。 下面這張圖,展示了基于子詞標記化算法,如何標記序列“Let’s do tokenization!”:

這些子詞最終提供了很多語義含義:例如,在上面的示例中,“tokenization”被拆分為“token”和“ization”,這兩個具有語義意義同時節省空間的詞符(token)(只需要兩個標記(token)代表一個長詞)。這使我們能夠對較小的詞匯表進行相對較好的覆蓋,并且幾乎沒有未知的標記。 ?
向量、矩陣、張量
了解完token之后,我們還要了解下向量、矩陣和張量的概念,因為他們是大模型計算中基礎的數據結構。 ? ?
向量(Vector)
向量是一個有序的數字列表,通常用來表示空間中的點或者方向。在數學中,向量可以表示為一個列向量或行向量,具體取決于上下文。例如,一個三維空間中的點可以用一個三維列向量表示,如?v=[x,y,z]T,其中 x,y,z 是實數。
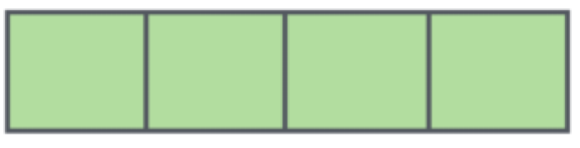
? ?
矩陣(Matrix)
矩陣是一個二維數組,由行和列組成,可以被視為向量的一個特例。矩陣在數學中用于表示線性變換、系統方程的系數等。矩陣的維度通常表示為 m×n,其中 m 是行數,n 是列數。例如,一個 4×3 的矩陣有四行三列。

? ?
張量(Tensor)
張量是一個多維數組,可以看作是向量和矩陣的更底層的表示,向量和矩陣是張量的特例。例如向量是一維的張量,矩陣是二維的張量。張量可以有任意數量的維度,而不僅僅是一維(向量)或二維(矩陣)。張量在物理學中用來表示多維空間中的物理量,如應力、應變等。在深度學習中,張量用于表示數據和模型參數的多維結構。

將token轉換成向量
在獲取到token之后,再將每個token映射為一個數字,當然了,Transformer能夠處理的數據,并不是簡單的1/2/3這樣的數字,而是一種向量數據,如下圖所示:
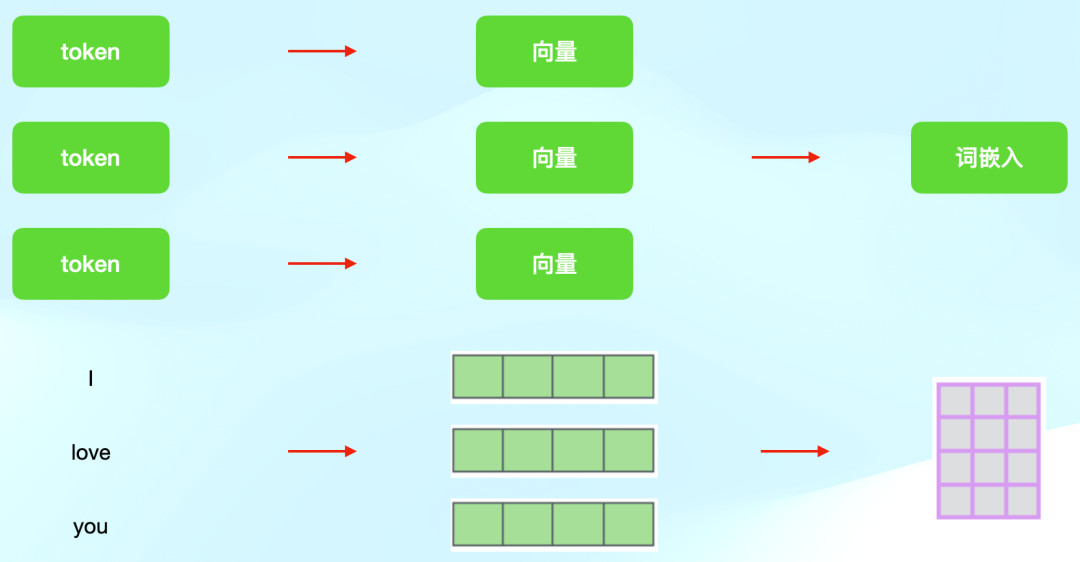
將向量轉換成嵌入
得到向量之后,再將向量轉換成詞嵌入,也就是我們所熟知的embeddings。 在Transformer模型中,編碼器接收的詞嵌入(embeddings)可以被視為矩陣。這些詞嵌入是將輸入序列中的每個token映射到一個固定維度的向量空間中的結果。每個詞嵌入都是一個向量,而這些向量按順序排列形成一個矩陣。 具體來說,如果你有一個句子或序列,其中包含了N個token,每個token都被映射到一個d維的向量空間中,那么你將得到一個N×d的矩陣,其中N是序列的長度,d是嵌入向量的維度。這個矩陣就是詞嵌入矩陣,它是一個二維張量,因為它具有兩個維度:序列長度(時間步長)和嵌入維度。 在Transformer模型的編碼器中,這個嵌入矩陣首先會通過一個線性層(可選)進行處理,然后添加位置編碼(positional encoding),最后輸入到自注意力(self-attention)和前饋網絡(feed-forward network)等組件中進行進一步的處理,具體細節我接下來會進行詳細解釋。 總結來說,編碼器接收的詞嵌入是一個矩陣,這個矩陣可以被視為一個二維張量,其中包含了序列中每個詞的d維向量表示。
四
理解Transformer的編解碼器
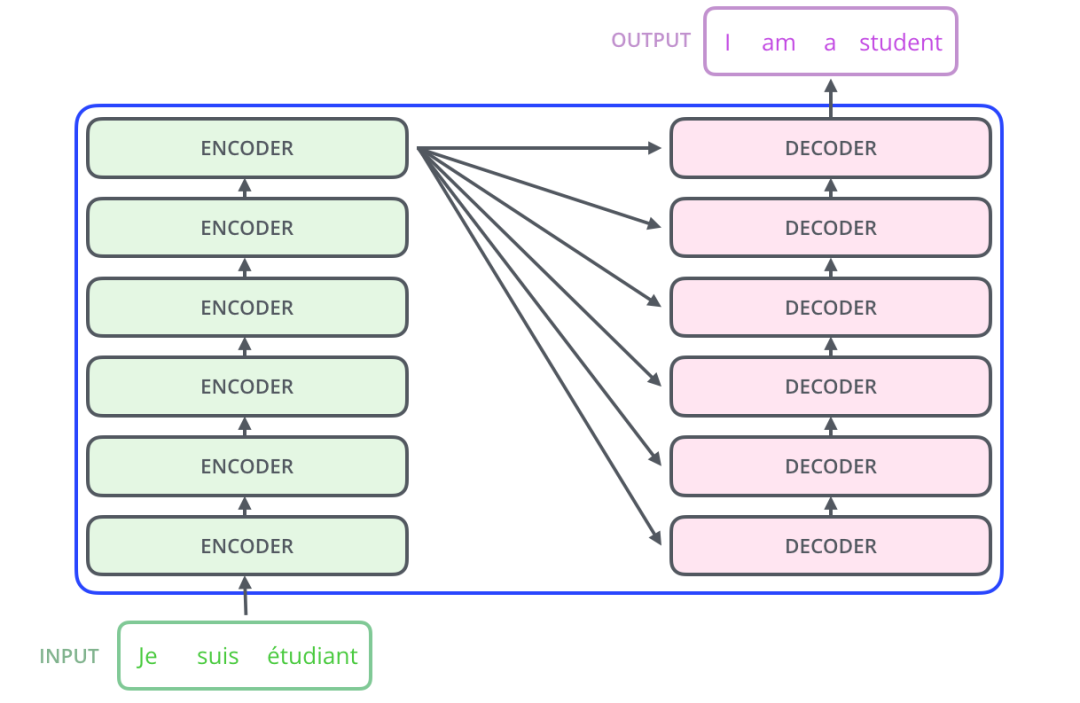
下面讓我們以文本翻譯來深入理解Transformer中的Encoder和Decoder是怎樣工作的,假設我們有以下這個翻譯任務,輸入是一段法文,輸出是英文。 整個流程是Transformer將輸入的input,經過Encoders處理后,將結果投遞到Decoders中處理,最后輸出翻譯后的結果。
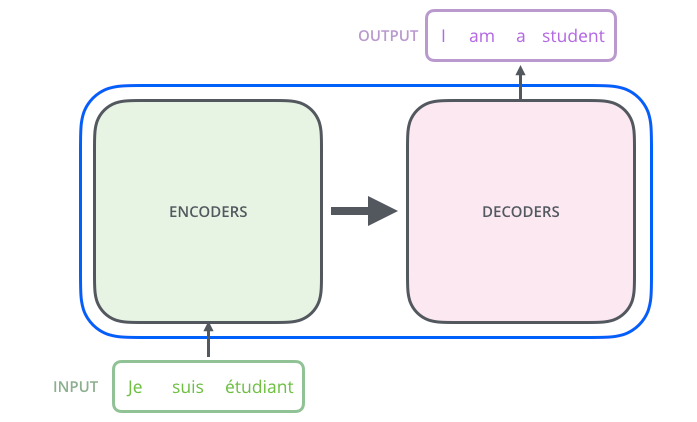
但是實際在Transformer的內部,是由多個獨立的Encoder和Decoder組成的,這里我們使用6個做驗證,當然我們也可以使用其他數量的Encoder和Decoder,筆者懷疑6個是經過驗證后相對折中的一個值。
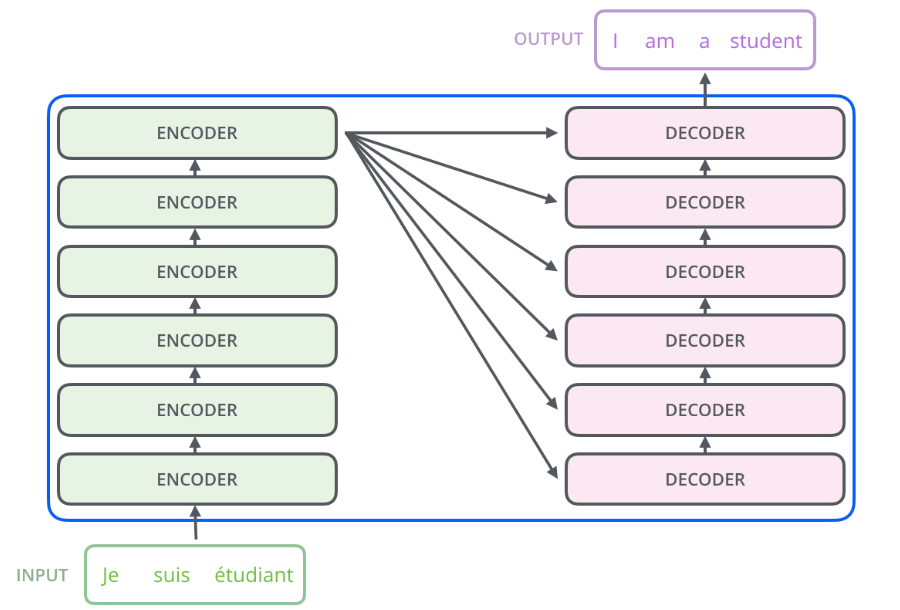
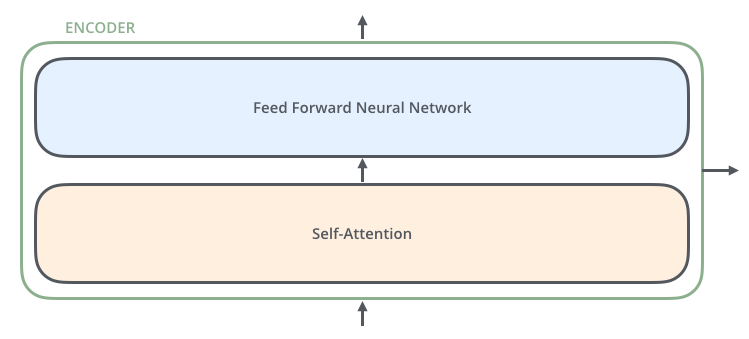
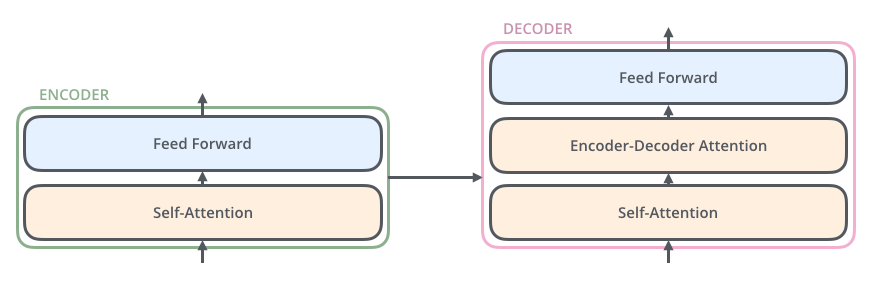
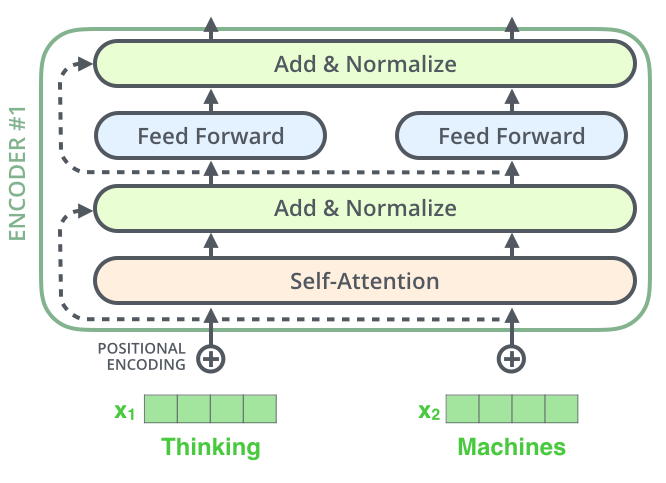
這6個Encoder和Decoder在結構上都是相同的,但是Encoder和Decoder的內部還有更細分的組件: 每一層的Encoder由2個子組件組成:自注意力層和前饋網絡層,其中文本的輸入會先流入自注意力層,正是由于自注意力層的存在,幫助Encoder在對特定文本進行遍歷時,能夠讓Encoder觀察到文本中的其他單詞。然后自注意力層的結果被輸出到前饋網絡層。
每一層的Decoder由3個子組件組成:除了自注意力層、前饋網絡層,在兩者之間還有一個編解碼注意力層,這個組件主要是幫助Decoder專注于輸入句子的相關部分。
五
理解Token在編碼器中的流轉
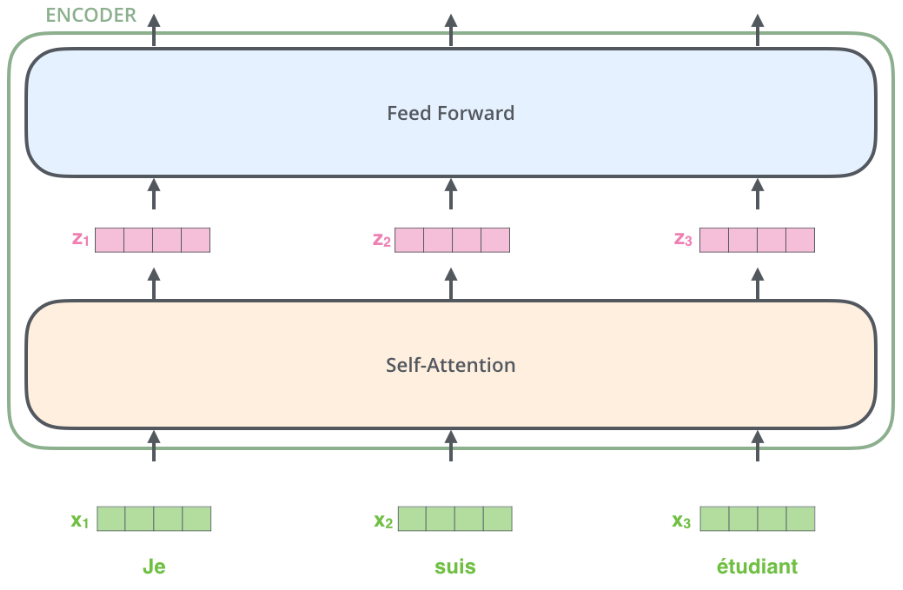
現在我們已經知道了Transformer模型中的核心組件Encoder和Decoder,接下來我們來看Token在Transformer中是怎么流轉的,換句話說Encoder和Decoder是怎么處理Token的。 拿最開始的法文翻譯的例子,模型將文本轉換token后,緊接著就是將每個token轉換成向量表達,在下圖中,我們用x1、x2、x3這樣的box來表示每個token的向量:

得到每個token的向量之后,從最底層的Encoder開始,每個token會沿著自己的路徑從下往上流轉,經過每一個Encoder,對每個Encoder來說,共同點是他們接收的向量的維度都是相同的,為了保證這一點,所有的token都需要被embedding成相同大小的向量。 ?
對Token進行位置編碼
在流經每個Encoder時,向量都會從自注意力層流向前饋層,如下圖所示:
這里需要注意的是,不同位置的向量在進入自注意力層的時候,相互之間是有依賴關系的,這就是注意力層需要關注的上下文的信息。 而當自注意力層處理后的向量進入前饋層后,前饋層是可以并行計算以提升性能的,因為在前饋層中向量之間不存在依賴關系。每個向量在經過Encoder處理后,得到的仍然是一個相同大小的向量,然后再提交給下一個Encoder進行處理。
為什么說不同位置的向量相互之間是有依賴關系的呢?我們可以想象一下,如果不關注一整個句子中token的位置信息,那么翻譯出來的結果是不準確的,比如:
Sam is always looking for trouble
Trouble is always looking for Sam
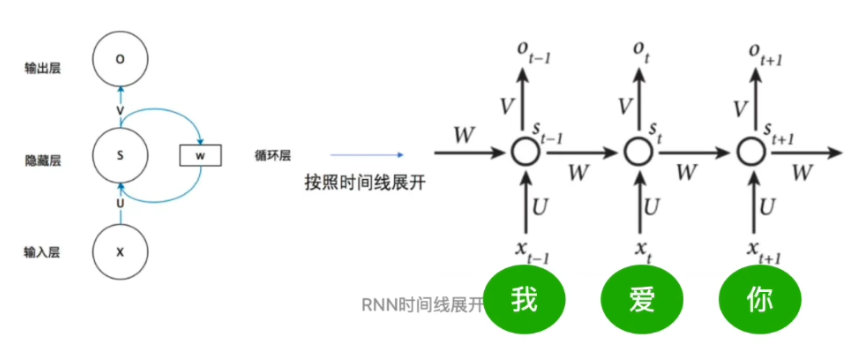
為了讓模型知道每個token的位置信息,傳統的RNN網絡的做法是,順序處理每個token,這樣在處理當前token時,可以往前查看已經處理過的token的信息,但是缺點是所有的token節點都共用一套相同的參數,即下圖中的:
U:輸入參數
W:隱藏參數
V:輸出參數
由于RNN的窗口較小,這種方案帶來的問題是,當token數變大時,模型無法參考更早之前已經參考過的token,這樣就會造成上下文記憶丟失。
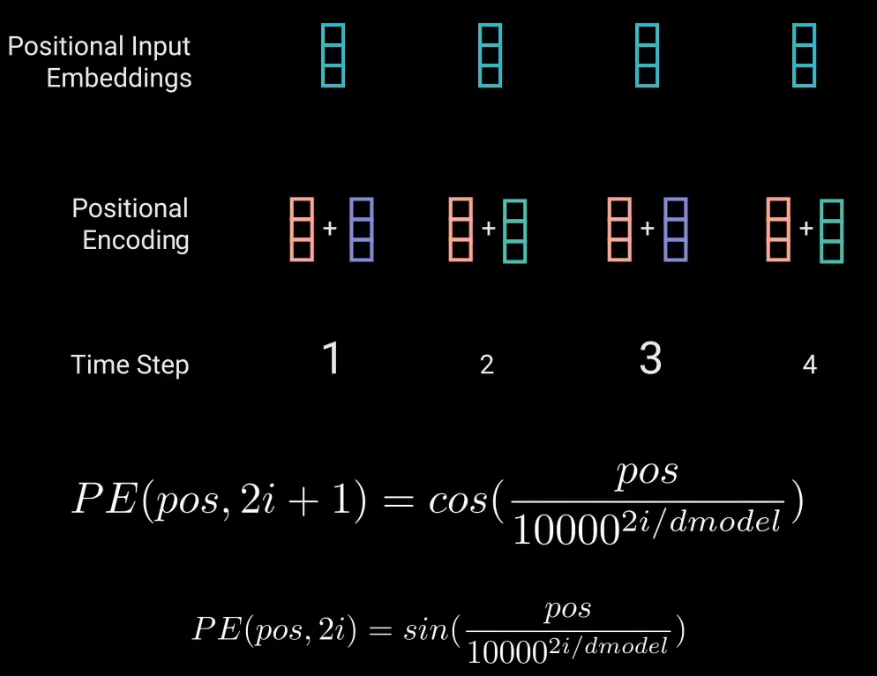
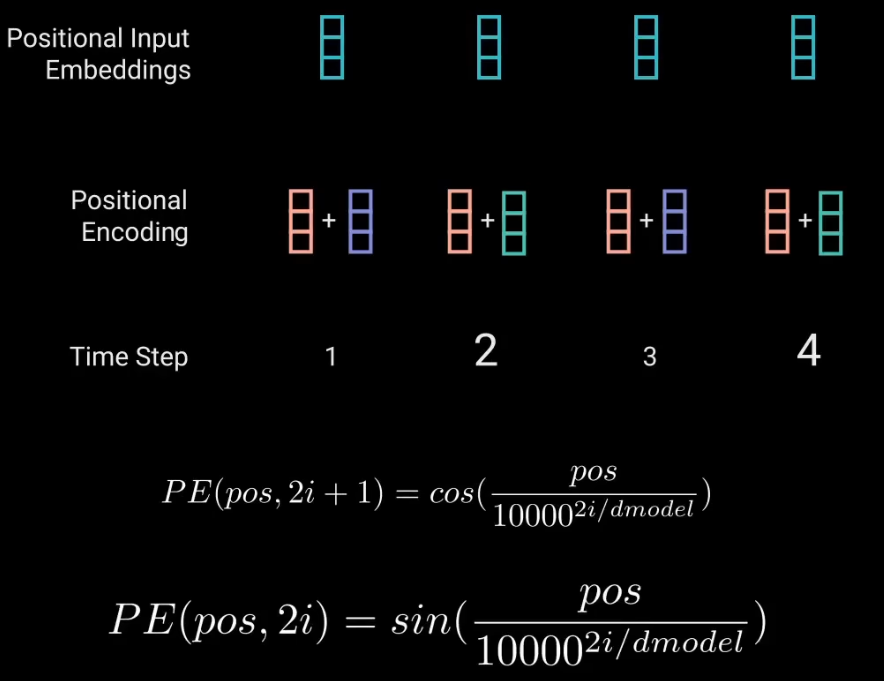
那么Transformer是怎么對token進行位置編碼的呢? 首先我們知道每個token會被轉換成512維(或更高的維度)的向量,比如:[0.12142,0.34181,....,-0.21231] 可以將這個向量分為兩個部分,奇數和偶數部分。 奇數部分使用cos函數,加上當前token的位置信息pos,通過cos編碼得到一個奇數編碼值; 偶數部分使用sin函數,加上當前token的位置信息pos,通過sin編碼得到一個偶數編碼值; 最后拿token的embeddings和pos的embeddings相加,得到位置編碼后的positional input embeddings。
?
自注意力機制
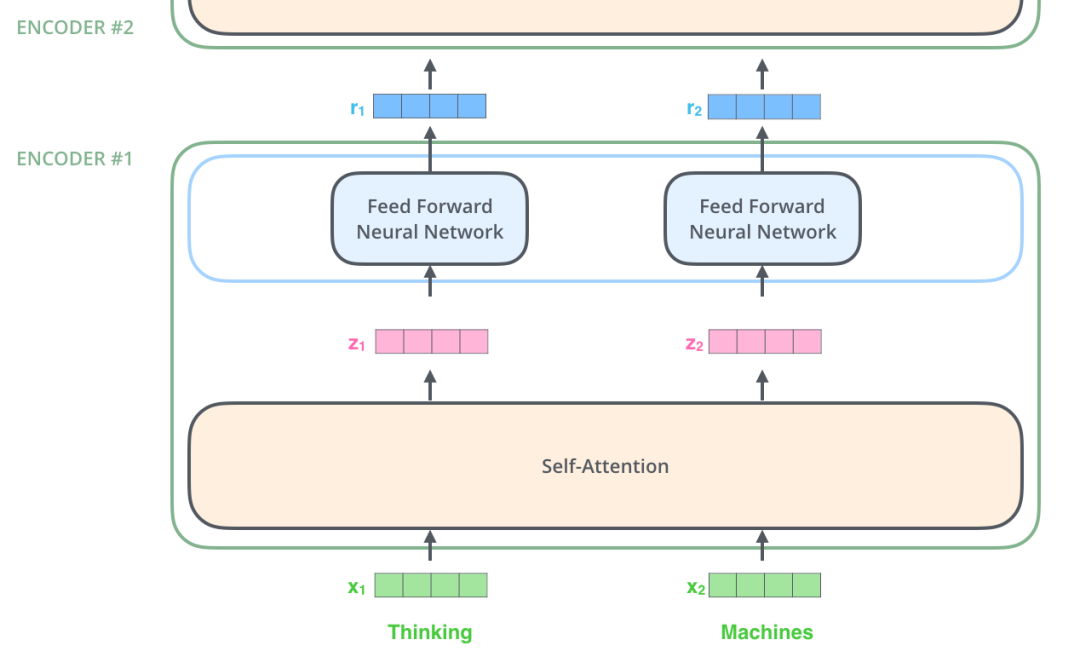
有了位置編碼的信息后,模型將接收經過位置編碼的embeddings輸入,為了方便描述,我們把token換成更簡單的文本,如下圖所示,Encoder在接收到兩個向量之后,通過自注意力層,將原始向量轉換成攜帶了自注意力值的向量,也就是圖中的z1和z2。
? ?
計算注意力值
那z1和z2這兩個向量是怎么得到的呢?原論文中給出了計算公式:
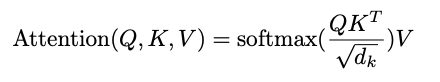
這個公式是用來計算注意力值的,借助了Q、K、V這三個矩陣: 首先通過Q矩陣和轉置后的K矩陣轉置相乘,得到結果后再除以dk的開平方,再通過softmax函數得到一個歸一化的結果,最后將歸一化的結果和矩陣V相乘就得到了表示注意力值的矩陣。
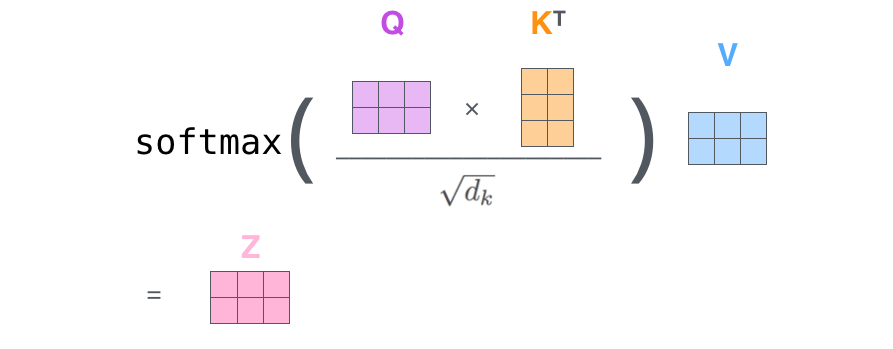
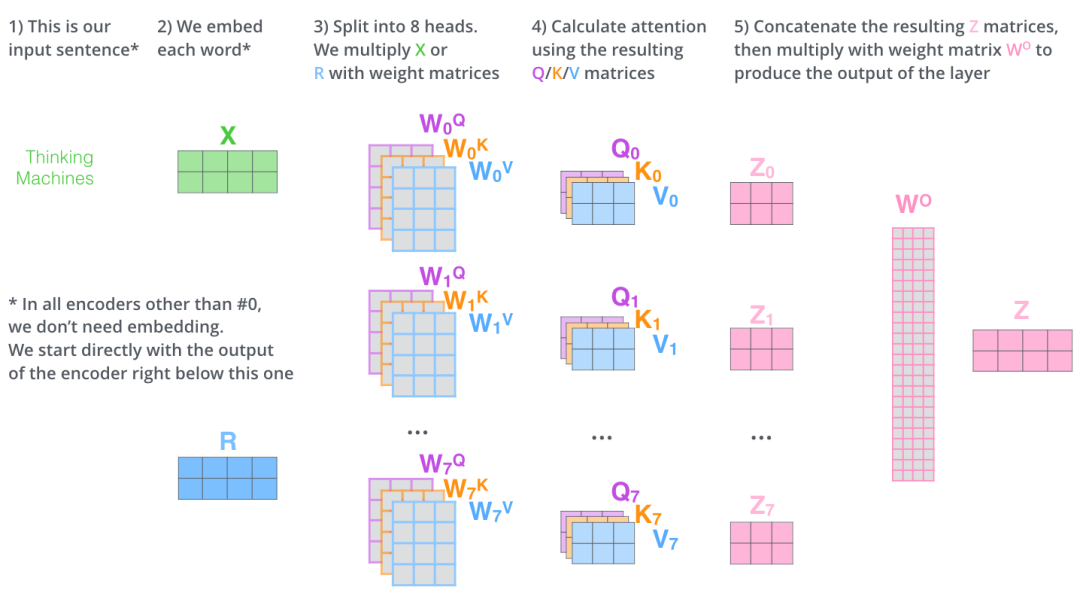
這里的Q、K、V三個矩陣(查詢矩陣、鍵矩陣、值矩陣)是通過原始token的embedding矩陣計算得到的,具體的方法是,先訓練出三個矩陣:Wq,Wk,Wv, 然后使用embedding處理后的X矩陣和這三個矩陣相乘得到:
Q=Wq * X
K=Wk * X
V=Wv * X
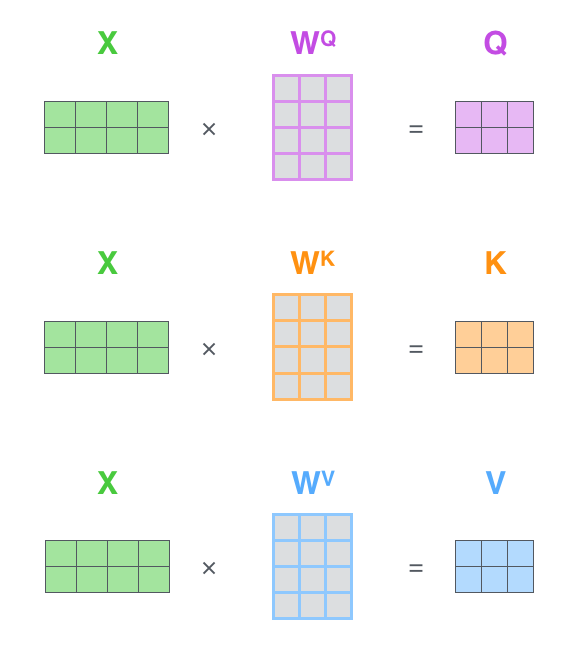
需要注意的是我們embedding輸入原本是向量,并不是矩陣,這里是將所有的向量打包之后,形成了一個矩陣,方便矩陣之間的計算。 下面我們一步步了解下注意力值是怎么計算的,使用原始的embedding,而不是打包后的矩陣,首先模型將會為句子中的每個token都計算出一個score分數,這個分數表示了該token對句子中其他token的關注程度,分數越高關注度越高。
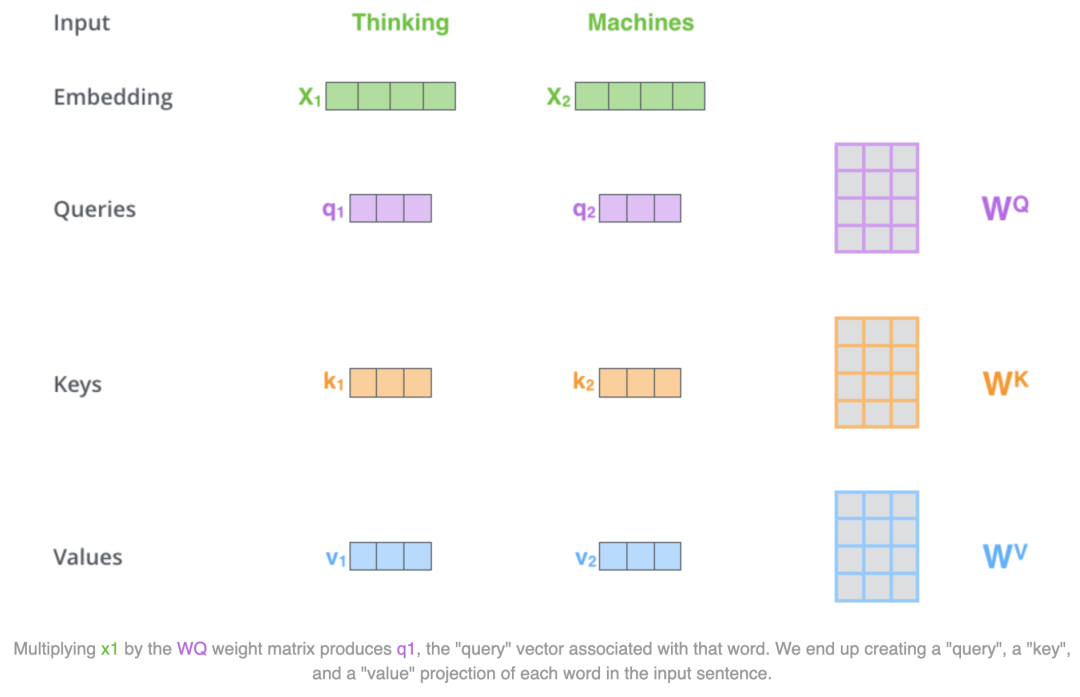
但是需要注意的是這里計算得到的中間向量q、k、v的維度是64維,小于Encoder接收的輸入向量的維度,這是一個經過計算后得到的相對穩定的數值。 如下圖所示,當我們在計算Tinking這個token的注意力值時,會依次計算出Thinking對其他token(在這里也就是Thinking和Machines)的注意力值,計算token1對其他各個token的score的方式是:q1 與 k1 做點積,q1 與 k2 做點積。
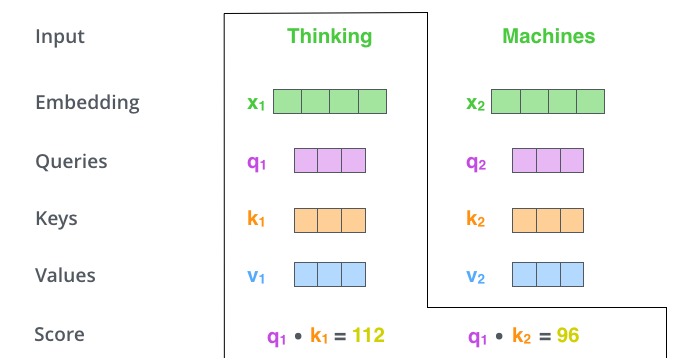
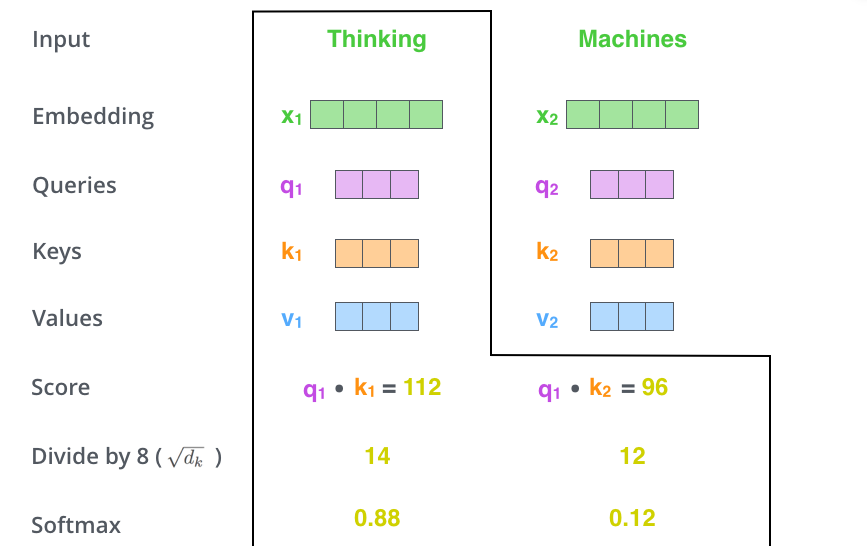
得到每個score后,再把score除以K向量維度的平方根也就是√64=8,然后將結果通過Softmax進行歸一化,得到一個0~1之間的概率值,所有的歸一化的加和值等于1。
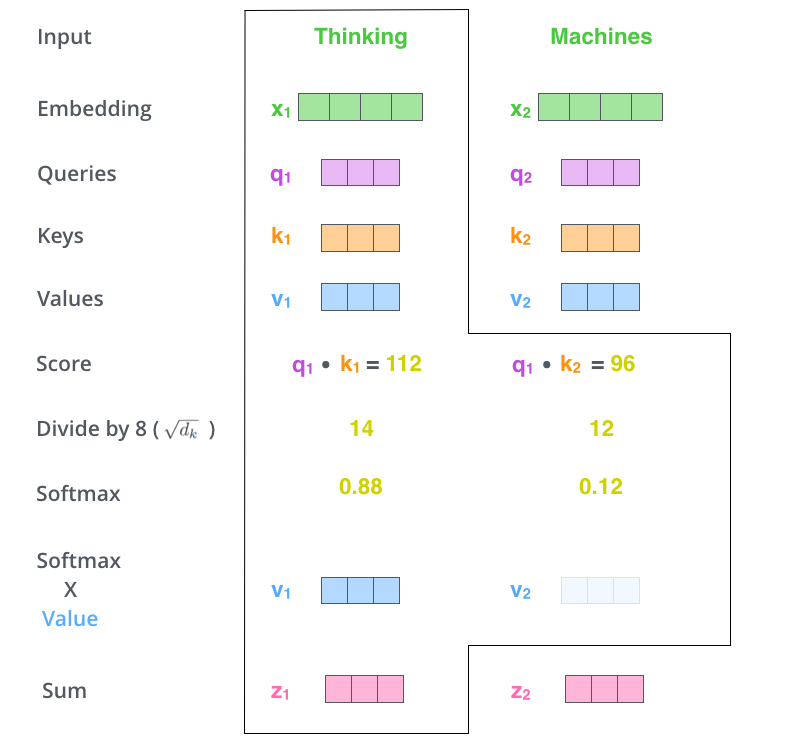
最后將Softmax的值,與V向量相乘,得到自注意力層的輸出結果向量:z1和z2,需要注意的是相乘的過程中會將不相關的token的關注度降低。
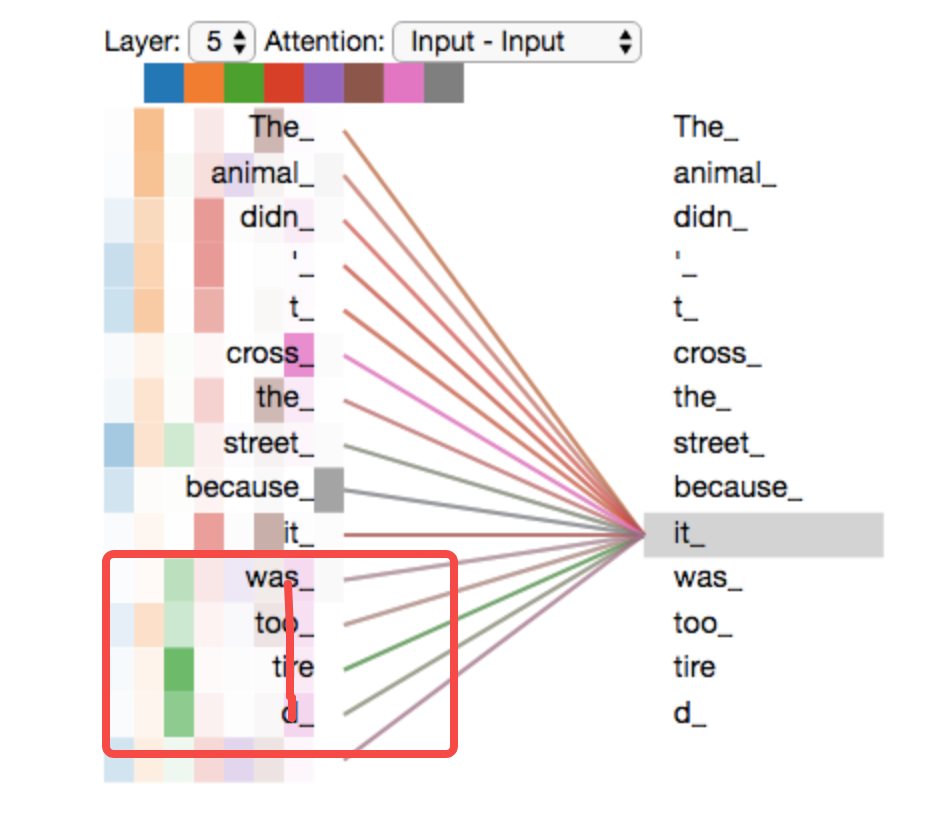
到這里其實已經把Encoder是怎么計算每個token對句子中其他token的注意力值的方法解釋清楚了,下面我們用一張圖從更高的層面來觀察這個過程,假設我們想要翻譯下面這個句子: The animal didn't cross the street because it was too tired. 句子中的it是表示什么呢,是animal還是street?模型就是通過自注意力值來確定的,當對it進行編碼時,Encoder會對句子中的每個token都計算一遍注意力值,模型會將it更關注的“The animal”編碼到it中。這樣模型在后續的處理過程中就能知道it指代的是“The animal”。

? ?
多頭注意力機制
論文中通過引入多個Encoder形成了一種“多頭注意力”的機制,對自注意力層進行了能力的提升,主要包括:
多頭注意力擴展了模型關注不同位置的能力
多頭注意力為自注意力層提供了多個子空間
Transformer模型使用了8個注意力頭,所以在計算每個Encoder的輸出時,我們會得到8個z向量。
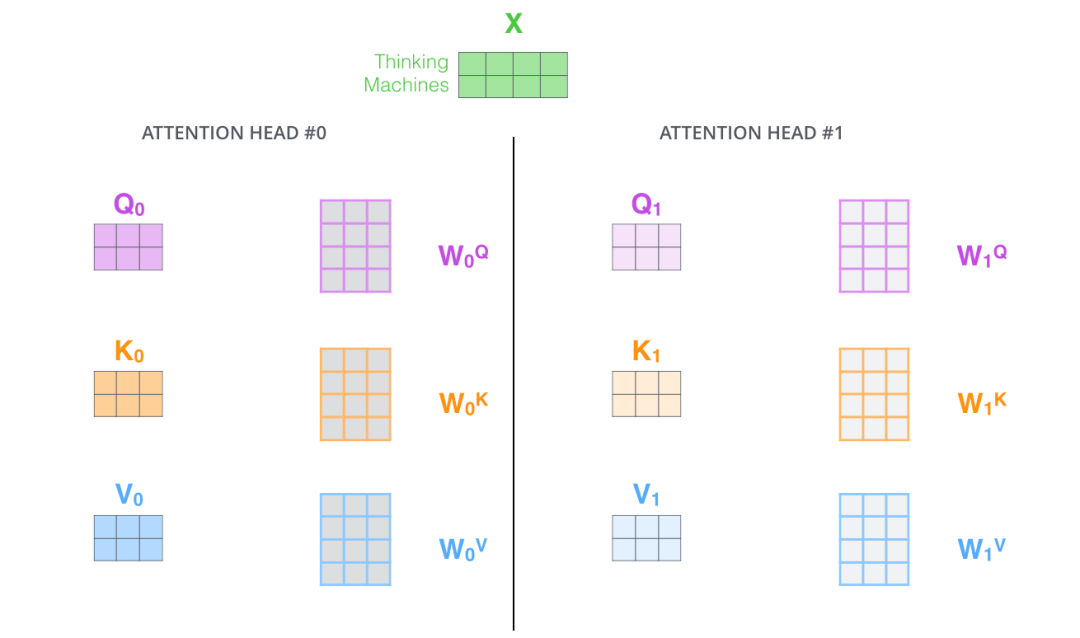
?
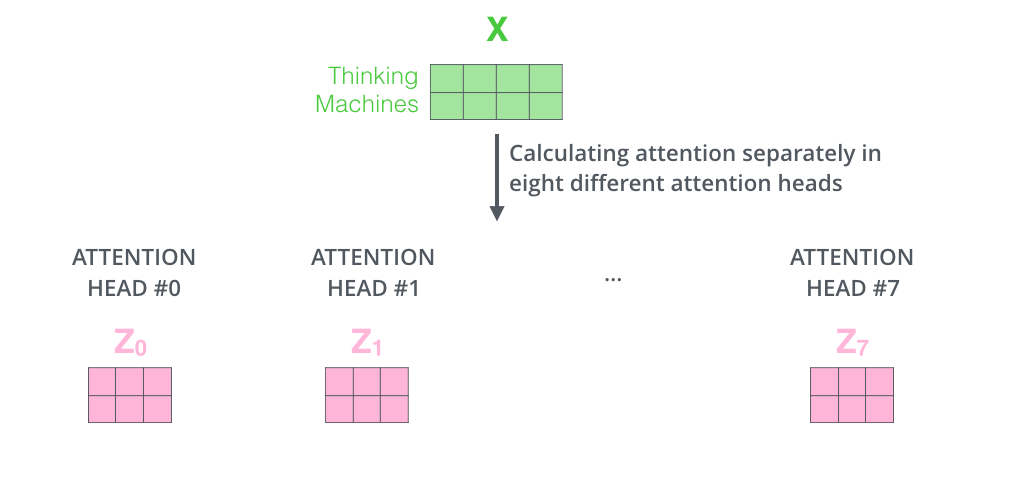
但是前饋層只能接收1個z向量,所以我們還需要將這8個z向量做壓縮得到1個向量,具體的做法是將這8個z向量鏈接起來,然后乘以一個附加的權重矩陣Wo,最后得到z向量,如下圖所示:
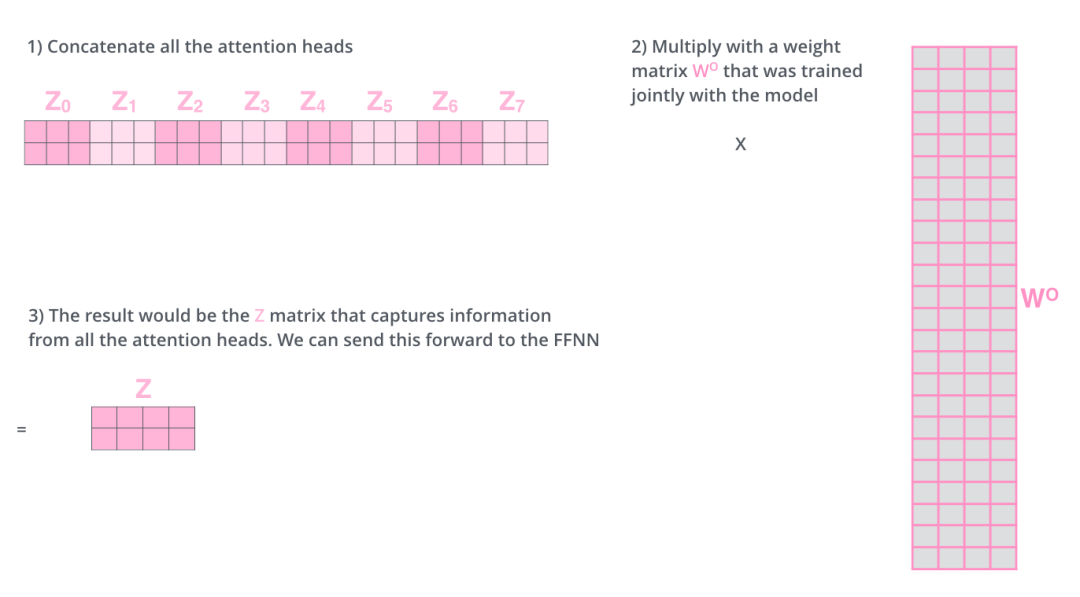
最后我們用一張完整的大圖來描述下在多個Encoder下,注意力值的計算過程,也就是多頭注意力機制:
下面我們可以看下,在多頭注意力機制下,在編碼it這個token時,模型在注意哪些其他的token:

可以看到其中一個頭(橙色)更關注“The Animal”,因為這兩個token對應的橙色更深,另外一個頭(綠色)則更關注“tired”,因為這兩個token對應的綠色更深。
殘差網絡
首先我們了解下什么是殘差網絡,殘差網絡(Residual Network,簡稱ResNet)是一種深度卷積神經網絡(CNN)架構,由Microsoft Research Asia的Kaiming He等人在2015年提出。ResNet的核心思想是通過引入“殘差學習”(residual learning)來解決深度神經網絡訓練中的退化問題(degradation problem)。 在傳統的深度神經網絡中,隨著網絡層數的增加,理論上網絡的表示能力應該更強,但實際上,過深的網絡往往難以訓練,性能反而不如層數較少的網絡。這種現象被稱為“退化問題”,即隨著網絡深度的增加,網絡的準確率不再提升,甚至下降。 ResNet通過引入“跳躍連接”(skip connections)或“捷徑連接”(shortcut connections)來解決這個問題。在ResNet中,輸入不僅傳遞給當前層,還直接傳遞到后面的層,跳過一些中間層。這樣,后面的層可以直接學習到輸入與輸出之間的殘差(即差異),而不是學習到未處理的輸入。這種設計允許網絡學習到恒等映射(identity mapping),即輸出與輸入相同,從而使得網絡可以通過更簡單的路徑來學習到正確的映射關系。 在Transformer模型中,殘差網絡的使用主要是為了解決自注意力機制(self-attention)帶來的問題。Transformer模型完全基于注意力機制,沒有卷積層,但其結構本質上也是深度網絡。在Transformer中,每個編碼器(encoder)和解碼器(decoder)層都包含自注意力和前饋網絡,這些層的參數量非常大,網絡深度也很容易變得很深。 使用殘差連接可以幫助Transformer模型更有效地訓練深層網絡。在Transformer的自注意力層中,輸入通過自注意力和前饋網絡后,與原始輸入相加,形成殘差連接。這種設計使得網絡即使在增加更多層數時,也能保持較好的性能,避免了退化問題。 總結來說,殘差網絡在Transformer模型中的應用解決了以下幾個問題:
緩解退化問題:通過殘差學習,使得網絡即使在增加層數時也能保持或提升性能。
加速收斂:殘差連接提供了梯度的直接路徑,有助于梯度在深層網絡中的傳播,加速訓練過程。
提高表示能力:允許網絡學習更復雜的函數,同時保持對簡單函數的學習能力。
Transformer模型的成功部分歸功于殘差連接的設計,這使得它能夠構建更深、更強大的模型,從而在自然語言處理(NLP)和計算機視覺等領域取得了顯著的成果。 可以使用下面這張圖來解釋殘差網絡,原始向量x在經過自注意力層之后得到z向量,為了防止網絡過深帶來的退化問題,Transformer模型使用了殘差網絡,具體做法是使用計算得到的z矩陣,在和原始輸入的x矩陣做殘差鏈接,即圖中的X+Z,然后使用LayerNorm函數進行層歸一化,計算得到新的z向量,然后輸入到前饋層。
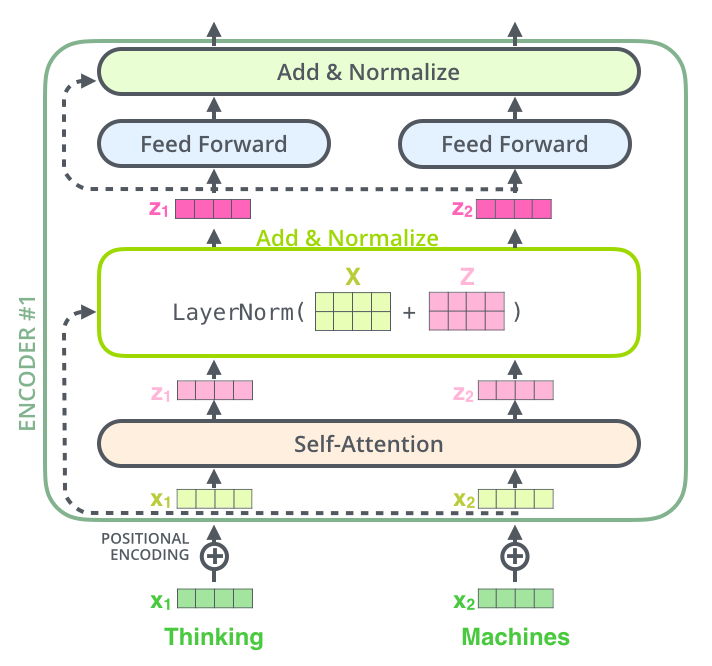
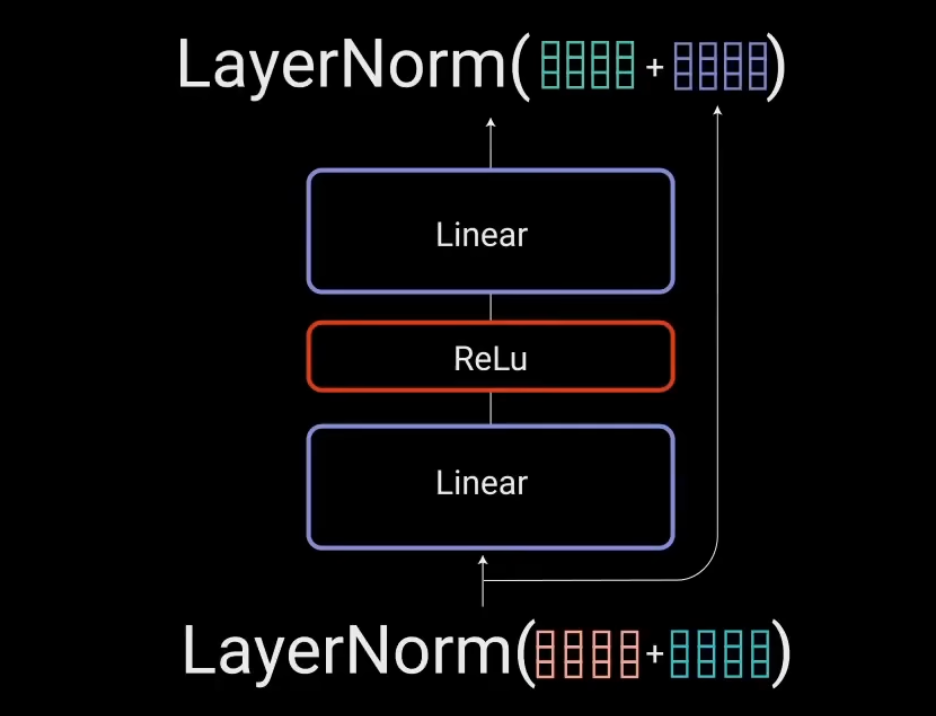
將?Add & Normalize?簡化之后表示為如下:
前饋網絡
歸一化后的殘差輸出,被送入點對點前饋網絡進行進一步處理,點對點前饋網絡是幾個線性層,中間有ReLU激活函數,將點對點輸出的結果與前饋網絡的輸入進行相加做殘差鏈接,然后再做進一步的歸一化。 點對點前饋網絡主要用于進一步處理注意力的輸出,讓結果具有更豐富的表達。
到這里編碼器就已經介紹完了,編碼器輸出的結果中攜帶了每個token的相關注意力信息,將用以幫助解碼器在解碼過程中關注輸入中的特定的token信息。
六
理解Token在解碼器中的流轉
每個解碼器擁有與編碼器相似的結構但也有不同的地方,它有兩個多頭注意力層,一個點對點前饋網絡層,并且在每個子層之后都有殘差鏈接和層歸一化。
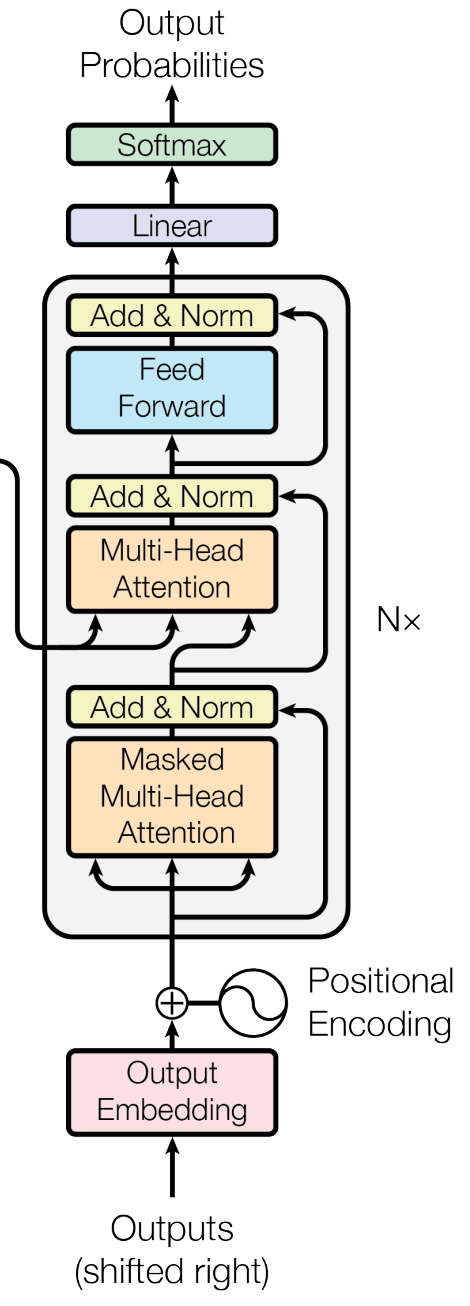
解碼器是自回歸的,它將前一個Decoder輸出的結果和來自編碼器輸出的注意力信息當做解碼器的輸入。
這里我們需要了解清楚,解碼器的先前的輸出結果是怎么得到的,即解碼器的第一個輸出結果從哪得到的。 在Transformer模型的訓練過程中,解碼器的第一個輸出序列通常是根據特定的起始標記(start token)或者一個預先定義的初始狀態得到的。這個起始標記是一個特殊的符號,它標志著輸出序列的開始。以下是解碼器如何獲得第一個輸出序列的詳細過程: 1. 起始標記: 在訓練階段,解碼器的輸入序列通常以一個起始標記(例如
Masked多頭注意力機制
需要注意的是解碼器中的第一層是一個特殊的多頭注意力層,是一個執行了mask的注意力層,因為解碼器是自回歸的,并且依次生成結果token,我們需要防止它在處理某個token時,對未來的token進行處理,原因是模型在訓練的時候,是不知道未來輸出的token是什么的,為了保證訓練過程和解碼的過程的一致性,我們需要讓解碼器在計算某個token的注意力值的時候,只關注這個句子中已經出現過的token,而屏蔽掉句子中當前token之后的其他token的信息。 可以通過以下這張圖來描述Mask的過程,當解碼器在處理it時,應該把it之后的所有token屏蔽掉。
計算注意力值
在解碼器中計算注意力值時,是用Encoder最后的輸出,和每一個Decoder進行交互,這就需要Decoder中的第二層Encoder-Decoder Attention。每個Decoder計算出結果之后,再作為輸入傳遞給下一個Decoder。
線性分類器&Softmax
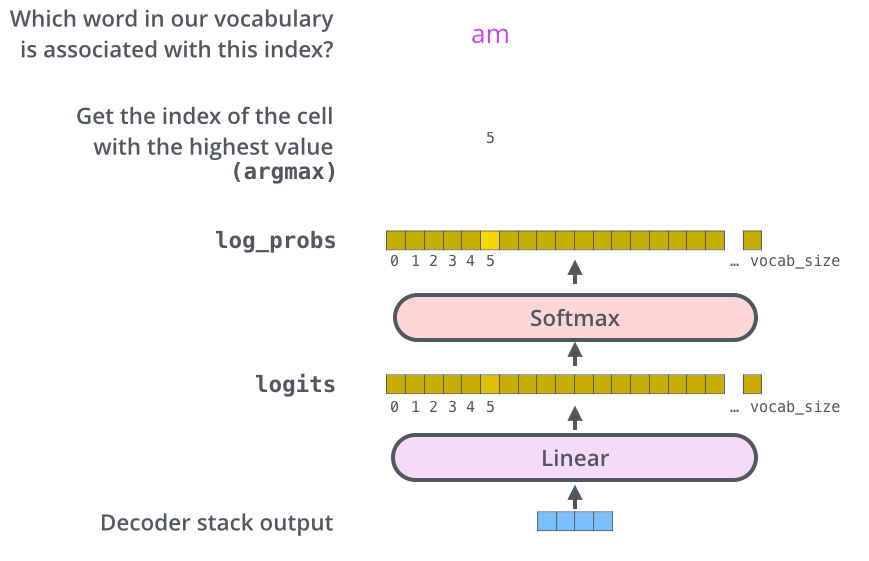
當最后一個Decoder計算完畢后,解碼器得到了一個輸出結果的向量數據。我們如何把它變成一個詞呢?這就是最后一個 Linear 層的工作,后面是 Softmax 層。 線性層是一個簡單的全連接神經網絡,它將解碼器產生的向量投影到一個更大的向量中,稱為 logits 向量。 假設我們的模型知道從訓練數據集中學習的 10,000 個獨特的英語單詞。這將使 logits 向量有 10,000 個單元格寬——每個單元格對應一個唯一單詞的分數,這就是我們解釋線性層模型輸出的方式。 然后,softmax 層將這些分數轉換為概率(全部為正,全部加起來為 1.0)。選擇概率最高的單元格,并生成與其關聯的單詞作為該時間步的輸出。
編解碼器的協同工作
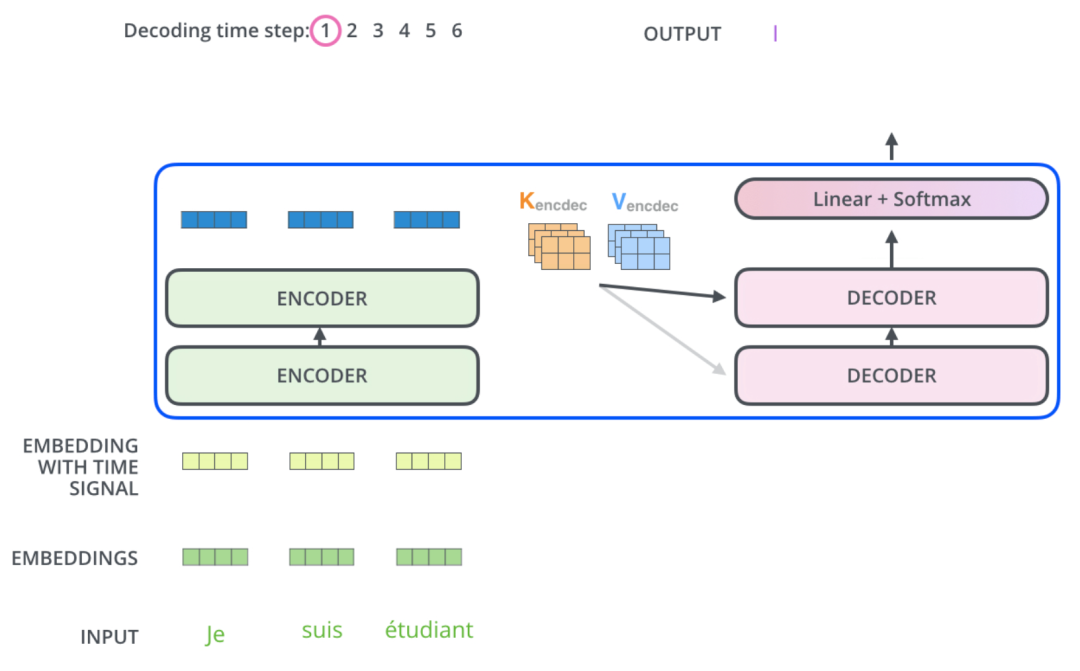
現在讓我們看看編碼器和解碼器之間是如何協同工作的。 編碼器首先處理輸入的文本token,然后輸出一組注意力向量 K 和 V。這些向量將由每個解碼器在其“編碼器-解碼器注意力”層中使用,這有助于解碼器關注輸入序列中的特定token的位置信息,具體計算注意力值的方法跟編碼器中是一樣的,需要注意的是,這里的K、V矩陣來自于編碼器的輸出,而Q矩陣來自于解碼器的輸入。
重復回歸以上的步驟,直到出現結束符號的標識,表示解碼器已完成其輸出。每個步驟的輸出在下一個時間步驟中被反饋到底部解碼器,并且解碼器像編碼器一樣向上反饋其解碼結果。就像我們對編碼器輸入所做的那樣,我們將位置編碼嵌入并添加到這些解碼器輸入中以指示每個單詞的位置。
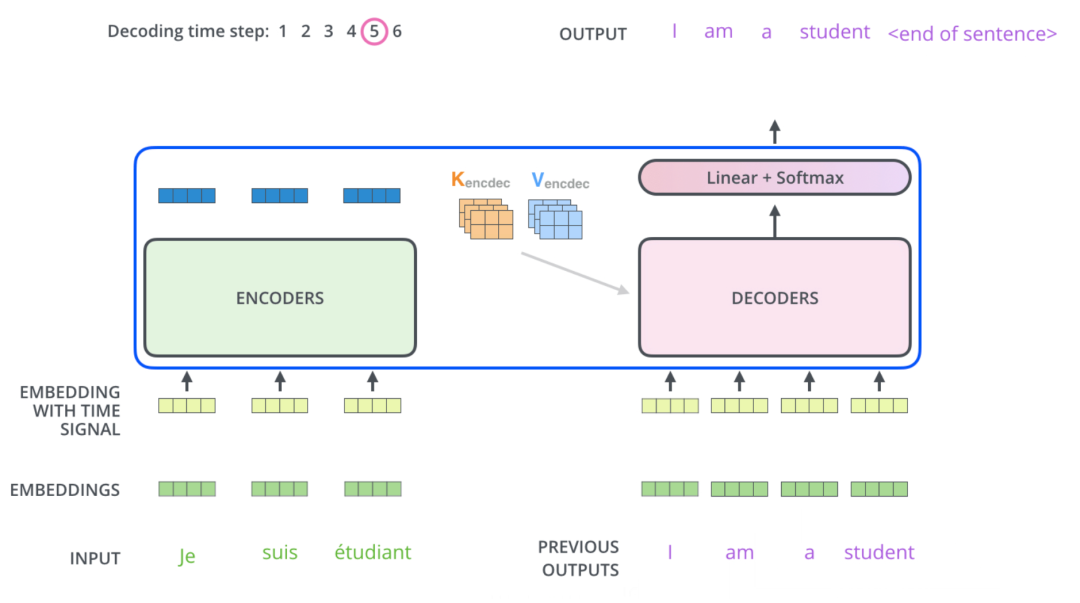
至此,已經分析完Transformer的編碼器和解碼器的全流程了。
七
Transformer-XL怎樣提升上下文長度
傳統的Transformer模型中,上下文長度是固定的,主要有以下幾個原因:
計算效率:在最初的設計中,Transformer模型是為了處理序列到序列的任務,如機器翻譯。對于這類任務,輸入序列(如源語言句子)和輸出序列(如目標語言句子)通常具有相似的長度,因此固定上下文長度可以簡化模型設計,提高計算效率。
模型復雜度:Transformer模型的核心是自注意力機制,該機制在計算時需要對序列中的每個元素進行成對的比較,以計算注意力權重。如果上下文長度不固定,那么每次添加或刪除元素時,都需要重新計算整個序列的注意力權重,這會導致計算復雜度和內存需求急劇增加。
訓練穩定性:固定長度的上下文可以提供穩定的訓練環境,有助于模型學習到更加一致和可靠的表示。如果上下文長度不固定,模型可能需要在每次迭代中適應新的序列長度,這可能會影響訓練的穩定性和模型的收斂速度。
硬件限制:在實際應用中,硬件資源(如GPU內存)是有限的。固定長度的上下文可以確保模型在任何時候都不會超出硬件資源的限制,從而避免因資源不足而導致的訓練中斷。
模型泛化:固定長度的上下文允許模型在訓練時學習到特定長度范圍內的依賴關系,這有助于模型在實際應用中泛化到類似的序列長度上。
然而,固定上下文長度也帶來了一些限制,特別是在處理長序列時,模型無法捕獲超過固定長度的依賴關系,這限制了模型在某些任務(如長文本生成和理解)上的性能。為了解決這個問題,Transformer-XL等模型通過引入新的機制來允許處理更長的上下文,從而在不犧牲計算效率的情況下捕獲更長期的依賴關系。 國產開源公司月之暗面的大模型產品kimi,能夠處理長達20萬字的超長上下文,那么他是怎么做到的呢,核心是他的模型在Transformer的基礎上做了擴展,實現了自己的Transformer-XL架構。 Transformer-XL通過引入兩個關鍵的技術改進來提升token上下文長度的處理能力:片段遞歸機制(segment-level recurrence)和相對位置編碼機制(relative positional encoding)。
片段遞歸機制:在傳統的Transformer模型中,由于上下文長度是固定的,模型無法捕獲超過預定義上下文長度的長期依賴性。Transformer-XL通過引入循環機制來解決這個問題。具體來說,它不再從頭開始計算每個新片段的隱藏狀態,而是重復使用之前片段中獲得的隱藏狀態,并將這些狀態作為當前片段的“記憶”。這樣,信息就可以在不同片段之間傳遞,從而捕獲更長的依賴關系。這種機制允許模型在不引起時間混亂的前提下,超越固定長度去學習依賴性,同時解決了上下文碎片化問題。
相對位置編碼機制:在Transformer-XL中,為了能夠在不造成時間混亂的情況下重復使用狀態,引入了相對位置編碼的概念。相對位置編碼與傳統的絕對位置編碼不同,它只編碼token之間的相對位置關系,而不是token與固定起始點的絕對位置。這種編碼方式使得模型能夠在處理長序列時更有效地利用位置信息,并且可以泛化至比在訓練過程中觀察到的長度更長的注意力長度。
通過這兩種機制,Transformer-XL顯著提升了模型在處理長序列時的性能。
八
Transformer相關應用分享
使用BERT做掩詞填充
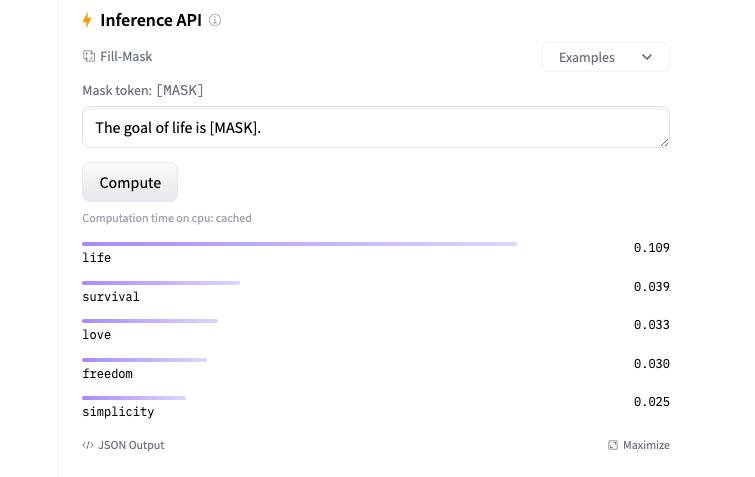
BERT(Bidirectional Encoder Representations from Transformers)是一種預訓練語言表示模型,由Google AI在2018年提出。BERT的核心創新在于利用Transformer架構的編碼器部分來學習文本數據的深層次雙向表示。這種表示能夠捕捉到文本中詞匯的上下文關系,從而在多種自然語言處理(NLP)任務中取得了顯著的性能提升。 以下是BERT模型的一些關鍵特點: 雙向上下文理解:與之前的單向語言模型不同,BERT通過在預訓練階段使用掩碼語言模型(Masked Language Model, MLM)任務,學習了詞匯在句子中的雙向上下文信息。這意味著模型能夠同時考慮一個詞前后的詞匯來理解其含義。 預訓練和微調:BERT采用了兩階段的訓練策略。在預訓練階段,BERT在大量文本數據上進行無監督學習,學習語言的通用模式。在微調階段,BERT可以通過少量標注數據針對特定任務進行有監督學習,以適應各種NLP任務,如情感分析、問答系統、命名實體識別等。 Transformer架構:BERT基于Transformer的編碼器部分,這是一種注意力機制(Attention Mechanism)的架構,它允許模型在處理序列數據時考慮序列中所有位置的信息。 大規模預訓練:BERT在非常大的文本語料庫上進行預訓練,這使得模型能夠學習到豐富的語言知識。預訓練的規模和質量對模型性能有重要影響。 多樣化的任務適應性:通過微調,BERT可以適應多種不同的NLP任務,而不需要對模型架構進行大的修改。這使得BERT成為了一個靈活且強大的工具。 BERT的推出標志著NLP領域的一個重大進展,它在多項NLP任務上刷新了記錄,并催生了一系列基于BERT的改進模型,如RoBERTa、ALBERT、DistilBERT等。這些模型在不同的方面對BERT進行了優化,以提高性能、減少計算資源消耗或改善特定任務的表現。 以下是使用BERT做掩詞填充的示例,輸入一段文本,讓模型預測出下一個被掩蓋的詞: https://huggingface.co/google-bert/bert-base-uncased
使用BART做文本摘要
BART(Bidirectional and Auto-Regressive Transformers)是一種先進的自然語言處理(NLP)模型,它結合了BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer)的特點,用于文本理解和生成任務。BART模型特別擅長處理不同類型的文本噪聲和序列變換,使其在多種NLP任務中表現出色。 設計原理和結構
BART是基于Transformer架構的自編碼自回歸模型。它通過兩個主要步驟進行預訓練:
使用任意噪聲函數破壞文本(例如,隨機打亂句子順序、刪除或遮蔽token)。
模型學習重建原始文本。
這種預訓練方式使得BART能夠有效地處理文本生成、翻譯和理解等任務。BART的編碼器是雙向的,能夠捕捉文本的前后文信息,而解碼器是自回歸的,能夠基于前面的輸出生成后續的內容。 應用 BART在多種NLP任務上取得了顯著的成績,包括但不限于:
文本摘要
機器翻譯
對話生成
問答系統
文本分類
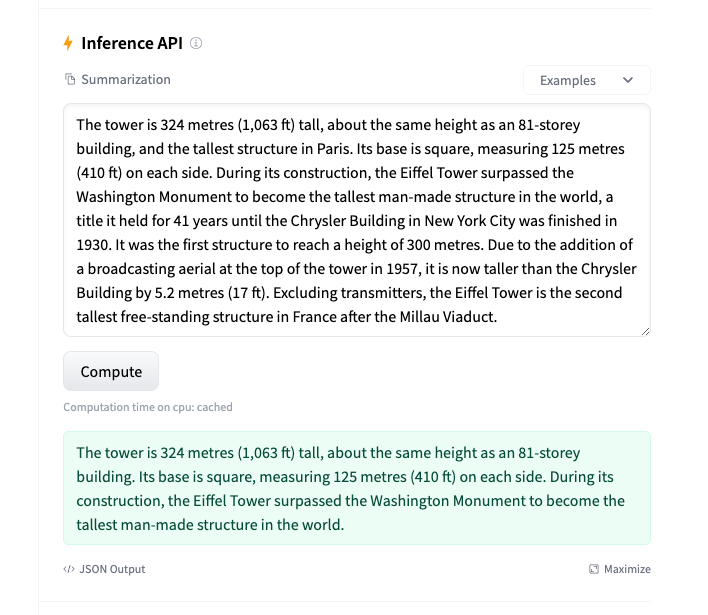
與其他模型的對比 與其他預訓練模型相比,BART在處理文本生成任務時尤其出色。它在自然語言理解任務中也有很好的表現,與BERT和GPT等模型相比,BART在多個基準數據集上取得了競爭性或更好的結果。 預訓練和微調 BART模型通過大量的文本數據進行預訓練,然后在特定任務上進行微調。預訓練階段,模型學習如何從噪聲文本中恢復原始文本,而微調階段則是針對特定任務調整模型參數,以優化任務性能。 以下是使用BART做文本摘要的應用示例: https://huggingface.co/facebook/bart-large-cnn
使用DistilBERT做問答
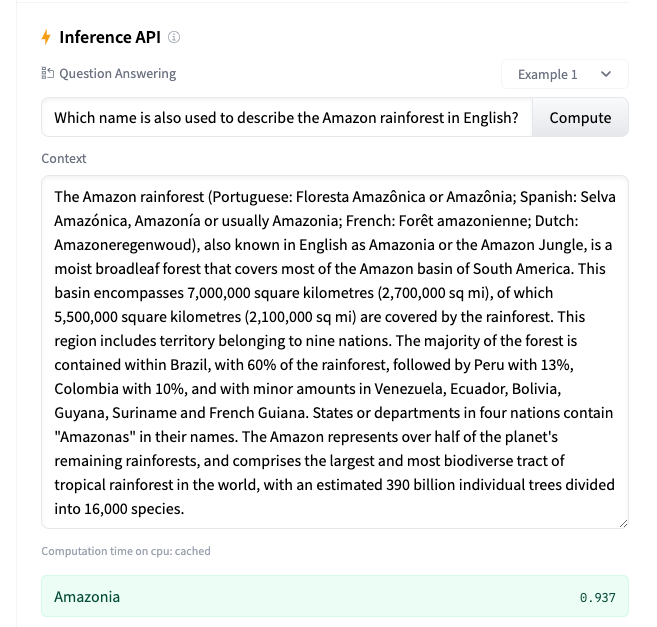
DistilBERT是一種輕量級的BERT模型,它通過知識蒸餾(knowledge distillation)技術從預訓練的BERT模型中學習知識。這種方法的核心思想是使用一個較小的BERT模型作為“學生”模型,而原始的、較大的BERT模型則充當“教師”模型。在訓練過程中,學生模型嘗試復制教師模型的輸出,以此來學習教師模型的知識。 主要特點和優勢 模型大小和效率:DistilBERT的模型大小和參數量都比原始的BERT模型小,這使得它在資源受限的環境中(如移動設備)更加實用。它的推理速度也比BERT快,因為它需要處理的參數更少。 知識蒸餾:DistilBERT使用了一種稱為“軟目標”的知識蒸餾方法。在這種方法中,學生模型不僅學習來自訓練數據的標簽,還學習教師模型的輸出,這些輸出被視為附加的、軟性的標簽。 保持性能:盡管DistilBERT的模型大小減小了,但它仍然保持了與原始BERT模型相當的性能,特別是在自然語言理解任務上。 靈活性:DistilBERT保留了BERT模型的基本架構,包括Transformer的串聯層,這使得它可以很容易地適應各種下游任務。 結構和訓練 DistilBERT的結構相對簡單,它僅保留了BERT的6層Transformer,刪除了token type embedding和pooler層。在訓練過程中,它使用了一種稱為“模型壓縮”的技術,通過這種方法,模型的層數被減半,同時從教師模型的層初始化學生模型的層。 應用場景 由于其較小的模型大小和較快的推理速度,DistilBERT適用于需要快速處理和低資源消耗的NLP任務,例如文本分類、情感分析、問答系統和語言模型等。 總的來說,DistilBERT是一個高效的BERT變體,它通過知識蒸餾技術實現了模型的壓縮,同時保持了良好的性能,特別適合在資源受限的環境中使用。 以下是是使用DistilBERT做問答的實例: https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad
使用T5做文本翻譯
T5模型,全稱為“Text-to-Text Transfer Transformer”,是由Google Research團隊開發的一種自然語言處理(NLP)模型。T5模型的核心思想是將所有NLP任務統一轉換為文本到文本(Text-to-Text)的格式,從而可以使用同一個模型和訓練過程來處理多種不同的任務,如翻譯、摘要、問答等。 主要特點和優勢 統一的框架:T5模型通過將任務轉換為文本到文本的格式,簡化了不同NLP任務的處理方式。例如,對于翻譯任務,輸入可以是“translate English to German: [English text]”,輸出則是翻譯后的文本。 基于Transformer架構:T5模型采用了Transformer的encoder-decoder架構,這是一種高效的網絡結構,特別適合處理序列數據。 預訓練和微調:T5模型首先在大規模的數據集上進行預訓練,學習語言的通用表示,然后可以針對特定任務進行微調,以優化任務性能。 廣泛的應用場景:T5模型可以應用于多種NLP任務,包括但不限于文本分類、命名實體識別、情感分析、機器翻譯和對話生成等。 高效的計算能力:T5模型的設計允許它高效地處理大規模數據集,并且具有強大的并行處理能力。 訓練和應用 T5模型在訓練時使用了一種稱為“C4”的大規模數據集,這個數據集由經過清洗的Common Crawl數據組成。模型通過不同的預訓練目標和策略進行訓練,包括自回歸、自編碼和文本重排等。 在應用方面,T5模型的強大語言表示能力和廣泛的應用場景使其成為NLP領域的一個重要工具。它可以通過微調來適應不同的領域和任務,從而在多個NLP任務上取得優異的性能。 T5模型通過其創新的Text-to-Text框架和基于Transformer的架構,在自然語言處理領域提供了一種新的解決方案,能夠處理多種復雜的語言任務,并且具有很好的擴展性和適應性。 以下是使用T5做文本翻譯的示例: https://huggingface.co/google-t5/t5-base
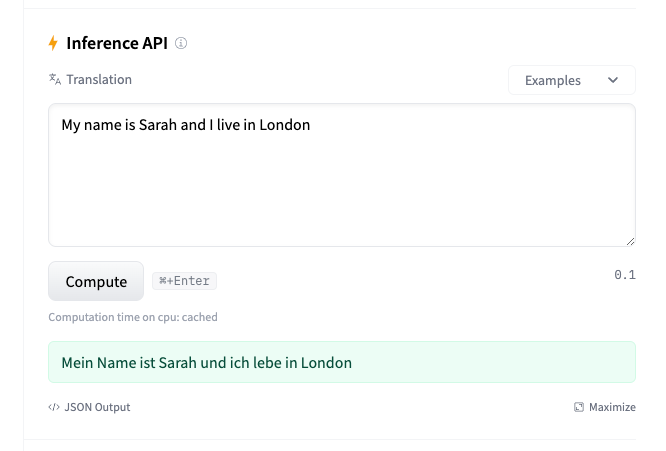
使用GPT-2寫小說
GPT-2(Generative Pre-trained Transformer 2)是由OpenAI開發的自然語言處理(NLP)模型,它是GPT系列模型的第二代。GPT-2在自然語言理解和生成方面表現出色,能夠生成連貫、相關且多樣化的文本。這個模型在發布時因其生成文本的質量和多樣性而受到廣泛關注。 主要特點和優勢 大規模預訓練:GPT-2通過在大規模的互聯網文本數據集上進行預訓練,學習到了豐富的語言模式和知識。這種預訓練使得模型能夠理解和生成自然語言文本。 Transformer架構:GPT-2基于Transformer模型架構,這是一種依賴于自注意力(self-attention)機制的深度學習架構,非常適合處理序列數據,如文本。 無監督學習:GPT-2采用無監督學習方法,通過預測下一個詞的任務來預訓練模型。這種訓練方式不依賴于標注數據,使得模型能夠學習到更廣泛的語言知識。 生成能力:GPT-2特別擅長文本生成任務,能夠生成連貫、有邏輯的段落和文章,甚至能夠模仿特定的寫作風格。 多樣性:GPT-2能夠處理多種語言任務,包括文本生成、翻譯、問答、摘要等。 版本和規模 GPT-2有多個版本,不同版本之間主要區別在于模型的大小和參數數量。例如,最小的版本有1.17億個參數,而最大的版本(GPT-2 1.5 Billion)有15億個參數。隨著模型規模的增加,性能和生成文本的質量也相應提高。 應用場景 GPT-2可以應用于多種場景,如聊天機器人、文本摘要、內容創作輔助、語言翻譯等。它的生成能力使得在創意寫作、新聞生成和其他需要自然語言生成的領域中具有潛在的應用價值。 挑戰和限制 盡管GPT-2在生成文本方面表現出色,但它也面臨一些挑戰和限制,包括生成文本的偏見問題、事實準確性問題以及潛在的濫用風險。因此,OpenAI在發布GPT-2時采取了謹慎的態度,逐步放開對模型的訪問權限。 總的來說,GPT-2是一個強大的NLP模型,它在文本生成和理解方面的能力使其成為自然語言處理領域的一個重要里程碑。 以下是使用GPT-2做文本生成的示例: https://huggingface.co/openai-community/gpt2
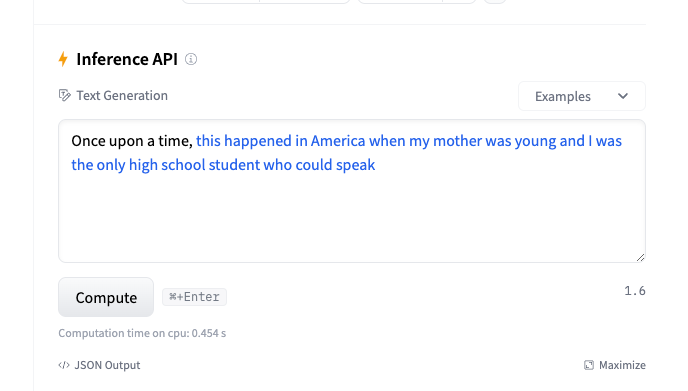
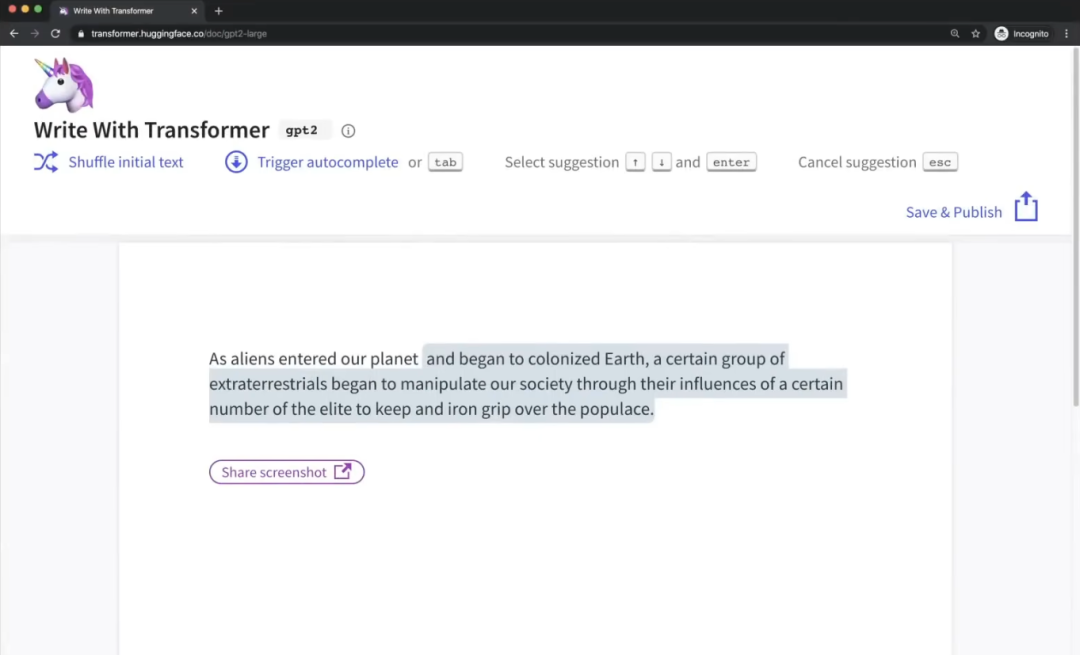
完整的體驗地址:https://transformer.huggingface.co/doc/gpt2-large 我們可以輸入一段小說的開頭,比如:As aliens entered our planet,然后Transformer就會依據我們輸入的文本,自動腦補剩下的小說情節。
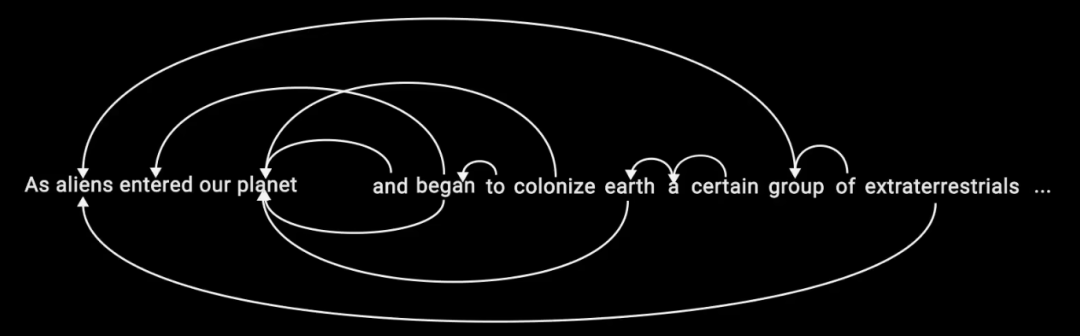
那Transformer是怎么做到的呢?如下圖所示,Transformer在生成每一個token時,會參考前面所有的token,并生成與之相符的token,這樣循環往復就能生成完整的一段內容。
審核編輯:黃飛













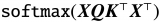







 工商網監
工商網監
評論