 電子發(fā)燒友App
電子發(fā)燒友App


作者:黃澤霞,邵春莉
摘要:本綜述涵蓋了深度學(xué)習(xí)技術(shù)應(yīng)用到SLAM領(lǐng)域的最新研究成果,重點(diǎn)介紹和總結(jié)了深度學(xué)習(xí)在前端跟蹤、后端優(yōu)化、語(yǔ)義建圖和不確定性估計(jì)中的研究成果,展望了深度學(xué)習(xí)下視覺(jué)SLAM的發(fā)展趨勢(shì),為后繼者了解與應(yīng)用深度學(xué)習(xí)技術(shù)、研究移動(dòng)機(jī)器人自主定位和建圖問(wèn)題的可行性方案提供助力。
?
引言
隨著機(jī)器人技術(shù)的發(fā)展,越來(lái)越多的機(jī)器人被用來(lái)代替人類(lèi)完成簡(jiǎn)單重復(fù)或危險(xiǎn)的工作。移動(dòng)機(jī)器人由于具有較強(qiáng)的靈活性和可靠性,已逐漸成為機(jī)器人領(lǐng)域的研究焦點(diǎn)。在沒(méi)有人干預(yù)的情況下,通過(guò)自身所帶的傳感器感知環(huán)境,獲取未知環(huán)境的信息,并對(duì)環(huán)境進(jìn)行建模,實(shí)現(xiàn)自主導(dǎo)航和定位是移動(dòng)機(jī)器人的核心任務(wù)。目前,同步定位與地圖創(chuàng)建(SLAM)技術(shù)是實(shí)現(xiàn)移動(dòng)機(jī)器人這一任務(wù)的主流技術(shù)方案。
SLAM技術(shù)最早被應(yīng)用在機(jī)器人領(lǐng)域,是希望在沒(méi)有任何先驗(yàn)知識(shí)的情況下,機(jī)器人能依據(jù)傳感器的信息實(shí)時(shí)構(gòu)建周?chē)h(huán)境地圖,同時(shí),根據(jù)這個(gè)地圖推測(cè)自身的位置[1]。根據(jù)所使用的傳感器類(lèi)型的不同,可以把SLAM分為基于雷達(dá)的SLAM和基于視覺(jué)的SLAM。如圖 1所示,一個(gè)完整的視覺(jué)SLAM系統(tǒng)主要由傳感器數(shù)據(jù)流、前端跟蹤模塊(視覺(jué)里程計(jì))、后端優(yōu)化模塊、回環(huán)檢測(cè)模塊和地圖構(gòu)建模塊組成[2]。
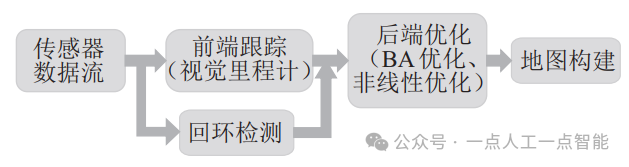
圖1 視覺(jué)SLAM系統(tǒng)框架
隨著深度學(xué)習(xí)技術(shù)的興起,計(jì)算機(jī)視覺(jué)的許多傳統(tǒng)領(lǐng)域都取得了突破性進(jìn)展,例如目標(biāo)的檢測(cè)、識(shí)別和分類(lèi)等領(lǐng)域。近年來(lái),研究人員開(kāi)始在視覺(jué)SLAM算法中引入深度學(xué)習(xí)技術(shù),使得深度學(xué)習(xí)SLAM系統(tǒng)獲得了迅速發(fā)展,并且比傳統(tǒng)算法展現(xiàn)出更高的精度和更強(qiáng)的環(huán)境適應(yīng)性。
從2015年Kendall等[3]?提出在視覺(jué)里程計(jì)中引入深度學(xué)習(xí)方法開(kāi)始,經(jīng)過(guò)近十年的發(fā)展,基于深度學(xué)習(xí)的視覺(jué)SLAM系統(tǒng)框架已日趨成熟。同時(shí),深度學(xué)習(xí)與視覺(jué)SLAM結(jié)合發(fā)展方面也取得了很多進(jìn)展[4-8]。其中,文[4] 較早地對(duì)深度學(xué)習(xí)與SLAM融合方法進(jìn)行了深入細(xì)致的調(diào)研,并展望了幾個(gè)未來(lái)的方向。但由于當(dāng)時(shí)對(duì)語(yǔ)義SLAM領(lǐng)域的研究剛剛起步,文中只進(jìn)行了簡(jiǎn)要討論,沒(méi)有辦法進(jìn)行全面總結(jié)。此外,多數(shù)綜述都只對(duì)SLAM系統(tǒng)的某幾個(gè)方面進(jìn)行歸納與總結(jié),如,對(duì)視覺(jué)里程計(jì)和回環(huán)檢測(cè)研究成果的總結(jié)[5],對(duì)視覺(jué)里程計(jì)、回環(huán)檢測(cè)和地圖重建的調(diào)研[6-7]?等。值得注意的是,雖然也有專(zhuān)門(mén)討論不確定性估計(jì)算法的綜述[9-10],然而,它們大部分的關(guān)注點(diǎn)主要集中在基于神經(jīng)網(wǎng)絡(luò)方法對(duì)不確定性的建模、深度模型下不確定性方法之間的對(duì)比等。
基于上述分析及廣泛調(diào)研,本文對(duì)深度學(xué)習(xí)下視覺(jué)SLAM方法涵蓋的幾大模塊(視覺(jué)里程計(jì)、回環(huán)檢測(cè)、全局優(yōu)化、語(yǔ)義SLAM以及不確定性估計(jì))當(dāng)前采用的算法的性能特點(diǎn)、應(yīng)用環(huán)境等方面進(jìn)行分類(lèi)討論,如圖 2所示。同時(shí),論述了現(xiàn)有模型的局限性,并指出該領(lǐng)域未來(lái)可能的發(fā)展方向。
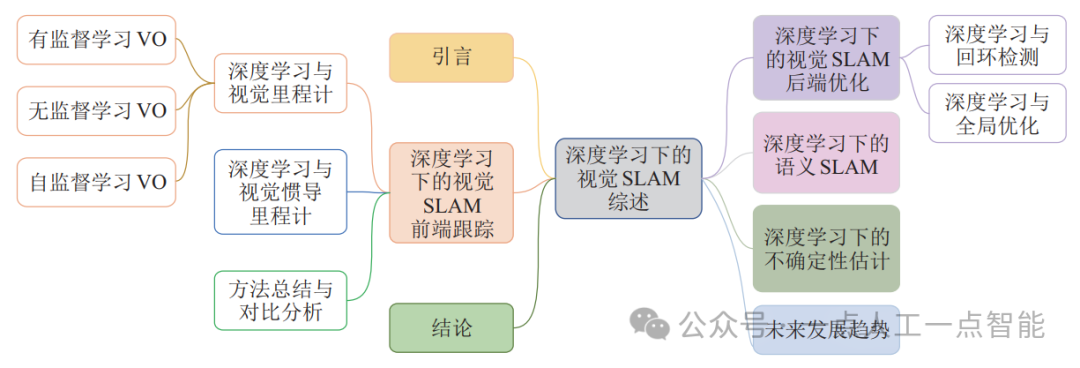
圖2 基于深度學(xué)習(xí)的視覺(jué)SLAM現(xiàn)有方法的分類(lèi)
?
深度學(xué)習(xí)下的視覺(jué)SLAM前端跟蹤
SLAM前端跟蹤也稱(chēng)作視覺(jué)里程計(jì)(VO),可以通過(guò)傳感器獲得的不同幀之間的感知信息估計(jì)出移動(dòng)機(jī)器人的運(yùn)動(dòng)變化[11]。VO估計(jì)最核心的任務(wù)是利用傳感器的測(cè)量數(shù)據(jù)準(zhǔn)確地預(yù)測(cè)移動(dòng)機(jī)器人的運(yùn)動(dòng)并輸出相對(duì)位姿。對(duì)SLAM系統(tǒng)而言,在初始狀態(tài)已知的情況下,可通過(guò)這些相對(duì)位姿重構(gòu)全局軌跡。因此,保證輸出位姿估計(jì)精度是移動(dòng)機(jī)器人實(shí)現(xiàn)高精度定位的關(guān)鍵因素[8]。
2.1 深度學(xué)習(xí)與視覺(jué)里程計(jì)
傳統(tǒng)的VO估計(jì)通常包括相機(jī)標(biāo)定、特征提取、特征匹配/ 跟蹤、異常值剔除、運(yùn)動(dòng)估計(jì)、尺度估計(jì)和局部?jī)?yōu)化幾部分,系統(tǒng)架構(gòu)如圖 3所示[12]。
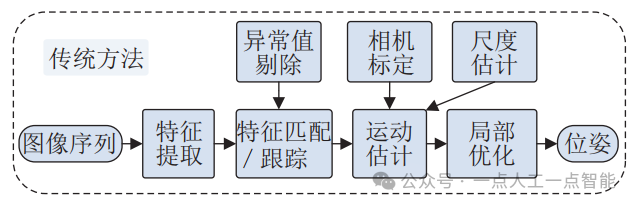
圖3 傳統(tǒng)單目VO的框架圖
卷積神經(jīng)網(wǎng)絡(luò)(CNN或ConvNet)在圖像識(shí)別任務(wù)中獲得的巨大成功,使得利用CNN來(lái)處理VO問(wèn)題成為了可能。和傳統(tǒng)的VO估計(jì)方法相比,深度學(xué)習(xí)方法可以自動(dòng)對(duì)圖像特征進(jìn)行提取,而不需要繁重的人工特征標(biāo)注過(guò)程,使得整個(gè)估計(jì)過(guò)程更加直觀(guān)簡(jiǎn)潔。根據(jù)網(wǎng)絡(luò)的訓(xùn)練方式和數(shù)據(jù)集是否使用標(biāo)簽,本節(jié)主要集中對(duì)有監(jiān)督學(xué)習(xí)(supervised learning)VO、無(wú)監(jiān)督學(xué)習(xí)(unsupervised learning)VO和自監(jiān)督學(xué)習(xí)(self-supervised learning)VO三種情況進(jìn)行討論和總結(jié)。
2.1.1 有監(jiān)督學(xué)習(xí)VO
有監(jiān)督學(xué)習(xí)VO的目的是通過(guò)在標(biāo)記數(shù)據(jù)集上訓(xùn)練一個(gè)深度神經(jīng)網(wǎng)絡(luò)模型,直接構(gòu)造出從連續(xù)圖像到運(yùn)動(dòng)變換的映射函數(shù)。模型的輸入是一對(duì)連續(xù)的圖像,輸出是包含了平移信息和旋轉(zhuǎn)信息的矩陣。
2015年,Konda等[13]?提出了基于端到端的卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)來(lái)預(yù)測(cè)相機(jī)速度和輸入圖像的方向變化的方法,整個(gè)預(yù)測(cè)過(guò)程主要包括圖像序列深度和運(yùn)動(dòng)信息的提取、圖像序列速度和方向變化估計(jì)2個(gè)步驟,是將深度學(xué)習(xí)融入到VO研究領(lǐng)域中最早的研究成果之一。
Costante等[14]?通過(guò)學(xué)習(xí)圖像數(shù)據(jù)的最優(yōu)特征表示,對(duì)視覺(jué)里程計(jì)進(jìn)行了估計(jì)。該方案將稠密光流特征作為CNN網(wǎng)絡(luò)的輸入,探索和設(shè)計(jì)了3種不同的CNN深度網(wǎng)絡(luò)架構(gòu),基于全局特征的CNN-1b、基于局部特征的CNN-4b,以及結(jié)合前2種架構(gòu)的P-CNN。所提方案雖然在應(yīng)對(duì)圖像運(yùn)動(dòng)模糊、光照變化方面具有較強(qiáng)的魯棒性,但當(dāng)圖像序列幀間速度過(guò)快時(shí),算法誤差會(huì)較大,準(zhǔn)確性會(huì)下降。
在有監(jiān)督學(xué)習(xí)VO的模型中,DeepVO[12]?是目前效果最好且應(yīng)用較為廣泛的。該算法采用將ConvNet和遞歸神經(jīng)網(wǎng)絡(luò)(RNN)相結(jié)合的方法來(lái)實(shí)現(xiàn)視覺(jué)里程計(jì)的端到端學(xué)習(xí)。該網(wǎng)絡(luò)的框架如圖 4所示,它不采用傳統(tǒng)VO中的任何模塊,而是直接從一系列原始RGB圖像或視頻中推斷出姿態(tài)。DeepVO框架不僅能通過(guò)CNN自動(dòng)學(xué)習(xí)VO問(wèn)題的有效特征表示,而且能夠利用RNN隱式地學(xué)習(xí)圖像間的內(nèi)在聯(lián)系及動(dòng)力學(xué)關(guān)系。
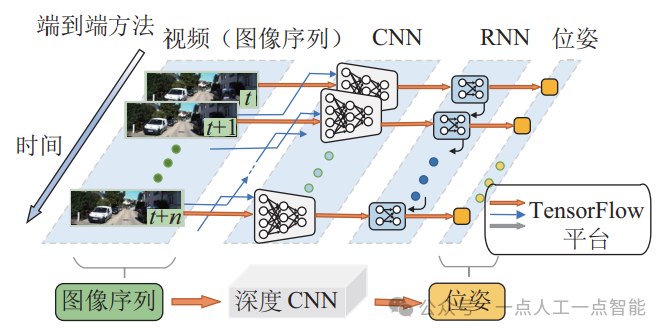
圖4 DeepVO網(wǎng)絡(luò)的框架結(jié)構(gòu)圖
與傳統(tǒng)方法相比,DeepVO模型在精度上沒(méi)有絕對(duì)的優(yōu)勢(shì),但是,因其學(xué)習(xí)的是各幀之間的位姿關(guān)系,具有較好的泛化能力,因而得到了廣泛的關(guān)注。例如,VINet算法[15]和Deep EndoVO算法[16]?等都是在此基礎(chǔ)上進(jìn)行的改進(jìn),并獲得了較好的效果。
隨著研究人員對(duì)高效的小規(guī)模網(wǎng)絡(luò)的深入研究,知識(shí)蒸餾作為一種新興的輕量化小模型,已成為深度學(xué)習(xí)領(lǐng)域又一個(gè)被關(guān)注的重點(diǎn)。2019年,Saputra等[17]?首次利用知識(shí)蒸餾來(lái)預(yù)測(cè)位姿回歸,提出了一種基于對(duì)教師模型結(jié)果的“信任”程度來(lái)附加蒸餾損失的方案。該方法有效地減少了網(wǎng)絡(luò)的參數(shù)量,增強(qiáng)了移動(dòng)機(jī)器人的實(shí)時(shí)操作性。其他相關(guān)方法還有很多,比如,Saputra等[18]?在ICRA會(huì)議上探討了將課程學(xué)習(xí)(curriculum learning,CL)應(yīng)用到復(fù)雜幾何任務(wù)上的問(wèn)題,設(shè)計(jì)了CL-VO網(wǎng)絡(luò)。該網(wǎng)絡(luò)利用新的課程學(xué)習(xí)策略來(lái)學(xué)習(xí)單目視覺(jué)里程計(jì)中的幾何信息,通過(guò)幾何感知目標(biāo)函數(shù),在訓(xùn)練的過(guò)程中逐步提升訓(xùn)練數(shù)據(jù)的復(fù)雜度。
總之,由于機(jī)器學(xué)習(xí)技術(shù)、數(shù)據(jù)存儲(chǔ)量和計(jì)算速度等方面的飛速發(fā)展,這些有監(jiān)督學(xué)習(xí)方法可以從輸入圖像中自動(dòng)獲取相機(jī)的位姿變換,從而解決實(shí)際場(chǎng)景中視覺(jué)里程計(jì)估計(jì)難的問(wèn)題。
2.1.2 無(wú)監(jiān)督學(xué)習(xí)VO
無(wú)監(jiān)督學(xué)習(xí)所學(xué)習(xí)的數(shù)據(jù)不需要標(biāo)注,學(xué)習(xí)的目標(biāo)通常是找出數(shù)據(jù)與數(shù)據(jù)之間的關(guān)系。隨著深度學(xué)習(xí)技術(shù)在計(jì)算機(jī)視覺(jué)領(lǐng)域中的優(yōu)勢(shì)凸顯,人們對(duì)探索無(wú)監(jiān)督學(xué)習(xí)在視覺(jué)里程計(jì)中的應(yīng)用越來(lái)越感興趣,研究者也逐步把側(cè)重點(diǎn)放在了該領(lǐng)域上。
2017年,Godard等[19]?在CVPR會(huì)議上提出了采用無(wú)監(jiān)督學(xué)習(xí)的方法來(lái)進(jìn)行單一圖像的深度估計(jì)。該方法的基本思路是利用圖像的多重目標(biāo)損失來(lái)訓(xùn)練神經(jīng)網(wǎng)絡(luò),使得光度誤差最小化,從而得到很好的視差圖。特別值得注意的是,文[19] 是在已知相機(jī)參數(shù)的情況下進(jìn)行訓(xùn)練的。為了解決相機(jī)參數(shù)未知且左右相機(jī)不在同一個(gè)平面的問(wèn)題,Zhou等[20]?提出了一種既不需要雙目相機(jī),也不用知道相機(jī)參數(shù)的改進(jìn)算法。其核心思想是通過(guò)深度CNN和位姿CNN兩個(gè)網(wǎng)絡(luò)分別生成深度圖和圖像間的位姿,根據(jù)深度圖與位姿將原圖像投射到目標(biāo)圖像上,最后通過(guò)比較真實(shí)目標(biāo)圖像與投射產(chǎn)生的目標(biāo)圖像的重建誤差來(lái)訓(xùn)練網(wǎng)絡(luò)。該學(xué)習(xí)方式在網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)、初始值設(shè)定和訓(xùn)練方法上都采用了較為合適的策略,是目前效果最好的無(wú)監(jiān)督學(xué)習(xí)方法之一。然而在文獻(xiàn)中,作者提到還存在幾個(gè)尚待解決的問(wèn)題:1) 該方法存在絕對(duì)尺度問(wèn)題。由于文中的深度預(yù)測(cè)不夠完整,因而無(wú)法重建環(huán)境的全局軌跡,降低了其在全局范圍內(nèi)定位的精度。2) 文中的光度一致性計(jì)算沒(méi)有考慮實(shí)際場(chǎng)景中可能出現(xiàn)的物體移動(dòng)和遮擋。
對(duì)于上述尺度一致性問(wèn)題,學(xué)者們進(jìn)行了討論和研究,并提出了許多不同的改進(jìn)方案[21-23]。例如,Li等[21]?在文[20] 的基礎(chǔ)上作了相應(yīng)的改進(jìn),提出一種基于無(wú)監(jiān)督學(xué)習(xí)方法來(lái)得到相機(jī)位姿絕對(duì)尺度的單目視覺(jué)里程計(jì)估計(jì)網(wǎng)絡(luò)UnDeepVO。該方法通過(guò)左右圖像分別估計(jì)出相機(jī)左右序列的位姿值和深度值,然后再利用輸入的立體圖像對(duì)得到真實(shí)尺度的深度圖,與大多數(shù)單目無(wú)監(jiān)督的學(xué)習(xí)方案相比,該方法能夠真實(shí)地恢復(fù)相機(jī)位姿的尺度。文[22] 提出利用幾何一致性損失函數(shù)來(lái)滿(mǎn)足深度估計(jì)和位姿估計(jì)之間的尺度一致性約束。該方法將預(yù)測(cè)的圖像深度圖轉(zhuǎn)換到3D空間,然后將局部深度重投影作為損失函數(shù),以此來(lái)保持深度預(yù)測(cè)的尺度一致性,從而保持位姿估計(jì)的尺度一致性。
在改善位姿估計(jì)精度方面,Yin等[24]?提出了一種可以聯(lián)合學(xué)習(xí)單目深度、光流和相機(jī)姿態(tài)的GeoNet無(wú)監(jiān)督網(wǎng)絡(luò)學(xué)習(xí)框架。該學(xué)習(xí)過(guò)程通過(guò)剛性結(jié)構(gòu)重建器和非剛性運(yùn)動(dòng)定位器2個(gè)子任務(wù),分別學(xué)習(xí)剛性流和目標(biāo)物體的運(yùn)動(dòng)。除此之外,GeoNet還引入了自適應(yīng)幾何一致性損失,增強(qiáng)了對(duì)相機(jī)遮擋和非朗伯區(qū)域的異常值的魯棒性,提升了相機(jī)位姿估計(jì)的精度。此外,Zhao等[25]?同樣也在改善位姿估計(jì)精度方面進(jìn)行了改進(jìn)和擴(kuò)展。
自2014年Goodfellow等[26]?提出生成式對(duì)抗網(wǎng)絡(luò)(GAN)以來(lái),由于其強(qiáng)大的生成能力,該方法在計(jì)算機(jī)視覺(jué)、自然語(yǔ)言處理等領(lǐng)域越來(lái)越受到學(xué)術(shù)界和工業(yè)界的重視。GANVO算法[27]?正是在GAN基礎(chǔ)上提出的一種生成式無(wú)監(jiān)督學(xué)習(xí)框架,該算法通過(guò)在單目VO中使用生成式對(duì)抗神經(jīng)網(wǎng)絡(luò)和循環(huán)無(wú)監(jiān)督學(xué)習(xí)方法來(lái)預(yù)測(cè)相機(jī)運(yùn)動(dòng)姿態(tài)和單目深度圖。SGANVO(疊加生成式對(duì)抗網(wǎng)絡(luò))[28]?是繼GANVO之后出現(xiàn)的一種改進(jìn)算法,其整體是由一堆GAN層堆疊組成。系統(tǒng)在對(duì)抗性學(xué)習(xí)過(guò)程中進(jìn)行深度估計(jì)和自我運(yùn)動(dòng)預(yù)測(cè),并對(duì)算法的前、后層網(wǎng)絡(luò)進(jìn)行遞歸表示,從而有效地捕捉各層的時(shí)間動(dòng)態(tài)特征。SGANVO通過(guò)增加網(wǎng)絡(luò)層數(shù)的方式,使得深度估計(jì)效果得到了很大的改善。
傳統(tǒng)的無(wú)監(jiān)督深度估計(jì)需要利用雙目圖片進(jìn)行自監(jiān)督,而文[29] 提出的SfM-Net網(wǎng)絡(luò)卻只需要單目的視頻流就能恢復(fù)深度圖和相機(jī)位姿的估計(jì)。首先,通過(guò)輸入的單個(gè)圖像生成對(duì)應(yīng)深度圖像;然后,融合生成深度點(diǎn)云;最后,通過(guò)輸入連續(xù)兩幀的圖像計(jì)算輸出圖像間的位姿關(guān)系,識(shí)別并分割出(以掩模的形式)場(chǎng)景中的運(yùn)動(dòng)物體。
相比于有監(jiān)督學(xué)習(xí)VO,無(wú)監(jiān)督學(xué)習(xí)VO學(xué)習(xí)到的特征更加具有適應(yīng)性和豐富性,因此,在性能上雖然與前者還有一定差距,但其在提供未知場(chǎng)景位姿信息方面具有更佳的可拓展性和可解釋性。
2.1.3 自監(jiān)督學(xué)習(xí)VO
在傳統(tǒng)的VO中,想要獲得場(chǎng)景像素點(diǎn)的深度真值比較困難,而自監(jiān)督學(xué)習(xí)方法集成了深度學(xué)習(xí)框架和經(jīng)典的幾何模型,給這一難題指明了方向。
第一種自監(jiān)督學(xué)習(xí)法是以立體相機(jī)拍攝的圖像對(duì)作為訓(xùn)練樣本,根據(jù)視差與場(chǎng)景深度的關(guān)系,預(yù)測(cè)出目標(biāo)圖像的視差圖,并轉(zhuǎn)換為深度圖[30-32]。如,文[30] 提出用立體圖像作為訓(xùn)練網(wǎng)絡(luò)的輸入,以自監(jiān)督的方式在圖像對(duì)上進(jìn)行模型訓(xùn)練。文中以左右視差之間的雙循環(huán)一致性作為目標(biāo)函數(shù),同時(shí)引入自適應(yīng)正則化損失函數(shù),以此排除立體圖像中的遮擋區(qū)域。Godard等[19]?使用單個(gè)圖像作為卷積神經(jīng)網(wǎng)絡(luò)的輸入,在全局范圍內(nèi)預(yù)測(cè)得到每個(gè)像素的場(chǎng)景深度;然后利用左右圖像一致性損失,增強(qiáng)左右視差圖的一致性,可以使結(jié)果更準(zhǔn)確。此外,Chen等[31]?和Choi等[32]?從訓(xùn)練策略著手,基于雙目深度估計(jì)的結(jié)果來(lái)估計(jì)單目圖像的深度。通過(guò)這種方式獲得的網(wǎng)絡(luò)模型可以獲得最佳性能。
另一種基于自監(jiān)督估計(jì)深度的思路是將視頻序列中的連續(xù)幀作為訓(xùn)練樣本[33-37]。由于連續(xù)幀之間的相機(jī)運(yùn)動(dòng)是未知的,因此,該方法既要估計(jì)目標(biāo)圖像的深度,還需要預(yù)測(cè)相機(jī)位姿。倫敦大學(xué)Godard等[33]?利用深度估計(jì)和姿態(tài)估計(jì)網(wǎng)絡(luò)得到圖像的逆深度估計(jì)和相機(jī)位姿估計(jì),然后把相機(jī)位姿與視差計(jì)算的光度投影誤差作為損失函數(shù),利用梯度下降這種優(yōu)化方法對(duì)損失函數(shù)中的每個(gè)誤差進(jìn)行優(yōu)化或更新,以此來(lái)提升算法處理遮擋場(chǎng)景的魯棒性。Li等[34]?利用連續(xù)幀之間的時(shí)序約束進(jìn)行自監(jiān)督學(xué)習(xí),該算法將自監(jiān)督學(xué)習(xí)VO表示為一個(gè)序列學(xué)習(xí)問(wèn)題,將幀間相關(guān)性表示為一個(gè)壓縮碼,并通過(guò)長(zhǎng)短期記憶(LSTM)網(wǎng)絡(luò)來(lái)集成序列信息。通過(guò)對(duì)抗學(xué)習(xí)這種方法,很好地解決了位姿估計(jì)過(guò)程中造成的誤差積累,給系統(tǒng)后端提供了更精確的深度和更準(zhǔn)確的位姿估計(jì)。Zhan等[36]?將學(xué)習(xí)到的深度和光流預(yù)測(cè)整合到傳統(tǒng)的VO測(cè)量模型中,獲得了比其他算法更具競(jìng)爭(zhēng)力的性能表現(xiàn)。此外,Li等[37]?提出了基于元學(xué)習(xí)的在線(xiàn)自監(jiān)督學(xué)習(xí)方法。
研究表明,與傳統(tǒng)的單目VO或視覺(jué)慣導(dǎo)里程計(jì)相比,將深度學(xué)習(xí)與傳統(tǒng)方法相結(jié)合的自監(jiān)督方法在性能上更加優(yōu)越[38]。這一結(jié)論從側(cè)面說(shuō)明了自監(jiān)督領(lǐng)域發(fā)展的巨大潛力和無(wú)限可能。
2.2 深度學(xué)習(xí)與視覺(jué)慣導(dǎo)里程計(jì)
高精度的導(dǎo)航和定位是自動(dòng)駕駛汽車(chē)的核心技術(shù)之一。傳統(tǒng)的視覺(jué)里程計(jì)方法由于遮擋、尺度不確定性、相對(duì)位置偏移和低幀率等一系列問(wèn)題,很難達(dá)到實(shí)際場(chǎng)景的應(yīng)用需求;相比而言,慣性測(cè)量單元(IMU)定位設(shè)備價(jià)格低廉,可以直接獲得運(yùn)動(dòng)主體的角速度和加速度的測(cè)量數(shù)據(jù),達(dá)到理想的定位效果。因此,為了提升導(dǎo)航定位系統(tǒng)的精度和穩(wěn)定性,在傳統(tǒng)的VO中融入慣性信息是行之有效的方案,并已取得了一定成果[39-41]。
深度學(xué)習(xí)是一種端到端的學(xué)習(xí)方式,在模型訓(xùn)練時(shí)直接學(xué)習(xí)從輸入的原始數(shù)據(jù)到期望輸出的映射。與傳統(tǒng)方法相比,基于深度學(xué)習(xí)的視覺(jué)慣性里程計(jì)(VIO)方法最大的優(yōu)點(diǎn)是無(wú)需手動(dòng)提取特征,完全依靠數(shù)據(jù)驅(qū)動(dòng),能利用數(shù)據(jù)本身蘊(yùn)含的信息實(shí)現(xiàn)深度預(yù)測(cè)。近年來(lái),對(duì)該領(lǐng)域的探索與研究開(kāi)始引起許多研究者的關(guān)注。
VINet網(wǎng)絡(luò)[15]?首次提出結(jié)合IMU的信息,通過(guò)深度神經(jīng)網(wǎng)絡(luò)的框架來(lái)解決VIO的問(wèn)題。整個(gè)VINet網(wǎng)絡(luò)利用CNN網(wǎng)絡(luò)從2個(gè)相鄰幀圖像中提取視覺(jué)運(yùn)動(dòng)特征,同時(shí)使用LSTM網(wǎng)絡(luò)來(lái)建模IMU的慣導(dǎo)特征。然后利用特殊歐氏群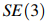 把視覺(jué)運(yùn)動(dòng)特征和慣導(dǎo)特征進(jìn)行結(jié)合,以此實(shí)現(xiàn)對(duì)相機(jī)位姿的預(yù)測(cè)。通過(guò)VINet方法,既減少了對(duì)手動(dòng)同步和校準(zhǔn)的依賴(lài),同時(shí)在同步誤差方面也表現(xiàn)出了更強(qiáng)的魯棒性。
把視覺(jué)運(yùn)動(dòng)特征和慣導(dǎo)特征進(jìn)行結(jié)合,以此實(shí)現(xiàn)對(duì)相機(jī)位姿的預(yù)測(cè)。通過(guò)VINet方法,既減少了對(duì)手動(dòng)同步和校準(zhǔn)的依賴(lài),同時(shí)在同步誤差方面也表現(xiàn)出了更強(qiáng)的魯棒性。
文[42] 利用在線(xiàn)糾錯(cuò)OEC模塊進(jìn)行了VIO無(wú)監(jiān)督網(wǎng)絡(luò)學(xué)習(xí)方法的設(shè)計(jì)。該方法在沒(méi)有慣性測(cè)量單元內(nèi)在參數(shù)或缺失IMU和相機(jī)之間的外部校準(zhǔn)的情況下,將RGB-D圖像與慣性測(cè)量直接相結(jié)合,根據(jù)像素的縮放圖像投影誤差的雅可比行列式生成相機(jī)運(yùn)動(dòng)的估計(jì)軌跡。DeepVIO是Han等[43]?提出的一種端到端自監(jiān)督深度學(xué)習(xí)網(wǎng)絡(luò)框架,該框架主要使用雙目序列來(lái)估計(jì)每個(gè)場(chǎng)景的深度和密集的3D幾何約束并作為監(jiān)督信號(hào),結(jié)合IMU數(shù)據(jù)來(lái)獲取絕對(duì)軌跡估計(jì)值。與傳統(tǒng)方法相比,DeepVIO減少了相機(jī)與IMU之間校準(zhǔn)不正確、數(shù)據(jù)不同步和丟失的影響,與其他基于VO和VIO系統(tǒng)的最新學(xué)習(xí)方法相比,該算法在準(zhǔn)確性和數(shù)據(jù)適應(yīng)性方面的表現(xiàn)也更為突出。
基于深度學(xué)習(xí)的視覺(jué)慣性里程計(jì)方法已經(jīng)被證明是成功的,然而,這些方法在設(shè)計(jì)過(guò)程中并沒(méi)有完全解決多傳感數(shù)據(jù)的魯棒融合策略問(wèn)題。針對(duì)這一問(wèn)題,Chen等[44]?提出一種新的單目端到端VIO多傳感器選擇融合策略。該策略融合了單目圖像和慣性測(cè)量單元,根據(jù)外部環(huán)境和內(nèi)部傳感器的動(dòng)態(tài)數(shù)據(jù)來(lái)估計(jì)運(yùn)動(dòng)軌跡,提高了對(duì)應(yīng)用場(chǎng)景的魯棒性。此外,還提出了不同掩碼策略下的融合網(wǎng)絡(luò)模式,在數(shù)據(jù)損壞的情況下,該融合策略表現(xiàn)出更優(yōu)的性能。
在很多室內(nèi)和室外場(chǎng)景中,面對(duì)不同的場(chǎng)景尺度因子,單目的SLAM系統(tǒng)需要對(duì)相機(jī)和IMU之間的空間變換和時(shí)間偏移進(jìn)行標(biāo)定。對(duì)這一限制問(wèn)題,Lee等[45]?利用光流神經(jīng)網(wǎng)絡(luò)的思想,以連續(xù)的2個(gè)相鄰幀作為網(wǎng)絡(luò)的輸入,提出了一種不需要標(biāo)定的VIO學(xué)習(xí)框架,該方法適用于計(jì)算能力不高且需要實(shí)時(shí)處理信息的VIO系統(tǒng)。為了解決單目視覺(jué)SLAM系統(tǒng)實(shí)時(shí)重構(gòu)真實(shí)尺度場(chǎng)景困難的問(wèn)題,浙江大學(xué)左星星博士提出了一種實(shí)時(shí)的CodeVIO方法[46],采用一種新的、實(shí)時(shí)的單目相機(jī)慣導(dǎo)定位與稠密深度圖重建的策略。該策略結(jié)合了深度神經(jīng)網(wǎng)絡(luò)與傳統(tǒng)的狀態(tài)估計(jì)器,利用輕量級(jí)的條件變分自動(dòng)編碼器(conditional variational autoencoder,CVAE),把高維度的稠密深度圖在神經(jīng)網(wǎng)絡(luò)中編碼為低維度的深度碼,以增加稠密深度估計(jì)的準(zhǔn)確性。CodeVIO方法一方面利用VIO稀疏深度圖的信息,以稀疏視覺(jué)特征點(diǎn)的深度作為神經(jīng)網(wǎng)絡(luò)的輸入;另一方面使用了一種高效的網(wǎng)絡(luò)雅可比矩陣計(jì)算方法,使網(wǎng)絡(luò)在實(shí)時(shí)單線(xiàn)程運(yùn)行的同時(shí),具有了很強(qiáng)的泛化能力和高了一個(gè)數(shù)量級(jí)的計(jì)算效率。
此外,Liu等[47]?提出InertialNet網(wǎng)絡(luò),訓(xùn)練端到端模型來(lái)推導(dǎo)圖像序列和IMU信息之間的聯(lián)系,預(yù)測(cè)相機(jī)旋轉(zhuǎn)角度。Kim等[48]?將不確定性建模引入無(wú)監(jiān)督的損失函數(shù)中,在不需要用真值協(xié)方差作為標(biāo)簽的情況下學(xué)習(xí)多傳感器間深度與位姿的不確定性。通過(guò)這種方法,克服了學(xué)習(xí)單個(gè)傳感器時(shí)的不確定性和局限性。文[49] 提出了一種新的基于深度學(xué)習(xí)模型的相機(jī)和IMU傳感器融合的算法,以預(yù)測(cè)無(wú)人機(jī)系統(tǒng)的3D運(yùn)動(dòng)。
2.3 方法總結(jié)與對(duì)比分析
近年來(lái),結(jié)合深度學(xué)習(xí)的視覺(jué)SLAM方法越來(lái)越受到研究者的高度關(guān)注。現(xiàn)有基于深度學(xué)習(xí)的VO估計(jì)方法的性能對(duì)比如表 1所示。由于各算法的測(cè)試數(shù)據(jù)集和評(píng)估性能各有差異,難以對(duì)算法性能進(jìn)行精確對(duì)比,因此表中僅列出了各算法在特定測(cè)試條件下的定位誤差作為參考指標(biāo)。特別強(qiáng)調(diào),表中所列誤差的性能指標(biāo)值越小,說(shuō)明算法的尺度一致性越佳,定位越準(zhǔn)確。
表1 現(xiàn)有基于深度學(xué)習(xí)的VO估計(jì)方法的性能對(duì)比
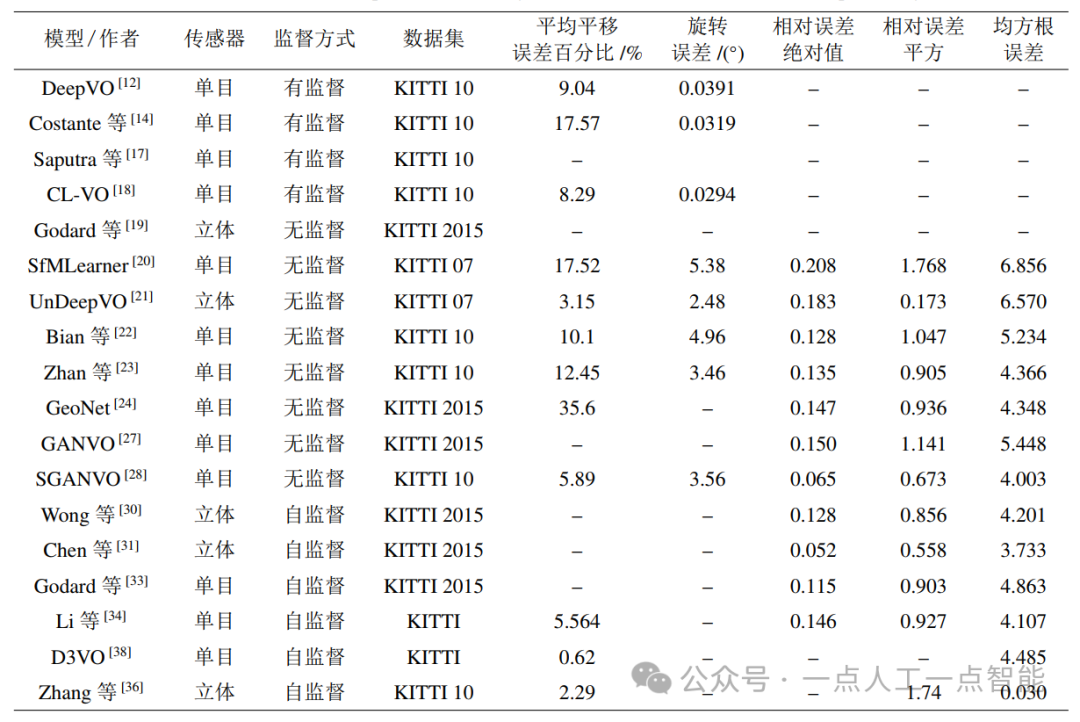
結(jié)合表 1性能,從現(xiàn)有的成果來(lái)看,深度學(xué)習(xí)在SLAM領(lǐng)域取得了一定的成果。與無(wú)監(jiān)督學(xué)習(xí)方法相比,有監(jiān)督學(xué)習(xí)方法表現(xiàn)出的尺度漂移誤差更小、跟蹤魯棒性更佳。從算法的深度估計(jì)結(jié)果來(lái)說(shuō),目前提出的基于無(wú)監(jiān)督/ 自監(jiān)督的VO算法都能達(dá)到較好的預(yù)測(cè)效果。
值得一提的是,無(wú)監(jiān)督學(xué)習(xí)是通過(guò)學(xué)習(xí)數(shù)據(jù)之間的規(guī)律來(lái)提取輸入圖像的特征,因此,能學(xué)習(xí)到更加豐富多樣的圖像特征表征,在未知的場(chǎng)景下具有更佳的適應(yīng)性和泛化能力。
自監(jiān)督學(xué)習(xí)方法既保留了傳統(tǒng)算法的特點(diǎn),又融合了深度學(xué)習(xí)的優(yōu)勢(shì),能夠較好地恢復(fù)場(chǎng)景的尺度,與無(wú)監(jiān)督學(xué)習(xí)相比,具有更大的優(yōu)勢(shì)。如,自監(jiān)督模型D3VO方法[38]?的跟蹤精度甚至超過(guò)了現(xiàn)有的單目深度視覺(jué)里程計(jì)或視覺(jué)慣導(dǎo)里程計(jì)系統(tǒng)。當(dāng)然,在特定限制的任務(wù)環(huán)境中,具體可以采用哪種學(xué)習(xí)方式還需要根據(jù)具體情況來(lái)決定。
近年來(lái),將慣性單元數(shù)據(jù)與相機(jī)的地標(biāo)信息進(jìn)行融合已成為構(gòu)建高精度、高魯棒SLAM系統(tǒng)的重要途徑。部分現(xiàn)有基于視覺(jué)/ 慣性融合的視覺(jué)SLAM算法的總結(jié)如表 2所示。表 2中,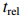 表示平均平移誤差百分比,ATE表示絕對(duì)軌跡誤差,RE表示旋轉(zhuǎn)誤差,RMSE表示均方根誤差。不難看出,基于學(xué)習(xí)的VIO的研究雖然才起步,但與傳統(tǒng)的SLAM系統(tǒng)相比,其在定位精度、尺度一致性以及生成運(yùn)動(dòng)軌跡等方面的能力很突出。另外,IMU和相機(jī)之間具有較強(qiáng)的互補(bǔ)性,將兩者進(jìn)行融合是提升SLAM系統(tǒng)精度和魯棒性的重要途徑。
表示平均平移誤差百分比,ATE表示絕對(duì)軌跡誤差,RE表示旋轉(zhuǎn)誤差,RMSE表示均方根誤差。不難看出,基于學(xué)習(xí)的VIO的研究雖然才起步,但與傳統(tǒng)的SLAM系統(tǒng)相比,其在定位精度、尺度一致性以及生成運(yùn)動(dòng)軌跡等方面的能力很突出。另外,IMU和相機(jī)之間具有較強(qiáng)的互補(bǔ)性,將兩者進(jìn)行融合是提升SLAM系統(tǒng)精度和魯棒性的重要途徑。
表2 現(xiàn)有視覺(jué)慣導(dǎo)里程計(jì)融合算法的簡(jiǎn)要比較

綜上所述,深度學(xué)習(xí)在SLAM領(lǐng)域中的實(shí)際應(yīng)用效果雖然還不是很理想,但是隨著深度學(xué)習(xí)研究的深入,該領(lǐng)域已成為近年來(lái)的研究熱門(mén)。
?
深度學(xué)習(xí)下的視覺(jué)SLAM后端優(yōu)化
SLAM的后端優(yōu)化主要是對(duì)不同時(shí)刻視覺(jué)里程計(jì)預(yù)測(cè)得到的相機(jī)位姿信息以及局部地圖進(jìn)行優(yōu)化調(diào)整。在VO中,不管是位姿估計(jì)還是建圖,都是利用相鄰幀之間的運(yùn)動(dòng)來(lái)完成的,這容易導(dǎo)致誤差逐幀累積,最終產(chǎn)生較大的累積漂移[11]。在對(duì)這些區(qū)域進(jìn)行地圖重構(gòu)時(shí),將導(dǎo)致與同一區(qū)域已建圖不重合,出現(xiàn)重影現(xiàn)象;同時(shí),也有必要把所有地圖數(shù)據(jù)放到一起再做一次全局的優(yōu)化,以降低系統(tǒng)各部分的誤差,提高系統(tǒng)的準(zhǔn)確性。因此,為了降低誤差漂移對(duì)SLAM系統(tǒng)性能帶來(lái)的影響,后端優(yōu)化就顯得至關(guān)重要。
3.1 深度學(xué)習(xí)與回環(huán)檢測(cè)
在視覺(jué)SLAM領(lǐng)域中,回環(huán)檢測(cè)(loop closure detection)是又一個(gè)值得關(guān)注和研究的熱點(diǎn)問(wèn)題。其主要解決機(jī)器人位姿估計(jì)的累積漂移問(wèn)題,以實(shí)現(xiàn)在大規(guī)模復(fù)雜環(huán)境下的精確導(dǎo)航。準(zhǔn)確的回環(huán)檢測(cè)可以進(jìn)一步優(yōu)化移動(dòng)機(jī)器人的運(yùn)動(dòng)估計(jì),建立全局一致的地圖,反之則可能導(dǎo)致地圖重建失敗。因此,回環(huán)檢測(cè)算法的好壞對(duì)整個(gè)視覺(jué)SLAM系統(tǒng)精度與魯棒性的提升至關(guān)重要[11]。
早期的回環(huán)檢測(cè)方法是手工標(biāo)注特征點(diǎn),應(yīng)用詞袋(BoW)模型來(lái)達(dá)到圖像匹配的目的。隨著深度學(xué)習(xí)、目標(biāo)識(shí)別、語(yǔ)義分割等領(lǐng)域的迅速發(fā)展,研究者更傾向于使用先進(jìn)技術(shù)來(lái)更好地實(shí)現(xiàn)回環(huán)檢測(cè)。2015年,國(guó)防科技大學(xué)張宏等[50]?較早地將深度學(xué)習(xí)應(yīng)用在回環(huán)檢測(cè)中,利用Caffe深度學(xué)習(xí)框架下已經(jīng)提前訓(xùn)練好的AlexNet模型產(chǎn)生一種適合回環(huán)檢測(cè)的描述符。該方法先將圖像輸入到CNN中,以每個(gè)中間層的輸出作為一個(gè)特征值,用來(lái)描述整幅圖像,然后利用二范數(shù)進(jìn)行特征匹配來(lái)確定是否存在回環(huán)。仿真結(jié)果表明在光照變化明顯的環(huán)境下這種深度學(xué)習(xí)的特征描述符比傳統(tǒng)的BoW和隨機(jī)蕨法等方法更穩(wěn)定、魯棒性更強(qiáng),并且產(chǎn)生描述符的用時(shí)更短。
自動(dòng)編碼器是一種無(wú)監(jiān)督學(xué)習(xí)模型,能夠自動(dòng)提取數(shù)據(jù)中的有效特征,具有較強(qiáng)的泛化性。近些年,該方法受到了廣泛的關(guān)注,且已成功應(yīng)用于諸多領(lǐng)域。清華大學(xué)高翔等[51]?提出采用堆疊去噪自動(dòng)編碼器(stacked denoising auto-encoder,SDA)的無(wú)監(jiān)督學(xué)習(xí)方式描述整幅圖像來(lái)進(jìn)行圖像的匹配,最終得到了較好的回環(huán)檢測(cè)效果。此外,如文[52] 也是在自動(dòng)編碼器結(jié)構(gòu)的基礎(chǔ)上,以無(wú)監(jiān)督學(xué)習(xí)的方式壓縮場(chǎng)景數(shù)據(jù)來(lái)提取緊湊的特征表示向量。
隨著CNN訓(xùn)練的飛速發(fā)展,針對(duì)光照變化、天氣變化和物體快速移動(dòng)等復(fù)雜場(chǎng)景,有不少研究者開(kāi)始考慮采用CNN網(wǎng)絡(luò)學(xué)習(xí)特征與人工設(shè)計(jì)特征相結(jié)合的方式進(jìn)行場(chǎng)景識(shí)別。文[53] 在局部特征聚合描述子(VLAD)的基礎(chǔ)上進(jìn)行了擴(kuò)展,提出了一種端對(duì)端的場(chǎng)景識(shí)別NetVLAD算法。此算法將傳統(tǒng)的VLAD結(jié)構(gòu)與CNN網(wǎng)絡(luò)結(jié)構(gòu)相結(jié)合,利用卷積網(wǎng)絡(luò)的反向傳播對(duì)網(wǎng)絡(luò)進(jìn)行算法優(yōu)化,提高了對(duì)同類(lèi)別圖像的表達(dá)能力,同時(shí)大大地提高了圖像的匹配精度。Bampis等[54]?提出了新的回環(huán)檢測(cè)方法,主要通過(guò)旋轉(zhuǎn)不變和尺度不變的局部特征描述向量以及動(dòng)態(tài)序列識(shí)別技術(shù)來(lái)提高系統(tǒng)的性能。除此之外,文中還引入時(shí)間一致性過(guò)濾器來(lái)進(jìn)一步提升所產(chǎn)生序列的相似性度量結(jié)果。參照文[54] 的思路與方法,Memon等[55]?提出了有監(jiān)督學(xué)習(xí)與無(wú)監(jiān)督學(xué)習(xí)相結(jié)合的回環(huán)檢測(cè)方法。文中利用深度學(xué)習(xí)在特征提取方面的優(yōu)勢(shì),引入超級(jí)字典的概念,加快了場(chǎng)景比較的速度。同時(shí),結(jié)合自動(dòng)編碼器對(duì)新場(chǎng)景進(jìn)行回環(huán)檢測(cè),提高了回環(huán)檢測(cè)的效率。
雖然,基于深度學(xué)習(xí)的回環(huán)檢測(cè)方法可以從原始數(shù)據(jù)中自動(dòng)地學(xué)習(xí)特征,能更充分地表達(dá)圖像信息,對(duì)復(fù)雜的環(huán)境變化有更好的適應(yīng)性和更強(qiáng)的魯棒性,但是,如何針對(duì)不同場(chǎng)景自動(dòng)選擇不同隱含層的結(jié)果、如何找到更好的用于場(chǎng)景識(shí)別的特征、如何尋找合適的回環(huán)檢測(cè)的性能評(píng)估基準(zhǔn)等諸多問(wèn)題依然是未來(lái)研究的重點(diǎn)。
3.2?深度學(xué)習(xí)與全局優(yōu)化
SLAM全局優(yōu)化需要考慮的問(wèn)題是如何利用不準(zhǔn)確的關(guān)鍵幀建立起全局約束,以?xún)?yōu)化各幀的相機(jī)位姿。為了實(shí)現(xiàn)全局優(yōu)化,可以通過(guò)建立和優(yōu)化位姿圖來(lái)求解各幀的相機(jī)位姿。位姿圖是以關(guān)鍵幀的全局位姿作為圖的節(jié)點(diǎn),以關(guān)鍵幀之間的相對(duì)位姿誤差作為圖的邊的權(quán)重,通過(guò)令整個(gè)圖的所有邊的權(quán)重值總和最小,來(lái)優(yōu)化得到每個(gè)圖節(jié)點(diǎn)的值。也可通過(guò)另一種目前比較主流的圖優(yōu)化方法來(lái)獲得全局最優(yōu)解。不論是何種優(yōu)化方法,一般采用的求解器都是高斯-牛頓法或LM算法[11]。
深度學(xué)習(xí)的實(shí)質(zhì)是利用觀(guān)察到的相機(jī)位姿和場(chǎng)景表征來(lái)提取圖像特征并構(gòu)建映射函數(shù)。近年來(lái),研究者們針對(duì)如何將深度學(xué)習(xí)融入到全局優(yōu)化問(wèn)題中進(jìn)行了探索與嘗試,獲得了比較好的性能優(yōu)化結(jié)果。文[56] 提出的CNN-SLAM法將CNN預(yù)測(cè)的稠密深度地圖引入到直接單目SLAM法獲得的深度測(cè)量值中,該方法使得SLAM系統(tǒng)在回環(huán)檢測(cè)和圖形優(yōu)化方面具有更強(qiáng)的魯棒性和更高的準(zhǔn)確性。Zhou等[57]?提出了DeepTAM學(xué)習(xí)方法,其核心在于將來(lái)自CNN的相機(jī)位姿和深度估計(jì)引入到經(jīng)典DTAM系統(tǒng)[58]?中,然后通過(guò)后端全局優(yōu)化,來(lái)實(shí)現(xiàn)更精確的相機(jī)位姿估計(jì)和場(chǎng)景重構(gòu)。
基于無(wú)監(jiān)督學(xué)習(xí)的單目視覺(jué)里程計(jì),由于缺少累積誤差的校正技術(shù),在大規(guī)模里程計(jì)估計(jì)方面的精確度達(dá)不到預(yù)期目標(biāo)。針對(duì)這一局限性,Li等[59]?將無(wú)監(jiān)督學(xué)習(xí)的單目VO與圖優(yōu)化后端集成在一起,提出了一種混合的視覺(jué)里程計(jì)系統(tǒng)。以時(shí)間和空間光度損失作為主要監(jiān)督信號(hào),在系統(tǒng)后端,根據(jù)估計(jì)得到的局部閉環(huán)6自由度約束構(gòu)建全局位姿圖并進(jìn)行優(yōu)化,從而改善系統(tǒng)的定位精度和魯棒性。除了文[59] 的方法之外,DeepFactors算法[60]?也值得一提。文[60] 中提出的深度SLAM系統(tǒng)是將學(xué)習(xí)到的稠密地圖與3種不同類(lèi)型的后端概率因子圖相結(jié)合來(lái)實(shí)現(xiàn)的。該系統(tǒng)在概率框架中整合了一致性度量、先驗(yàn)學(xué)習(xí)等算法,在對(duì)位姿和深度變量進(jìn)行聯(lián)合優(yōu)化的同時(shí)還能保持系統(tǒng)的實(shí)時(shí)性能。
目前,深度學(xué)習(xí)方法在全局優(yōu)化中的應(yīng)用處于初步探索階段,隨著各種深入研究的解決方案的提出與實(shí)現(xiàn),深度學(xué)習(xí)在該領(lǐng)域的應(yīng)用將會(huì)引來(lái)更多的關(guān)注。基于深度學(xué)習(xí)的全局優(yōu)化方案也會(huì)得到進(jìn)一步的提升和改進(jìn)。
?
深度學(xué)習(xí)下的語(yǔ)義SLAM
語(yǔ)義SLAM是語(yǔ)義信息和視覺(jué)SLAM的相互融合,其研究的核心就是對(duì)目標(biāo)物體進(jìn)行檢測(cè)與識(shí)別。而深度學(xué)習(xí)算法是當(dāng)前主流的物體識(shí)別算法。因此,在語(yǔ)義SLAM系統(tǒng)中引入深度學(xué)習(xí)成為SLAM系統(tǒng)發(fā)展的必然趨勢(shì)。
而真正意義上的語(yǔ)義SLAM(即語(yǔ)義建圖和SLAM定位相互促進(jìn))發(fā)展相對(duì)較晚。2017年,Bowman等[61]?引入了期望最大值方法來(lái)動(dòng)態(tài)估計(jì)物體與觀(guān)測(cè)的匹配關(guān)系。作者把語(yǔ)義SLAM轉(zhuǎn)換成概率問(wèn)題,利用概率模型計(jì)算出來(lái)的物體中心在圖像上重投影時(shí)應(yīng)該接近檢測(cè)框的中心這一思想來(lái)優(yōu)化重投影誤差。雖然文[61] 解決了語(yǔ)義特征的數(shù)據(jù)關(guān)聯(lián)問(wèn)題和如何用語(yǔ)義信息獲取路標(biāo)和攝像頭位姿的問(wèn)題,但是沒(méi)有考慮語(yǔ)義元素之間的互斥關(guān)系,以及連續(xù)多幀的時(shí)序一致性。Lianos等[62]?提出的視覺(jué)語(yǔ)義里程計(jì)(VSO)方法是在文[61] 的基礎(chǔ)上,使用距離變換將分割結(jié)果的邊緣作為約束,同時(shí)利用投影誤差構(gòu)造約束條件,從而實(shí)現(xiàn)中期連續(xù)點(diǎn)跟蹤。
為了提高語(yǔ)義SLAM系統(tǒng)識(shí)別動(dòng)態(tài)物體的準(zhǔn)確性,清華大學(xué)的Yu等[63]?在2018年IROS會(huì)議上提出了一種動(dòng)態(tài)環(huán)境下魯棒的語(yǔ)義視覺(jué)SLAM系統(tǒng)(DS-SLAM)。在DS-SLAM中,將語(yǔ)義分割網(wǎng)絡(luò)放在一個(gè)單獨(dú)運(yùn)行的線(xiàn)程之中,結(jié)合語(yǔ)義信息和運(yùn)動(dòng)特征點(diǎn)檢測(cè),來(lái)剔除每一幀中的動(dòng)態(tài)物體,從而提高位姿估計(jì)的準(zhǔn)確性和系統(tǒng)運(yùn)行的效率。動(dòng)態(tài)環(huán)境下,此系統(tǒng)降低了對(duì)動(dòng)態(tài)目標(biāo)的影響,極大地提高了定位精度。同時(shí),生成的密集語(yǔ)義八叉樹(shù)地圖可用于執(zhí)行高級(jí)任務(wù)。但此方法要求所使用的語(yǔ)義網(wǎng)絡(luò)運(yùn)行速度足夠快。
Kaneko等[64]?借用語(yǔ)義分割能將圖像中每一類(lèi)物體進(jìn)行分類(lèi)和標(biāo)注這一特點(diǎn),利用語(yǔ)義分割產(chǎn)生的掩模來(lái)排除不可能找到正確對(duì)應(yīng)的區(qū)域。在檢測(cè)特征點(diǎn)階段,添加了“不檢測(cè)掩蔽區(qū)域中的特征點(diǎn)”的操作,可以排除大部分獲得的不準(zhǔn)確的對(duì)應(yīng)關(guān)系,減小了隨機(jī)一致性采樣誤差。該方法引入了語(yǔ)義分割的全局信息,可以彌補(bǔ)視覺(jué)SLAM局部信息的不足,故具有較高的精度。
為了解決實(shí)際應(yīng)用中的動(dòng)態(tài)遮擋問(wèn)題,文[65] 提出了一種新穎的動(dòng)態(tài)分割方法,從而實(shí)現(xiàn)對(duì)相機(jī)自我運(yùn)動(dòng)的準(zhǔn)確跟蹤。該方法首先將語(yǔ)義信息與對(duì)象級(jí)的幾何約束相結(jié)合,快速提取出場(chǎng)景中的靜態(tài)部分,再對(duì)靜態(tài)部分從粗到細(xì)分兩步實(shí)現(xiàn)精確跟蹤。另外,對(duì)動(dòng)態(tài)部分,提出了利用分層次掩碼的動(dòng)態(tài)物體掩碼策略。相比于其他動(dòng)態(tài)視覺(jué)SLAM方法,文[65] 的方法在效率和動(dòng)態(tài)跟蹤精度等方面都有了明顯的提升。
隨著語(yǔ)義分割技術(shù)的發(fā)展,借助語(yǔ)義信息,將數(shù)據(jù)關(guān)聯(lián)升級(jí)到物體級(jí)別,使得提升復(fù)雜場(chǎng)景下的識(shí)別精度成為了可能。目前,有許多研究(如文[66-69])都是基于物體級(jí)別關(guān)聯(lián)的語(yǔ)義SLAM算法。2019年,Yang等[66]?提出用于聯(lián)合估計(jì)相機(jī)位姿和動(dòng)態(tài)物體軌跡的CubeSLAM方法。該算法針對(duì)靜態(tài)物體和動(dòng)態(tài)物體分別采用不同的關(guān)聯(lián)方法:對(duì)于靜態(tài)物體,將SLAM提取到的特征點(diǎn)和2D檢測(cè)框檢測(cè)的對(duì)象關(guān)聯(lián)起來(lái);而對(duì)于動(dòng)態(tài)物體,直接用稀疏光流算法來(lái)跟蹤像素,動(dòng)態(tài)特征的3D位置通過(guò)三角化測(cè)量來(lái)得到。數(shù)據(jù)關(guān)聯(lián)過(guò)程中,采用立方體在地圖中表示物體。除了上述描述,還有學(xué)者提出用橢圓體(特殊雙曲面)來(lái)表示物體[67-68]。但是橢圓體的物體表示只是一種近似,它的檢測(cè)框和實(shí)際測(cè)量的檢測(cè)框不可能完全重合,因此QuadricSLAM算法[67]?對(duì)精度提升并沒(méi)有幫助,但采用CubeSLAM方法對(duì)其精度提升很大。DSP-SLAM算法[69]的基礎(chǔ)框架也是把一個(gè)物體級(jí)的3維重建算法加到一個(gè)傳統(tǒng)SLAM算法中,其數(shù)據(jù)關(guān)聯(lián)還是要用到特征點(diǎn),也是在地圖優(yōu)化中加入物體與相機(jī)以及物體與地圖點(diǎn)的約束。
在復(fù)雜多變的環(huán)境下,基于深度學(xué)習(xí)的語(yǔ)義信息具有光線(xiàn)不變性,因此語(yǔ)義分割下的定位比較穩(wěn)定[70-71]。如,Stenborg等[70]?通過(guò)結(jié)合深度學(xué)習(xí)去解決SLAM中的位置識(shí)別問(wèn)題。其核心思想是在已有3D地圖的基礎(chǔ)上利用圖像語(yǔ)義分割后得到的描述子代替?zhèn)鹘y(tǒng)描述子,然后再去建模,同時(shí)考慮2D點(diǎn)到3D點(diǎn)的映射關(guān)系。
雖然對(duì)語(yǔ)義SLAM已有不少初步探索,但由于其發(fā)展較晚,因此許多工作還僅處于起步階段,很多問(wèn)題還沒(méi)有考慮,但可以預(yù)見(jiàn)未來(lái)幾年這方面的研究會(huì)越來(lái)越多。
?
深度學(xué)習(xí)下的不確定性估計(jì)
盡管深度神經(jīng)網(wǎng)絡(luò)在無(wú)人駕駛車(chē)輛控制或醫(yī)學(xué)圖像分析等高風(fēng)險(xiǎn)領(lǐng)域非常有吸引力,但它們?cè)谥匾暟踩默F(xiàn)實(shí)生活中的應(yīng)用仍然有限。而造成這種限制的主要原因是模型給出的預(yù)測(cè)結(jié)果并不總是可靠的。例如,在無(wú)人駕駛等對(duì)安全性要求較高的領(lǐng)域中,完全依賴(lài)深度模型進(jìn)行決策有可能導(dǎo)致災(zāi)難性的后果。為此,有必要對(duì)基于深度學(xué)習(xí)的移動(dòng)機(jī)器人的不確定性進(jìn)行預(yù)測(cè),以確保安全性。
一般地,模型中預(yù)測(cè)的不確定性大致可分為由模型引起的認(rèn)知不確定性(模型不確定性)和由數(shù)據(jù)引起的任意不確定性(數(shù)據(jù)不確定性)[10]。近年來(lái),很多研究者對(duì)捕捉深度神經(jīng)網(wǎng)絡(luò)(DNN)中的不確定性表現(xiàn)出越來(lái)越大的興趣。貝葉斯模型就是預(yù)測(cè)認(rèn)知不確定性的重要方法之一[72]。該方法使用隨機(jī)失活方法(dropout方法)來(lái)訓(xùn)練DNN,訓(xùn)練得到的均值是預(yù)測(cè)值,而方差就是不確定度。本節(jié)重點(diǎn)討論定位與建圖過(guò)程中的不確定性估計(jì)和運(yùn)動(dòng)跟蹤過(guò)程中的不確定性估計(jì),以及這些不確定性估計(jì)的用途,表 3對(duì)現(xiàn)有的深度學(xué)習(xí)下不確定性估計(jì)算法進(jìn)行了總結(jié)。
表3 現(xiàn)有的深度學(xué)習(xí)下不確定性估計(jì)算法
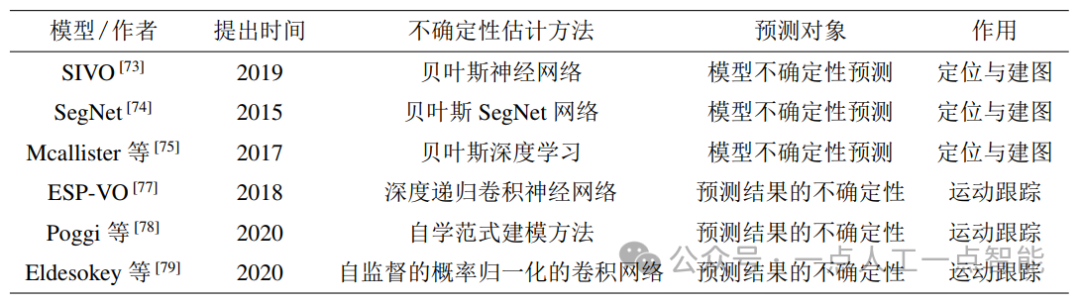
在視覺(jué)SLAM系統(tǒng)中,定位或場(chǎng)景識(shí)別的不確定性是影響系統(tǒng)可信度的重要因素。語(yǔ)義分割是進(jìn)行長(zhǎng)期視覺(jué)定位或者場(chǎng)景理解的重要工具,有意義的不確定性度量對(duì)于決策至關(guān)重要。隨著技術(shù)的發(fā)展,越來(lái)越多的工作對(duì)上述問(wèn)題進(jìn)行了探討(如文[73-76]),并獲得了較理想的性能。
文[73] 提出了一種基于信息理論的視覺(jué)SLAM特征選擇方法SIVO(semantically informed visual odometry and mapping),該方法將語(yǔ)義分割和神經(jīng)網(wǎng)絡(luò)不確定性引入到特征選擇過(guò)程中,利用貝葉斯神經(jīng)網(wǎng)絡(luò)把特征的分類(lèi)熵加到新的特征中,每一個(gè)被選擇的特征都顯著降低了車(chē)輛狀態(tài)的不確定性,并多次被檢測(cè)為靜態(tài)對(duì)象(建筑物、交通標(biāo)志等),且具有較高的置信度。根據(jù)這種選擇策略生成稀疏地圖,可以促進(jìn)長(zhǎng)期定位。
貝葉斯SegNet網(wǎng)絡(luò)[74]?能夠通過(guò)對(duì)場(chǎng)景模型不確定性的度量來(lái)預(yù)測(cè)場(chǎng)景像素級(jí)的不確定性,其核心思想是在SegNet網(wǎng)絡(luò)結(jié)構(gòu)的基礎(chǔ)上增加隨機(jī)失活層與貝葉斯決策。算法通過(guò)多次的前向運(yùn)算得到多個(gè)輸出結(jié)果,對(duì)這些結(jié)果求均值得到最終預(yù)測(cè)的分割結(jié)果;求對(duì)應(yīng)位置像素的方差,得到模型的不確定性圖。此外,該算法還可以使用蒙特卡洛算法來(lái)生成像素類(lèi)標(biāo)簽的后驗(yàn)分布,并在多個(gè)預(yù)測(cè)的結(jié)果中找到最優(yōu)的結(jié)果。
在實(shí)際應(yīng)用中除了需要進(jìn)行模型預(yù)測(cè)之外,也需要預(yù)測(cè)結(jié)果的置信度。利用神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)給定輸入的不確定性估計(jì)已受到越來(lái)越多研究者的重視。2018年,Wang等[77]?從深度學(xué)習(xí)的角度出發(fā)探討了視覺(jué)里程計(jì)估計(jì)的不確定性,針對(duì)基于深度遞歸卷積神經(jīng)網(wǎng)絡(luò)的單目VO,提出了一種端到端的序列間概率視覺(jué)里程計(jì)(ESP-VO)框架。通過(guò)這種方法,在不引入太多額外計(jì)算的情況下,可以有效地預(yù)測(cè)運(yùn)動(dòng)變換的不確定性。為了驗(yàn)證算法的有效性,文[77] 在代表駕駛、飛行和步行情景的幾個(gè)數(shù)據(jù)集上進(jìn)行了廣泛的驗(yàn)證實(shí)驗(yàn)。結(jié)果表明,基于這些最小化誤差函數(shù)進(jìn)行全局優(yōu)化能減少系統(tǒng)的累積漂移,與其他先進(jìn)的方法相比,所提出的ESP-VO具有競(jìng)爭(zhēng)優(yōu)勢(shì)。
鑒于單目自監(jiān)督網(wǎng)絡(luò)在深度估計(jì)時(shí)不需要深度標(biāo)注,因而越來(lái)越多的研究者開(kāi)始致力于理解和量化自監(jiān)督網(wǎng)絡(luò)預(yù)測(cè)中深度不確定性的估計(jì)。2020年,Poggi等[78]?提出了一種新穎的不確定性估計(jì)方法,該方法用到2個(gè)網(wǎng)絡(luò):一個(gè)網(wǎng)絡(luò)用于重建,主要利用翻轉(zhuǎn)圖像輸入的方法和多個(gè)不同的模型對(duì)同一張圖片的深度不確定性進(jìn)行預(yù)測(cè);另一個(gè)網(wǎng)絡(luò)用來(lái)模擬重建網(wǎng)絡(luò)生成的分布,通過(guò)自監(jiān)督的方式學(xué)習(xí)一個(gè)可以預(yù)測(cè)不確定度的模型,其輸出為不確定度。在位姿未知的情況下,該方法可以始終提高深度的估計(jì)準(zhǔn)確度。另外,文[79] 提出一種自監(jiān)督的概率歸一化的卷積網(wǎng)絡(luò),該方法可同時(shí)對(duì)深度與不確定度進(jìn)行預(yù)測(cè)。一方面,對(duì)輸入數(shù)據(jù)的不確定度進(jìn)行估計(jì),使得該網(wǎng)絡(luò)可以基于數(shù)據(jù)可靠性進(jìn)行針對(duì)性的學(xué)習(xí);另一方面,提出概率歸一化的卷積神經(jīng)網(wǎng)絡(luò)(NCNN),將訓(xùn)練過(guò)程轉(zhuǎn)變?yōu)樽畲蠡迫还烙?jì)問(wèn)題,實(shí)現(xiàn)對(duì)輸出不確定度的估計(jì)。
綜上所述,在視覺(jué)SLAM中引入不確定估計(jì)后,可知模型對(duì)于預(yù)測(cè)結(jié)果的置信程度,有助于提高模型在實(shí)際場(chǎng)景環(huán)境中的應(yīng)用性能。但目前關(guān)于該理論的研究才剛剛起步,其學(xué)習(xí)的方法較少,在實(shí)際場(chǎng)景下的適應(yīng)性還有待進(jìn)一步驗(yàn)證。
?
未來(lái)發(fā)展趨勢(shì)
盡管基于深度學(xué)習(xí)的SLAM技術(shù)在精度和魯棒性上已經(jīng)表現(xiàn)出比傳統(tǒng)SLAM方法更優(yōu)的性能,解決方案也變得更有吸引力。但目前的研究仍處于初級(jí)階段,所設(shè)計(jì)的模型還存在不足,故無(wú)法完全解決當(dāng)前的問(wèn)題。為了提高實(shí)際應(yīng)用中的適用性和安全性,研究人員還將面臨許多挑戰(zhàn)。為此,文中討論了幾點(diǎn)可能助力該領(lǐng)域進(jìn)一步發(fā)展的思路。
1) 適應(yīng)性更強(qiáng)的數(shù)據(jù)集標(biāo)注
深度學(xué)習(xí)嚴(yán)重依賴(lài)于海量的數(shù)據(jù),如果想用這些數(shù)據(jù)來(lái)訓(xùn)練深度學(xué)習(xí)的模型,首先需要對(duì)它們進(jìn)行處理與標(biāo)注。從理想的角度看,標(biāo)注的數(shù)據(jù)數(shù)量越多,訓(xùn)練得到的模型效果也會(huì)越好。但是,在實(shí)際標(biāo)注過(guò)程中,不但需要結(jié)合實(shí)際的硬件資源與時(shí)間,還需要注意數(shù)據(jù)量的增大給模型效果提升帶來(lái)的負(fù)面影響。數(shù)據(jù)標(biāo)注的質(zhì)量將直接影響訓(xùn)練得到的深度學(xué)習(xí)模型的可靠性。
綜上所述,提高數(shù)據(jù)標(biāo)注的質(zhì)量也成為了該領(lǐng)域的研究重點(diǎn)。數(shù)據(jù)標(biāo)注是一個(gè)耗費(fèi)成本與時(shí)間的過(guò)程,經(jīng)濟(jì)、高效地完成數(shù)據(jù)標(biāo)注,這是研究人員必須面對(duì)和解決的難題。如何在成本與質(zhì)量這兩者之間找到一個(gè)平衡就顯得尤為重要。同時(shí),期望未來(lái)能夠利用SLAM方法來(lái)構(gòu)建圖像之間存在對(duì)應(yīng)關(guān)系的大規(guī)模的數(shù)據(jù)集,這可能有助于解決數(shù)據(jù)標(biāo)注問(wèn)題。
2) 深度學(xué)習(xí)模型的拓展
目前,許多基于深度學(xué)習(xí)的模型,如卷積神經(jīng)網(wǎng)絡(luò)、長(zhǎng)短期記憶網(wǎng)絡(luò)和自動(dòng)編碼器等都是端到端的學(xué)習(xí)方式。盡管這些模型的快速發(fā)展提升了系統(tǒng)的魯棒性和準(zhǔn)確性,但在實(shí)際應(yīng)用場(chǎng)景中,許多數(shù)據(jù)是從非歐氏空間生成的,而傳統(tǒng)的端到端的深度學(xué)習(xí)方法對(duì)此類(lèi)數(shù)據(jù)的處理能力卻難以使人滿(mǎn)意。
近幾年,越來(lái)越多的學(xué)者對(duì)深度學(xué)習(xí)方法在圖數(shù)據(jù)上的擴(kuò)展產(chǎn)生了濃厚的興趣。用于處理圖數(shù)據(jù)的圖神經(jīng)網(wǎng)絡(luò)(graph neural network)[80]?由此應(yīng)運(yùn)而生。從本質(zhì)上講,圖神經(jīng)網(wǎng)絡(luò)是幾何深度學(xué)習(xí)的一部分,主要是將端到端學(xué)習(xí)與歸納推理相結(jié)合,研究具有結(jié)構(gòu)屬性、拓?fù)湫再|(zhì)的數(shù)據(jù)的學(xué)習(xí)和預(yù)測(cè)任務(wù)。因此,對(duì)于圖神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的深入研究有助于解決深度學(xué)習(xí)無(wú)法處理的關(guān)系推理和組合泛化的問(wèn)題,是未來(lái)一個(gè)新的研究熱點(diǎn)。
3) 多傳感器融合算法的研究
在現(xiàn)實(shí)生活中,移動(dòng)機(jī)器人或硬件設(shè)備往往不僅僅只攜帶一種傳感器,而是多種傳感器相互配合使用。不同傳感器的最遠(yuǎn)探測(cè)距離、精度、功能等各不相同,因此在使用多種傳感器的情況下,要想保證系統(tǒng)決策的可靠性和快速性,就必須對(duì)傳感器進(jìn)行信息融合。例如,手機(jī)VIO系統(tǒng)就是通過(guò)融合IMU數(shù)據(jù)和相機(jī)信息,彌補(bǔ)了單一傳感器的不足,為實(shí)現(xiàn)SLAM的小型化和低成本提供了行之有效的研究方向。DeLS-3D設(shè)計(jì)[81]?融合了相機(jī)視頻、運(yùn)動(dòng)傳感器(GPS/IMU)等數(shù)據(jù)和3維語(yǔ)義地圖,可以提升SLAM系統(tǒng)的魯棒性和效率。上述例子表明,將多種具有互補(bǔ)性的傳感器進(jìn)行融合是提升SLAM系統(tǒng)精度和魯棒性的重要途徑。
多傳感器融合的軟硬件難以分離。當(dāng)前,在硬件層面實(shí)現(xiàn)多傳感器融合并不難,重點(diǎn)和難點(diǎn)在于如何實(shí)現(xiàn)算法和傳感器之間的融合。另外,動(dòng)態(tài)與未知環(huán)境下的融合問(wèn)題也將是多傳感器融合面臨的另一個(gè)難題。相信隨著技術(shù)的不斷發(fā)展,算法融合問(wèn)題將會(huì)得到很好的解決,多傳感器融合技術(shù)也許很快就會(huì)在實(shí)際生活中得到廣泛應(yīng)用。
?
結(jié)論
從已有的大量研究可以看出,基于深度學(xué)習(xí)的SLAM方法雖然是一個(gè)剛起步且在不斷發(fā)展的研究領(lǐng)域,但是已逐漸引起了研究者的廣泛關(guān)注。
到目前為止,深度學(xué)習(xí)與SLAM的結(jié)合已經(jīng)在視覺(jué)里程計(jì)、場(chǎng)景識(shí)別與全局優(yōu)化等各種任務(wù)中取得了顯著的成果。同時(shí),由于深度神經(jīng)網(wǎng)絡(luò)具有強(qiáng)大的非線(xiàn)性擬合能力,可以任意逼近人工建模難以模擬的非線(xiàn)性函數(shù),因此在實(shí)際應(yīng)用中魯棒性更佳。
此外,語(yǔ)義信息與傳統(tǒng)視覺(jué)SLAM算法的集成有助于提高對(duì)圖像特征的理解,對(duì)構(gòu)建高精度的語(yǔ)義圖也產(chǎn)生了重要影響。基于深度學(xué)習(xí)的SLAM技術(shù)的快速發(fā)展為移動(dòng)機(jī)器人向?qū)嵱没⑾盗谢?a href="http://www.nxhydt.com/v/" target="_blank">智能化發(fā)展提供了助力。
審核編輯:黃飛
?




















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論