 電子發燒友App
電子發燒友App


作者:陳珍 伍雅樂
背景
2022年11月30日,OpenAI發布了一款具有多種能力的通用大模型ChatGPT,開啟了人工智能新時代的序幕。
2023年7月,OpenAI發布公告稱給ChatGPT加了一個名為Custom instructions的新功能,使機器人更具有個性化特色的同時,更好地貼近使用者的需求。同時,安卓版ChatGPT也于7月25日正式上線。
2023年11月,OpenAI前總裁兼董事長Greg Brockman宣布,所有用戶均可使用其語音功能ChatGPT Voice。2024年4月1日,OpenAI宣布,將允許用戶直接使用ChatGPT,而無需注冊該項服務。
ChatGPT:我是什么?
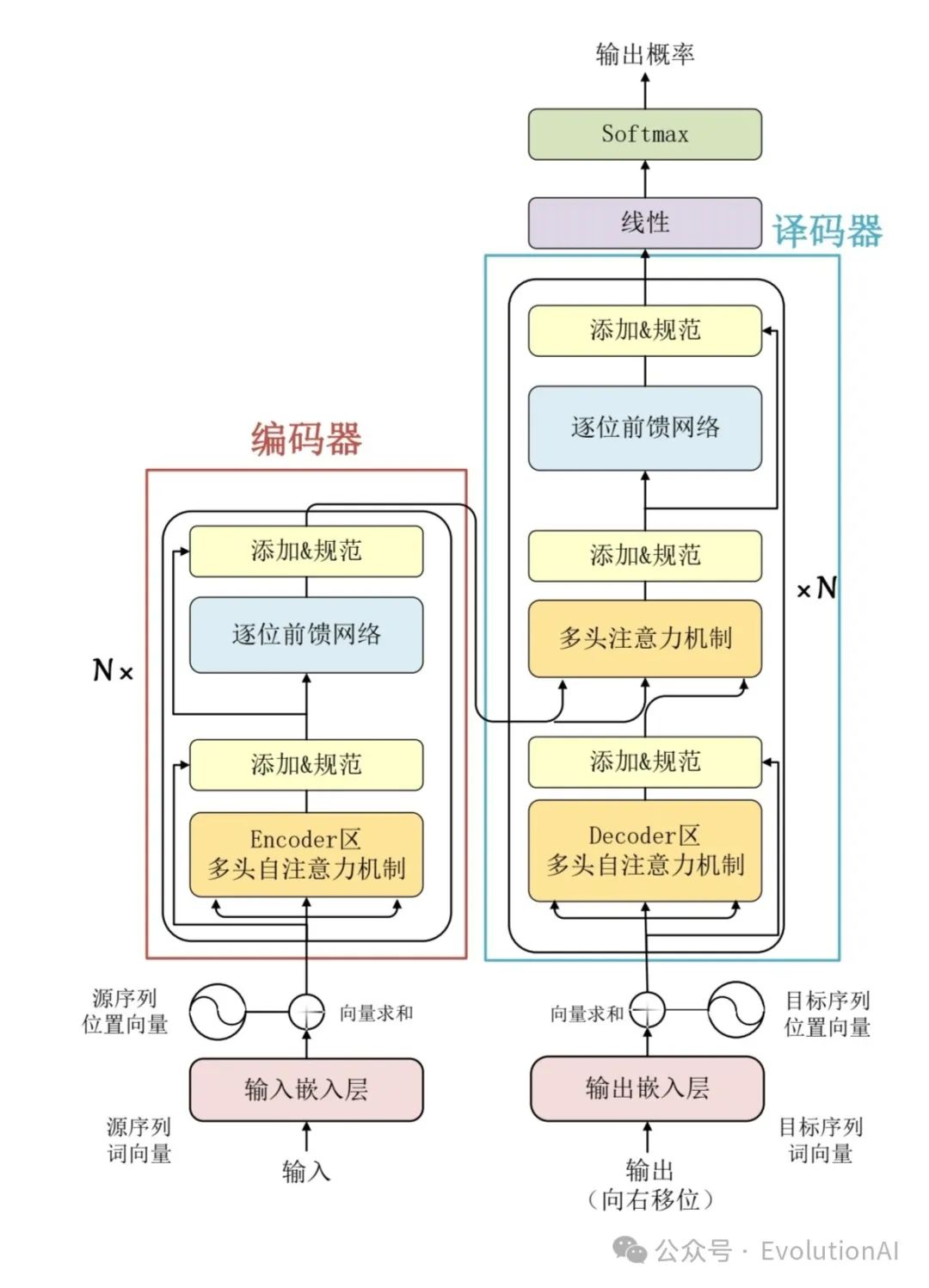
ChatGPT是一款由OpenAI公司開發的人工智能技術驅動的自然語言處理工具。它建立在先進的深度學習模型之上,特別是Transformer模型,采用了自注意力機制來捕捉輸入文本中的長距離依賴關系,并通過多層編碼器-解碼器結構來實現輸入到輸出的映射,使得模型能夠逐步捕捉和理解輸入序列中的復雜關系,并生成更加準確和自然的回復。ChatGPT不僅能夠回答各種問題,還能進還能進行流暢的對話交流,甚至能完成撰寫郵件、視頻腳本、文案、翻譯、代碼等任務。
多層編碼器-解碼器結構:Transformer模型的核心組件,它模擬了大腦理解自然語言的過程。
編碼器(Encoder):將輸入序列(如用戶的提問或對話內容)映射到一組中間表示,這個過程可以理解為將語言轉化為大腦能夠理解和記憶的內容。在ChatGPT中,編碼器由多層的注意力模塊和前饋神經網絡模塊組成,其中自注意力模塊能夠學習序列中不同位置之間的依賴關系。這種機制使得模型能夠有效地處理長距離依賴關系,從而更好地理解輸入的上下文信息。
解碼器(Decoder):將這些中間表示轉換為目標序列,即生成連貫、合理的回復。在ChatGPT中,解碼器同樣由多層的注意力模塊和前饋神經網絡模塊組成。解碼器在生成回復時,會考慮之前生成的內容以及編碼器提供的上下文信息,從而模擬人類的對話方式。
? Transformer模型:
ChatGPT:我與GPT系列模型是一樣嗎?
ChatGPT與GPT系列模型是不一樣的ChatGPT專門針對對話式交互任務進行了優化,可以生成具有上下文感知和連貫性的自然語言回復。與其它GPT系列模型相比:
1.最大的區別ChatGPT是通過對話數據進行預訓練,而不僅僅是通過單一的句子進行預訓練,這使得ChatGPT能夠更好地理解對話的上下文,并進行連貫的回復。
2.ChatGPT還使用了一種叫做Dialog Response Ranking(DRR)的訓練方法,該方法通過給定正樣本對話和負樣本對話,強調了正確回答的重要性,提高了模型的表現。
快看工作原理和代碼!
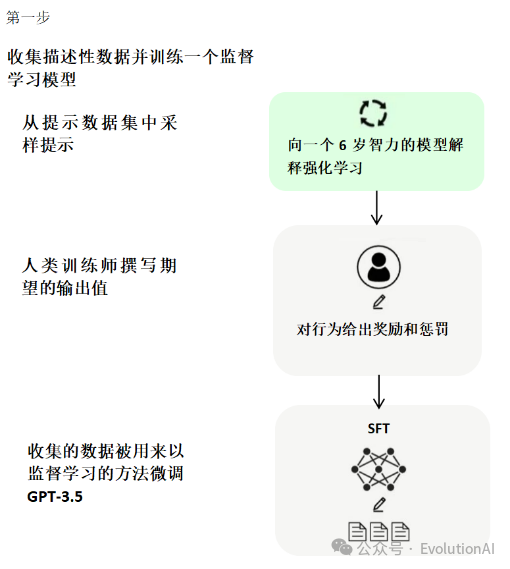
ChatGPT的核心方法就是引入“人工標注數據+強化學習”來不斷微調預訓練語言模型。訓練ChatGPT主要分為以下三個階段:
第一階段,使用標準數據(提示和對應的回答)進行微調,也就是有監督微調(Supervised Fine-Tuning, SFT)。為了讓ChatGPT能夠理解用戶提出的問題中所包含的意圖,首先需要從用戶提交的問題中隨機抽取一部分,由專業的標注人員給出相應的高質量答案,然后用這些人工標注好的<提示, 答案> 數據來微調 GPT-3模型。微調技術是ChatGPT實現對話生成的關鍵技術之一,它可以通過在有標注數據上進行有監督訓練,從而使模型適應特定任務和場景。微調技術通常采用基于梯度下降的優化算法,不斷地調整模型的權重和偏置,以最小化損失函數,從而提高模型的表現能力。
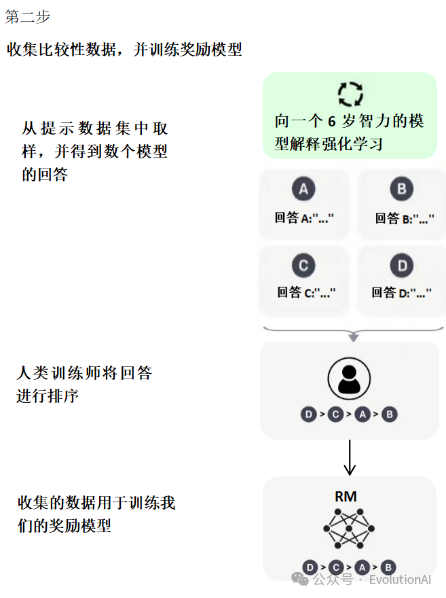
第二階段,訓練獎勵模型(Reward Model, RM)。給定提示(大約3萬左右),使用微調后的模型生成多個回答,人工對多個答案進行排序,然后使用成對學習(pair-wise learning)來訓練獎勵模型,也就是學習人工標注的順序(人工對模型輸出的多個答案按優劣進行排序)。目的是用人工標注數據來訓練獎勵模型(Reward Model, RM)。
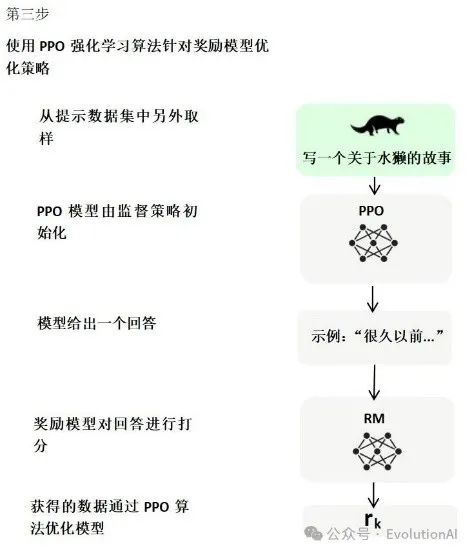
第三階段,使用強化學習,微調預訓練語言模型。利用獎勵模型的打分結果來更新模型參數,從而使模型更加符合用戶的期望。
代碼:
import torchimport torch.nn.functional as Ffrom transformers import GPT2LMHeadModel, GPT2Tokenize
# 加載預訓練模型和分詞器:使用 GPT2LMHeadModel.from_pretrained() 和 GPT2Tokenizer.from_pretrained() 函數加載預訓練的 GPT 模型和分詞器? ? ? ??model=GPT2LMHeadModel.from_pretrained('gpt2')?
# 加載預訓練模型??
tokenizer=GPT2Tokenizer.from_pretrained('gpt2')?
# 加載分詞器# 定義對話生成函數:使用模型和分詞器生成對話文本。輸入參數包括模型 model、分詞器 tokenizer、對話前綴 prompt、生成文本的最大長度max_length 和溫度 temperature。首先使用分詞器將對話前綴轉換為輸入張量 input_ids,并將其移動到 GPU 上。然后使用模型的 generate() 方法生成文本,并將輸出張量轉換為文本返回
def generate(model, tokenizer, prompt, max_length=30, temperature=1.0):
# 將對話前綴轉換為輸入張量
input_ids= tokenizer.encode(prompt, add_special_tokens=False, return_tensors='pt')input_ids = input_ids.cuda()?
# 將輸入張量移動到 GPU 上
# 使用模型生成文本?
output=model.generate(input_ids,max_length=max_length,temperature=temperature)
# 將輸出張量轉換為文本并返回
return? ? ? ?tokenizer.decode(output[0],skip_special_tokens=True)
# 微調對話數據:首先定義對話數據 conversation,然后將其拼接成一個字符串 text,其中奇數句子末尾添加 eos 標記。然后使用分詞器將對話數據轉換為輸入張量 input_ids,并將其移動到 GPU 上。接著使用模型計算損失并反向傳播,以微調模型。我們使用 model.train() 將模型設置為訓練模式,并使用 optimizer.step() 和 optimizer.zero_grad() 分別執行參數更新和梯度清零操作
conversation = [
"你好,我是小明。",
"你好,我是小紅。",
"你喜歡什么運動?",
"我喜歡打籃球。",
"你呢?",
"我喜歡跑步。"]
text = "
"for ?i, sentence in enumerate(conversation): ? ?text += sentence
if i % 2 == 0: ?text +=tokenizer.eos_token ?# 在奇數句子末尾添加 eos 標記
model.train()
# 設置模型為訓練模式
for epoch in range(3):
# 將對話數據轉換為輸入張量
input_ids = tokenizer.encode(text,add_special_tokens=True,return_tensors='pt')
input_ids = input_ids.cuda()?
# 將輸入張量移動到 GPU 上?
# 使用模型計算損失并反向傳播?
output = model(input_ids, labels=input_ids) ?loss =output.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 測試對話生成函數:使用 generate() 函數生成對話文本,并將其打印出來
prompt = "你喜歡什么運動?"
response = generate(model, tokenizer, prompt, max_length=20, temperature=0.7)print(response)
GhatGPT:我的優點太多啦
1.ChatGPT的模型架構主要基于Transformer結構,與傳統的基于RNN(循環神經網絡)的結構不同。這種基于Transformer的結構能夠更好地捕捉文本中的長距離依賴關系,從而提高了模型的性能。具體來說,Transformer結構通過使用自注意力機制(Self-Attention Mechanism)來計算輸入序列中每個位置的表示,這使得模型能夠更好地理解文本的上下文信息。
2.ChatGPT還采用了生成式AI技術,可以生成連貫且符合語法的文本。這種技術使得ChatGPT能夠為人們提供各種問答和文本生成服務,如智能客服、智能助手等。同時,ChatGPT還具備人機交互的能力,可以與用戶進行交互,根據用戶的輸入和反饋生成個性化的回答和回復。
3.ChatGPT模型在大量的文本數據上進行預訓練,這使得模型能夠更好地學習到語言的特征和規律。在訓練過程中,ChatGPT使用了大量的語料庫,包括網頁文本、書籍、文章等,從而保證了模型的通用性和泛化能力。
?GhatGPT:我也有缺點
1.在生成文本時可能會出現一些不符合實際或常識的錯誤,或者在某些情況下無法準確地理解用戶的意圖。
2.由于ChatGPT是在大量的文本數據上進行預訓練的,因此其可能會包含一些不適當或冒犯性的內容。因此,在使用ChatGPT時需要注意其生成的文本內容是否合適和準確。
3.中文訓練語料庫比英文訓練語料庫要少,所以中文知識也少。
4.無法給出這個信息提供的來源,這就跟百度和Google有本質的不同,在搜索引擎中,我們知道文章是誰寫的,所以ChatGPT只能使用它訓練的知識。
5.無法獲取最新的數據,只能獲取訓練時間節點的數據來提供知識。
使用注意事項
簡單的說,其實就是一句話,提出好的問題,對于ChatGPT來說,問題比答案更重要,因為GPT模型本身就是基于提示(Prompt)來起作用的,它的回答,取決于你給他的提示的內容和質量,那么怎么才能提出好的問題呢?
1.增加細節(增加提示的細節和要求)。
2.不斷追問(基于ChatGPT生成的內容不斷追問)。
3.心存疑問(對于ChatGPT的回答不能盲目相信)。
ChatGPT的未來與應用
ChatGPT的發展趨勢:更加智能化、多模態交互、知識圖譜的融合、個性化定制、隱私和安全性。
ChatGPT的挑戰(在多模態交互上):數據獲取和標注、跨模態理解和融合、計算資源和效率、隱私和安全性。
ChatGPT的應用:客戶服務與智能助手、社交媒體與聊天應用、在線教育與培訓、金融與投資.醫療健康、內容創作與生成、信息檢索與問答系統、虛擬角色和游戲NPC等領域。隨著技術的不斷發展,ChatGPT在更多領域的應用也將不斷拓展。
審核編輯:黃飛
?












 工商網監
工商網監
評論