 電子發(fā)燒友App
電子發(fā)燒友App


電子發(fā)燒友早八點訊:圍棋已經(jīng)流傳近3000年,但人類一直低估了一點:以第五條線為代表的棋局中部區(qū)域。
這是AlphaGo之父、DeepMind創(chuàng)始人DemisHassabis向外界分享AlphaGo背后故事時透露的重要信息。
?
自去年3月首爾那場載入史冊的比賽以來,AlphaGo超越人類棋手固有思維和套路的招法,對圍棋界的沖擊史無前例。用DemisHassabis的話說,“就像人們利用哈勃望遠(yuǎn)鏡發(fā)現(xiàn)新的宇宙空間一樣。AlphaGo就是圍棋界的‘哈勃天文望遠(yuǎn)鏡’。”
5月24日,DeepMind創(chuàng)始人DemisHassabis以及AlphaGo團隊負(fù)責(zé)人DavidSilver一起對外詳解了AlphaGo背后的研發(fā)故事,以及AlphaGo究竟意味著什么?
“AlphaGo已經(jīng)展示出了創(chuàng)造力,在某一個領(lǐng)域它甚至已經(jīng)可以模仿人類直覺了。”DemisHassabis對第一財經(jīng)記者表示,在未來能看到人機合作的巨大力量,人類智慧將通過人工智能進一步放大。“強人工智能是人類研究和探尋宇宙的終極工具。”
圍棋難在哪兒
歷史上,電腦最早掌握的第一款經(jīng)典游戲是井字游戲,這是1952年一位博士在讀生的研究項目;隨后是1994年電腦程序Chinook成功挑戰(zhàn)西洋跳棋游戲;3年后,IBM深藍(lán)超級計算機在國際象棋比賽中戰(zhàn)勝世界冠軍加里·卡斯帕羅夫。
相比之下,圍棋看似規(guī)則簡單,復(fù)雜性卻難以想象。它一共有10的170次方種可能性,這個數(shù)字比整個宇宙中的原子數(shù)10的80次方都多,沒有辦法窮舉出圍棋所有可能的結(jié)果。
在DemisHassabis看來,更困難的是圍棋不像象棋等游戲靠計算,而是靠直覺。“圍棋中沒有等級概念,所有棋子都一樣,圍棋是筑防游戲,因此需要盤算未來。你在下棋的過程中,是棋盤在心中,必須要預(yù)測未來。小小一個棋子可撼動全局,牽一發(fā)而動全身。圍棋‘妙手’如受天啟。”Hassabis如此解釋道。
第一位與AlphaGo對陣的人類職業(yè)棋手樊麾對記者感慨,“曾經(jīng)以為計算機打敗職業(yè)棋手,一輩子都不會看到,沒想到這么快就實現(xiàn)了。”
對AlphaGo團隊來說,是時候?qū)ふ乙环N更聰明的方法來解開圍棋謎題了。
AlphaGo系統(tǒng)的關(guān)鍵是,將圍棋巨大無比的搜索空間壓縮到可控的范圍之內(nèi)。
為了應(yīng)對圍棋的巨大復(fù)雜性,AlphaGo采用了一種新穎的機器學(xué)習(xí)技術(shù),結(jié)合了監(jiān)督學(xué)習(xí)和強化學(xué)習(xí)的優(yōu)勢。
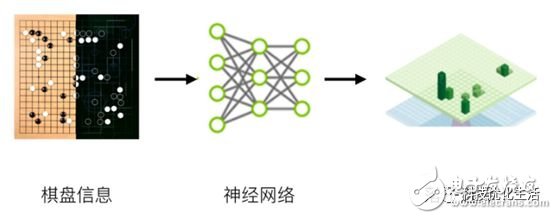
具體而言,首先是通過訓(xùn)練形成一個策略網(wǎng)絡(luò)(policynetwork),將棋盤上的局勢作為輸入信息,并對所有可行的落子位置生成一個概率分布。然后,訓(xùn)練出一個價值網(wǎng)絡(luò)(valuenetwork)對自我對弈進行預(yù)測,以-1(對手的絕對勝利)到1(AlphaGo的絕對勝利)的標(biāo)準(zhǔn),預(yù)測所有可行落子位置的結(jié)果。
這兩個網(wǎng)絡(luò)自身都十分強大,而AlphaGo將這兩種網(wǎng)絡(luò)整合進基于概率的蒙特卡羅樹搜索(MCTS)中,實現(xiàn)了它真正的優(yōu)勢。最后,新版的AlphaGo產(chǎn)生大量自我對弈棋局,為下一代版本提供了訓(xùn)練數(shù)據(jù),此過程循環(huán)往復(fù)。
AlphaGo如何決定落子
在獲取棋局信息后,AlphaGo會根據(jù)策略網(wǎng)絡(luò)探索哪個位置同時具備高潛在價值和高可能性,進而決定最佳落子位置。
在分配的搜索時間結(jié)束時,模擬過程中被系統(tǒng)最頻繁考察的位置將成為AlphaGo的最終選擇。在經(jīng)過先期的全盤探索和過程中對最佳落子的不斷揣摩后,AlphaGo的搜索算法就能在其計算能力之上加入近似人類的直覺判斷。
DemisHassabis表示,AlphaGo不只是模仿其他人類選手的下法,而且在不斷創(chuàng)新。
例如,在與李世石第二局里對弈第37步,這一步是Demis在整個比賽中感到最震驚的一步。
Demis解釋道:在圍棋中有兩條至關(guān)重要的分界線,從右數(shù)第三根線。如果在第三根線上移動棋子,意味著你將占領(lǐng)該線右邊的領(lǐng)域。而如果是在第四根線上落子,意味著你計劃向棋盤中部進軍,潛在的,未來你會占棋盤上其他部分的領(lǐng)域,可能和你在第三根線上得到的領(lǐng)域相當(dāng)。
因此,在過去的3000多年里,人們普遍認(rèn)為在第三根線上落子和第四根線上落子有著相同的重要性。但在第37步中,阿爾法狗卻把棋子落在了第五條線,進軍棋局的中部區(qū)域。“這可能意味著,在過去幾千年里,人們低估了棋局中部區(qū)域的重要性。”
值得一提的是,和去年戰(zhàn)勝李世石的AlphaGo相比,DeepMind科學(xué)家DavidSilver稱現(xiàn)在AlphaGo要更強三子,他介紹道:“與李世石對戰(zhàn)的AlphaGo在云上有50個TPUs在運作,搜索50個棋步為10000個位置/秒,而5月23日打敗柯潔的AlphaGoMaster則在單個TPU上進行游戲,AlphaGo成為自己的老師,它從自己的搜索里學(xué)習(xí),有著更強大的策略和價值網(wǎng)絡(luò)。”
柯潔也在5月24日的微博中,對于AlphaGo團隊給出的檢測報告感嘆:自己是在跟怎樣可怕的對手下棋。
“這個差距有多大呢?簡單地解釋一下就是一人一手輪流下的圍棋,對手連續(xù)讓你下三步……又像武林高手對決讓你先捅三刀一樣……”柯潔說。
除了下圍棋,AlphaGo還能做什么?
圍棋之外,DemisHassabis告訴記者,AlphaGo的高效算法是一種通用型的算法,也可以推廣到其他算法,把人工智能運用到各種各樣的領(lǐng)域,如將AI用到材料設(shè)計、新藥研制上,還有現(xiàn)實生活中的應(yīng)用,如醫(yī)療、智能手機、教育等。
不過他也對第一財經(jīng)坦言,圍繞AlphaGo,背后的技術(shù)包括圖像處理、大數(shù)據(jù)分析等,這些技術(shù)目前在其他領(lǐng)域的使用還在早期探索階段,只在AlphaGo研究的中間環(huán)節(jié)某些領(lǐng)域應(yīng)用,但是在未來肯定會在多個領(lǐng)域推廣相關(guān)的技術(shù)。
聲明:電子發(fā)燒友網(wǎng)轉(zhuǎn)載作品均盡可能注明出處,該作品所有人的一切權(quán)利均不因本站轉(zhuǎn)載而轉(zhuǎn)移。作者如不同意轉(zhuǎn)載,即請通知本站予以刪除或改正。轉(zhuǎn)載的作品可能在標(biāo)題或內(nèi)容上或許有所改動。














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論