 電子發(fā)燒友App
電子發(fā)燒友App


在下面的文章中,我們將討論決策樹、聚類算法和回歸,指出它們之間的差異,并找出如何根據(jù)不同的案例選擇最合適的模型。
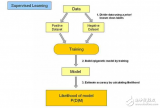
有監(jiān)督學(xué)習(xí) VS 無監(jiān)督學(xué)習(xí)
理解機(jī)器學(xué)習(xí)的基礎(chǔ)就是如何對有監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)這兩個大類進(jìn)行分類的問題,因為機(jī)器學(xué)習(xí)問題中的任何一個問題最終都是這兩個大類中的某一個。
在有監(jiān)督學(xué)習(xí)的情況下,我們有數(shù)據(jù)集,某些算法會將這些數(shù)據(jù)集作為輸入。前提是我們已經(jīng)知道正確的輸出格式應(yīng)該是什么樣子(假設(shè)輸入和輸出之間存在某種關(guān)系)。
稍后我們看到的回歸和分類問題都是屬于這一類。
另一方面,無監(jiān)督學(xué)習(xí)適用于我們不確定或者不知道正確的輸出應(yīng)該是什么樣子的情況。事實上,我們需要根據(jù)數(shù)據(jù)推導(dǎo)出正確的結(jié)構(gòu)應(yīng)該是什么樣。聚類問題是該類的主要代表。
為了使上述分類更加清晰,我將列舉一些現(xiàn)實世界的問題,并嘗試對它們進(jìn)行相應(yīng)的分類。
實例1
假設(shè)你在經(jīng)營一家房地產(chǎn)公司。考慮到新房子的特點(diǎn),你想基于之前記錄的其他房子的銷售情況,從而預(yù)測這間房屋的銷售價格應(yīng)該在什么價位。輸入的數(shù)據(jù)集包含多個房子的特征,比如浴室的數(shù)量和大小,而你想要預(yù)測的變量,通常稱為目標(biāo)變量,在本例子中也就是價格。因為已經(jīng)知道了數(shù)據(jù)集中房子的出售價格,因此這是一個有監(jiān)督學(xué)習(xí)的問題,說的更具體一點(diǎn),這是一個關(guān)于回歸的問題。
實例2
假設(shè)你做了一項實驗,根據(jù)某些物理測量結(jié)果以及遺傳因素,來推斷某人是否會發(fā)展成為近視眼。在這種情況下,輸入的數(shù)據(jù)集是由人體醫(yī)學(xué)特征組成的,目標(biāo)變量是雙重的:1表示那些可能發(fā)展近視的人,0表示沒有成為近視眼的人。由于已經(jīng)提前知道了參與實驗者的目標(biāo)變量的值(即你已經(jīng)知道如果他們是否是近視),這又是一個有監(jiān)督學(xué)習(xí)的問題——更具體地說,這是一個分類的問題。
實例3
假設(shè)你負(fù)責(zé)的公司有很多的客戶。根據(jù)他們最近與公司的互動結(jié)果,最近購買的產(chǎn)品,以及他們的人口統(tǒng)計資料,你想要把相似的客戶組成一個群體,以不同的方式來對待他們——比如給他們提供獨(dú)家折扣券。在這種情況下,將會使用上面提到的某些特性作為算法的輸入,而算法將決定應(yīng)該客戶群的數(shù)量或類型。這是無監(jiān)督學(xué)習(xí)最典型的一個例子,因為我們事先根本就不知道輸出結(jié)果應(yīng)該是怎樣的。
話雖如此,現(xiàn)在是實現(xiàn)我的承諾的時候了,來介紹一些更具體的算法……
回歸
首先,回歸不是單一的有監(jiān)督學(xué)習(xí)的技術(shù),而是許多技術(shù)所屬的整個類別。
回歸的主要思想是給定一些輸入變量,我們想要預(yù)測目標(biāo)變量的值是什么樣的。在回歸的情況下,目標(biāo)變量是連續(xù)的——這意味著它可以在指定范圍內(nèi)取任意的值。另一方面,輸入變量既可以是離散的,也可以是連續(xù)的。
在回歸技術(shù)中,最廣為人知的就是線性回歸和邏輯回歸了。讓我們仔細(xì)研究研究。
線性回歸
在線性回歸中,我們試圖建立輸入變量與目標(biāo)變量之間的關(guān)系,這種關(guān)系是由一條直線表示的,通常稱為回歸線。
例如,假設(shè)我們有兩個輸入變量X1和X2以及一個目標(biāo)變量Y,這種關(guān)系可以用數(shù)學(xué)形式表示:
Y = a * X1 + b*X2 +c
假設(shè)已經(jīng)提供了X1和X2的值,我們的目標(biāo)是對a、b、c三個參數(shù)進(jìn)行調(diào)整,從而使Y盡可能接近實際值。
花點(diǎn)時間講個例子吧!
假設(shè)我們已經(jīng)有了Iris數(shù)據(jù)集,它已經(jīng)包含了不同類型的花朵的萼片和花瓣的大小數(shù)據(jù),例如:Setosa,Versicolor和Virginica。
使用R軟件,假設(shè)已經(jīng)提供了花瓣的寬度和長度,我們需要實現(xiàn)一個線性回歸來預(yù)測萼片的長度。
在數(shù)學(xué)上,我們將通過如下關(guān)系是獲取a、b的值:
SepalLength = a * PetalWidth + b* PetalLength +c
相應(yīng)的代碼如下:

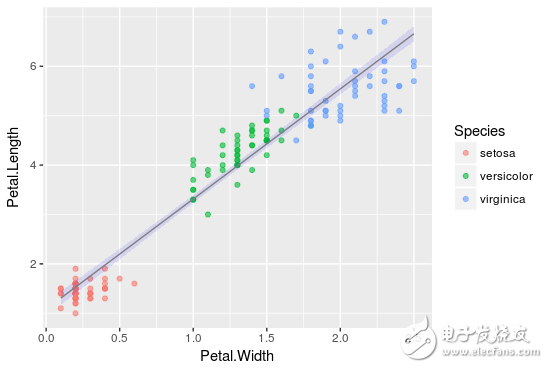
線性回歸的結(jié)果如下圖所示,黑點(diǎn)表示初始數(shù)據(jù)點(diǎn)在藍(lán)線擬合回歸直線,于是便有了估算結(jié)果,a= -0.31955,b = 0.54178,和c = 4.19058,這個結(jié)果可能最接近實際情況,即花萼的長度。
從現(xiàn)在開始,通過將花瓣長度和花瓣寬度的值應(yīng)用到定義的線性關(guān)系中來,新出現(xiàn)的數(shù)據(jù)點(diǎn)我們也可以預(yù)測它的長度了。
邏輯回歸
這里的主要思想和線性回歸完全一樣。最大的不同就是回歸線不再是直的的。
相反,我們試圖建立的數(shù)學(xué)關(guān)系是類似于以下形式:
Y=g(a*X1+b*X2)
這里的g()就是邏輯函數(shù)。
由于logistic函數(shù)的性質(zhì),Y是連續(xù)的,在[0,1]范圍內(nèi),可以理解為事件發(fā)生的概率。
我知道你喜歡例子,所以我再給你看一個!
這次,我們將對mtcars數(shù)據(jù)集進(jìn)行實驗,該數(shù)據(jù)集包括燃料消耗和汽車設(shè)計的10個方面,以及1973 - 1974年生產(chǎn)的32輛汽車的性能。
使用R,我們將根據(jù)V/S和Miles/(US)加侖的測量值,預(yù)測自動變速器(am = 0)或手動(am = 1)汽車的概率。
am = g(a * mpg + b* vs +c):

結(jié)果如下圖所示,其中黑點(diǎn)代表數(shù)據(jù)集的初始點(diǎn),藍(lán)色線代表a = 0.5359,b = - 2.7957,c = - 9.9183的擬合邏輯回歸線。
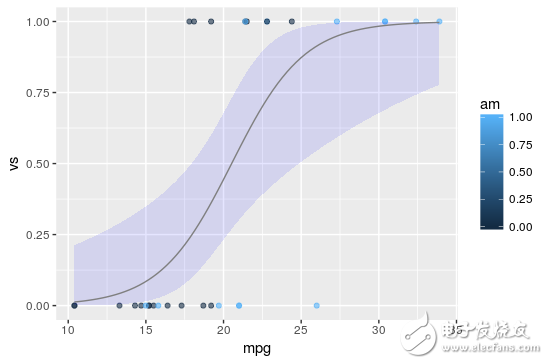
正如前面所提到的,我們可以觀察到由于回歸線的形式,logistic回歸輸出值只在范圍[0,1]中。
對于任何以V/S和Miles/(US)加侖為標(biāo)準(zhǔn)的新車,我們現(xiàn)在可以預(yù)測這輛車自動變速器的概率。
決策樹
決策樹是我們將要研究的第二種機(jī)器學(xué)習(xí)算法。決策樹最終分裂成了回歸和分類樹,因此可以用于有監(jiān)督學(xué)習(xí)問題。
誠然,決策樹是最直觀的算法之一,它們可以模仿人們在大多數(shù)情況下的決定方式。他們所做的基本上就是繪制出所有可能路徑的“地圖”,并在每種情況下畫出相應(yīng)的結(jié)果。
圖形表示將有助于更好地理解我們正在討論的內(nèi)容。
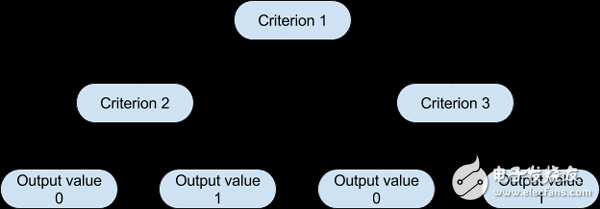
基于這樣一棵樹,算法可以根據(jù)相應(yīng)的標(biāo)準(zhǔn)值決定在每個步驟中遵循哪條路徑。算法選擇分割標(biāo)準(zhǔn)的方式和每個級別的相應(yīng)閾值,取決于候選變量對目標(biāo)變量的信息量,以及哪個設(shè)置最小化了所產(chǎn)生的預(yù)測錯誤。
這里還有一個例子!
這一次討論的數(shù)據(jù)集是readingSkills。它包括了學(xué)生的考試成績和分?jǐn)?shù)。
我們將基于多種指標(biāo)把學(xué)生分為母語為英語的人(nativeSpeaker = 1)或外國人(nativeSpeaker = 0),包括他們在測試中的得分,他們的鞋碼,以及他們的年齡。
對于R中的實現(xiàn),我們首先需要安裝party包。

我們可以看到,使用的第一個分裂標(biāo)準(zhǔn)是分?jǐn)?shù),因為它在預(yù)測目標(biāo)變量時非常重要,而鞋子的大小并沒有被考慮在內(nèi),因為它沒有提供任何關(guān)于語言的有用信息。
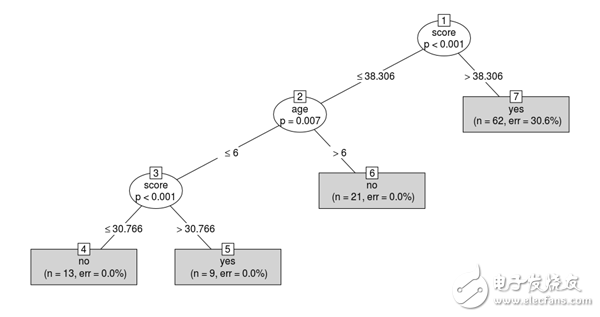
現(xiàn)在,如果我們有了一個新學(xué)生,知道他們的年齡和分?jǐn)?shù),我們就可以預(yù)測他們是不是一個以英語為母語的人!
聚類算法
到目前為止,我們只討論了一些關(guān)于有監(jiān)督學(xué)習(xí)的問題。現(xiàn)在,我們繼續(xù)研究聚類算法,而它則是無監(jiān)督學(xué)習(xí)方法的子集。
所以,只是稍微修改了一點(diǎn)…
對于集群,如果有一些初始數(shù)據(jù)進(jìn)行支配,我們想要形成一個組,這樣一些組的數(shù)據(jù)點(diǎn)是相似的,并且不同于其他組的數(shù)據(jù)點(diǎn)。
我們將要學(xué)習(xí)的算法叫做k-means,k表示產(chǎn)生的簇的數(shù)量,這是最流行的聚類方法之一。
還記得我們之前用過的Iris數(shù)據(jù)集嗎?我們將再次使用它。
為了研究,我們用他們的花瓣測量方法繪制了數(shù)據(jù)集的所有數(shù)據(jù)點(diǎn),如下圖所示:
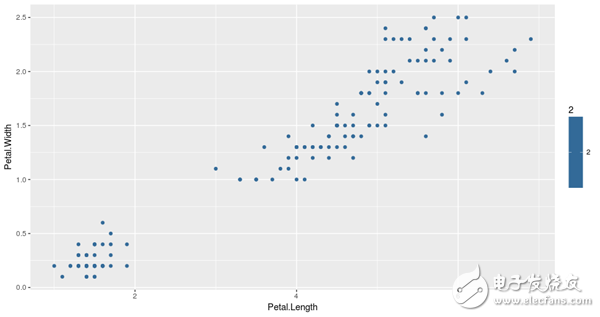
基于花瓣的度量值,我們將使用3-means clustering方法將數(shù)據(jù)點(diǎn)聚集成3組。
那么3-means,或者說是k-means算法是如何工作的呢?整個過程可以用幾個簡單的步驟來概括:
初始化步驟:對于k = 3簇,算法隨機(jī)選取3個點(diǎn)作為每個集群的中心點(diǎn)。
集群分配步驟:算法通過其余的數(shù)據(jù)點(diǎn),并將每個數(shù)據(jù)點(diǎn)分配給最近的集群。
Centroid移動步驟:在集群分配之后,每個集群的中心點(diǎn)移動到屬于集群的所有點(diǎn)的平均值。
步驟2和步驟3重復(fù)多次,直到對集群分配沒有更改。R中k-means算法的實現(xiàn)很簡單,可以用以下代碼實現(xiàn):
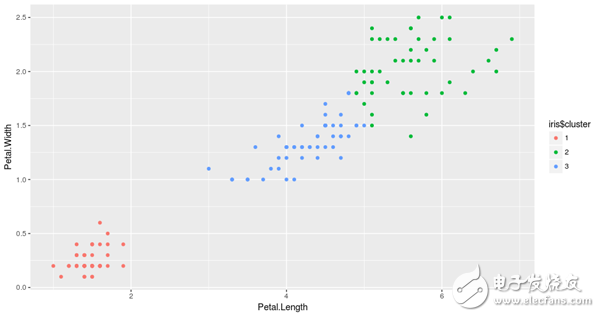
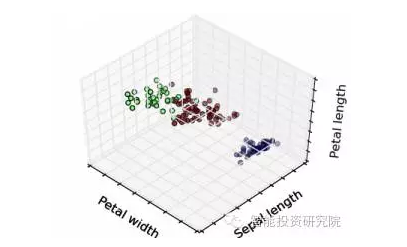
從結(jié)果中可以看出,該算法將數(shù)據(jù)分成三組,分別用三種不同的顏色表示。我們也可以觀察到這些簇是根據(jù)花瓣的大小形成的。更具體地說,紅色表示花瓣小的花,綠色表示花瓣相對較大的蝴蝶花,而藍(lán)色則表示中等大小的花瓣。
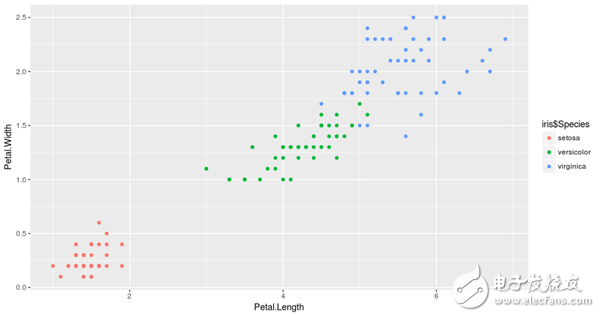
值得注意的是,在任何聚類中,對形成群體的解釋都需要在該領(lǐng)域有一些專家知識。在我們的例子中,如果你不是一個植物學(xué)家,你可能不會意識到k - means所做的是把iris聚集到他們不同的類型,例如Setosa,Versicolor和Virginica,而沒有任何關(guān)于它們的知識!
因此,如果我們再次繪制數(shù)據(jù),這個時間被它們的物種著色,我們將看到集群中的相似性。
總結(jié)
我們從一開始就走了很長一段路。我們討論了回歸(線性和邏輯)和決策樹,最后討論了k - means集群。我們還在R中實現(xiàn)了一些簡單但強(qiáng)大的方法。
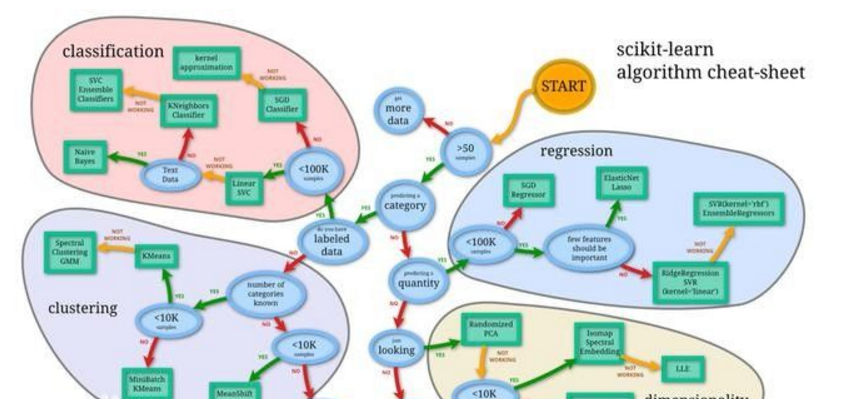
那么,每種算法的優(yōu)點(diǎn)是什么呢?在現(xiàn)實生活中,你應(yīng)該選擇哪一個?
首先,所呈現(xiàn)的方法并不是一些不適用的算法——它們在世界各地的生產(chǎn)系統(tǒng)中被廣泛使用,因此需要根據(jù)不同的任務(wù)進(jìn)行選擇,選擇恰當(dāng)?shù)脑捒梢宰兊孟喈?dāng)強(qiáng)大。
其次,為了回答上述問題,你必須清楚你所說的優(yōu)點(diǎn)究竟是什么意思,因為每種方法在不同環(huán)境中展現(xiàn)出來的優(yōu)點(diǎn)是不同的,例如解釋性、穩(wěn)健性、計算時間等。




















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論