卷積是一種線性運算,其本質是滑動平均思想,廣泛應用于圖像濾波。而隨著人工智能及深度學習的發展,卷積也在神經網絡中發揮重要的作用,如卷積神經網絡。本參考設計主要介紹如何基于INTEL 硬浮點的DSP
2018-07-23 09:09:45 7322
7322 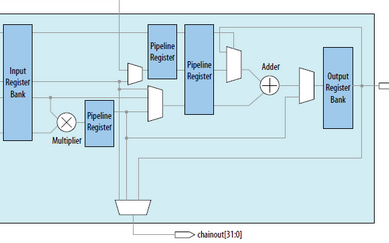
FPGA中DSP資源是寶貴的且有限,我們在計算大位寬的指數、復數乘法、累加、累乘等運算時都會用到DSP資源,如果我們不了解底層的DSP特性,很多設計可能都無法進行。邏輯綜合往往是不可控的,為了能夠
2020-09-30 11:48:5526638 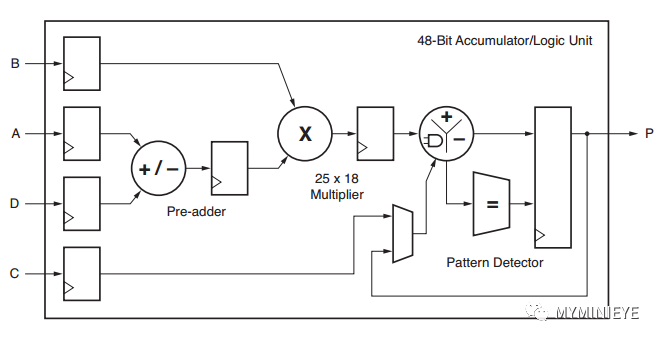
DSP48E2是zynq器件中使用的DSP類型,其主要結構包括一個27bit前加器,27x18bit的乘法器,一個48bit的可以執行加減法,累加以及邏輯功能的ALU。
2022-08-02 09:16:273378 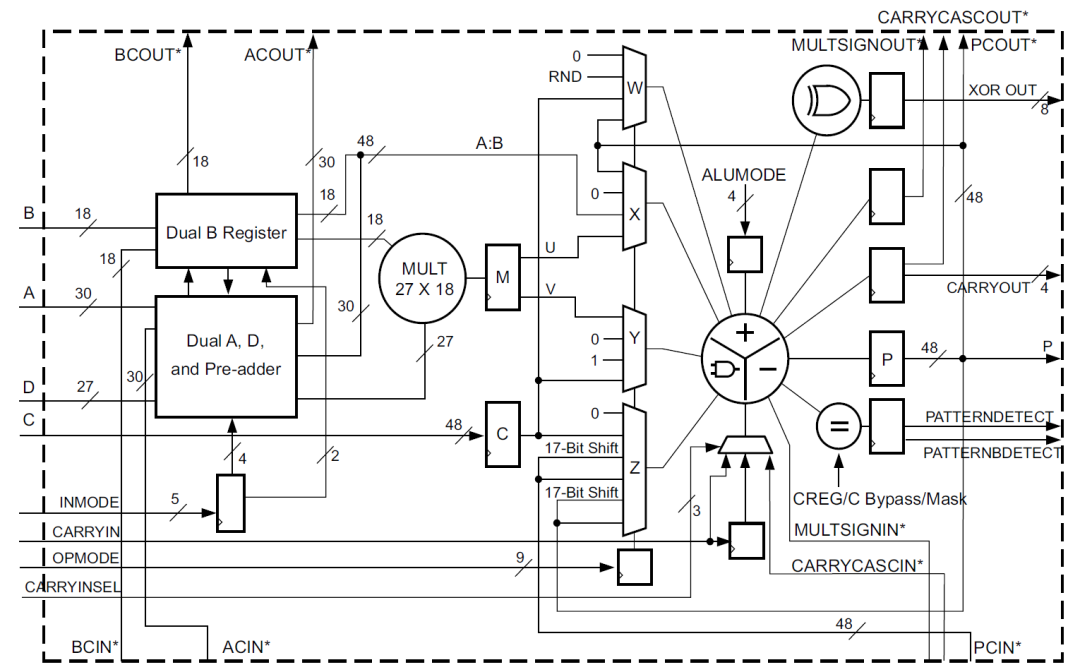
人工智慧隸屬于大範疇,包含了機器學習(Machine Learning) 與深度學習(Deep Learning)。如下圖所示,我們最興趣的深度學習則是規範于機器學習之中的一項分支,而以下段落將簡單介紹機器學習與深度學習的差異。
2020-12-18 15:45:313870 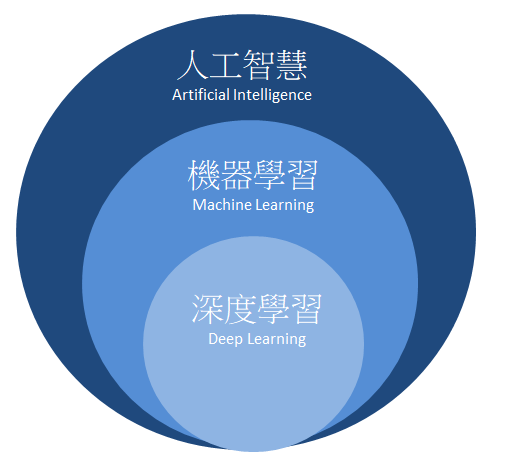
乘法器和一個三輸入加法器/減法器/累加器。DSP48E1乘法器具有非對稱的輸入,接受18位2的補數操作數和25位2的補數操作數。乘法器階段以兩個部分乘積的形式產生一個43位2的補碼結果。這些部分積在X
2021-01-08 16:46:10
7系列FPGA DSP48E1片的特點什么
2021-03-05 06:26:41
我正在實例化DSP切片并進行簡單的乘法然后加法((A * B)+ C)。根據DSP48E1用戶指南,當使用所有三個流水線寄存器時,它給出了最高頻率為600 MHz。但就我而言,它使用流水線寄存器
2020-06-12 06:32:01
嗨,我有一個如下的指令:(D-A)* B + C.端口A,B,C,D與DSP48E1輸入引腳相對應。我試圖將整個操作打包在DSP單元中。 (順便說一句,我的數據寬度是8位)在布局和布線完成后,我
2019-04-01 14:25:40
to use a DSP48E1 slice to delay data up to 48bits wide by three cycles and hence only use 1 DSP48 rather
2019-04-18 06:40:33
DSP48E1屬性
2021-01-27 06:21:23
和RSTB復位(如圖2-7和圖2-8所示)。 P端口 每個DSP48E1片都有一個48位的輸出端口p。這個輸出可以通過PCOUT路徑內部連接(級聯連接)到相鄰的DSP48E1片。PCOUT連接
2020-12-23 16:54:08
Memory,開啟cache。 如DSP能對SDRAM的不同4個bank可以同時訪問,此時你可以將需要同時運算的數據放入不同的bank (8)開啟仿真軟件的編譯優化選項 在菜單相應的地方勾上
2011-10-19 10:31:23
,51的指令是一條一條的執行,DSP的指令可以多條并行處理,從而獲得了更快的計算速度。2、運算能力。很多DSP器件硬件支持浮點數乘法,同時有硬件循環指令。硬件浮點乘法極大的提高了運算能力。硬件循環指令
2012-01-11 09:28:20
一、int8的輸出和fp32模型輸出差異比較大
解決方案:
檢查前后處理是否有問題,int8網絡輸入輸出一般需要做scale處理,看看是否遺漏?
通過量化可視化工具分析int8的輸出和fp32
2023-09-19 06:09:33
深度學習常用模型有哪些?深度學習常用軟件工具及平臺有哪些?深度學習存在哪些問題?
2021-10-14 08:20:47
時間安排大綱具體內容實操案例三天關鍵點1.強化學習的發展歷程2.馬爾可夫決策過程3.動態規劃4.無模型預測學習5.無模型控制學習6.價值函數逼近7.策略梯度方法8.深度強化學習-DQN算法系列9.
2022-04-21 14:57:39
CPU優化深度學習框架和函數庫機器學***器
2021-02-22 06:01:02
具有深度學習模型的嵌入式系統應用程序帶來了巨大的好處。深度學習嵌入式系統已經改變了各個行業的企業和組織。深度學習模型可以幫助實現工業流程自動化,進行實時分析以做出決策,甚至可以預測預警。這些AI
2021-10-27 06:34:15
機器學習 (ML) 是云和邊緣基礎設施中增長最快的部分之一。在 ML 中,深度學習推理預計會增長得更快。在本博客中,我們比較了三種 Amazon Web Services (AWS) EC2 云實例
2022-08-31 15:03:46
1. 簡介隨著人工智能的普及,深度學習網絡的不斷涌現,為了讓各硬件(CPU, GPU, NPU,…)能夠支持深度學習應用,各硬件芯片需要軟件庫去支持高性能的深度學習張量運算。目前,這些高性能計算庫
2021-12-14 06:18:21
L2cache
2.2 峰值算力
峰值算力:
FP32峰值算力 = 64 * 16 * 2(FP32 MAC) * 2 * 0 55G / 1024 = 2.2 TOPS
INT8峰值算力 = 64
2023-09-19 08:11:10
學習,也就是現在最流行的深度學習領域,關注論壇的朋友應該看到了,開發板試用活動中有【NanoPi K1 Plus試用】的申請,介紹中NanopiK1plus的高大上優點之一就是“可運行深度學習算法的智能
2018-06-04 22:32:12
`Nanopi深度學習之路這一系列的日記內容如下:1. 根據深度學習任務配置Nanopi2。2. 在Nanopi2上安裝Keras和TensorFlow。3. 在Nanopi2上部署一個訓練好的深度
2018-06-05 17:29:51
DSP(Digital Signal Processor)和 EVE(Embedded Vision/Vector Engine),用于加速計算深度學習神經網絡。相比于上一代TDA2/TDA3系列
2022-11-03 06:53:11
UltraScale DSP48 Slice架構的優勢是什么?UltraScale內存架構的優勢是什么?
2021-05-24 06:34:00
the slice, can't I use the DSP48A1 macro itself to test this Xapp706 application?
2019-07-04 15:36:07
,這樣的輸入選擇有助于構建多種類型,高流水化的DSP應用。
2. DSP48E1使用
(1)DSP原語使用的每個端口及位寬如下所示:
①表示的數據通道,運算數據的輸入。
②寄存器配置通道,我們可以通過
2023-06-20 14:29:51
model_deploy.py --mlir yolov5l.mlir --quantize INT8 --calibration_table yolov5l_cali_table --chip
2024-01-10 06:40:14
,使其更緊湊和更易debug,并提供了擴展的便利性。 課程內容基本上是以代碼編程為主,也會有少量的深度學習理論內容。課程會一步一步從Keras環境安裝開始講解,并從最基礎的Keras實現線性回歸
2018-07-17 11:40:31
caffe模型(浮點),得到int8的模型,再通過sdk編程,直接部署到FPGA上,這個過程本質上應該還是使用了SDSoC的相關工具。 大佬們開發了DPU這個深度學習的IP,在不遠的將來要放置到
2019-03-21 15:09:29
申請理由:1)由于剛接觸到DSP不久,希望通過DSP的開發板能夠快速入門,前期實現一些基本的功能;2)在學習到DSP的一些基本知識后,將逐漸運用DSP的實際項目中,先試著嘗試解決一些振動數據分析
2015-09-10 11:20:00
計算公司賽靈思(NASDAQ:XLNX)宣布,收購北京人工智能(AI)芯片初創公司深鑒科技。深鑒科技擁有業界較為領先的機器學習能力,專注于神經網絡剪枝、深度壓縮技術及系統級優化。深鑒科技原本是一家芯片
2020-12-10 15:23:40
開始的,相比傳統的CPU和GPU,在深度學習運算能力上有比較大幅度的提升。接下來在RV1109和RV1126上使用了第二代NPU,提升了NPU的利用率。第三代NPU應用在RK3566和RK3568上
2022-06-23 15:05:22
深度學習是什么意思
2020-11-11 06:58:03
,即使使用具有一定低位寬的數據,深度學習推理也不會降低最終精度。目前據說8位左右可以提供穩定的準確率,但最新的研究表明,已經出現了即使降低到4位或2位也能獲得很好準確率的模型和學習方法,越來越多的正在
2023-02-17 16:56:59
本文闡述了Spartan-3 FPGA針對DSP而優化的特性,并通過實現示例分析了它們在性能和成本上的優勢。
2019-10-18 07:11:35
矩陣乘,則可使用 B 與 A 矩陣乘之后進行轉置進行替換,可節約一次轉置運算。b. 算子融合是常見的深度學習的優化手段。算子融合雖然不能減少計算量,但是可以減少訪存量,提高計算訪存比,從而提升性能
2023-02-09 16:35:34
1323%DSP48E1的數量168641%設備利用率摘要(估計值)[ - ]邏輯利用用過的可得到采用切片寄存器的數量38695068736056%切片LUT的數量15269234368044%完全
2019-03-25 14:27:40
嗨,我想使用DSP45E1模塊實現Multply-Add操作,其中一個要求是我需要DSP模塊上的3級流水線。查看UG479 7系列DSP48E1 Slice用戶指南(UG479) - Xilinx
2020-07-21 13:52:24
DSP48E1片的數學部分由一個25位的預加器、2個25位、18位的補法器和3個48位的數據路徑多路復用器(具有輸出X、Y和Z)組成,然后是一個3輸入加法器/減法器或2輸入邏輯單元(參見圖2
2021-01-08 16:36:32
簡化DSP48E1片操作
2021-01-27 07:13:57
切片是整個切片數量的一部分還是它們在FPGA上共享資源?2)如果我們沒有進行任何DSP操作,那么DSP48E Slice是否可以用于實現某些常規邏輯,或者這些DSP Slice是否專門用于實現DSP
2019-04-04 06:36:56
DSP48E1磁貼(由2個切片和互連組成)與5個CLB具有相同的高度1 DSP48E1瓷磚與一個BRAM36K具有相同的高度1 DPS48E1 Slice水平對齊BRAM18K我讀到了xilinx asmbl架構
2020-07-25 11:04:42
求大神指教:在labview的公式節點中如何定義一個靜態變量(例如:static int8 i=0;這樣可以嗎?)
2016-04-13 21:37:29
的體系結構,熟練使用相關開發調試工具,擅長軟件性能分析和優化,能在緊約束條件下充分利用硬件資源,深度優化提升軟件效率; 8、勇于承擔責任,良好的溝通能力和團隊合作精神; 9、較好的英文閱讀能力。 有興趣的朋友,請聯系我,企鵝號碼:1537906585
2016-05-04 17:40:52
嗨,我正在使用兩個使用級聯鏈路連接的DSP48切片來執行所需的操作。我想嘗試多泵操作以有效地使用DSP48切片。請提供DSP48 slice中的Multipumping示例。提前致謝
2019-08-06 10:42:26
本帖最后由 一只耳朵怪 于 2018-6-13 16:29 編輯
大家好,使用28335也有1年多了,這個數制問題一直困擾我,就是如何自己定義8位的int型整數?在網上搜到的 typedef CPU_INT08U uint8; //[0 255],這個能用么?謝謝大家~
2018-06-13 04:13:04
本帖最后由 一只耳朵怪 于 2018-6-25 14:58 編輯
不能是INT16字型的?INT8精度不夠呀~
2018-06-25 01:12:25
與采用舊 CPU 的推理相比,在新 CPU 上推斷的 INT8 模型的推理速度更快。
2023-08-15 08:28:42
High DSP Performance Platform– The DSP48E Slice– Essential DSP Building Blocks• Imaging Algorithms
2009-04-09 22:05:31 12
12 本文簡要介紹了MPEG4-SP在DSP TM1300上的實現和優化過程。分析了其性能優化原理,給出了性能優化中使用到的幾個技巧,最終取得了滿意的優化效果。
2009-05-09 14:14:4513 CDMA網絡深度覆蓋的天線應用與RSSI指標優化分析,很好的網絡資料,快來學習吧。
2016-04-19 11:30:4823 、乘加(MACC, ),乘加,三輸入加法等等。該架構還支持串聯多個DSP48E1 slice,避免使用fpga邏輯功能的繁瑣。 System generator DSP48E1 模塊參數 雙擊dsp48e1模塊
2017-02-08 01:07:12595 
UltraScale DSP48E2 Slice 完美結合在一起。Prodigy KU 邏輯模塊理想適用于計算密集型應用;根據 S2C 的介紹,該模塊提供的 DSP 資源比市場上任何原型板都要多。除了數千
2017-02-08 12:19:14884 為了適應越來越復雜的DSP運算,Spartan-6在Spartan 3A DSP模塊DSP48A 基礎上,不斷進行功能擴展,推出了功能更強大的DSP48A1 SLICE。
2017-02-11 08:53:13992 
為了適應越來越復雜的DSP運算,Virtex-6中嵌入了功能更強大的DSP48E1 SLICE,簡化的DSP48E1模塊如圖5-16所示。
2017-02-11 09:17:131391 
賽靈思 INT8 優化為使用深度學習推斷和傳統計算機視覺功能的嵌入式視覺應用提供最優異的性能和能效最出色的計算方法。與其他 FPGA/DSP 架構相比,賽靈思的集成 DSP 架構在 INT8 深度學習運算上能實現 1.75 倍的性能優勢。
2017-09-22 17:27:115280 類庫,用數組向量來定義和計算數學表達式。它使得在Python環境下編寫深度學習算法變得簡單。在它基礎之上還搭建了許多類庫。Keras是一個簡潔、高度模塊化的神經網絡庫,它的設計參考了Torch,用Python語言編寫,支持調用GPU和CPU優化后的Theano運算。
2017-11-16 14:20:452873 這篇論文對于使用深度學習來改進IoT領域的數據分析和學習方法進行了詳細的綜述。
2018-03-01 11:05:127452 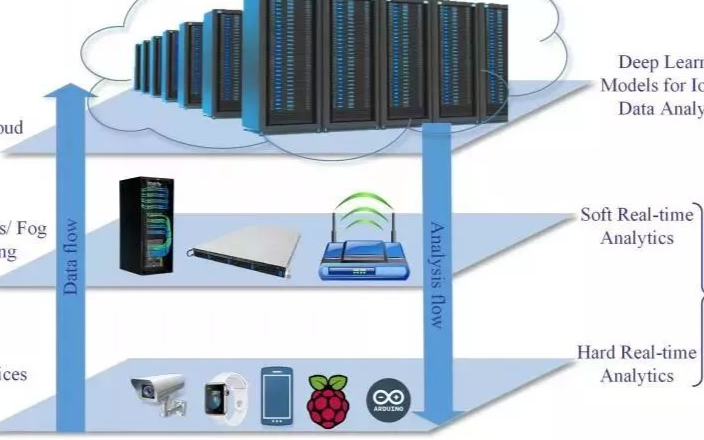
在研究基于大數據框架將深度學習的分布式實現后,王萬良指出,人工智能是大數據分析領域的研究主流,基于深度學習的大數據分析方法發展最為迅速,GPU成為深度學習的更高效的硬件平臺,研究分布式計算智能優化算法將解決大數據優化問題,能夠提升算法的效果并降低計算復雜度。
2018-09-26 16:56:138879 了解如何為UltraScale +設計添加額外的安全級別。
該視頻演示了如何防止差分功耗分析(DPA),以在比特流配置之上增加額外的安全性。
2018-11-27 06:24:002667 本視頻介紹了7系列FPGA的DSP Slice功能。
此外,還討論了Pre-Adder和Dynamic Pipeline控制資源。
2018-11-26 06:02:006700 賽靈思的 DSP 架構和庫針對 INT8 運算進行了精心優化。本白皮書介紹如何使用賽靈思 16nm 和 20nm All Programmable 器件中的 DSP48E2 Slice,在共享相同內核權重的同時處理兩個并行的 INT8 MACC 運算。
2019-07-29 11:19:322303 要使用可編程邏輯上的 DSP 實現中值濾波器,可以對算法做改動。每次比較運算可以分為減法運算及后續的符號位檢查。對減法運算,DSP48E2 Slice 能夠以四個 12 位或兩個 24 位模式進行運算。要充分利用 DSP48E2 Slice,可以并行運算多個像素。
2019-07-30 08:59:462913 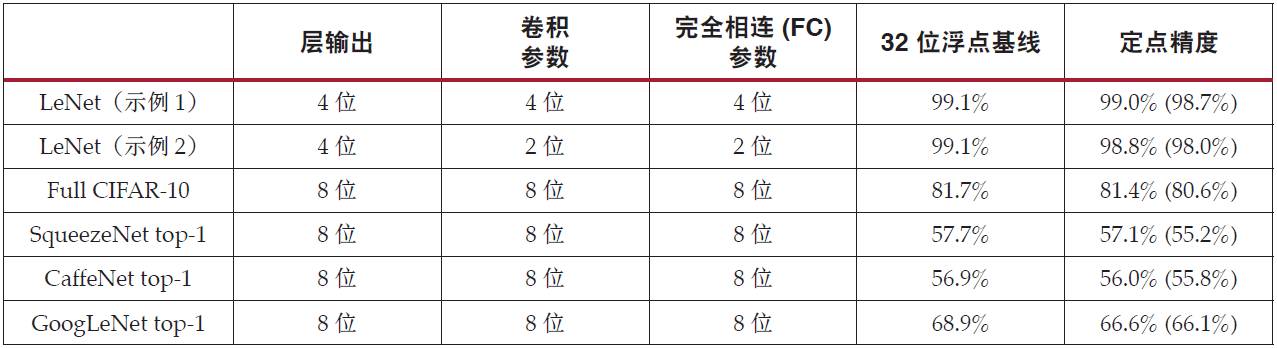
晶心科技今日宣布將攜手合作,在基于AndeStar? V5架構的晶心RISC-V CPU核心上配置高度優化的深度學習模型,使AI深度學習模型變得更輕巧、快速和節能。
2019-12-31 16:30:111002 Intel近日發布了最新版的高性能深度學習優化庫DNNL 1.2,證實即將推出的全新Xe架構獨立GPU的一項新技能,那就是支持Int8整數數據類型。
2020-02-04 15:31:191258 在深度學習中,有很多種優化算法,這些算法需要在極高維度(通常參數有數百萬個以上)也即數百萬維的空間進行梯度下降,從最開始的初始點開始,尋找最優化的參數,通常這一過程可能會遇到多種的情況
2020-08-28 09:52:452268 
DSP48最早出現在XilinxVirtex-4 FPGA中,但就乘法器而言,Virtex-II和Virtex-II Pro中就已經有了專用的18x18的乘法器,不過DSP48可不只是乘法器,其功能
2020-10-30 17:16:515770 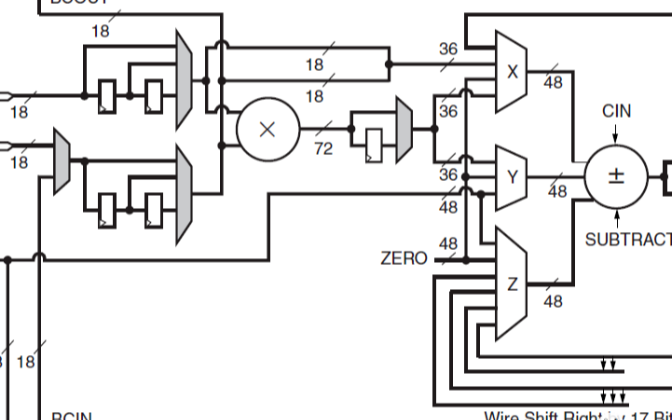
深度學習是機器學習與神經網絡、人工智能、圖形化建模、優化、模式識別和信號處理等技術融合后產生的一個領域。
2020-11-05 09:31:194711 A、B、C、CARRYIN、CARRYINSEL、OPMODE、BCIN、PCIN、ACIN、ALUMODE、CARRYCASCIN、MULTSIGNIN以及相應的時鐘啟用輸入和復位輸入都是保留端口。D和INMODE端口對于DSP48E1片是唯一的。本節詳細描述DSP48E1片的輸入端口
2022-07-25 18:00:184429 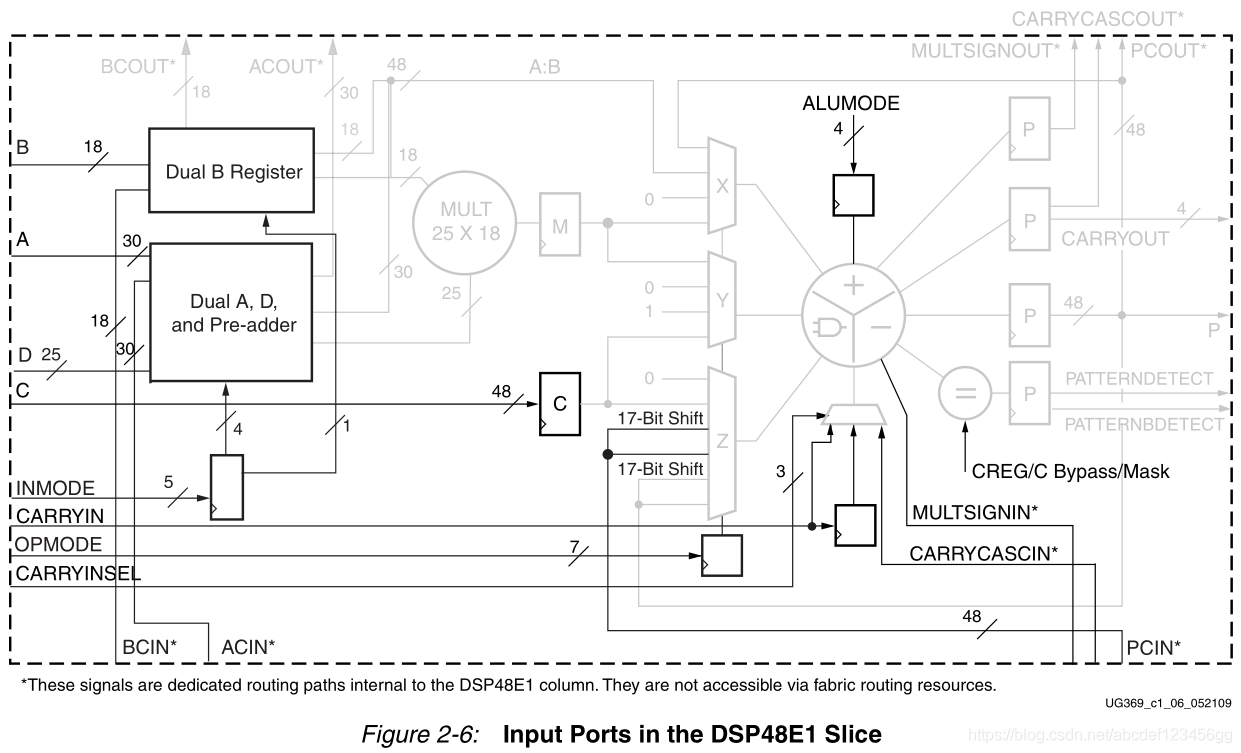
在DSP48E1列中,級聯各個DSP48E1片可以支持更高級的DSP功能。兩個數據路徑(ACOUT和BCOUT)和DSP48E1片輸出(PCOUT、MULTSIGNOUT和CARRYCASCOUT)提供級聯功能。級聯數據路徑的能力在過濾器設計中很有用。
2021-01-27 07:34:328 A、B、C、CARRYIN、CARRYINSEL、OPMODE、BCIN、PCIN、ACIN、ALUMODE、CARRYCASCIN、MULTSIGNIN以及相應的時鐘啟用輸入和復位輸入都是保留端口。D和INMODE端口對于DSP48E1片是唯一的。本節詳細描述DSP48E1片的輸入端口
2021-01-27 08:18:022 深度模型中的優化與學習課件下載
2021-04-07 16:21:013 2020年開始,新手機 CPU 幾乎都是 armv8.2 架構,這個架構引入了新的 fp16 運算和 int8 dot 指令,優化得當就能大幅加速深度學習框架的...
2022-01-26 18:53:190 本文是對NCNN社區int8模塊的重構開發,再也不用擔心溢出問題了,速度也還行。作者:圈圈蟲首發知乎傳送門ncnnBUG1989/caffe-int8-conver...
2022-02-07 12:38:261 FasterTransformer BERT 包含優化的 BERT 模型、高效的 FasterTransformer 和 INT8 量化推理。
2023-01-30 09:34:481283 
先大致講一下什么是深度學習中優化算法吧,我們可以把模型比作函數,一種很復雜的函數:h(f(g(k(x)))),函數有參數,這些參數是未知的,深度學習中的“學習”就是通過訓練數據求解這些未知的參數。
2023-02-13 15:31:481019 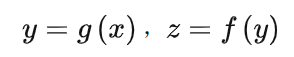
繼續深度學習編譯器的優化工作解讀,本篇文章要介紹的是OneFlow系統中如何基于MLIR實現Layerout Transform。
2023-05-18 17:32:42389 FasterTransformer BERT 包含優化的 BERT 模型、高效的 FasterTransformer 和 INT8 量化推理。
2023-05-30 15:15:15905 
電子發燒友網站提供《PyTorch教程12.1之優化和深度學習.pdf》資料免費下載
2023-06-05 15:08:410 12.1. 優化和深度學習? Colab [火炬]在 Colab 中打開筆記本 Colab [mxnet] Open the notebook in Colab Colab [jax
2023-06-05 15:44:30327 
深度學習模型量化支持深度學習模型部署框架支持的一種輕量化模型與加速模型推理的一種常用手段,ONNXRUNTIME支持模型的簡化、量化等腳本操作,簡單易學,非常實用。
2023-07-18 09:34:572200 
INT8量子化PyTorch x86處理器
2023-08-31 14:27:07453 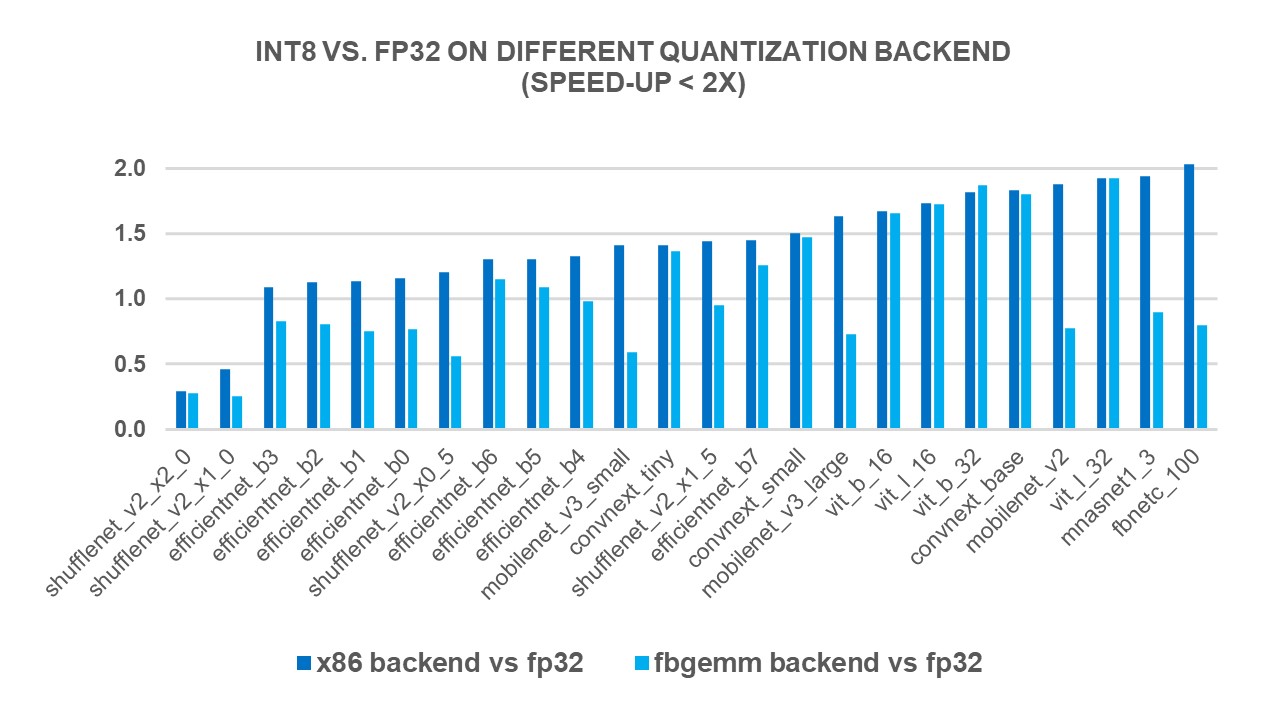
可視化其他量化形式的engine和問題engine進行對比,我們發現是一些層的int8量化會出問題,由此找出問題量化節點解決。
2023-11-23 16:40:20531
 電子發燒友App
電子發燒友App











 工商網監
工商網監
評論