 電子發(fā)燒友App
電子發(fā)燒友App


摘要:本文通過一個簡單的實例詳細介紹了Cassandra數(shù)據(jù)建模的五個步驟。以下是譯文。
我們最近在Instaclustr發(fā)表了一篇有關在Cassandra中經(jīng)常出現(xiàn)的數(shù)據(jù)建模錯誤的文章。這篇文章非常受歡迎,并促使我思考如何設計出高質(zhì)量的Cassandra數(shù)據(jù)模型,以避免在設計的過程中掉入陷阱。
在互聯(lián)網(wǎng)上,你可以找到很多有關適配數(shù)據(jù)模型設計規(guī)則和設計模式的優(yōu)秀文章,例如:Apache Cassandra數(shù)據(jù)建模指南和數(shù)據(jù)建模優(yōu)秀實踐 。
然而,我們并沒有一個詳細的操作步驟來指導你對數(shù)據(jù)進行分析,并適配相應的規(guī)則和模式。但這份白皮書正嘗試著填補這方面的空白。
第一階段:了解數(shù)據(jù)
這個階段有兩個步驟,這兩個步驟都是為了更好地理解你正在建模的數(shù)據(jù)和所需的訪問模式。
定義數(shù)據(jù)域
第一步是深入理解數(shù)據(jù)域。作為一個非常熟悉關系數(shù)據(jù)建模的人,我傾向于通過繪制ER圖來理解這些實體、主鍵和互相之間的關系。但是,如果你熟悉另一種標記法,你也可以用一下試試。你需要在邏輯層面理解以下關鍵點:
數(shù)據(jù)模型中的實體(或?qū)ο螅┦鞘裁矗?/p>
實體的主要關鍵屬性是什么?
實體之間有哪些關系(即從一個到另一個的引用)?
關系的相對基數(shù)是多少(例如,假設存在一對多的關系,那么平均是1對10,還是1對10000)?
定義所需的訪問模式
下一步,弄清楚你自己需要如何訪問數(shù)據(jù):
列出需要訪問數(shù)據(jù)的路徑,例如:
以客戶ID為索引,在某個日期范圍內(nèi)搜索交易記錄,然后從搜索結果中搜索特定交易的詳細信息。按某個特定的服務器和度量標準搜索,檢索x度量值,按年齡升序排列。
按某個特定的服務器和度量檢索,從特定時間點開始檢索x度量值。
對于給定的傳感器,檢索給定日期的多個度量的所有讀數(shù)。
對于給定的傳感器,檢索當前值。
請記住,對記錄的任何更新操作都是一個訪問路徑,都需要仔細考慮。
從性能的角度來確定哪些訪問最關鍵。是否有一些訪問需要盡可能快的速度,而其他一些訪問則需要花一定的時間進行多次讀取或在一定范圍內(nèi)進行檢索?
請記住,在這個階段,你需要非常全面地了解如何訪問數(shù)據(jù),在Cassandra的性能、可靠性和可伸縮性之間做出權衡。
第二階段:了解實體
這個階段有兩個具體的步驟,旨在了解與數(shù)據(jù)相關的主要和次要實體。
確定主要訪問實體
現(xiàn)在,我們開始從分析數(shù)據(jù)域和應用需求轉(zhuǎn)為開始設計數(shù)據(jù)模型了。在進入這個階段之前,你需要把上面兩個步驟的工作做得扎實一點。
這一階段主要的想法是根據(jù)你所使用的訪問模式將數(shù)據(jù)去規(guī)范化到盡可能少的表中。對于每一次按鍵進行的查詢,需要有一張表來滿足查詢需求。我創(chuàng)造了一個術語“主要訪問實體”來描述用于查詢的實體(例如,按客戶ID進行的查找將使用客戶表作為主要訪問實體,按服務器和度量名稱的查找將使用服務器-度量實體作為主要訪問實體)。
主要訪問實體定義了去規(guī)范化結果表的分區(qū)級別(即表會為每個主要訪問實體的實例提供一個分區(qū))。
你可以選擇使用二級索引來滿足一些訪問模式,而不是使用不同的主要訪問實體來實現(xiàn)數(shù)據(jù)復制。請記住,包含在輔助索引中的列應比被索引的表的基數(shù)更低,并且你要對索引值的更新頻率了如指掌。
對于上面舉的訪問模式的例子,我們將定義以下主要訪問實體:
客戶和交易(從客戶實體獲取交易清單,然后從交易實體查找交易詳情)
服務器-度量
傳感器
傳感器
分配次要實體
下一步是尋找一個地方用來存儲那些沒有被選為主要訪問實體的實體數(shù)據(jù)(這些實體被稱為次要實體)。你可以這樣做:
通過從一對多關系的父級次要實體獲取數(shù)據(jù)并在主要訪問實體級別存儲它的多個副本(例如,將客戶的電話號碼存儲在客戶的訂單記錄中)。
通過從一對多關系的子次要實體獲取數(shù)據(jù)并通過使用聚集鍵或通過使用多值類型(列表和映射)將其存儲在主要訪問實體級別上(例如,將記錄項列表添加到交易表中)。
對于一些次要實體,只有一個相關的主要訪問實體,所以不需要選擇在哪個方向推入數(shù)據(jù)。對于其他實體,你需要選擇將數(shù)據(jù)推入哪些主要訪問實體。
為了獲得最佳的讀取性能,需要將數(shù)據(jù)副本推送到用作次要實體中數(shù)據(jù)訪問路徑的每個主要訪問實體中。
然而,維護多個副本數(shù)據(jù)會影響到數(shù)據(jù)插入和更新的性能,并會增加應用程序的復雜性。因此,需要根據(jù)應用程序指定的性能要求在讀取性能與數(shù)據(jù)維護成本之間做出權衡。
在這個階段要做出的另一個決定是要選擇使用聚集鍵還是多值類型來進行數(shù)據(jù)推升。一般來說:
在只有一個子次要實體向上推升的情況下使用聚集鍵,特別是在子次要實體本身有子節(jié)點上卷的情況下。
在有多個子實體推升到主要實體的時候使用多值類型
請注意,這些規(guī)則可能比較簡單,但它們可以引申出對這方面更深入的思考。
第三階段:審核與調(diào)優(yōu)
最后一個階段則是在必要的情況下對數(shù)據(jù)模型進行審核、測試,以及調(diào)優(yōu)。
審核分區(qū)和聚集鍵
在這個階段中,你需要將所有需要存儲的數(shù)據(jù)分配到一個或多個表中,并且這些表需要支持所需的訪問模式。下一步是檢查生成的數(shù)據(jù)模型是否有效地使用了Cassandra,如果沒有,則進行調(diào)優(yōu)。在這個階段,需要檢查和調(diào)整的內(nèi)容包括:
分區(qū)鍵是否有足夠的基數(shù)?如果沒有,則可能需要將列從聚集鍵變?yōu)榉謪^(qū)鍵(例如,將主鍵(client_id,timestamp)更改為主鍵((client_id,timestamp)))或引入將多個聚集鍵分組為分區(qū)的新列(例如,將主鍵(client_id,timestamp)更改為主鍵((client_id,day),timestamp))。
分區(qū)鍵中的值是否會經(jīng)常更新?對主鍵的更新將導致記錄的刪除和重新插入。例如,在一個維護了所有客戶的狀態(tài)的表中,可能有主鍵(狀態(tài),客戶ID)。但是,這將導致每當客戶狀態(tài)發(fā)生變化時都需要刪除并重新插入記錄。在這種情況下,最好選擇集合或列表數(shù)據(jù)類型,而不是將客戶ID作為聚集鍵。
每個分區(qū)中的記錄數(shù)是否有限制?特別大的分區(qū)和或者分布非常不均勻的分區(qū)可能會出現(xiàn)問題。例如,假設有一張client_updates表,其主鍵為(client_id,update_timestamp),則客戶記錄的更新次數(shù)可能并沒有限制,因為可能有少量的客戶已經(jīng)有10年未更新,而大多數(shù)客戶只有一兩天而已。
測試和調(diào)優(yōu)
最后一步,也可能是最重要的,即對數(shù)據(jù)模型進行測試,并根據(jù)需要進行調(diào)優(yōu)。請記住,像分區(qū)或記錄數(shù)增長過快的問題只有在實際負載下使用幾天(或更長時間)之后才能發(fā)現(xiàn)。因此,測試的時候需要盡可能地接近真實負載,并密切監(jiān)視各種警告信息(nodetool cfstats和cfhistograms命令對此非常有用)。
在這個階段,你也可以考慮調(diào)整一些影響數(shù)據(jù)物理存儲的設置。例如:
改變壓縮策略;
如果只使用TTL來刪除數(shù)據(jù)的話,則可以降低gc_grace_seconds,或者
設置緩存選項。
一個完整的例子
為了說明這一點,下文將介紹一個示例,該示例構建了一個數(shù)據(jù)庫,用于存儲和檢索來自多個服務器的日志消息。請注意,與大多數(shù)實際的案例相比,這個例子非常簡單。
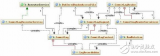
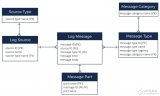
步驟1:定義數(shù)據(jù)域
上面的ER圖描述了本示例的數(shù)據(jù)域,包括:
有很多(百萬數(shù)量級)的日志消息,有時間戳和主體。盡管消息ID在ER圖中顯示為主鍵,但消息時間加消息類型是備用主鍵。
每個日志消息都有一個消息類型,多個類型被進一步分組為一個消息類別(例如,消息類型可能是“內(nèi)存不足錯誤”,類別可能是“錯誤”)。有幾百個消息類型和大約20個類別。
每個日志消息來自一個消息源。消息源是生成消息的服務器。我們的系統(tǒng)中有1000臺服務器。每個消息源都有一個源類型對其進行分類(如紅帽服務器、Ubuntu服務器、Windows服務器、路由器等)。有大約20個源類型。每個源每天有大約10000條消息。
消息體可以被解析并存儲為多個消息體(一般來說是鍵值對)。每條消息通常不超過20個消息體。
步驟2:定義所需的訪問模式
我們需要能夠:
檢索給定源的最近10條消息的所有可用信息(并且能夠從中及時回溯)。
檢索給定源類型的最近10條消息的所有可用信息。
步驟3:確定主要訪問實體
這里有兩個主要訪問實體:源和源類型。源類型的基數(shù)(約為20)使其非常適合成為二級索引,所以我們將使用源作為主要訪問實體,并添加源類型為二級索引。
步驟4:分配次要實體
在這個例子中,這個步驟相對簡單,因為所有數(shù)據(jù)都需要滾入到日志源主要訪問實體中。所以我們需要:
下推源類型名稱
下推消息類別和消息類型以記錄消息
上推日志消息,使其作為新實體的聚集鍵
作為map類型上推消息體。
最終這將是一個帶有源ID分區(qū)鍵和(消息時間,消息類型)聚集鍵的單個表。
步驟5:審核分區(qū)和聚集鍵
根據(jù)檢查清單檢查這些分區(qū)和聚集鍵:
分區(qū)鍵是否有足夠的基數(shù)?是的,有1000個源。
分區(qū)鍵中的值是否會經(jīng)常更新?不,所有的數(shù)據(jù)都是一次寫入的。
每個分區(qū)中的記錄數(shù)是否有限制?不,消息數(shù)可能會隨著時間的推移而無限地增長。所以,我們需要解決無限分區(qū)大小的問題。在時間序列數(shù)據(jù)中,解決這個問題的典型模式是將一組時間段引入到聚集鍵中。在這種情況下,每天10000條消息是一個比較合理的數(shù)字,可以包含在一個分區(qū)中,因此我們將使用“天”作為分區(qū)鍵的一部分。
最后,Cassandra結果表是這樣的:
CREATETABLEexample.log_messages ( message_id uuid, source_name text, source_type text, message_type text, message_urgencyint, message_category text, message_timetimestamp, message_time_day text, message_body text, message_parts map
?




























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論