 電子發燒友App
電子發燒友App


阿爾法圍棋(AlphaGo)是第一個擊敗人類職業圍棋選手、第一個戰勝圍棋世界冠軍的人工智能程序,由谷歌(Google)旗下DeepMind公司戴密斯·哈薩比斯領銜的團隊開發。
那么阿爾法狗的工作原理是什么?相關技術又有哪些呢?下面讓我們一起來看看。
阿爾法狗工作原理
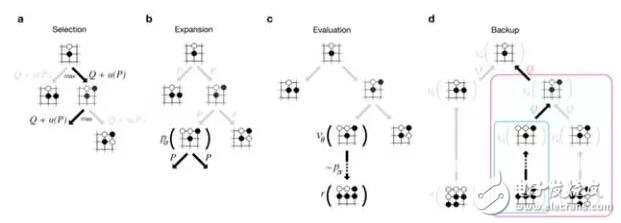
阿爾法圍棋(AlphaGo)為了應對圍棋的復雜性,結合了監督學習和強化學習的優勢。它通過訓練形成一個策略網絡(policynetwork),將棋盤上的局勢作為輸入信息,并對所有可行的落子位置生成一個概率分布。然后,訓練出一個價值網絡(valuenetwork)對自我對弈進行預測,以-1(對手的絕對勝利)到1(AlphaGo的絕對勝利)的標準,預測所有可行落子位置的結果。這兩個網絡自身都十分強大,而阿爾法圍棋將這兩種網絡整合進基于概率的蒙特卡羅樹搜索(MCTS)中,實現了它真正的優勢。新版的阿爾法圍棋產生大量自我對弈棋局,為下一代版本提供了訓練數據,此過程循環往復。
在獲取棋局信息后,阿爾法圍棋會根據策略網絡(policynetwork)探索哪個位置同時具備高潛在價值和高可能性,進而決定最佳落子位置。在分配的搜索時間結束時,模擬過程中被系統最頻繁考察的位置將成為阿爾法圍棋的最終選擇。在經過先期的全盤探索和過程中對最佳落子的不斷揣摩后,阿爾法圍棋的搜索算法就能在其計算能力之上加入近似人類的直覺判斷。
圍棋棋盤是19x19路,所以一共是361個交叉點,每個交叉點有三種狀態,可以用1表示黑子,-1表示白字,0表示無子,考慮到每個位置還可能有落子的時間、這個位置的氣等其他信息,我們可以用一個361*n維的向量來表示一個棋盤的狀態。我們把一個棋盤狀態向量記為s。
當狀態s下,我們暫時不考慮無法落子的地方,可供下一步落子的空間也是361個。我們把下一步的落子的行動也用361維的向量來表示,記為a。
這樣,設計一個圍棋人工智能的程序,就轉換成為了,任意給定一個s狀態,尋找最好的應對策略a,讓你的程序按照這個策略走,最后獲得棋盤上最大的地盤。
阿爾法狗三大核心技術
AlphaGo結合了3大塊技術:先進的搜索算法、機器學習算法(即強化學習),以及深度神經網絡。這三者的關系大致可以理解為:
1、蒙特卡洛樹搜索(MCTS)是大框架
實質上可以看成一種增強學習
蒙特卡羅樹搜索(MCTS)會逐漸的建立一顆不對稱的樹。可以分為四步并反復迭代:
(1)選擇
從根節點,也就是要做決策的局面R出發向下選擇一個最急迫需要被拓展的節點T;局面R是第一個被檢查的節點,被檢查的節點如果存在一個沒有被評價過的招式m,那么被檢查的節點在執行m后得到的新局面就是我們所需要展開的T;如果被檢查的局面所有可行的招式已經都被評價過了,那么利用ucb公式得到一個擁有最大ucb值的可行招式,并且對這個招式產生的新局面再次進行檢查;如果被檢查的局面是一個游戲已經結束的游戲局面,那么直接執行步驟4;通過反復的進行檢查,最終得到一個在樹的最底層的最后一次被檢查的局面c和它的一個沒有被評價過的招式m,執行步驟2。
(2)拓展
對于此時存在于內存中的局面c,添加一個它的子節點。這個子節點由局面c執行招式m而得到,也就是T。
(3)模擬
從局面T出發,雙方開始隨機的落子。最終得到一個結果(win/lost),以此更新T節點的勝利率。
(4)反向傳播
在T模擬結束之后,它的父節點c以及其所有的祖先節點依次更新勝利率。一個節點的勝利率為這個節點所有的子節點的平均勝利率。并從T開始,一直反向傳播到根節點R,因此路徑上所有的節點的勝利率都會被更新。
之后,重新從第一步開始,不斷地進行迭代。使得添加的局面越來越多,則對于R所有的子節點的勝利率也越來越準。最后,選擇勝利率最高的招式。
實際應用中,mcts還可以伴隨非常多的改進。我描述的這個算法是mcts這個算法族中最出名的uct算法,現在大部分著名的ai都在這個基礎上有了大量的改進了。 2、強化學習(RL)是學習方法,用來提升AI的實力。
2、強化學習 (RL) 是學習方法,用來提升AI的實力
強化學習是從動物學習、參數擾動自適應控制等理論發展而來,其基本原理是:
如果Agent的某個行為策略導致環境正的獎賞(強化信號),那么Agent以后產生這個行為策略的趨勢便會加強。Agent的目標是在每個離散狀態發現最優策略以使期望的折扣獎賞和最大。
強化學習把學習看作試探評價過程,Agent選擇一個動作用于環境,環境接受該動作后狀態發生變化,同時產生一個強化信號(獎或懲)反饋給Agent,Agent根據強化信號和環境當前狀態再選擇下一個動作,選擇的原則是使受到正強化(獎)的概率增大。選擇的動作不僅影響立即強化值,而且影響環境下一時刻的狀態及最終的強化值。
強化學習不同于連接主義學習中的監督學習,主要表現在教師信號上,強化學習中由環境提供的強化信號是Agent對所產生動作的好壞作一種評價(通常為標量信號),而不是告訴Agent如何去產生正確的動作。由于外部環境提供了很少的信息,Agent必須靠自身的經歷進行學習。通過這種方式,Agent在行動一一評價的環境中獲得知識,改進行動方案以適應環境。
強化學習系統學習的目標是動態地調整參數,以達到強化信號最大。若已知r/A梯度信息,則可直接可以使用監督學習算法。因為強化信號r與Agent產生的動作A沒有明確的函數形式描述,所以梯度信息r/A無法得到。因此,在強化學習系統中,需要某種隨機單元,使用這種隨機單元,Agent在可能動作空間中進行搜索并發現正確的動作。
3、深度神經網絡(DNN)是工具,用來擬合局面評估函數和策略函數
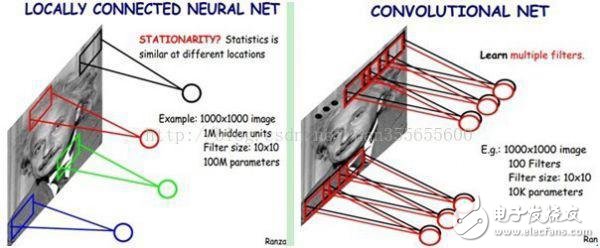
深度神經網絡,也被稱為深度學習,是人工智能領域的重要分支,根據麥卡錫(人工智能之父)的定義,人工智能是創造像人一樣的智能機械的科學工程。
通過比較當前網絡的預測值和我們真正想要的目標值,再根據兩者的差異情況來更新每一層的權重矩陣(比如,如果網絡的預測值高了,就調整權重讓它預測低一些,不斷調整,直到能夠預測出目標值)。因此就需要先定義“如何比較預測值和目標值的差異”,這便是損失函數或目標函數(lossfunctionorobjectivefunction),用于衡量預測值和目標值的差異的方程。lossfunction的輸出值(loss)越高表示差異性越大。那神經網絡的訓練就變成了盡可能的縮小loss的過程。
所用的方法是梯度下降(Gradientdescent):通過使loss值向當前點對應梯度的反方向不斷移動,來降低loss。一次移動多少是由學習速率(learningrate)來控制的。
總結
這三大技術都不是AlphaGo或者DeepMind團隊首創的技術。但是強大的團隊將這些結合在一起,配合Google公司強大的計算資源,成就了歷史性的飛躍。










 工商網監
工商網監
評論