 電子發燒友App
電子發燒友App


1.什么是決策樹
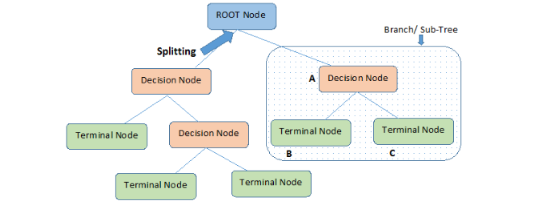
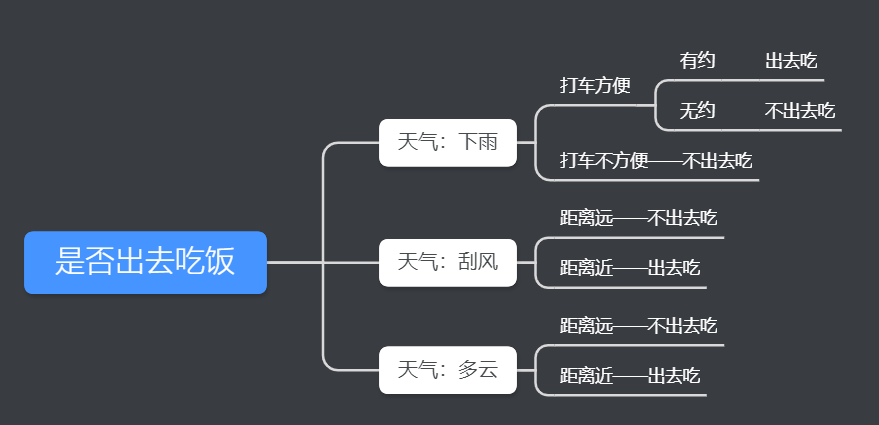
決策樹是一種基本的分類和回歸方法,本文主要講解用于分類的決策樹。決策樹就是根據相關的條件進行分類的一種樹形結構,比如某高端約會網站針對女客戶約會對象見面的安排過程就是一個決策樹:

根據給定的數據集創建一個決策樹就是機器學習的課程,創建一個決策樹可能會花費較多的時間,但是使用一個決策樹卻非常快。
創建決策樹時最關鍵的問題就是選取哪一個特征作為分類特征,好的分類特征能夠最大化的把數據集分開,將無序變為有序。這里就出現了一個問題,如何描述一個數據集有序的程度?在信息論和概率統計中,熵表示隨機變量不確定性的度量,即有序的程度。
現給出一個集合D,本文所有的討論都以該集合為例:
序號 不浮出水面是否可以生存 是否有腳蹼 是否為魚類
1?是?是?是?
2?是?是?是?
3?是?否?否?
4?否?是?否?
5?否?是?否
創建該集合的代碼如下:
def create_data_set():
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['no surfacing', 'flippers'] #不浮出水面是否可以生存,是否有腳蹼
return dataSet, labels
2.熵,信息增益和信息增益比
2.1熵(entropy)
博主第一次接觸“熵”這個字,是在高中的化學課上,但是感覺“熵”在化學課上的含義和信息論中的含義沒什么區別,都是表示混亂的程度,熵越大,越混亂,比如一杯渾濁水的熵就比一杯純凈的水熵大。
在信息論和概率統計中,設X是一個取有限個值的離散隨機變量,其概率分布為:

編寫計算熵的函數,其中dataSet是建立決策樹的數據集,每行最后一個元素表示類別:
def cal_Ent(dataSet): #根據給定數據集計算熵
num = len(dataSet)
labels = {}
for row in dataSet: #統計所有標簽的個數
label = row[-1]
if label not in labels.keys():
labels[label] = 0
labels[label] += 1
Ent = 0.0
for key in labels: #計算熵
prob = float(labels[key]) / num
Ent -= prob * log(prob, 2)
return Ent
2.2信息增益(information gain)
信息增益表示得知特征X的信息而使得類Y的信息的不確定性減少的程度。

當熵和條件熵中的概率由數據估計得到時,所對應的熵與條件熵分別稱為經驗熵和經驗條件熵。
決策樹選擇某個特征作為其分類特征的依據就是該特征對于集合的信息增益最大,即去除該特征后,集合變得最有序。仍舊以給定的集合D為例,根據計算信息增益準則選擇最優分類特征。
以X1表示“不浮出水面是否可以生存”,則

編寫選擇最佳決策特征的函數,其中dataSet是建立決策樹的數據集,每行最后一個元素表示類別:
#按照給定特征劃分數據集,返回第axis個特征的值為value的所有數據
def split_data_set(dataSet, axis, value):
retDataSet = []
for row in dataSet:
if (row[axis]) == value:
reducedRow = row[:axis]
reducedRow.extend(row[axis+1:])
retDataSet.append(reducedRow)
return retDataSet
#選擇最佳決策特征
def choose_best_feature(dataSet):
num = len(dataSet[0]) - 1 #特征數
baseEnt = cal_Ent(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(num):
featlist = [example[i] for example in dataSet] #按列遍歷數據集,選取一個特征的所有值
uniqueVals = set(featlist) #一個特征可以取的值
newEnt = 0.0
for value in uniqueVals:
subDataSet = split_data_set(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEnt += prob * cal_Ent(subDataSet)
infoGain = baseEnt - newEnt #信息增益
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
ID3決策樹在生成的過程中,根據信息增益來選擇特征。
2.3信息增益比(information gain ratio)
以信息增益作為劃分訓練數據集的特征,存在偏向于選擇取值較多的特征的問題,使用信息增益比可以對這一問題進行校正。

以給定的集合D為例,計算信息增益比。

根據信息增益比,選擇X1作為分類的最優特征。
C4.5決策樹在生成的過程中,根據信息增益比來選擇特征。
3.實現一個決策樹
3.1創建或載入數據集
首先需要創建或載入訓練的數據集,第一節用的是創建數據集的方法,不過更常用的是利用open()函數打開文件,載入一個數據集。
3.2生成決策樹
決策樹一般使用遞歸的方法生成。
編寫遞歸函數有一個好習慣,就是先考慮結束條件。生成決策樹結束的條件有兩個:其一是劃分的數據都屬于一個類,其二是所有的特征都已經使用了。在第二種結束情況中,劃分的數據有可能不全屬于一個類,這個時候需要根據多數表決準則確定這個子數據集的分類。
在非結束的條件下,首先選擇出信息增益最大的特征,然后根據其分類。分類開始時,記錄分類的特征到決策樹中,然后在特征標簽集中刪除該特征,表示已經使用過該特征。根據選中的特征將數據集分為若干個子數據集,然后將子數據集作為參數遞歸創建決策樹,最終生成一棵完整的決策樹。
#多數表決法則
def majorityCnt(classList):
print classList
classCount = {}
for vote in classList: #統計數目
if vote not in classCount.keys(): classCount[vote] = 0
classCount += 1
sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return classCount[0][0]
# 生成決策樹
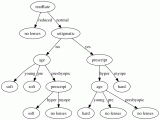
def create_tree(dataSet, labels):
labelsCloned = labels[:]
classList = [example[-1] for example in dataSet] #[yes,yes,no,no,no]
if classList.count(classList[0]) == len(classList): #只有一種類別,則停止劃分
return classList[0]
if len(dataSet[0]) == 1: #沒有特征,則停止劃分
return majorityCnt(classList)
#print dataSet
bestFeat = choose_best_feature(dataSet)
bestFeatLabel = labelsCloned[bestFeat] #最佳特征的名字
myTree = {bestFeatLabel:{}}
del(labelsCloned[bestFeat])
featValues = [example[bestFeat] for example in dataSet] #獲取最佳特征的所有屬性
uniqueVals = set(featValues)
for value in uniqueVals: #建立子樹
subLabels = labelsCloned[:] #深拷貝,不能改變原始列表的內容,因為每一個子樹都要使用
myTree[bestFeatLabel][value] = create_tree(split_data_set(dataSet, bestFeat, value), subLabels)
return myTree
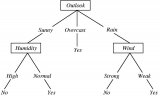
生成的決策樹如下所示:
3.3使用決策樹
使用決策樹對輸入進行分類的函數也是一個遞歸函數。分類函數需要三個參數:決策樹,特征列表,待分類數據。特征列表是聯系決策樹和待分類數據的橋梁,決策樹的特征通過特征列表獲得其索引,再通過索引訪問待分類數據中該特征的值。
def classify(tree, featLabels, testVec):
firstJudge = tree.keys()[0]
secondDict = tree[firstJudge]
featIndex = featLabels.index(firstJudge) #獲得特征索引
for key in secondDict: #進入對應的分類集合
if key == testVec[featIndex]: #按特征分類
if type(secondDict[key]).__name__ == 'dict': #如果分類結果是一個字典,則說明還要繼續分類
classLabel = classify(secondDict[key], featLabels, testVec)
else: #分類結果不是字典,則分類結束
classLabel = secondDict[key]
return classLabel
3.4保存或者載入決策樹
生成決策樹是比較花費時間的,所以決策樹生成以后存儲起來,等要用的時候直接讀取即可。
def store_tree(tree, fileName): #保存樹
import pickle
fw = open(fileName, 'w')
pickle.dump(tree, fw)
fw.close()
def grab_tree(fileName): #讀取樹
import pickle
fr = open(fileName)
return pickle.load(fr)
4.決策樹可視化
使用字典的形式表示決策樹對于人類來說還是有點抽象,如果能以圖像的方式呈現就很方便了。非常幸運,matplotlib中有模塊可以使決策樹可視化,這里就不講解了,直接“拿來使用”。將treePlotter.py拷貝到我們文件的根目錄,直接導入treePlotter,然后調用treePlotter.createPlot()函數即可:
import treePlotter
treePlotter.createPlot(tree)
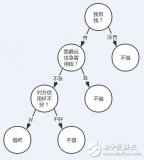
如上面的決策樹可視化后如下:

5.使用決策樹預測隱形眼鏡類型
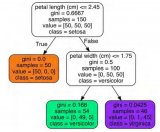
隱形眼鏡數據集包含患者的眼睛狀況以及醫生推薦的隱形眼鏡類型,患者信息有4維,分別表示年齡,視力類型,是否散光,眼睛狀況,隱形眼鏡類型有3種,分別是軟材質,硬材質和不適合帶隱形眼鏡。
想要把我們編寫的腳本應用于別的數據集?沒問題,只要修改載入數據集的函數即可,其他的函數不需要改變,具體如下:
#載入數據
def file2matrix():
file = open("lenses.data.txt")
allLines = file.readlines()
row = len(allLines)
dataSet = []
for line in allLines:
line = line.strip()
listFromLine = line.split()
dataSet.append(listFromLine)
labels = ['age', 'prescription', 'astigmatic', 'tear rate'] #年齡,視力類型,是否散光,眼睛狀況
return dataSet, labels
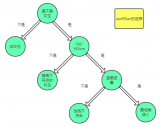
生成的決策樹可視化后如下:

其實博主還嘗試了其他的數據集,不過決策樹實在是太復雜了,太大了,密密麻麻根本看不清楚,誰有興趣可以嘗試一下別的數據集。














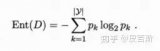








 工商網監
工商網監
評論