 電子發燒友App
電子發燒友App


一、最小均方算法(LMS)概述
1959年,Widrow和Hoff在對自適應線性元素的方案一模式識別進行研究時,提出了最小均方算法(簡稱LMS算法)。LMS算法是基于維納濾波,然后借助于最速下降算法發展起來的。通過維納濾波所求解的維納解,必須在已知輸入信號與期望信號的先驗統計信息,以及再對輸入信號的自相關矩陣進行求逆運算的情況下才能得以確定。因此,這個維納解僅僅是理論上的一種最優解。所以,又借助于最速下降算法,以遞歸的方式來逼近這個維納解,從而避免了矩陣求逆運算,但仍然需要信號的先驗信息,故而再使用瞬時誤差的平方來代替均方誤差,從而最終得出了LMS算法。
因LMS算法具有計算復雜程度低、在信號為平穩信號的環境中的收斂性好、其期望值無偏地收斂到維納解和利用有限精度實現算法時的穩定性等特性,使LMS算法成為自適應算法中穩定性最好、應用最廣泛的算法。
下圖是實現算法的一個矢量信號流程圖:
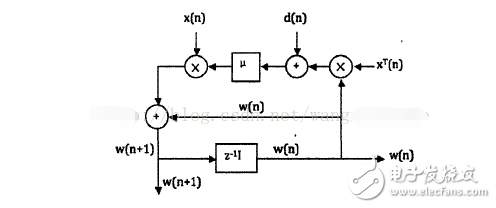
圖1 LMS算法矢量信號流程圖
由圖1我們可以知道,LMS算法主要包含兩個過程:濾波處理和自適應調整。
一般情況下,LMS算法的具體流程為:
(1)確定參數:全局步長參數β以及濾波器的抽頭數(也可以稱為濾波器階數)
(2)對濾波器初始值的初始化
(3)算法運算過程:
濾波輸出:y(n)=wT(n)x(n)
誤差信號:e(n)=d(n)-y(n)
權系數更新:w(n+1)=w(n)+βe(n)x(n)
二、性能分析
在很大程度上,選取怎樣的自適應算法決定著自適應濾波器是否具有好的性能。因此,對應用最為廣泛的算法算法進行性能分析則顯得尤為重要。平穩環境下算法的主要性能指標有收斂性、收斂速度、穩態誤差和計算復雜度等。
1、收斂性
收斂性就是指,當迭代次數趨向于無窮時,濾波器權矢量將達到最優值或處于其附近很小的鄰域內,或者可以說在滿足一定的收斂條件下,濾波器權矢量最終趨近于最優值。
2、收斂速度
收斂速度是指濾波器權矢量從最初的初始值向其最優解收斂的快慢程度,它是判斷LMS算法性能好壞的一個重要指標。
3、穩態誤差
穩態誤差,是指當算法進入穩態后濾波器系數與最優解之間距離的遠近情況。它也是一個衡量LMS算法性能好壞的重要指標。
4、計算復雜度
計算復雜度,是指在更新一次濾波器權系數時所需的計算量。LMS算法的計算復雜度還是很低的,這也是它的一大特點。
三、LMS算法分類
1、量化誤差LMS算法
在回聲消除和信道均衡等需要自適應濾波器高速工作的應用中,降低計算復雜度是很重要的。LMS算法的計算復雜度主要來自在進行數據更新時的乘法運算以及對自適應濾波器輸出的計算,量化誤差算法就是一種降低計算復雜度的方法。其基本思想是對誤差信號進行量化。常見的有符號誤差LMS算法和符號數據LMS算法。
2、解相關LMS算法
在LMS算法中,有一個獨立性假設橫向濾波器的輸入u(1),u(2),…, u(n-1)是彼此統計獨立的向量序列。當它們之間不滿足統計獨立的條件時,基本LMS算法的性能將下降,尤其是收斂速度會比較慢。為解決此問題,提出了解相關算法。研究表明,解相關能夠有效加快LMS算法的收斂速度。解相關LMS算法又分為時域解相關LMS算法和變換域解相關LMS算法。
3、并行延時LMS算法
在自適應算法的實現結構中,有一類面向VLSI的脈動結構,由于其具有的高度并行性和流水線特性而備受關注。將算法直接映射到脈動結構時,在權值更新和誤差計算中存在著嚴重的計算瓶頸。該算法解決了算法到結構的計算瓶頸問題,但當濾波器階數較長時,算法的收斂性能會變差,這是由于其本身所具有的延時影響了它的收斂性能。可以說,延時算法是以犧牲算法的收斂性能為代價的。
4、自適應格型LMS算法
LMS濾波器屬于橫向自適應濾波器且假定階數固定,然而在實際應用中,橫向濾波器的最優階數往往是未知的,需要通過比較不同階數的濾波器來確定最優的階數。當改變橫向濾波器的階數時,LMS算法必須重新運行,這顯然不方便而且費時。格型濾波器解決了這一問題。
格型濾波器具有共軛對稱的結構,前向反射系數是后向反射系數的共軛,其設計準則和LMS算法一樣是使均方誤差最小。
5、Newton-LMS算法
Newton-LMS算法是對環境信號二階統計量進行估計的算法。其目的是為了解決輸入信號相關性很高時算法收斂速度慢的問題。一般情況下,牛頓算法能夠快速收斂,但對R-1的估計所需計算量很大,而且存在數值不穩定的問題。
四、LMS算法基本原理
根據小均方誤差準則以及均方誤差曲面,自然的我們會想到沿每一時刻均方誤差 的陡下降在權向量面上的投影方向更新,也就是通過目標函數k反梯度向量來反 復迭代更新。由于均方誤差性能曲面只有一個唯一的極小值,只要收斂步長選擇恰當, 不管初始權向量在哪,后都可以收斂到誤差曲面的小點,或者是在它的一個鄰域內。 這種沿目標函數梯度反方向來解決小化問題的方法,我們一般稱為速下降法,表達式如下:
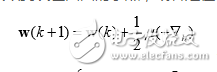
基于隨機梯度算法的小均方 自適應濾波算法的完整表達式如下:
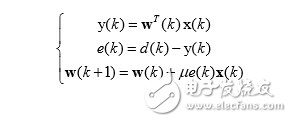
LMS 自適應算法是一種特殊的梯度估計,不必重復使用數據,也不必對相關矩陣 和互相關矩陣 進行運算,只需要在每次迭代時利用輸入向量和期望響應,結構簡單, 易于實現。雖然 LMS 收斂速度較慢,但在解決許多實際中的信號處理問題,LMS 算法 是仍然是好的選擇。
3 LMS算法性能分析
隨機梯度 LMS 算法的性能前人有過大量研究,按照前一章所提到的自適應濾波性能 指標,假設輸入信號和期望信號具有聯合平穩性,詳細討論基于橫向 FIR 結構的濾波器 的標準 LMS 算法的四個性能:一、收斂性;二、收斂速度;三、穩態誤差;四、計算復 雜度。 只有在輸入信號具有嚴格穩定的統計特性時,權向量的優解是不變的。否則, 將會隨著統計特性的變化而變化。自適應算法則能夠通過不斷的調整濾波器權向量,使權向量接近優解 。因此,自適應算法在平穩條件下的性能表現可以認為是非平穩條件下的一種特殊情況。如果在平穩條件下,自適應算法能夠快 速,平穩的逼近權向量的優值,那么在非平穩條件下,該算法也能很好的逼近時變的 權向量優解。
五、算法流程
下面介紹一下LMS算法的基本流程。
1. 初始化工作,為各個輸入端的權值覆上隨機初始值;
2. 隨機挑選一組訓練數據,進行計算得出計算結構C;
3. 利用公式3對每一個輸入端的權值進行調整;
4. 利用公式1計算出均方差MSE;
5. 對均方差進行判斷,如果大于某一個給定值,回到步驟2,繼續算法;如果小于給定值,就輸出正確權值,并結束算法。
六、算法實現
以下就給出一段LMS算法的代碼。
[cpp] view plain copyconst unsigned int nTests =4;
const unsigned int nInputs =2;
const double rho =0.005;
struct lms_testdata
{
doubleinputs[nInputs];
doubleoutput;
};
double compute_output(constdouble * inputs,double* weights)
{
double sum =0.0;
for (int i = 0 ; i 《 nInputs; ++i)
{
sum += weights[i]*inputs[i];
}
//bias
sum += weights[nInputs]*1.0;
return sum;
}
//計算均方差
double caculate_mse(constlms_testdata * testdata,double * weights)
{
double sum =0.0;
for (int i = 0 ; i 《 nTests ; ++i)
{
sum += pow(testdata[i].output -compute_output(testdata[i].inputs,weights),2);
}
return sum/(double)nTests;
}
//對計算所得值,進行分類
int classify_output(doubleoutput)
{
if(output》 0.0)
return1;
else
return-1;
}
int _tmain(int argc,_TCHAR* argv[])
{
lms_testdata testdata[nTests] = {
{-1.0,-1.0, -1.0},
{-1.0, 1.0, -1.0},
{ 1.0,-1.0, -1.0},
{ 1.0, 1.0, 1.0}
};
doubleweights[nInputs + 1] = {0.0};
while(caculate_mse(testdata,weights)》 0.26)//計算均方差,如果大于給定值,算法繼續
{
intiTest = rand()%nTests;//隨機選擇一組數據
doubleoutput = compute_output(testdata[iTest].inputs,weights);
doubleerr = testdata[iTest].output - output;
//調整輸入端的權值
for (int i = 0 ; i 《 nInputs ; ++i)
{
weights[i] = weights[i] + rho * err* testdata[iTest].inputs[i];
}
weights[nInputs] = weights[nInputs] +rho * err;
cout《《“mse:”《《caculate_mse(testdata,weights)《《endl;
}
for(int w = 0 ; w 《 nInputs + 1 ; ++w)
{
cout《《“weight”《《w《《“:”《《weights[w]《《endl;
}
cout《《“\n”;
for (int i = 0 ;i 《 nTests ; ++i)
{
cout《《“rightresult:êo”《《testdata[i].output《《“\t”;
cout《《“caculateresult:” 《《 classify_output(compute_output(testdata[i].inputs,weights))《《endl;
}
//
char temp ;
cin》》temp;
return 0;
}




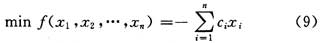











 工商網監
工商網監
評論