 電子發燒友App
電子發燒友App


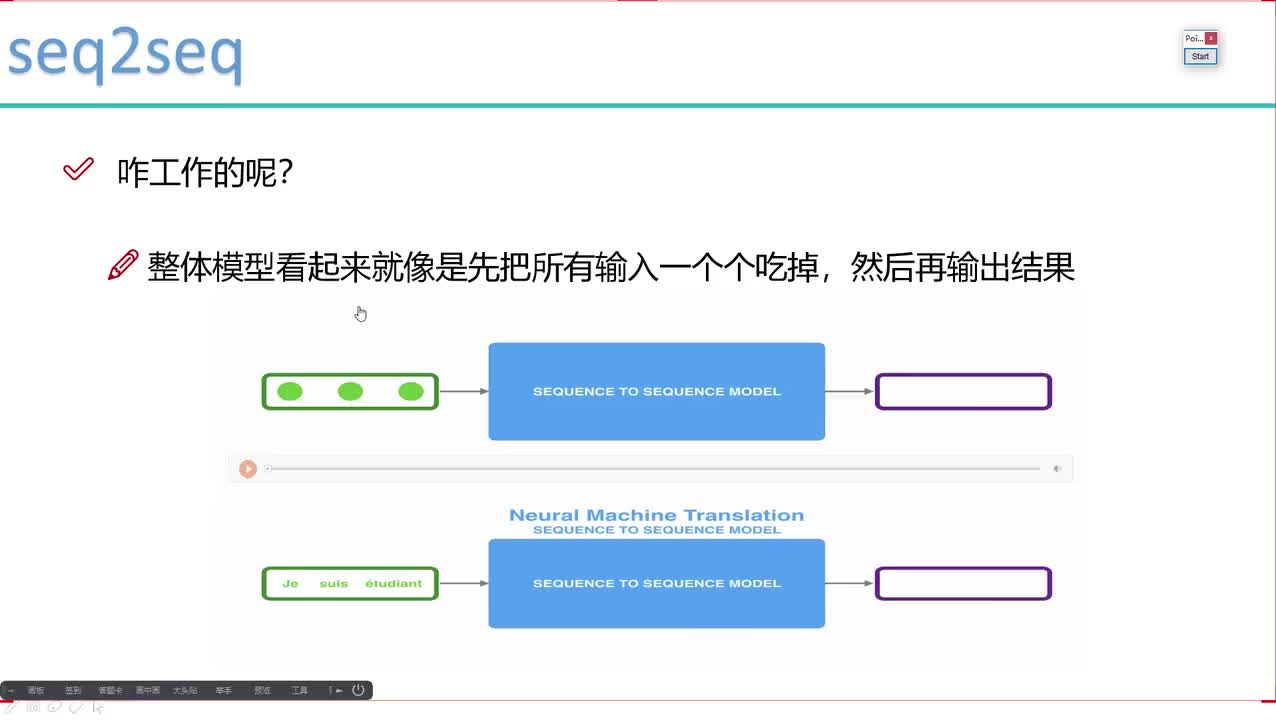
在AI技術發展的過程中自然語言處理技術已經成了最重要的一大體系,隨著年代的定義越加細分化語言識別逐漸區分為語音識別和語義識別兩個概念。一字之差卻大不相同。語音識別是前提語義識別才是它的目標。從語音識別到語義識別,中間還有多長的路要走?
最近科技圈刮起一股收購風,前面博通收購高通還在如火如荼的進行,這周蘋果就宣布收購音樂識別軟件Shazam。Shazam這個軟件,通過手機麥克風收錄音頻片段,能夠識別音樂、電影、電視節目甚至是廣告。那么蘋果公司整合這項技術做什么?很大可能是為了其人工智能助理軟件Siri。
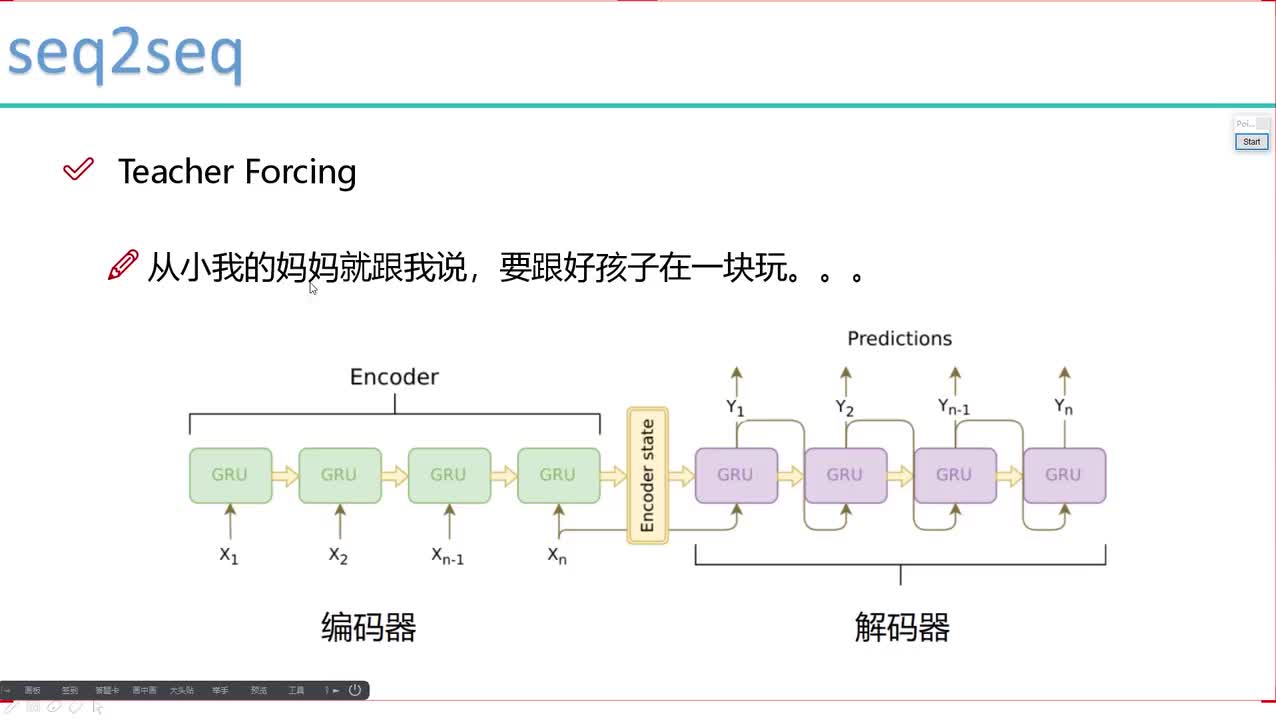
Siri使用自然語言處理技術,是AI技術的一大體系,而隨著近年定義和產業分工越發精細,語言識別漸漸分成了語音識別和語義識別兩個支系。語音和語義雖只有一字之差,卻有很大的不同。
打個簡單的比方,語音識別相當于是人的耳朵,而語義識別則是大腦,語音識別幫助機器獲取和輸出信息,那么語義識別則是對這些信息進行識別加工。
在這里, 小編舉個例子來幫助大家更好的理解上面的話:
爸爸沒法舉起他的兒子,因為他很重。
問:誰重?
爸爸沒法舉起他的兒子,因為他很虛弱。
問:誰虛弱?
可以看到,這兩個句子結構完全一致,后面的“他”指的到底是爸爸還是爸爸的兒子?這對于我們來說輕而易舉,因為我們有能清楚的通過我們積累的知識知道:爸爸舉不起兒子,要么兒子太重,爸爸舉不起;要么兒子不重,但是爸爸力氣小,比較虛弱,因此舉不起兒子。
但是對于一個只會語音識別的機器來說,它不會去思考句子中的“他”到底指的兒子還是爸爸,事實上,它也“想不清楚”。但是通過語義識別,機器會對聽到的信息進行加工理解,從而給出正確的答案。
與語音識別相比,顯然語義識別顯然要更深一個層次,用到的技術也更為復雜。
本期《趣科技》, 小編就給大家介紹一下人工智能中,自然語言識別這一重要支系。
語音識別發展史
語音是最自然的交流方式,自從1877年愛迪生發明了留聲機,人們就開始了與機器的交談,但是主要還是與人交流,而非機器本身。
1950年,計算機科學之父阿蘭·圖靈在《Mind》雜志上發表了題為《計算的機器和智能》的論文,首次提出了機器智能的概念,論文還提出了一種驗證機器是否有智能的方法:讓人和機器進行交流,如果人無法判斷自己交流的對象是人還是機器,就說明這個機器有智能了,這就是后來鼎鼎有名的人工智能圖靈測試。
到20世紀80年代,語音識別技術能夠將口語轉化為文本。
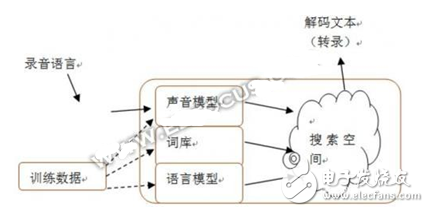
2001年,計算機語音識別達到了80%的準確度。從那時起,我們就可以提取口語語言的含義并作出回應。然而,多數情況下,語音技術仍然不能像鍵盤輸入那樣帶給我們足夠好的交流體驗。
近幾年來,語音識別又取得了巨大的技術進步。科大訊飛董事長劉慶峰在一次演講中,在演講的同時使用著最新的智能語音識別技術——可以讓他演講的內容實時以中英文雙字幕的形式呈現在大屏幕上,反應迅速、幾乎沒錯。識別精確度超過95%。隨著這項技術的進步,語音優先的基礎設施變得越來越重要,亞馬遜、蘋果、谷歌、微軟和百度都迅速部署了聲音優先軟件、軟件構建快和平臺。
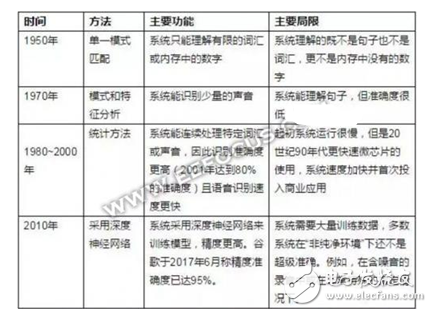
圖|語音發展史
語音識別產品應用
語音識別作為打造良好交互體驗的重要前提,今年的發展可謂是持續火爆。在智能音箱市場,首先想到的就是Amazon的Echo。Echo作為將自然語音轉化為在線指令的設備,其效率之高無容置疑,并且可保持在線的自然環境中的自然語言識別。
Echo的核心技術在于它集成的智能語音助手Alexa。在2015年6月25日亞馬遜曾宣布,將開放智能語音硬件Echo的內置AI助手Alexa的語音技術,供第三方開發者免費使用。由此可見,亞馬遜向用戶呈現出來的不僅僅是技術上的領先,還有真正落地的產品,以及良好的產品體驗。
與此同時,國內語音識別領域也開始爭奪大戰。以科大訊飛聽見系列產品為例,自2015年發布以來,總用戶突破1000萬,應用于30余個行業。目前,已經形成了以聽見智能會議系統、訊(詢)問筆錄系統、聽見轉寫網站、錄音寶APP、聽見智能會議服務等以智能語音轉寫技術為核心的產品和服務體系。
語音識別技術瓶頸
從下圖可以看出,語音識別的誤字率呈明顯的下降趨勢。
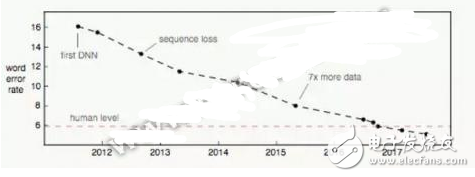
然而,即使達到100%的準確率,僅限于輸入法功用的語音識別也無人機互動的意義,它還算不得真正的人工智能。
我們所期望的語音識別實質上是人機交互,大致上可以理解為人與機器之間無障礙溝通。要達到這種期望,光靠誤字率很低甚至為零的語音識別可能并不能做到,那么就需要有“大腦”的語義識別了,相對于語音識別,它可以通過人們的語氣、談話的內容等等判斷用戶說的話到底是什么意思,而不是簡單的一字不落的識別出所說的內容。比如說:小沈陽長得可真帥!在不同的語境下卻有著截然相反的意思。
從“傻白甜”的語音識別到“帶腦子”的語義識別,還有很長的路要走。
口音和噪聲
語音識別中最明顯的一個缺陷就是對口音和背景噪聲的處理。最直接的原因是大部分的訓練數據都是高信噪比、美式口音的英語。
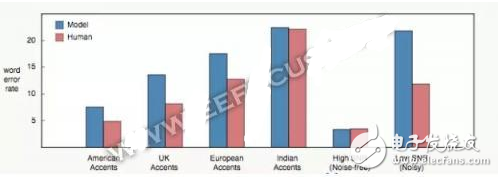
上圖中可以看到有口音的情況下,人的錯誤率低于模型;從高信噪比到低信噪比,人與模型之間的錯誤率差距急劇擴大。
語義錯誤
實際上語音識別系統的目標并不是誤字率。人們更關心的是語義錯誤率。
舉個語義錯誤的例子,比如某人說“let’s meet up Tuesday”,但語音識別預測為“let’s meet up today”。我們也可能在單詞錯誤的情況下保持語義正確,比如語音識別器漏掉了“up”而預測為“let’s meet Tuesday”,這樣話語的語義是不變的。
將模型與人工進行比較時的重點是查找錯誤的本質,而不僅僅是將誤字率作為一個決定性的數字。
微軟研究人員將他們的人工級語音識別器的錯誤與人類進行過比較。他們發現的一個差異是該模型比人更頻繁地混淆“uh”和“uh huh”。而這兩條術語的語義大不相同:“uh”只是個填充詞,而“uh huh”是一個反向確認。這個模型和人出現了許多相同類型的錯誤。
單通道和多人會話
一個好的會話語音識別器必須能夠根據誰在說話對音頻進行劃分,還應該能弄清重疊的會話(聲源分離)來理解音頻。
一個人在一個有多個人說話的環境中的時候,能夠很容易的分辨出自己要與某人說話,并且能夠在同時與多個人交談。很明顯,目前的語音識別器并不能做到這一點。當多個人對著麥克風講話時,它可能直接就“懵”了。
上下文理解
實際生活中我們會使用許多其他的線索來輔助理解別人在說什么。
列舉幾個人類使用上下文而語音識別器沒有的情況:
歷史會話和討論過的話題;
說話人的視覺暗示,包括面部表情和嘴唇動作;
關于會話者的背景。
可以看到雖然目前語音識別技術的誤字率已經低于5%,但想從語音識別轉變成真正的語義識別,是仍然面臨著很多挑戰。
語音識別到真正的語義識別
語音識別和語義識別合起來的語言識別雖然為人工智能的一大支系,但是比起語音識別,顯然語義識別要更加智能。在這里, 小編先給大家梳理一下人工智能,機器學習,深度學習,神經網絡這些術語之間的關系,大家或許就更加能理解從語音識別到真正的語義識別還有哪些路要走(目前市場上有很多做語義識別的公司,但是跟人類相比還存在一定的距離。)?
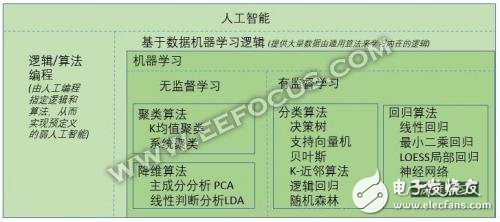
人工智能(AI)是一個大的概念,它是機器學習的父類。
除學習之外的人工智能可以歸納成了“邏輯/算法編程”,也就是通過編程將人類所知的知識和邏輯告訴機器,從而借助機器的高速計算和海量存儲等能力實現一些人類才能做的“弱智能”工作,像上世紀深藍計算機,將國際象棋中所有可能的結果都通過預先編好的程序計算出來從而選擇最佳的下法(窮舉法)。從程序的實現上來說恐怕就是無數的if…else…吧。
而另一類就是基于數據的自我學習,把大量的數據告訴機器由機器自己去分析這些數據從而總結得出某種規律/邏輯,然后利用這種邏輯來處理新的數據。
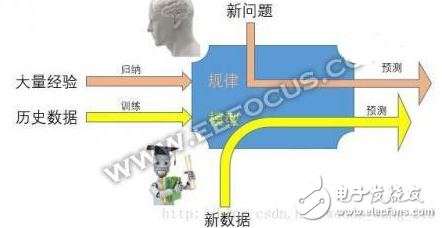
毫無疑問,學習是人工智能中最為火熱和最有前途的方向,讓人去“學習”那么復雜的邏輯來告訴機器怎么做還不如讓機器自己來學習呢,畢竟人都是懶的嘛,而“懶”就是人類進步的動力!
學習是不斷的訓練過程,其模型是在連續的優化調整中,隨著訓練數據越多其模型越準確,但是人類的學習不僅僅是一個連續學習過程,還有一種跳躍式學習,也就是常說的“頓悟”,這點是機器學習目前所沒有的。
也就是說,要從語音識別成功轉變成真正意義上的語義識別,首先要獲得大量的數據(比如說普通話,上海方言等),用過這些數據不斷訓練,來提高識別的準確率。
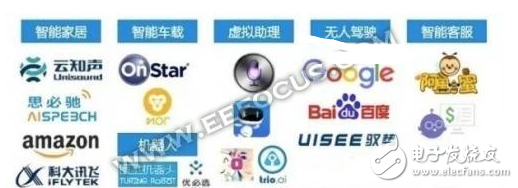
圖|語義識別市場
雖說實現真正的語義識別不容易,但是就目前的市場分析來看,語義識別已經滲透到了我們的生活之中,作為人工智能的基礎性技術之一,隨著技術的不斷成熟,語義識別將不斷地改變更多的傳統行業。
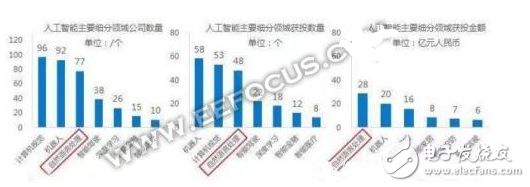
圖|人工智能各分支占比
在人工智能的整個領域里,自然語言處理無論是在創業熱度/獲投數量還是獲投金額都處于細分領域的前三名。據有關數據分析,預計到2024年,市場規模可達110億美元。并且在這個領域還沒有出現巨頭,這塊蛋糕還給創業者留有大量的余地。可以說語音識別(在這里指的整個語言識別)未來的市場發展十分有看頭。
想象一下,當語音識別發展到一定程度,我們坐在電視機前就可以語音遙控想看的節目。假如你要看英劇《神探夏洛克》,經常會被人叫成《神探夏洛特》(因為夏洛特更順嘴或者更普遍),這時候如果不做語義理解,可能你搜出來的名字就是《夏洛特煩惱》,因為它頻度也很高。
圖|語義識別帶來的人機交互
專做語義識別的三角獸公司CTO亓超對以上現象如此解釋:當你沒有辦法記住片子完整名字時,語義識別需要給你做糾正,做更合適處理。其實用戶在看電視產生很大需求,當用戶不知道要看什么,需要機器幫忙做推薦和引導,而這個過程中精準化程度、和人性化程度取決于智能化程度。
當語音識別發展到一定的程度,語義識別或將成為新的主流。












 工商網監
工商網監
評論