 電子發(fā)燒友App
電子發(fā)燒友App


站在2018年,圖像分類準(zhǔn)確率在95%以上的模型,已經(jīng)遍地都是。
回想2012年,Hinton帶著學(xué)生們以ImageNet上16.4%的錯(cuò)誤率震驚計(jì)算機(jī)視覺(jué)研究界,似乎已經(jīng)是遠(yuǎn)古時(shí)期的歷史。
這些年來(lái)的突飛猛進(jìn),真的可信嗎?
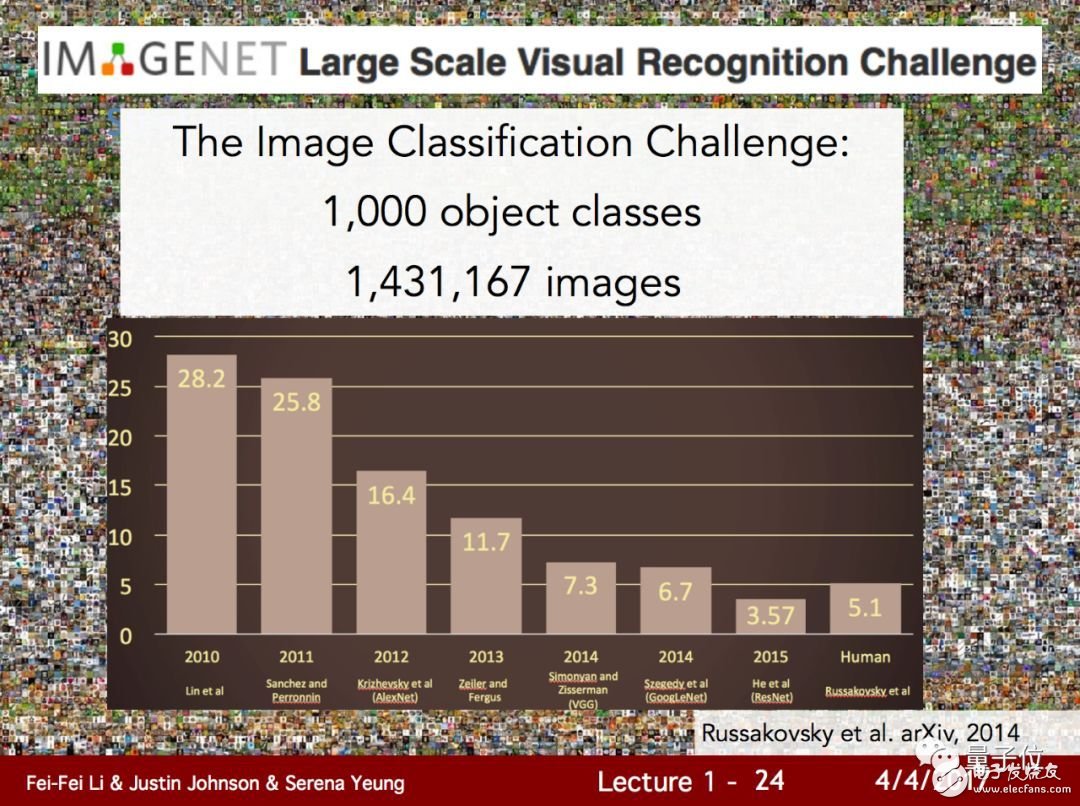
最近一項(xiàng)研究引出了一些反思:這些進(jìn)步很可疑。
這項(xiàng)研究,就是加州大學(xué)伯克利分校和MIT的幾名科學(xué)家在arXiv上公開(kāi)的一篇論文:Do CIFAR-10 Classifiers Generalize to CIFAR-10?。
解釋一下,這個(gè)看似詭異的問(wèn)題——“CIFAR-10分類器能否泛化到CIFAR-10?”,針對(duì)的是當(dāng)今深度學(xué)習(xí)研究的一個(gè)大缺陷:
看起來(lái)成績(jī)不錯(cuò)的深度學(xué)習(xí)模型,在現(xiàn)實(shí)世界中不見(jiàn)得管用。因?yàn)楹芏嗄P秃陀?xùn)練方法取得的好成績(jī),都來(lái)自對(duì)于那些著名基準(zhǔn)驗(yàn)證集的過(guò)擬合。
論文指出,過(guò)去5年間,大多數(shù)發(fā)表的論文擁抱了這樣一種范式:一種新的機(jī)器學(xué)習(xí)方法在幾個(gè)關(guān)鍵基準(zhǔn)測(cè)試中數(shù)據(jù),就決定了它的地位。
然而,這種方法與前人相比,為什么會(huì)有這樣的進(jìn)步?卻很少有人解釋。我們對(duì)于進(jìn)步的感知主要基于幾個(gè)標(biāo)準(zhǔn)的基準(zhǔn)測(cè)試,比如CIFAR-10、ImageNet、MuJoCo。
這就帶來(lái)了一個(gè)關(guān)鍵的問(wèn)題:我們目前對(duì)機(jī)器學(xué)習(xí)進(jìn)步的衡量方法,有多可靠?
這個(gè)指控,幾乎要質(zhì)疑圖像分類算法幾年來(lái)的一切進(jìn)步。
空口無(wú)憑,如何證明?
為了說(shuō)明這個(gè)問(wèn)題,幾位作者拿出30個(gè)在CIFAR-10驗(yàn)證集上表現(xiàn)良好的圖像分類模型,換一個(gè)數(shù)據(jù)集來(lái)測(cè)試它們,用結(jié)果說(shuō)話。
CIFAR-10包含60000張32×32像素的彩色圖像,平均分為5個(gè)訓(xùn)練批次(batch)和1個(gè)測(cè)試批次圖像共有10類:飛機(jī)、小汽車、鳥(niǎo)、貓、鹿、狗、青蛙、船、卡車。

當(dāng)然,如果隨便找個(gè)數(shù)據(jù)集來(lái)測(cè)試,有欺負(fù)AI的嫌疑。他們?yōu)榇藢iT造了一個(gè)和CIFAR-10非常相似的測(cè)試集,包含2000張新圖片,一樣的圖片來(lái)源,一樣的數(shù)據(jù)子類別分布,甚至連構(gòu)建過(guò)程中的分工都學(xué)了過(guò)來(lái)。
這個(gè)新數(shù)據(jù)集,也就是論文標(biāo)題中提到的第二個(gè)CIFAR-10,確切地說(shuō)應(yīng)該是“高仿CIFAR-10的小型測(cè)試集”。
新測(cè)試集給模型帶來(lái)了明顯的打擊,戰(zhàn)況如下:
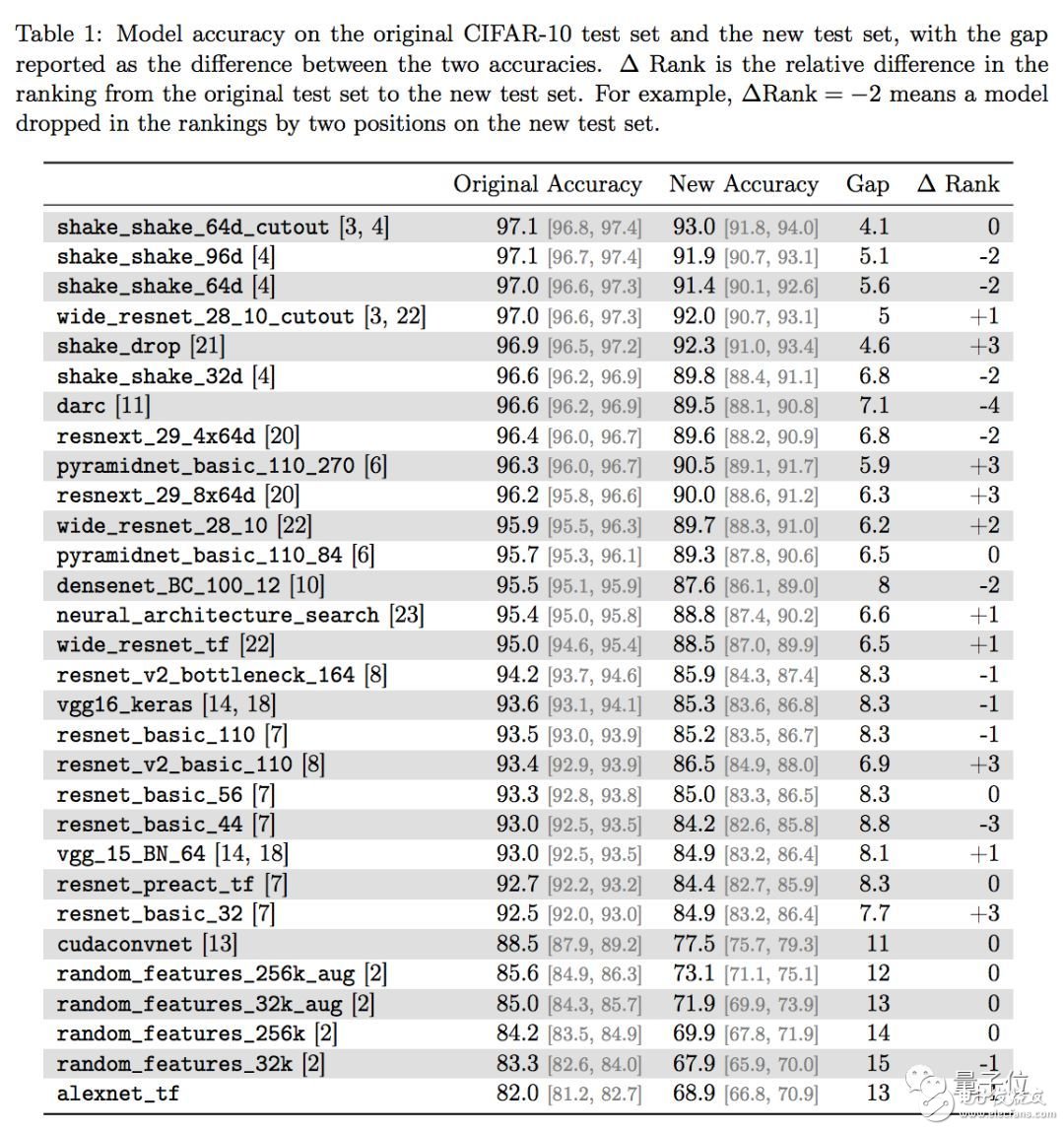
著名的VGG和ResNet,分類準(zhǔn)確率從93%左右下降到了85%左右,8個(gè)百分點(diǎn)憑空消失。
各位作者還在準(zhǔn)確率的差異上,發(fā)現(xiàn)了一個(gè)小趨勢(shì)。在原版CIFAR-10上準(zhǔn)確率比較高的那些新模型,在新測(cè)試集上的成績(jī)下滑不那么明顯。
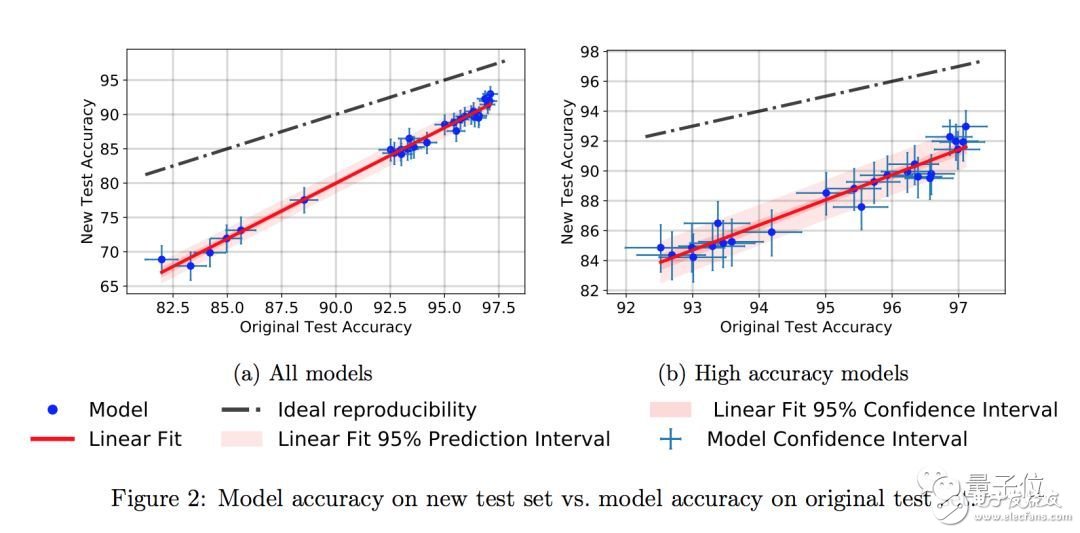
比如說(shuō)成績(jī)最好的Shake Shake模型,在新舊測(cè)試集上的準(zhǔn)確率只差4個(gè)百分點(diǎn)。
論文中說(shuō),這個(gè)小趨勢(shì)說(shuō)明換個(gè)數(shù)據(jù)集成績(jī)就下降可能不是因?yàn)榛谶m應(yīng)性的過(guò)擬合,而是因?yàn)樾屡f測(cè)試集之間,數(shù)據(jù)的分布上有一些小變化。
但終究,那些為CIFAR-10打造的分類器,泛化性能依然堪憂。
質(zhì)疑引熱議
這個(gè)研究如同一枚深水炸彈。
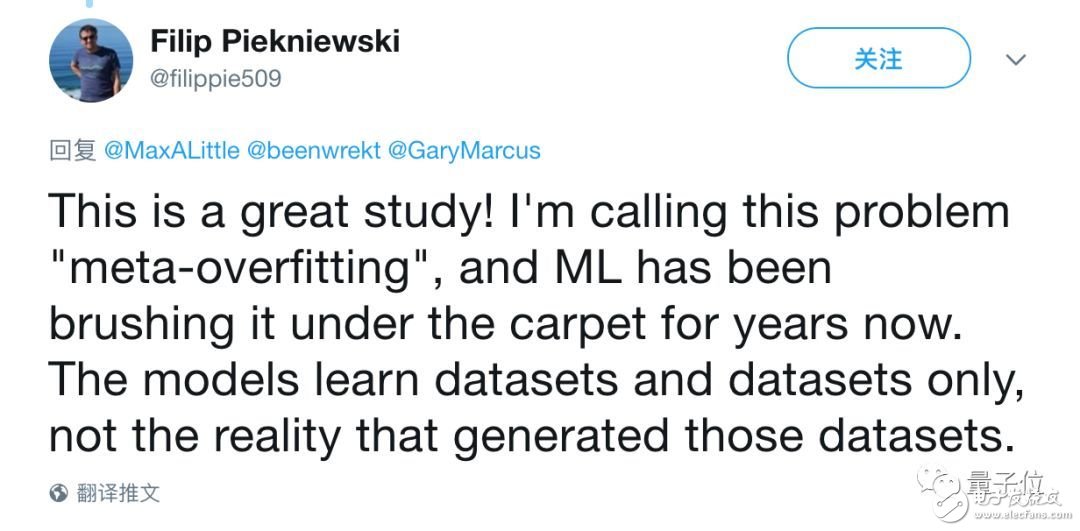
前不久曾撰文唱衰人工智能的的Filip Piekniewski,稱贊這篇論文是一個(gè)偉大的研究。他還把這個(gè)問(wèn)題,稱為“元過(guò)擬合”(meta-overfitting)。他還批評(píng)機(jī)器學(xué)習(xí)這幾年只關(guān)注幾個(gè)數(shù)據(jù)集,不關(guān)注現(xiàn)實(shí)情況。
俄勒岡州立大學(xué)教授Thomas G. Dietterich指出,不僅僅是CIFAR10,所有的測(cè)試數(shù)據(jù)集都被研究者們很快搞得過(guò)擬合了。測(cè)試基準(zhǔn)需要不斷有新的數(shù)據(jù)集注入。
“我在MNIST上也見(jiàn)過(guò)類似的情況。一個(gè)準(zhǔn)確率達(dá)到99%的分類器,換一個(gè)全新的手寫數(shù)據(jù)集,立刻掉到90%。”O(jiān)penAI的研究員Yaroslav Bulatov說(shuō)。

Keras作者Fran?ois Chollet顯得更為激動(dòng)。他說(shuō):“顯而易見(jiàn)的是,一大票目前的深度學(xué)習(xí)tricks都對(duì)知名的基準(zhǔn)測(cè)試集過(guò)擬合了,包括CIFAR10。至少?gòu)?015年以來(lái),ImageNet也存在這個(gè)問(wèn)題。”
如果你的論文,需要固定的驗(yàn)證集,以及特定的方法、架構(gòu)和超參數(shù)。那么這個(gè)就不是驗(yàn)證集,而是訓(xùn)練集。這種特定的方法,也不一定能泛化到真實(shí)數(shù)據(jù)上。
深度學(xué)習(xí)的研究,很多時(shí)候使用了并不科學(xué)的方法。驗(yàn)證集過(guò)擬合是一個(gè)值得注意的地方。其他問(wèn)題還包括:基準(zhǔn)太弱、實(shí)證結(jié)果不支持論文想法、大多數(shù)論文存在可重復(fù)性問(wèn)題、結(jié)果后選等。
比方你參加Kaggle競(jìng)賽時(shí),如果只根據(jù)驗(yàn)證集(public leaderboard)數(shù)據(jù)來(lái)調(diào)整你的模型,那么你在測(cè)試集(private leaderboard)只會(huì)一直表現(xiàn)不佳。這在更廣泛的研究領(lǐng)域也是如此。
最后給一個(gè)非常簡(jiǎn)單的建議,可以克服這些問(wèn)題:使用高熵驗(yàn)證過(guò)程,例如k-fold驗(yàn)證,或者更進(jìn)一步,使用帶shuffling的遞歸k-fold驗(yàn)證。只在最后用官方驗(yàn)證集上檢查結(jié)果。
“當(dāng)然,這樣做成本更高。但成本本身就是一個(gè)正則因子:它迫使你謹(jǐn)慎行動(dòng),而不是把一大坨面條扔到墻上,看最后哪根能粘住。”Fran?ois Chollet說(shuō)。
不止圖像分類
其實(shí),這個(gè)過(guò)擬合的問(wèn)題并不是只出現(xiàn)在圖像分類研究上,其他模型同樣無(wú)法幸免。
今年年初,微軟亞洲研究院和阿里巴巴的NLP團(tuán)隊(duì),在機(jī)器閱讀理解數(shù)據(jù)集SQuAD上的成績(jī)超越了人類。
當(dāng)時(shí),SQuAD閱讀理解水平測(cè)試的主辦方,斯坦福NLP小組就對(duì)自己的數(shù)據(jù)集產(chǎn)生了懷疑。他們轉(zhuǎn)發(fā)的一條Twitter說(shuō):
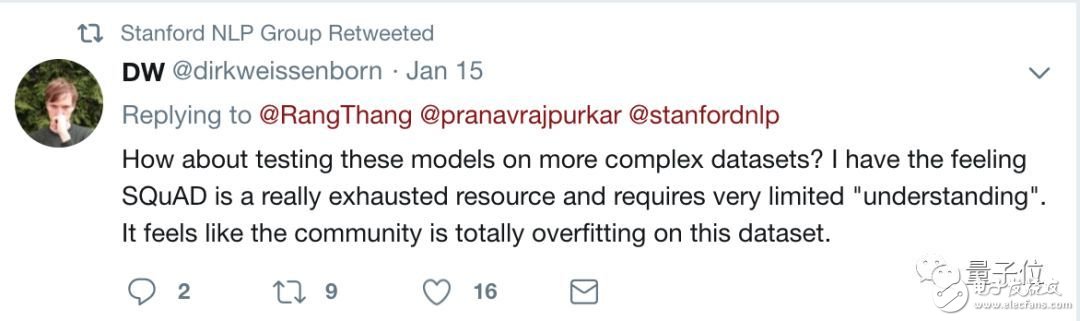
好像整個(gè)研究界都在這個(gè)數(shù)據(jù)集上過(guò)擬合了。
Google Brain研究員David Ha也說(shuō),很期待在文本和翻譯領(lǐng)域也有類似的研究,他說(shuō)如果在PTB上也看到類似的結(jié)果,那可真是一個(gè)好消息,也許更好的泛化方法會(huì)被發(fā)現(xiàn)。
論文
這篇論文的作者,包括來(lái)自UC Berkeley的Benjamin Recht、Rebecca Roelofs、Vaishaal Shankar,以及來(lái)自MIT的Ludwig Schmidt。

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論