 電子發燒友App
電子發燒友App


在大多數傳統的自動語音識別(automatic speech recognition,ASR)系統中,不同的語言(方言)是被獨立考慮的,一般會對每種語言從零開始訓練一個聲學模型(acoustic model,AM)。這引入了幾個問題。第一,從零開始為一種語言訓練一個聲學模型需要大量人工標注的數據,這些數據不僅代價高昂,而且需要很多時間來獲得。這還導致了資料豐富和資料匱乏的語言之間聲學模型質量間的可觀差異。這是因為對于資料匱乏的語言來說,只有低復雜度的小模型能夠被估計出來。大量標注的訓練數據對那些低流量和新發布的難以獲得大量有代表性的語料的語言來說也是不可避免的瓶頸。第二,為每種語言獨立訓練一個 AM 增加了累計訓練時間。這在基于 DNN 的 ASR 系統中尤為明顯,因為就像在第7章中所描述的那樣,由于 DNN 的參數量以及所使用的反向傳播(backpropagation,BP)算法,訓練DNN要顯著慢于訓練混合高斯模型(Gaussian mixture models,GMM)。第三,為每種語言構建分開的語言模型阻礙了平滑的識別,并且增加了識別混合語言語音的代價。為了有效且快速地為大量語言訓練精確的聲學模型,減少聲學模型的訓練代價,以及支持混合語言的語音識別(這是至關重要的新的應用場景,例如,在香港,英語詞匯經常會插入中文短語中),研究界對構建多語言 ASR 系統以及重用多語言資源的興趣正在不斷增加。
盡管資源限制(有標注的數據和計算能力兩方面)是研究多語言 ASR 問題的一個實踐上的原因,但這并不是唯一原因。通過對這些技術進行研究和工程化,我們同樣可以增強對所使用的算法的理解以及對不同語言間關系的理解。目前已經有很多研究多語言和跨語言 ASR 的工作(例如 [265, 431])。在本章中,我們只集中討論那些使用了神經網絡的工作。
我們將在下面幾節中討論多種不同結構的基于DNN的多語言ASR(multilingualASR)系統。這些系統都有同一個核心思想:一個DNN的隱藏層可以被視為特征提取器的層疊,而只有輸出層直接對應我們感興趣的類別,就像第9章所闡述的那樣。這些特征提取器可以跨多種語言享,采用來自多種語言的數據聯合訓練,并遷移到新的(并且通常是資源匱乏的)語言。通過把共享的隱藏層遷移到一個新的語言,我們可以降低數據量的需求,而不必從零訓練整個巨大的DNN,因為只有特定語言的輸出層的權重需要被重新訓練。
12.2.1 基于Tandem或瓶頸特征的跨語言語音識別
大多數使用神經網絡進行多語言和跨語言聲學建模(multilingual and crosslingual acoustic modeling)的早期研究工作都集中在 Tandem 和瓶頸特征方法上[318, 326, 356, 383, 384]。直到文獻 [73, 359] 問世以后,DNN-HMM 混合系統才成為大詞匯連續語音識別(large vocabulary continuous speech recognition,LVCSR)聲學模型的一個重要選項。如第10章中所述的,在 Tandem 或瓶頸特征方法中,神經網絡可以用來進行單音素狀態或三音素狀態的分類,而這些神經網絡的輸出或隱藏層激勵可以用作 GMM-HMM 聲學模型的鑒別性特征。
由于神經網絡的隱藏層和輸出層都包含有對某個語言中音素狀態進行分類的信息,并且不同的語言存在共享相似音素的現象,我們就有可能使用為一種語言(稱為源語言)訓練的神經網絡中提取的Tandem或瓶頸特征來識別另一種語言(稱為目標語言)。實驗顯示出當目標語言的有標注的數據很少時,這些遷移的特征能夠獲得一個更具有競爭力的目標語言的基線。用于提取Tandem或瓶頸特征的神經網路可以由多種語言訓練[384],在訓練中為每種語言使用一個不同的輸出層(對應于上下文無關的音素),類似于圖12.2所示。另外,多個神經網絡可分別由不同的特征訓練,例如,一個使用感知線性預測特征(PLP)[184],而其他的使用頻域線性預測特征(frequency domain linear prediction or FDLP[15])。 提取自這些神經網絡的特征可被合并來進一步提高識別正確率。
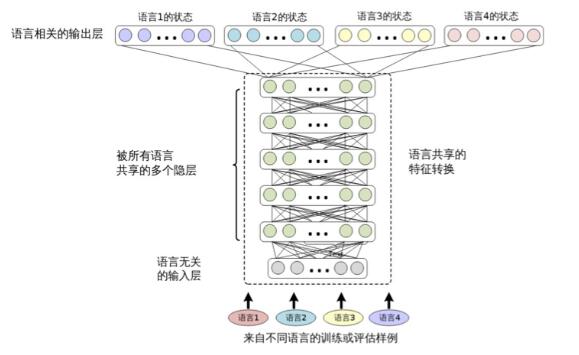
圖 12.2 共享隱層的多語言深度神經網絡的結構(Huang 等[204] 中有相似的圖)
基于 Tandem 或瓶頸特征的方法主要用于跨語言 ASR 來提升數據資源匱乏的語言的ASR 性能。它們很少用于多語言 ASR。這是因為,即使使用同一個神經網絡提取Tandem 或瓶頸特征,仍然常常需要為每種語言準備一個完全不同的 GMM-HMM 系 統。然而這個限制在多種語言共享相同的音素集(或者上下文相關的音素狀態)以及決策樹的情況下,就可能被移除,就像 [265] 中所做的那樣。共享的音素集可以由領域知識確定,比如使用國際音素字母表(international phonetic alphabet,IPA)[14],或者通過數據驅動的方法,比如計算不同語言單音素和三音素狀態間的距離[431]。
12.2.2 共享隱層的多語言深度神經網絡
多語言和跨語言的自動語音識別可以通過 CD-DNN-HMM 框架輕松實現。圖12.2描述了用于多語言 ASR 的結構。在文獻 [204] 中,這種結構被稱為共享隱層的多語言深度神經網絡(SHL-MDNN)。因為輸入層和隱層被所有的語言所共享,所以 SHL- MDNN 可以用這種結構進行識別。但是輸出層并不被共享,而是每種語言有自己的 softmax 層來估計聚類后狀態(綁定的三音素狀態)的后驗概率。相同的結構也在文獻 [153, 180] 中獨立地提出。
注意,這種結構中的共享隱層可以被認為是一種通用的特征變換或一種特殊的通用前端。就像在單語言的 CD-DNN-HMM 系統中一樣,SHL-MDNN 的輸入是一個較長的上下文相關的聲學特征窗。但是,因為共享隱層被很多語言共用,所以一些語言相關的特征變換(如HLDA)是無法使用的。幸運的是,這種限制并不影響 SHL-MDNN 的性能,因為如第9章中所述,任何線性變換都可以被 DNN 所包含。
圖 12.2中描述的 SHL-MDNN 是一種特殊的多任務學習方式[55],它等價于采用共享的特征表示來進行并行的多任務學習。有幾個原因使得多任務學習比 DNN 學習更有利。第一,通過找尋被所有任務支持的局部最優點,多任務學習在特征表達上更具有通用性。第二,它可以緩解過擬合的問題,因為采用多個語言的數據可以更可靠地估計共享隱層(特征變換),這一點對資源匱乏的任務尤其有幫助。第三,它有助于并行地學習特征。第四,它有助于提升模型的泛化能力,因為現在的模型訓練是包含了來自多個數據集的噪聲。
雖然 SHL-MDNN 有這些好處,但如果我們不能正確訓練 SHL-MDNN,也不能得到這些好處。成功訓練 SHL-MDNN 的關鍵是同時訓練所有語言的模型。當使用整批數據訓練,如 L-BFGS 或 Hessian free[280] 算法時,這是很容易做到的,因為在每次模型更新中所有的數據都能被用到。但是,如果使用基于小批量數據的隨機梯度下降
(SGD)訓練算法時,最好是在每個小批量塊中都包含所有語言的訓練數據。這可以通過在將數據提供給 DNN 訓練工具前進行隨機化,使其包含所有語言的訓練音頻樣本列表的方式高效地實現。
在文獻 [153] 中提出了另一種訓練方法。在這種方法中,所有的隱層首先用第5章提到的無監督的 DBN 預訓練方式訓練得到。然后一種語言被選中,隨機初始化這種語言對應的 softmax 層,并將其添加到網絡中。這個 softmax 層和整個 SHL-MDNN 使用這種語言的數據進行調整。調整之后,softmax層被下一種語言對應的隨機初始化的 softmax 代替,并且用那種語言的數據調整網絡。這個過程對所有的語言不斷重復。這種語言序列訓練方式的一個可能的問題是它會導致有偏差的估計,并且與同時訓練相比,性能會下降。
SHL-MDNN 可以用第5章介紹的生成或鑒別性的預訓練技術進行預訓練。SHL-MDNN的調整可以使用傳統的反向傳播(BP)算法。但是,因為每種語言使用了不同的softmax層,算法需要一些微調。但一個訓練樣本給到SHL-MDNN訓練器時,只有共享的隱層和指定語言的 softmax 層被更新。其他 softmax 層保持不變。
訓練之后,SHL-MDNN 可以用來識別任何訓練中用到的語言。因為在這種統一的結構下多種語言可以同時解碼,所以SHL-MDNN 令大詞匯連續語言識別任務變得輕松和高效。如圖12.3所示,在 SHL-MDNN 中增加一種新語言很容易。這只需要在已經存在的SHL-MDNN 中增加一個新的 softmax 層,并且用新語言訓練這個新加的softmax 層。
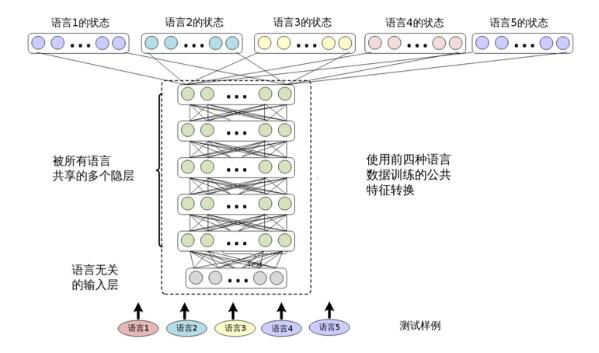
圖 12.3 用四種語言訓練的 SHL-MDNN 支持第五種語言
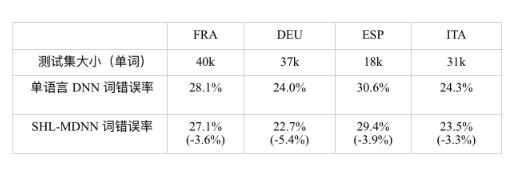
在 SHL-MDNN 中通過共享隱層和聯合訓練策略,相比只使用單一語言訓練得到的單語言 DNN,SHL-MDNN 可以提高所有可解碼語言的識別準確率。微軟內部對 SHL-MDNN 進行了實驗評估[204]。實驗中的 SHL-MDNN 有5個隱層,每層有2048個神經元。DNN的輸入是11(5-1-5)幀帶一階和二階差分的13維MFCC特征。使用138小時的法語(FRA)、195小時的德語(DEU)、63小時的西班牙語(ESP)和63小時的意大利語(ITA)數據進行訓練。對一種語言,輸出層包含1800個三音素的聚類狀態(即輸出類別),它們是由用相同訓練集和最大似然估(MLE)訓練得到的GMM-HMM系統確定的。SHL-MDNN使用無監督的DBN預訓練方法初始化,然后用由MLE模型對齊的聚類后的狀態進行BP算法調整模型。訓練得到的DNN之后被用到第6章介紹的CD-DNN-HMM框架中。
表 12.1比較了單語言 DNN 和共享隱層的多語言 DNN 的詞錯誤率(WER),單 語言 DNN 只使用指定語言的數據訓練,并用這種語言的測試集測試,SHL-MDNN 的隱層由所有的四種語言的數據訓練得到。從表 12.1中可以觀察到,在所有的語言 中,SHL-MDNN 比單語言 DNN 有 3% ~ 5% 相對 WER 減少。我們認為來自 SHL- MDNN 的提升是因為跨語言知識。即使是有超過 100 小時訓練數據的 FRA 和 DEU, SHL-MDNN 仍然有提升。
表 12.1 比較單語言 DNN 和共享隱層的多語言 DNN 的詞錯誤率(WER);括號中的是 WER 的相對減少。
12.2.3 跨語言模型遷移
從多語言 DNN 中提取的共享隱層可以被看作一種由多個源語言聯合訓練得到的 特征提取模塊。因此,它們富有識別多種語言的語音類別的信息,并且可以識別新語 言的音素。
跨語言模型遷移的過程很簡單。我們僅提取 SHL-MDNN 的共享隱層,并在其上 添加一個新的 softmax 層,如圖 12.4所示。softmax 層的輸出節點對應目標語言聚類后 的狀態。然后我們固定隱層,用目標語言的訓練數據來訓練 softmax 層。如果有足夠 的訓練數據可用,還可以通過進一步調整整個網絡得到額外的性能提升。
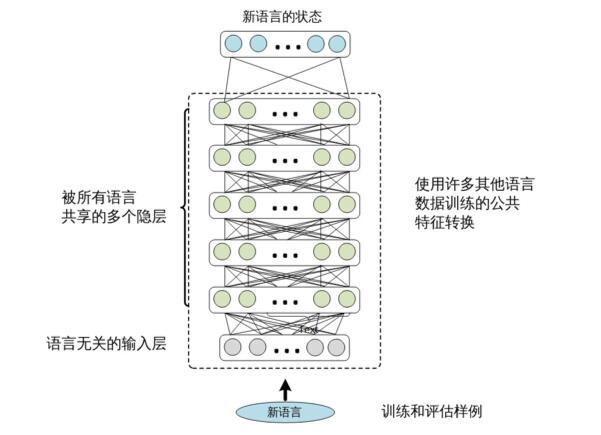
圖 12.4 跨語言遷移。隱層從多語言 DNN 中借來,而 softmax 層需要用目標語言的數 據訓練。
為了評估跨語言模型遷移的效果,文獻 [204] 中做了一系列實驗。這些實驗中,兩 種不同的語言被用作目標語言:與12.2.2節中訓練 SHL-MDNN 的歐洲語言相近的美式英語(ENU)和與歐洲語言相差較遠的中文普通話(CHN)。ENU 測試集包括 2286
句話(或 18000 個詞),CHN 測試集包括 10510 句話(或 40000 個字符)。
隱層的可遷移性
第一個問題是隱層是否可以被遷移到其他語言上。為了回答這個問題,我們假設 9 小時美式英文訓練數據(55737 句話)可以構建一個 ENU 的 ASR 系統。表 12.2總 結了實驗結果。基線 DNN 只用 9 小時 ENU 訓練集,這種方式達到了 ENU 測試集上 30.9% 的 WER。另一種方式是借用從其他語言中學到的隱層(特征變換)。在這個實 驗中,一個單語言的 DNN 由 138 小時的法語數據訓練得到。這個 DNN 的隱層隨后被 提取并在美式英語 DNN 中復用。如果隱層固定,只用 9 小時美式英語數據訓練 ENU 對應的 softmax 層,可以獲得相對基線 DNN 的 2.6% 的 WER 減少(30.9%→27.3%)。 如果整個法語 DNN 用 9 小時美式英語數據重新訓練,可以獲得 30.6% 的 WER,這比 30.9% 的基線 WER 還要略微好一點。這些結果說明法語 DNN 的隱層所表示的特征變 換可以被有效地遷移以識別美式英語語音。
表 12.2 比較使用和不使用遷移自法語 DNN 的隱層網絡在 ENU 測試集上的詞錯誤率
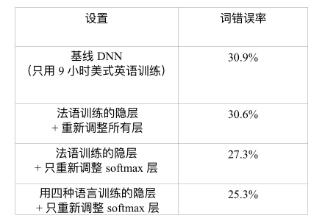
另外,如果在12.2.2節中描述的 SHL-MDNN 的共享隱層被提取并用在美式英語 DNN 中,可以得到額外 2.0% 的 WER 減少(27.3%→25.3%)。這說明在構造美式英語 DNN 時,提取自 SHL-MDNN 的隱層比提取自單獨的法語 DNN 的隱層更有效。總之, 相對基線 DNN,通過使用跨語言模型遷移可以獲得 4.6%(或相對的 18.1%)的 WER 減少。
目標語言訓練集的大小
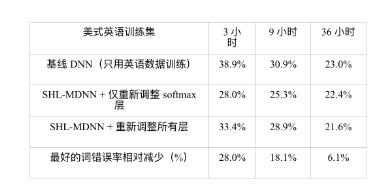
第二個問題是目標語言的訓練集大小如何影響多語言 DNN 跨語言模型遷移的性 能。為了回答這個問題,Huang 等人做了一些實驗,假設 3、9 和 36 小時的英語(目標語言)訓練數據可用。文獻 [204] 中的表 12.3總結了實驗結果。從表中可以觀察到, 利用遷移隱層的 DNN 始終好于不使用跨語言模型遷移的基線 DNN。我們也可以觀察 到,當不同大小的目標語言數據可用時,最優策略會有所不同。當目標語言的訓練數 據少于 10 小時,最好的策略是只訓練新的 softmax 層。當數據分別為 3 小時和 9 小時 的時候,這么做可以看到 28.0% 和 18.1% 的 WER 相對減少。但是,當訓練數據足夠 多時,進一步訓練整個 DNN 可以得到額外的錯誤減少。例如,當 36 小時的美式英語 語音數據可用時,我們觀察到通過訓練所有的層,可以獲得額外的 0.8% 的 WER 減少(22.4%→21.6%)。
表 12.3 比較當隱層遷移自 SHL-MDNN 時,目標語言訓練集大小對詞錯誤率(WER) 的影響效果。
從歐洲語言到中文普通話的遷移是有效的
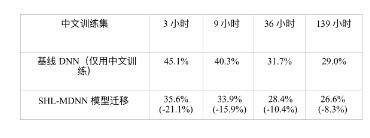
第三個問題是跨語言模型遷移方式的效果是否對源語言和目標語言之間的相似 性敏感。為了回答這個問題,Huang 等人[204] 使用了與訓練 SHL-MDNN 的歐洲語言極 其不同的中文普通話(CHN)作為目標語言。文獻 [204] 中的表 12.4列出了不同中文 訓練集大小的情況下,使用基線 DNN 和經過多語言增強的 DNN 的字錯誤率(CER)。 當數據少于 9 小時的時候,只有 softmax 層被訓練;當中文數據多于 10 小時的時候,所 有的層都被進一步調整。我們可以看到通過使用遷移隱層的方法,所有的 CER 都減少 了。即使有 139 小時的 CHN 訓練數據可用,我們仍然可以從 SHL-MDNN 中獲得 8.3% 的 CER 相對減少。另外,只用 36 小時的中文數據,我們可以通過遷移 SHL-MDNN 的共享隱層的方式在測試集上得到 28.4% 的 CER。這比使用 139 小時中文訓練數據的 基線 DNN 得到 29% 的 CER 還好,節省了超過 100 小時的中文標注。
表 12.4 CHN 的跨語言模型遷移效果,由字錯誤率(CER)減少衡量;括號中是 CER 相 對減少。
使用標注信息的必要性
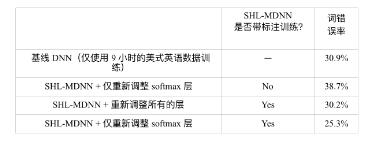
第四個問題是通過無監督學習提取的特征是否可以在分類任務上表現得和有監 督學習一樣好。如果回答是可以,這種方法會有顯著的優勢,因為獲取未標注的語音 數據比標注過的語音數據要容易很多。本節揭示出標注信息對于高效地學習多語言 數據的共享表示還是很重要的。基于文獻 [204] 中的結果,表 12.5比較了在訓練共享 隱層的時候,使用和不使用標注信息的兩種系統。從表 12.5中可以發現,只使用預訓 練過的多語言深度神經網絡,然后使用 ENU 數據適應學習整個網絡的方法,只得到 了很小的性能提升(30.9%→30.2%)。這個提升顯著小于使用標注信息時得到的提升
(30.9%→25.3%)。這些結果清晰地表明,標注數據比未標注數據更有價值,同時,在 從多語言數據中學習高效特征時標注信息的使用非常重要。
表 12.5 對比在 ENU 數據上使用和不使用標注信息時從多語言數據上學習到的特 征。

















 工商網監
工商網監
評論