 電子發燒友App
電子發燒友App


普華永道最近推出了一系列機器學習信息圖示,很好地將機器學習的發展歷史、關鍵方法以及未來會如何影響社會生活展現了出來。基礎概念部分包括機器學習各大學派錯綜關系的梳理;應用部分則描述了機器學習在社會中作用。作為專業的咨詢機構,普華永道繪制的信息圖非常專業,是值得珍藏的材料。新智元在此基礎上進行了解說。【進入新智元后臺,回復“170422”下載完整信息圖示】
AI 如何能成為商業的主流?這需要不同研究方法的結合,以及大量人類的智慧。
我們正處在 AI 取得突破性進展的時代:更為復雜的神經網絡伴著有效的語音識別訓練數據將亞馬遜的 Echo 和谷歌的 Home 帶進了千家萬戶。深度學習在圖像、語音和其他模式識別中取得的準確度提升使得微軟和谷歌的機器翻譯被更多人使用。圖像識別的增強使 Facebook 的照片搜索和谷歌照片中的 AI 相關功能得以實現。總體來說,這些進展使得機器識別的能力在很大程度上可以被消費者使用了。
在商業上,如何取得相似的進展?這需要高質量的訓練數據、數字化數據處理和數據科學家,同時需要大量的人類智慧,比如請語言領域的專家來調整、精修可計算的、邏輯貫通的商業語境,以使得計算機實現在商業領域的邏輯推理。商業領袖們也要花時間來教導機器將其智能融入具體領域內的處理進程。
一些以統計學為導向的機器學習研究流派,比如聯結學派、貝葉斯學派和類推學派,會擔心符號學派推動的 “human-in-the-loop” 方法無法擴展。但是,我們期待這一融合了幾種流派的、人類和機器間相互反饋的環,在接下來的幾年中,會在企業內部變得更為常見。
機器學習演化史:各學派發展融合,最終讓自動機器成為可能
長久以來,各種派別的人工智能研究者總是在相互競爭。相互合作的時機到來了嗎?他們不得不握手言和,因為只有合作將算法整合才能實現真正的通用人工智能(AGI)。下面,我們就來看看機器學習方法走過了什么樣的歷程,未來又將如何?

符號學派(Symbolists):是使用基于規則的符號系統做推理的人。大部分AI都圍繞著這種方法。使用Lisp和Prolog的方法屬于這一派,使用SemanticWeb,RDF和OWL的方法也屬于這一派。其中一個最雄心勃勃的嘗試是Doug Lenat在80年代開發的Cyc,試圖用邏輯規則將我們對這個世界的理解編碼。這種方法主要的缺陷在于其脆弱性,因為在邊緣情況下,一個僵化的知識庫似乎總是不適用。但在現實中存在這種模糊性和不確定性是不可避免的。愛用方法:規則和決策樹
貝葉斯學派(Bayesians):是使用概率規則及其依賴關系進行推理的一派。概率圖模型(PGM)是這一派通用的方法,主要的計算機制是用于抽樣分布的蒙特卡羅方法。這種方法與符號學方法的相似之處在于,可以以某種方式得到對結果的解釋。這種方法的另一個優點是存在可以在結果中表示的不確定性的量度。愛用方法:樸素貝葉斯或馬爾科夫
聯結學派(Connectionists):這一派的研究者相信智能起源于高度互聯的簡單機制。這種方法的第一個具體形式是出現于1959年的感知器。自那以后,這種方法消亡又復活了好幾次。其最新的形式是深度學習。愛用方法:神經網絡
進化學派(Evolutionists):是應用進化的過程,例如交叉和突變以達到一種初期的智能行為的一派。在深度學習中,GA確實有被用來替代梯度下降法,所以它不是一種孤立的方法。這個學派的人也研究細胞自動機(cellular automata ),例如Conway的“生命游戲”和復雜自適應系統(GAS)。愛用方法:遺傳算法
類推學派(The analogizers):更多地關注心理學和數學最優化,通過外推來進行相似性判斷。類推學派遵循“最近鄰”原理進行研究。各種電子商務網站上的產品推薦(例如亞馬遜或 Netflix的電影評級)是類推方法最常見的示例。愛用方法:支持向量機(SVM)

上世紀 80 年代流行符號學派,主導方法是知識工程(Knowledge engineering),由某個領域專家制造能夠在特定領域發揮一定決策輔助的機器,也即所謂的“專家機”。
上世紀 90 年代開始,貝葉斯學派發展了起來,概率論成為當時的主流思想,基于的原理是可以擴展的比較和對比,這種方法能夠適用的場景比較多。
到上世紀末至今,連接學派掀起熱潮,神經科學和概率論的方法得到了廣泛應用。神經網絡可以更精準地識別圖像、語音,做好機器翻譯乃至情感分析(sentiment analysis)等任務。同時,由于神經網絡需要大量的計算,基礎架構也從上世紀 80 年代的服務器便為大規模數據中心或者云。這部分內容相信大家都非常熟悉了。

如今,各學派開始相互借鑒融合,21 世紀的頭十年,最顯著的就是連接學派和符號學派的結合,由此產生了記憶神經網絡以及能夠根據知識進行簡單推理的智能體。基礎架構也向大規模云計算轉換。
第二個十年,連接學派、符號學派和貝葉斯學派也將融合到一起,實際上我們現在已經看到了這樣的趨勢,比如 DeepMind 的貝葉斯 RNN,而主要的局面將是感知任務由神經網絡完成,但涉及到推理和行動還是需要人為編寫規則。
從 2040 年以后,根據普華永道的預測,主流學派將成為 Algorithmic convergence,也即各種算法融合在一起,屆時機器自主學習,也即元學習(Meta-learning)實現,計算服務將無處不在。

機器學習:工作原理及適用場景
機器學習通過使人類能夠“教”機器如何學習,使人類和機器的聯系更為緊密。機器通過處理合適的訓練集來學習,這些訓練集包含優化一個算法所需的各種特征。這個算法使機器能夠執行特定的任務,例如對電子郵件進行分類。
但是,其好處遠遠不止過濾電子郵件,那些十年前就能做到了。如今,在機器學習的助力下,無人機可以實時近距離地拍攝例如橋梁之類的地方,然后快速、準確地評估重建項目的范圍。
下面,普華永道的信息圖示概述了機器學習的工作原理,機器學習與人工智能的關系,以及企業應該在哪些地方利用它們。

機器學習能夠通過“學習”大量的數據,在不需要人為編程的情況下,生成以及識別特定的對象,比如人臉。目前,機器學習也是商業應用中最常用的算法。
那么,機器學習跟人工智能之間具體是怎樣的關系呢?
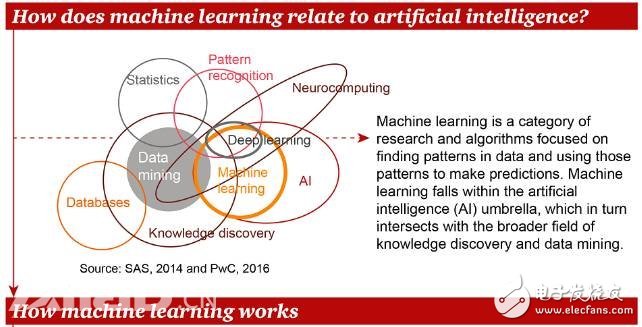
機器學習是一類關注從數據中找到模式,并根據這些模式進行預測的研究和算法。機器學習屬于人工智能,它與數據挖掘、統計學、模式識別等相關領域的關系如上圖所示。接下來看看機器學習如何工作。
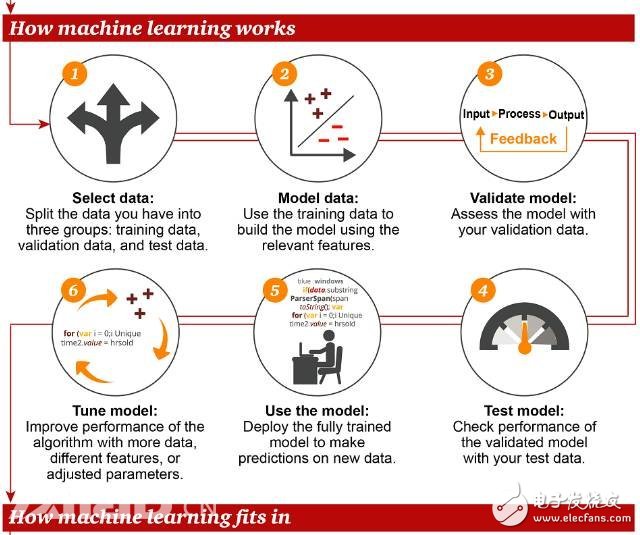
根據普華永道信息圖的總結,機器學習的主要流程/步驟:
選擇數據:這一過程又分為三部分,分別是訓練用數據、驗證用數據、測試用數據
數據建模:使用訓練數據構建涉及相關特征的模型
驗證模型:用驗證數據驗證建立的模型
調試模型:為了提升模型的性能,使用更多的數據、不同的特征,調整參數,這也是最耗時耗力的一步
使用模型:部署模型訓練好的模型,對新的數據進行預測
測試模型:使用測試用數據驗證模型,并評估模型的性能
接下來,我們看看機器學習在傳統編程、統計學這些常見方法中處于什么樣的地位。
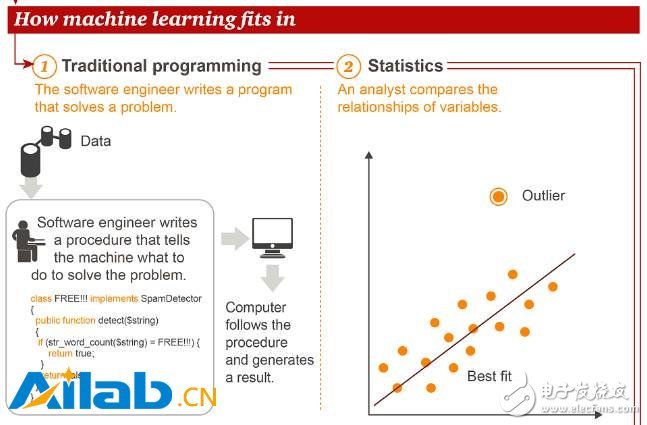

與傳統編程和統計學方法不同,在機器學習當中,數據科學家使用訓練數據“教育”計算機,然后讓計算機執行任務。由此,產生了智能應用(Intelligent App)。圖中所舉的例子是智能農業,通過無人機采集的數據進行精準的施肥、灌溉等操作。
在實際應用中機器學習有很多適用場景。下圖給出了3個例子:

1. 快速三維成圖和建模對一個鐵路橋梁重建項目,PwC 數據科學家和領域專家將機器學習應用于無人機收集到的數據。這樣的組合使得對正在進行的工作進行精確的監控和快速的反饋成為可能。
2. 加強分析以減輕風險為了檢測內幕交易,PwC 結合機器學習與其他分析技術,發掘更全面的用戶資料,更深入地了解復雜的可疑行為。
3. 預測最佳表現者PwC 使用機器學習和其他分析技術來評估墨爾本杯參賽的各匹馬的潛力。
實際應用機器學習:什么才是特定任務的正確算法?
人工智能和機器學習是企業界的熱門話題,公司的領導者對如何利用它們改善及自動化業務流程抱有很高的期望。實際上,根據普華永道《2017全球數字化IQ調查》,全球約有54% 的機構正在大力投資AI,這個數字在三年內將提升到63%。
那么,AI 如何解決商業上的問題,例如幫助你弄清楚為什么流失了客戶,或評估信貸申請人的風險?這取決于許多因素,尤其是算法使用的數據以及要訓練的類型。什么是特定任務的正確算法?報告調查了最常用的算法以及它們解決的商業問題。
下面列舉了最常用的算法及其使用案例。

機器學習中常用的算法有很多,具體需要用哪種,很大程度上取決于你手頭的數據及其特征,你的訓練目標,尤其是具體的使用場景。除非特殊情況,不必使用最復雜的算法。下面是常見的機器學習算法。
1. 決策樹(Decision Trees)

決策樹是一個決策支持工具,它使用樹形圖或決策模型以及序列可能性。包括各種偶然事件的后果、資源成本、功效。從商務決策的角度來看,大部分情況下,決策樹是一個人為了評估做出正確決定的概率需要問的是/否問題的最小數值。它能讓你以一個結構化和系統化的方式來處理這個問題,然后得出一個合乎邏輯的結論。
2. 支持向量機

支持向量機(SVM)是二元分類算法。給定一組兩種類型的N維的地方點,SVM產生一個(N - 1)維超平面到這些點分成2組。假設你有兩種類型的點,且它們是線性可分的。 SVM將找到一條直線將這些點分成2種類型,并且這條直線會盡可能地遠離所有的點。在規模上,目前使用SVM(在適當修改的情況下)解決的最大的問題包括顯示廣告、人類剪接位點識別、基于圖像的性別檢測和大規模的圖像分類等等。
3. 邏輯回歸

回歸是非常常用的方法。其中,邏輯回歸是一種強大的統計方法,它能建模出一個二項結果與一個(或多個)解釋變量。它通過估算使用邏輯運算的概率,測量分類依賴變量和一個(或多個)獨立的變量之間的關系,是累積的邏輯分布情況。
總的來說,邏輯回歸可以用于以下場景:
車流分析
信用評分
衡量營銷活動的成功率
預測某個產品的收入
某一天是否會發生地震?
4. 樸素貝葉斯分類

樸素貝葉斯分類是一種十分簡單的分類算法,方程 P(A|B)是后驗概率,P(B|A)是可能性,P(A)是類先驗概率,而P(B)是預測先驗概率。樸素貝葉斯的思想基礎是這樣的:對于給出的待分類項,求解在此項出現的條件下各個類別出現的概率,哪個最大,就認為此待分類項屬于哪個類別。它的現實使用例子有:
將一篇新的文章歸類到科技、政治或者運動
檢查一段文本表達的是積極情緒還是消極情緒
用于臉部識別軟件
客戶分類
5. 隱馬爾科夫模型

可觀察的馬爾科夫決策過程是確定性的——一個給定的狀態總是遵循另一個給定的狀態。例如交通信號燈的模式。
相反,隱馬爾科夫模型通過分析可觀察的數據來計算隱藏狀態的概率,然后通過分析隱藏狀態來估計未來可能觀察到的模式。一個例子是,通過分析高氣壓(或低氣壓)的概率來預測天氣是晴天,雨天或多云的可能性。
6. 隨機森林

隨機森林算法結合了多個樹,使用隨機挑選的數據子集,以此提升決策樹的分析準確率。上圖中的例子展示的是與乳腺癌復發相關的不同基因及其幾率。隨機深林算法的優勢在于能夠處理大規模數據集,以及大量看似不相關的數據,可以用于風險評估和客戶信息分析。
7. 遞歸神經網絡
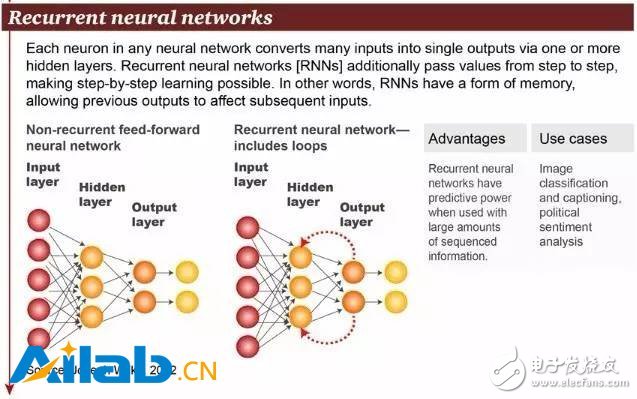
實際上,遞歸神經網絡(RNN)是兩種人工神經網絡的總稱。一種是時間遞歸神經網絡(Recurrent Neural Network),另一種是結構遞歸神經網絡(Recursive Neural Network)。時間遞歸神經網絡的神經元間連接構成有向圖,而結構遞歸神經網絡利用相似的神經網絡結構遞歸構造更為復雜的深度網絡。RNN一般指代時間遞歸神經網絡,正如上圖所示。
時間遞歸神經網絡可以描述動態時間行為,因為和前饋神經網絡(feedforward neural network)接受較特定結構的輸入不同,RNN 將狀態在自身網絡中循環傳遞,因此可以接受更廣泛的時間序列結構輸入。手寫識別是最早成功利用 RNN 的研究結果,其他應用還包括圖像分類、圖說生成和情感分析。
8. 長短期記憶(LSTM)
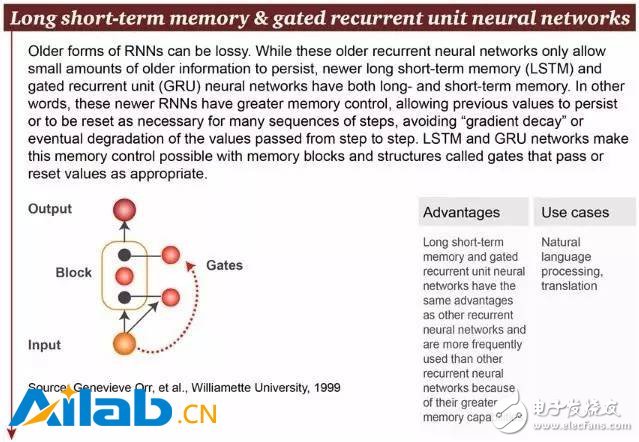
較舊的 RNN 可能是有損的(lossy),因為它們只能保存少量的舊信息。但新的長短期記憶(LSTM)和門控循環單元(gated recurrent unit, GRU)神經網絡同時具有長期記憶和短期記憶。換句話說,這些較新的 RNN 具有更好的記憶控制,允許先前的值持續保存,或必要時為許多序列步驟重置,避免在步驟到步驟的傳遞時造成“梯度衰減”(gradient decay)。LSTM 和 GRU 網絡通過記憶體組(memory blocks)和被稱為“門”(gates)的結構適當地 pass 或 reset 值來實現這種記憶控制。
9. 卷積神經網絡

卷積神經網絡(Convolutional Neural Network, CNN)是一種前饋神經網絡,它的人工神經元可以響應一部分覆蓋范圍內的周圍單元,對于大型圖像處理、藥物發現等有出色表現。
卷積神經網絡由一個或多個卷積層和頂端的全連通層(對應經典的神經網絡)組成,同時也包括關聯權重和池化層。這一結構使得卷積神經網絡能夠利用輸入數據的二維結構。與其他深度學習結構相比,卷積神經網絡在圖像和語音識別方面能夠給出更優的結果。這一模型也可以使用反向傳播算法進行訓練。相比較其他深度、前饋神經網絡,卷積神經網絡需要估計的參數更少。









 工商網監
工商網監
評論