 電子發(fā)燒友App
電子發(fā)燒友App


深度學(xué)習(xí)需要大量的計(jì)算。它通常包含具有許多節(jié)點(diǎn)的神經(jīng)網(wǎng)絡(luò),并且每個(gè)節(jié)點(diǎn)都有許多需要在學(xué)習(xí)過(guò)程中必須不斷更新的連接。換句話說(shuō),神經(jīng)網(wǎng)絡(luò)的每一層都有成百上千個(gè)相同的人工神經(jīng)元在執(zhí)行相同的計(jì)算。因此,神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)適用于GPU(圖形處理單元)可以高效執(zhí)行的計(jì)算類(lèi)型(GPU是專(zhuān)門(mén)為并行計(jì)算相同指令而設(shè)計(jì)的)。
隨著深度學(xué)習(xí)和人工智能在過(guò)去幾年的迅速發(fā)展,我們也看到了許多深度學(xué)習(xí)框架的引入。深度學(xué)習(xí)框架的創(chuàng)建目標(biāo)是在GPU上高效運(yùn)行深度學(xué)習(xí)系統(tǒng)。這些深度學(xué)習(xí)框架都依賴(lài)于計(jì)算圖的概念,計(jì)算圖定義了需要執(zhí)行的計(jì)算順序。在這些框架中你使用的是一種可以建立計(jì)算圖的語(yǔ)言,并且語(yǔ)言的執(zhí)行機(jī)制與其宿主語(yǔ)言本身的機(jī)制有所不同。然后,計(jì)算圖可以并行地在目標(biāo)GPU中優(yōu)化和運(yùn)行。
在這篇文章中,我想向大家介紹推動(dòng)深度學(xué)習(xí)發(fā)展的5個(gè)主力框架。這些框架使數(shù)據(jù)科學(xué)家和工程師更容易為復(fù)雜問(wèn)題構(gòu)建深度學(xué)習(xí)解決方案,并執(zhí)行更復(fù)雜的任務(wù)。這只是眾多開(kāi)源框架中的一小部分,由不同的科技巨頭支持,并相互推動(dòng)更快創(chuàng)新。

1. TensorFlow (Google)
TensorFlow最初是由Google Brain Team的研究人員和工程師開(kāi)發(fā)的。其目的是面向深度神經(jīng)網(wǎng)絡(luò)和機(jī)器智能研究。自2015年底以來(lái),TensorFlow的庫(kù)已正式在GitHub上開(kāi)源。TensorFlow對(duì)于快速執(zhí)行基于圖形的計(jì)算非常有用。靈活的TensorFlow API可以通過(guò)其GPU支持的架構(gòu)在多個(gè)設(shè)備之間部署模型。
簡(jiǎn)而言之,TensorFlow生態(tài)系統(tǒng)有三個(gè)主要組成部分:
用C ++編寫(xiě)的TensorFlow API包含用于定義模型和使用數(shù)據(jù)訓(xùn)練模型的API。 它也有一個(gè)用戶(hù)友好的Python接口。
TensorBoard是一個(gè)可視化工具包,可幫助分析,可視化和調(diào)試TensorFlow計(jì)算圖。
TensorFlow Serving是一種靈活的高性能服務(wù)系統(tǒng),用于在生產(chǎn)環(huán)境中部署預(yù)先訓(xùn)練好的機(jī)器學(xué)習(xí)模型。Serving也是由C ++編寫(xiě)并可通過(guò)Python接口訪問(wèn),可以即時(shí)從舊模式切換到新模式。
TensorFlow已被廣泛應(yīng)用于學(xué)術(shù)研究和工業(yè)應(yīng)用。一些值得注意的當(dāng)前用途包括Deep Speech,RankBrain,SmartReply和On-Device Computer Vision。大家可以在TensorFlow的GitHub項(xiàng)目中查看一些最佳官方用途,研究模型、示例和教程。
我們來(lái)看一個(gè)運(yùn)行的示例。 在這里,我在TensorFlow上用隨機(jī)數(shù)據(jù)訓(xùn)練一個(gè)基于L2損失的2層ReLU網(wǎng)絡(luò)。

這個(gè)代碼有兩個(gè)主要組件:定義計(jì)算圖并多次運(yùn)行這個(gè)圖。在定義計(jì)算圖時(shí),我為輸入x,權(quán)重w1和w2以及目標(biāo)y創(chuàng)建placeholders進(jìn)行占位。然后在前向傳播中,我計(jì)算目標(biāo)y的預(yù)測(cè)以及損失值(損失值為y的真實(shí)值與預(yù)測(cè)值之間的L2距離)。最后,我讓Tensorflow計(jì)算關(guān)于w1和w2的梯度損失。
完成計(jì)算圖構(gòu)建之后,我創(chuàng)建一個(gè)會(huì)話框來(lái)運(yùn)行計(jì)算圖。在這里我創(chuàng)建了numpy數(shù)組,它將填充建圖時(shí)創(chuàng)建的placeholders(占位符),將它們數(shù)值提供給x,y,w1,w2。為了訓(xùn)練網(wǎng)絡(luò),我反復(fù)運(yùn)行計(jì)算圖,使用梯度來(lái)更新權(quán)重然后獲得loss,grad_w1和grad_w2的numpy數(shù)組。
Keras: 高級(jí)包裝
深度學(xué)習(xí)框架在兩個(gè)抽象級(jí)別上運(yùn)行:低級(jí)別--數(shù)學(xué)運(yùn)算和神經(jīng)網(wǎng)絡(luò)基本實(shí)體的實(shí)現(xiàn)(TensorFlow, Theano, PyTorch etc.)和高級(jí)別--使用低級(jí)基本實(shí)體來(lái)實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)抽象,如模型和圖層(Keras) 。
Keras是其后端庫(kù)的包裝,該后端庫(kù)可以是TensorFlow或Theano - 這意味著如果你們?cè)谑褂靡訲ensorFlow為后端庫(kù)的Keras,你實(shí)際上是在運(yùn)行TensorFlow代碼。Keras為您考慮到了許多基本細(xì)節(jié),因?yàn)樗槍?duì)神經(jīng)網(wǎng)絡(luò)技術(shù)用戶(hù),而且非常適合那些練習(xí)數(shù)據(jù)科學(xué)的人。它支持簡(jiǎn)單快速的原型設(shè)計(jì),支持多種神經(jīng)網(wǎng)絡(luò)架構(gòu),并可在CPU / GPU上無(wú)縫運(yùn)行。
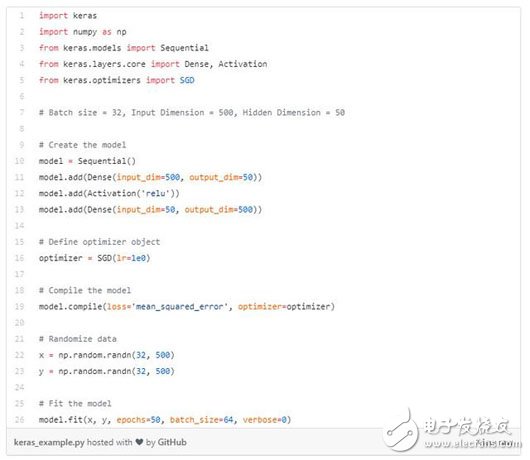
在這個(gè)例子中,對(duì)一個(gè)與之前例子中相似的神經(jīng)網(wǎng)絡(luò)進(jìn)行訓(xùn)練,我首先將模型對(duì)象定義為一系列圖層,然后定義優(yōu)化器對(duì)象。接下來(lái),我建立模型,指定損失函數(shù),并用單個(gè)“fit”曲線來(lái)訓(xùn)練模型。
2. Theano (蒙特利爾大學(xué))
Theano是另一個(gè)用于快速數(shù)值計(jì)算的Python庫(kù),可以在CPU或GPU上運(yùn)行。它是蒙特利爾大學(xué)蒙特利爾學(xué)習(xí)算法小組開(kāi)發(fā)的一個(gè)開(kāi)源項(xiàng)目。它的一些最突出的特性包括GPU的透明使用,與NumPy緊密結(jié)合,高效的符號(hào)區(qū)分,速度/穩(wěn)定性?xún)?yōu)化以及大量的單元測(cè)試。
遺憾的是,Youshua Bengio(MILA實(shí)驗(yàn)室負(fù)責(zé)人)在2017年11月宣布他們將不再積極維護(hù)或開(kāi)發(fā)Theano。原因在于Theano多年來(lái)推出的大部分創(chuàng)新技術(shù)現(xiàn)在已被其他框架所采用和完善。如果有興趣,大家仍然可以為它的開(kāi)源庫(kù)做貢獻(xiàn)。
Theano在許多方面與TensorFlow相似。那么讓我們來(lái)看看另一個(gè)代碼示例,使用相同批量和輸入/輸出尺寸來(lái)訓(xùn)練神經(jīng)網(wǎng)絡(luò):
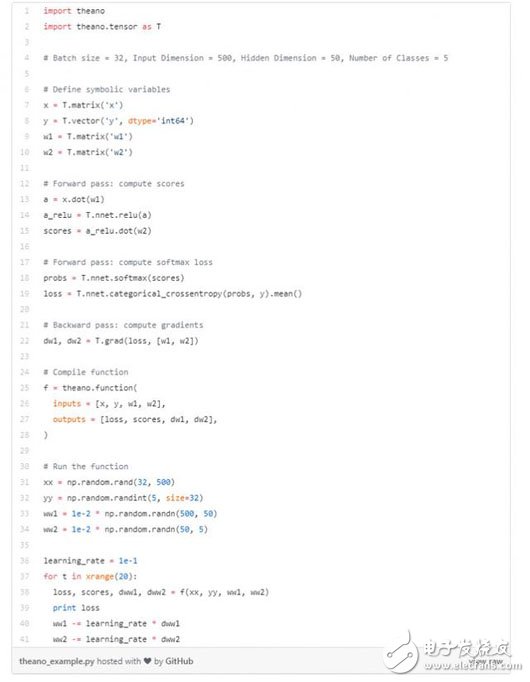
我首先定義了Theano符號(hào)變量(類(lèi)似于TensorFlow占位符)。對(duì)于正向傳播,我計(jì)算預(yù)測(cè)和損失; 對(duì)于反向傳播,我計(jì)算梯度。然后我編譯一個(gè)函數(shù),根據(jù)數(shù)據(jù)和權(quán)重計(jì)算損失,得分和梯度。最后,我多次運(yùn)行這個(gè)函數(shù)來(lái)訓(xùn)練網(wǎng)絡(luò)。
3. PyTorch (Facebook)
Pytorch在學(xué)術(shù)研究者中很受歡迎,也是相對(duì)比較新的深度學(xué)習(xí)框架。Facebook人工智能研究組開(kāi)發(fā)了pyTorch來(lái)應(yīng)對(duì)一些在它前任數(shù)據(jù)庫(kù)Torch使用中遇到的問(wèn)題。由于編程語(yǔ)言Lua的普及程度不高,Torch永遠(yuǎn)無(wú)法經(jīng)歷Google TensorFlow那樣的迅猛發(fā)展。因此,PyTorch采用了被已經(jīng)為許多研究人員,開(kāi)發(fā)人員和數(shù)據(jù)科學(xué)家所熟悉的原始Python命令式編程風(fēng)格。同時(shí)它還支持動(dòng)態(tài)計(jì)算圖,這一特性使得它對(duì)做時(shí)間序列以及自然語(yǔ)言處理數(shù)據(jù)相關(guān)工作的研究人員和工程師很有吸引力。
到目前為止,Uber將PyTorch使用得最好,它已經(jīng)構(gòu)建了Pyro,一種使用PyTorch作為其后端的通用概率編程語(yǔ)言。 PyTorch的動(dòng)態(tài)差異化執(zhí)行能力和構(gòu)建梯度的能力對(duì)于概率模型中的隨機(jī)操作非常有價(jià)值。
PyTorch有3個(gè)抽象層次:
張量:命令性的ndarray,但在GPU上運(yùn)行
變量:計(jì)算圖中的節(jié)點(diǎn);存儲(chǔ)數(shù)據(jù)和梯度
模塊:神經(jīng)網(wǎng)絡(luò)層;可以存儲(chǔ)狀態(tài)或可學(xué)習(xí)的權(quán)重
在這里我將著重談一談張量抽象層次。 PyTorch張量就像numpy數(shù)組,但是它們可以在GPU上運(yùn)行。沒(méi)有內(nèi)置的計(jì)算圖或梯度或深度學(xué)習(xí)的概念。在這里,我們使用PyTorch Tensors(張量)擬合一個(gè)2層網(wǎng)絡(luò):

正如你所看到的,我首先為數(shù)據(jù)和權(quán)重創(chuàng)建隨機(jī)張量。然后我計(jì)算正向傳播過(guò)程中的預(yù)測(cè)和損失,并在反向傳播過(guò)程中手動(dòng)計(jì)算梯度。我也為每個(gè)權(quán)重設(shè)置梯度下降步長(zhǎng)。最后,我通過(guò)多次運(yùn)行該功能來(lái)訓(xùn)練網(wǎng)絡(luò)。
4. Torch (NYU / Facebook)
接下來(lái)我們來(lái)談?wù)凾orch。它是Facebook的開(kāi)源機(jī)器學(xué)習(xí)庫(kù)、科學(xué)計(jì)算框架和基于Lua編程語(yǔ)言的腳本語(yǔ)言。它提供了廣泛的深度學(xué)習(xí)算法,并已被Facebook,IBM,Yandex和其他公司用于解決數(shù)據(jù)流的硬件問(wèn)題。
作為PyTorch的直系祖先,Torch與PyTorchg共享了很多C后端。與具有3個(gè)抽象級(jí)別的PyTorch不同,Torch只有2個(gè):張量和模塊。讓我們?cè)囈辉囈粋€(gè)使用Torch張量來(lái)訓(xùn)練兩層神經(jīng)網(wǎng)絡(luò)的代碼教程:
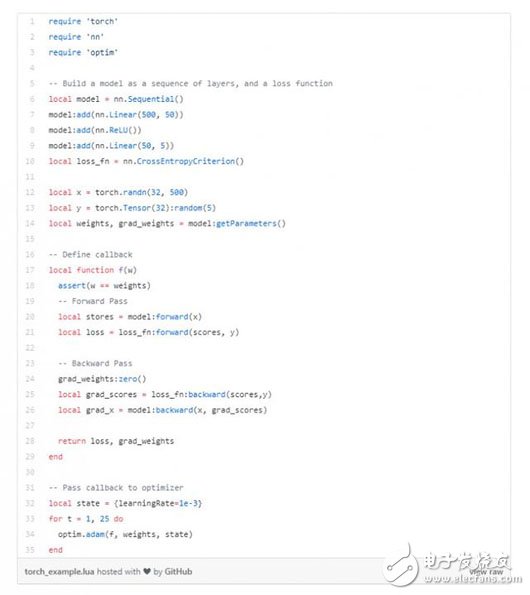
最初,我建立了一個(gè)多層的神經(jīng)網(wǎng)絡(luò)模型,以及一個(gè)損失函數(shù)。接下來(lái),我定義一個(gè)回溯函數(shù),輸入權(quán)重并在權(quán)重上產(chǎn)生損失/梯度。在函數(shù)內(nèi)部,我計(jì)算前向傳播中的預(yù)測(cè)和損失,以及反向傳播中的梯度。最后,我反復(fù)將該回溯函數(shù)傳遞給優(yōu)化器進(jìn)行優(yōu)化。
5. Caffe (UC Berkeley)
Caffe是一個(gè)兼具表達(dá)性、速度和思維模塊化的深度學(xué)習(xí)框架。由伯克利人工智能研究小組和伯克利視覺(jué)和學(xué)習(xí)中心開(kāi)發(fā)。雖然其內(nèi)核是用C ++編寫(xiě)的,但Caffe有Python和Matlab相關(guān)接口。這對(duì)訓(xùn)練或微調(diào)前饋分類(lèi)模型非常有用。雖然它在研究中使用得并不多,但它仍然很受部署模型的歡迎,正如社區(qū)貢獻(xiàn)者所證明的那樣。
為了使用Caffe訓(xùn)練和微調(diào)神經(jīng)網(wǎng)絡(luò),您需要經(jīng)過(guò)4個(gè)步驟:
轉(zhuǎn)換數(shù)據(jù):我們讀取數(shù)據(jù)文件,然后清洗并以Caffe可以使用的格式存儲(chǔ)它們。我們將編寫(xiě)一個(gè)進(jìn)行數(shù)據(jù)預(yù)處理和存儲(chǔ)的Python腳本。
定義模型:模型定義了神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)。我們選擇CNN體系結(jié)構(gòu)并在擴(kuò)展名為.prototxt的配置文件中定義其參數(shù)。
定義求解器:求解器負(fù)責(zé)模型優(yōu)化,定義所有關(guān)于如何進(jìn)行梯度下降的信息。我們?cè)跀U(kuò)展名為.prototxt的配置文件中定義求解器參數(shù)。
訓(xùn)練模型:一旦我們準(zhǔn)備好模型和求解器,我們就通過(guò)從終端調(diào)用caffe binary(咖啡因)來(lái)訓(xùn)練模型。訓(xùn)練好模型后,我們將在一個(gè)擴(kuò)展名為.caffemodel的文件中獲得訓(xùn)練好的模型。
我不會(huì)為Caffe做代碼展示,但是您可以在Caffe的主頁(yè)上查看一個(gè)教程。總的來(lái)說(shuō),Caffe對(duì)于前饋網(wǎng)絡(luò)和微調(diào)現(xiàn)有網(wǎng)絡(luò)非常有用。您可以輕松地訓(xùn)練模型而無(wú)需編寫(xiě)任何代碼。它的Python接口非常有用,因?yàn)槟梢栽诓皇褂肞ython代碼的情況下部署模型。不利的一面是,您需要為每個(gè)新的GPU圖層編寫(xiě)C++內(nèi)核代碼(在Caffe下)。因此,大網(wǎng)絡(luò)(AlexNet,VGG,GoogLeNet,ResNet等)的構(gòu)建將會(huì)非常麻煩。
您應(yīng)該使用哪種深度學(xué)習(xí)框架?
由于Theano不再繼續(xù)被開(kāi)發(fā),Torch是以不為許多人熟悉的Lua語(yǔ)言編寫(xiě)的,Caffe還處于它的早熟階段,TensorFlow和PyTorch成為大多數(shù)深度學(xué)習(xí)實(shí)踐者的首選框架。雖然這兩個(gè)框架都使用Python,但它們之間存在一些差異:
PyTorch有更加干凈清爽的接口,更易于使用,特別適合初學(xué)者。大部分代碼編寫(xiě)較為直觀,而不是與庫(kù)進(jìn)行戰(zhàn)斗。相反,TensorFlow擁有更繁雜的小型、含混的庫(kù)。
然而,TensorFlow擁有更多的支持和一個(gè)非常龐大,充滿活力和樂(lè)于助人的社區(qū)。這意味著TensorFlow的在線課程,代碼教程,文檔和博客帖子多于PyTorch。
也就是說(shuō),PyTorch作為一個(gè)新平臺(tái),有許多有趣的功能尚未被完善。但是令人驚奇的是PyTorch在短短一年多的時(shí)間里取得了巨大的成就。
TensorFlow更具可擴(kuò)展性,并且與分布式執(zhí)行非常兼容。它支持從僅GPU到涉及基于實(shí)時(shí)試驗(yàn)和錯(cuò)誤的繁重分布式強(qiáng)化學(xué)習(xí)的龐大系統(tǒng)的所有的系統(tǒng)。
最重要的是,TensorFlow是“定義 - 運(yùn)行”,在圖形結(jié)構(gòu)中定義條件和迭代,然后運(yùn)行它。另一方面,PyTorch是“按運(yùn)行定義”,其中圖結(jié)構(gòu)是在正向計(jì)算過(guò)程中實(shí)時(shí)定義的。換句話說(shuō),TensorFlow使用靜態(tài)計(jì)算圖,而PyTorch使用動(dòng)態(tài)計(jì)算圖。基于動(dòng)態(tài)圖的方法為復(fù)雜體系結(jié)構(gòu)(如動(dòng)態(tài)神經(jīng)網(wǎng)絡(luò))提供了更易于操作的調(diào)試功能和更強(qiáng)的處理能力。基于靜態(tài)圖的方法可以更方便地部署到移動(dòng)設(shè)備,更容易部署到更具不同的體系結(jié)構(gòu),以及具有提前編譯的能力。
因此,PyTorch更適合于愛(ài)好者和小型項(xiàng)目的快速原型開(kāi)發(fā),而TensorFlow更適合大規(guī)模部署,尤其是在考慮跨平臺(tái)和嵌入式部署時(shí)。 TensorFlow經(jīng)受了時(shí)間的考驗(yàn),并且仍然被廣泛使用。它對(duì)大型項(xiàng)目具有更多功能和更好的可擴(kuò)展性。 PyTorch越來(lái)越容易學(xué)習(xí),但它并沒(méi)有與TensorFlow相同的一體化整合功能。這對(duì)于需要快速完成的小型項(xiàng)目非常有用,但對(duì)于產(chǎn)品部署并不是最佳選擇。
寫(xiě)在最后
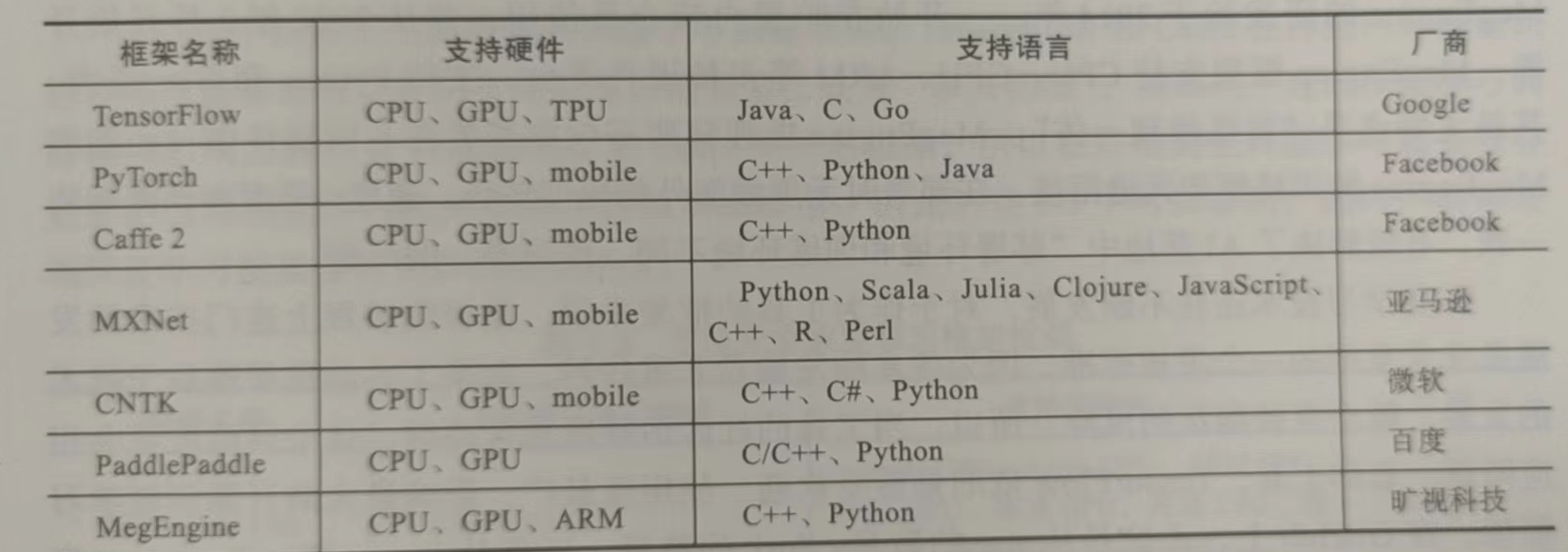
上述列舉只是眾多框架中較為突出的框架,并且大多數(shù)支持Python語(yǔ)言。去幾年里發(fā)布了多個(gè)新的深度學(xué)習(xí)框架,如DeepLearning4j(Java),Apache的MXNet(R,Python,Julia),Microsoft CNTK(C ++,Python)和Intel的Neon(Python)。每個(gè)框架都是不同的,因?yàn)樗鼈兪怯刹煌娜藶榱瞬煌哪康亩_(kāi)發(fā)的。有一個(gè)整體的大致了解會(huì)幫助你解決你的下一個(gè)深度學(xué)習(xí)難題。在選擇適合您的最佳選擇時(shí),易于使用(就架構(gòu)和處理速度而言),GPU支持,教程和培訓(xùn)材料的獲得難度,神經(jīng)網(wǎng)絡(luò)建模功能以及支持的語(yǔ)言都是重要的考慮因素。
















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論