 電子發燒友App
電子發燒友App


2015-2016的機器學習平臺開源大潮中,美國是當之無愧的引領者:無論是谷歌、亞馬遜、微軟、IBM等互聯網巨頭,還是美國各大科研院所,為開源世界貢獻了品類繁多的機器學習工具。這其中不乏華人的身影,比如開發出Caffe的賈楊清。
但在大陸這邊,無論是BAT還是學界,在開源機器學習項目上始終慢了一拍,令人十分遺憾。這與我國世界最大AI研究者社區、占據AI科研領域半壁江山的江湖地位*頗為不符。讓人欣喜的是,2016下半年,百度和騰訊先后發布了它們的開源平臺戰略。雖然姍姍來遲,但作為下半場入場的選手,它們的開源平臺各自有什么意義?本文中,作為機器學習開源項目盤點的第三彈,我們將與你一起看看包括百度騰訊平臺在內的國內四大開源項目。
注:據創新工場人工智能工程院王詠剛副院長統計,我國AI發文數與引用文章數居世界第一,占世界總數一半以上。
1. 百度:希望獲得開發者青睞的 “PaddlePaddle”
2016年9月1日的百度世界大會上,百度首席科學家吳恩達宣布,該公司開發的異構分布式深度學習系統PaddlePaddle將對外開放。這標志著國內第一個機器學習開源平臺的誕生。
其實,PaddlePaddle 的開發與應用已經有段時日:它源自于2013年百度深度學習實驗室創建的 “Paddle”。當時的深度學習框架大多只支持單GPU 運算,對于百度這樣需要對大規模數據進行處理的機構,這顯然遠遠不夠,極大拖慢了研究速度。百度急需一種能夠支持多GPU、多臺機器并行計算的深度學習平臺。而這就導致了 Paddle 的誕生。自2013年以來,Paddle 一直被百度內部的研發工程師們所使用。
而 Paddle 的核心創始人,當年的百度深度學習實驗室研究員徐偉,現在已是 PaddlePaddle 項目的負責人。
徐偉
對了,從 “Paddle” 到 “PaddlePaddle” 的命名還有一個小插曲:Paddle 是“Parallel Distributed Deep Learning”的縮寫,意為“并行分布式深度學習”。而去年9月發布時,吳恩達認為 “PaddlePaddle” (英語意為劃船——“讓我們蕩起雙~昂~槳,小船兒推開波浪。。。”)其實更郎朗上口、更好記,于是就有了這么個可愛的名字。
那么,PaddlePaddle 有什么特點?
支持多種深度學習模型 DNN(深度神經網絡)、CNN(卷積神經網絡)、 RNN(遞歸神經網絡),以及 NTM 這樣的復雜記憶模型。
基于 Spark,與它的整合程度很高。
支持分布式計算。作為它的設計初衷,這使得 PaddlePaddle 能在多 GPU,多臺機器上進行并行計算。
相比現有深度學習框架,PaddlePaddle 對開發者來說有什么優勢?
首先,是易用性。
相比偏底層的谷歌 TensorFlow,PaddlePaddle 的特點非常明顯:它能讓開發者聚焦于構建深度學習模型的高層部分。項目負責人徐偉介紹:
“在PaddlePaddle的幫助下,深度學習模型的設計如同編寫偽代碼一樣容易,設計師只需關注模型的高層結構,而無需擔心任何瑣碎的底層問題。未來,程序員可以快速應用深度學習模型來解決醫療、金融等實際問題,讓人工智能發揮出最大作用。”
拋開底層編碼,使得 TensorFlow 里需要數行代碼來實現的功能,可能在 PaddlePaddle 里只需要一兩行。徐偉表示,用 PaddlePaddle 編寫的機器翻譯程序只需要“其他”深度學習工具四分之一的代碼。這顯然考慮到該領域廣大的初入門新手,為他們降低開發機器學習模型的門檻。這帶來的直接好處是,開發者使用 PaddlePaddle 更容易上手。
其次,是更快的速度。
如上所說,PaddlePaddle 上的代碼更簡潔,用它來開發模型顯然能為開發者省去一些時間。這使得 PaddlePaddle 很適合于工業應用,尤其是需要快速開發的場景。
另外,自誕生之日起,它就專注于充分利用 GPU 集群的性能,為分布式環境的并行計算進行加速。這使得在 PebblePebble 上,用大規模數據進行 AI 訓練和推理可能要比 TensorFlow 這樣的平臺要快很多。
說到這里,業內對 PaddlePaddle 怎么看?
首先不得不提的是 Caffe,許多資深開發者認為 PaddlePaddle 的設計理念與 Caffe 十分相似,懷疑是百度對標 Caffe 開發出的替代品。這有點類似于谷歌 TensorFlow 與 Thano 之間的替代關系。
知乎上,Caffe 的創始人賈楊清對 PaddlePaddle 評價道:
“很高質量的GPU代碼”
“非常好的RNN設計”
“設計很干凈,沒有太多的 abstraction,這一點比 TensorFlow 好很多”
“設計思路有點老”
“整體的設計感覺和 Caffe ‘心有靈犀’,同時解決了Caffe早期設計當中的一些問題”
最后,賈表示 PaddlePaddle 的整體架構功底很深,是下了功夫的。這方面,倒是贏得了開發者的普遍認同。
總結起來,業內對 PaddlePaddle 的總體評價是“設計干凈、簡潔,穩定,速度較快,顯存占用較小”。
但是,具有這些優點,不保證 PaddlePaddle 就一定能在群雄割據的機器學習開源世界占有一席之地。有國外開發者表示, PaddlePaddle 的最大優點是快。但是,比 TensorFlow 快的開源框架其實有很多:比如 MXNet,Nervana System 的 Neon,以及三星的 Veles,它們也都對分布式計算都很好的支持,但都不如 TensorFlow 普及程度高。這其中有 TensorFlow 龐大用戶基礎的原因,也得益于谷歌自家 AI 系統的加持。
百度的 AI 產品能夠對普及 PaddlePaddle 產生多大的幫助,尚需觀察。我們獲知,它已經應用于百度旗下的多項業務。百度表示:
“PaddlePaddle 已在百度30多項主要產品和服務之中發揮著巨大的作用,如外賣的預估出餐時間、預判網盤故障時間點、精準推薦用戶所需信息、海量圖像識別分類、字符識別(OCR)、病毒和垃圾信息檢測、機器翻譯和自動駕駛等領域。”
最后,我們來看看對于自家推出的 PaddlePaddle,李彥宏怎么說:
“經過了五六年的積累,PaddlePaddle實際上是百度深度學習算法的引擎,把源代碼開放出來,讓同學們、讓社會上所有的年輕人能夠學習,在它的基礎上進行改進,我相信他們會發揮出來他們的創造力,去做到很多我們連想都沒有想過的東西。”
2. 騰訊:面向企業的 “Angel”
2016,鵝廠在 AI 領域展開一系列大動作:
9 月,成立 AI 實驗室。
11 月,獲得 Sort Benchmark 大賽的冠軍
12月18日,在騰訊大數據技術峰會暨 KDD China 技術峰會上對外公開 “Angel” 的存在,并透漏它就是拿下 Sort Benchmark 冠軍背后的天使。
在2017 年一季度,開放 Angel 源代碼。
Angel 將成為 PaddlePaddle 之后、BAT 發布的第二個重磅開源平臺。那么,它到底是什么?
簡單來說,Angel 是面向機器學習的分布式計算框架,由鵝廠與香港科技大學、北京大學聯合研發。騰訊表示,它為企業級大規模機器學習任務提供解決方案,可與 Caffe、TensorFlow 和 Torch 等業界主流深度學習框架很好地兼容。但就我們所知,它本身并不算是機器學習框架,而側重于數據運算。
上個月18日的發布會上,騰訊首席數據專家蔣杰表示:
“面對騰訊快速增長的數據挖掘需求,我們希望開發一個面向機器學習的、能應對超大規模數據集的、高性能的計算框架,并且它要對用戶足夠友好,具有很低的使用門檻,就這樣,Angel 平臺應運而生。”
這其中的關鍵詞,一個是“大”規模數據,另一個是“低”使用門檻。
“大”方面,企鵝表示 Angel 支持十億級別維度的模型訓練:
“Angel 采用多種業界最新技術和騰訊自主研發技術,包括 SSP(Stale synchronous Parallel)、異步分布式SGD、多線程參數共享模式HogWild、網絡帶寬流量調度算法、計算和網絡請求流水化、參數更新索引和訓練數據預處理方案等。這些技術使 Angel 性能大幅提高,達到 Spark 的數倍到數十倍,能在千萬到十億級的特征維度條件下運行。”
“低”方面,Angel 并沒有采用機器學習領域標配的 Python,而使用企業界程序猿最熟悉的 Java,以及 Scala 。企鵝聲明:“在系統易用性上,Angel 提供豐富的機器學習算法庫及高度抽象的編程接口、數據計算和模型劃分的自動方案及參數自適應配置。同時,用戶能像使用 MR、Spark 一樣在 Angel 上編程,我們還建設了拖拽式的一體化的開發運營門戶,屏蔽底層系統細節,降低用戶使用門檻。”
總的來講,Angel 的定位是對標 Spark 。蔣杰宣稱,它融合了 Spark 和 Petuum 的優點。“以前Spark能跑的,現在Angel快幾十倍;以前Spark跑不了的,Angel也能輕松跑出來。”
其實,Angel 已經是鵝廠的第三代大數據計算平臺。
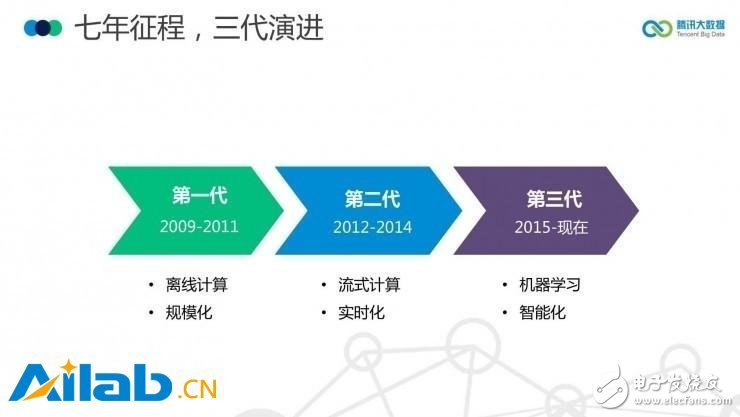
第一代是基于 Hadoop 的深度定制版本“TDW”,它的重點是“規模化”(擴展集群規模)。
第二代集成了Spark 和 Storm,重點是提高速度,“實時化”。
第三代自研平臺 Angel,能處理超大規模數據,重點是“智能化”,專門對機器學習進行了優化。
這三代平臺的演進,從使用第三方開源平臺過渡到自主研發,涵蓋了從數據分析到數據挖掘、從數據并行到模型并行的發展。現在 Angel 已支持 GPU 運算,以及文本、語音、圖像等非結構化數據。自今年初在鵝廠內部上線以來,Angel 已應用于騰訊視頻、騰訊社交廣告及用戶畫像挖掘等精準推薦業務。另外,國內互聯網行業開口閉口就要打造“平臺”、“生態”的風氣,鵝廠也完美繼承:“Angel 不僅僅是一個只做并行計算的平臺,更是一個生態”——這種話雖然不耐聽,但騰訊的大數據野心可見一斑。
12 月18 日晚,馬化騰在微信朋友圈寫道:“AI與大數據將成為未來各領域的標配,期待更多業界同行一起開源攜手互助。”
但對于機器學習社區,Angel 開源的意義是否如同鵝廠宣稱的那樣大?
對此,機器學習界的“網紅”、微軟研究員彭河森說道:
“對于小一點的公司和組織,Spark 甚至MySQL 都已經夠了(為了政治正確我提一下 PostgresQL);而對于大一點真的用得上Angel的企業,如阿里巴巴等,早就自主開發了自己的大數據處理平臺。”
因此,他總結 Angel 的發布是一個“很尷尬的時間和市場定位”。
彭河森
與百度 PaddlePaddle 相比,Angel 有一個很大的不同:它的服務對象是有大數據處理需求的企業,而不是個人開發者。可惜的是,由于 Angel 尚未正式開源,大數據、機器學習同行們無法對其進行一番評頭論足。目前所有的信息都來自于鵝廠的官方宣傳。關于 Angel 開放源代碼后能在業界引發多大反響,請關注后續報道。
最后,我們來看看蔣杰對 Angel 開源意義的官方總結:
“機器學習作為人工智能的一個重要類別,正處于發展初期,開源Angel,就是開放騰訊18年來的海量大數據處理經驗和先進技術。我們連接一切連接的資源,激發更多創意,讓這個好平臺逐步轉化成有價值的生態系統,讓企業運營更有效、產品更智能、用戶體驗更好。”
3. 阿里巴巴: 猶抱琵牌半遮面的 DTPAI
但凡說到平臺,就不能不提阿里。
與百度比起來,阿里的 AI 戰略布局看上去更“務實”:主要是依托阿里云計算、貼近淘寶生態圈的一系列 AI 工具與服務,比如阿里小蜜。而基礎研究起步較晚,相對百度和鵝廠也更低調。 2016 年阿里 AI 戰略的大事件是 8 月 9 日的云棲大會,馬云親自站臺發布了人工智能 ET,而它的前身是阿里“小Ai ”。綜合目前信息,阿里想要把 ET 打造成一個多用途 AI 平臺:應用于語音、圖像識別,城市計算(交通),企業云計算,“新制造”,醫療健康等等領域,讓人不禁聯想起 IBM Watson。用阿里的話來說,ET 將成為“全局智能”。
但是,在開源項目方面,阿里有什么布局(馬云最喜歡用這樣的詞)?
答案有驚喜也有失望。
好消息是,阿里早在 2015 年就宣布了數據挖據平臺 DTPAI (全稱:Data technology,the Platform of AI,即數據技術—人工智能平臺)。
壞消息是,那之后就沒動靜了。
當時,也就是 2015 年的八月,阿里宣布將為阿里云客戶提供付費數據挖掘服務 DTPAI。當然,對它的發布免不了大談特談一通“生態”、“平臺”——宣稱 DTPAI 是“中國第一個人工智能平臺”。格調定得相當高。
它有什么特點?
首先, DTPAI 將集成阿里巴巴核心算法庫,包括特征工程、大規模機器學習、深度學習等等。其次,與百度、騰訊一樣,阿里也很重視旗下產品的易用性。阿里 ODPS 和 iDST 產品經理韋嘯表示,DTPAI 支持鼠標拖拽的編程可視化,也支持模型可視化;并且廣泛與MapReduce、Spark、DMLC、R 等開源技術對接。
若僅僅如此,一個阿里云的付費數據挖據工具還不會出現在這篇文章中。我們真正感興趣的是:阿里表示 DTPAI “未來會提供通用的深度學習框架,它的算法庫將在后期向社會開放”。
嗯,有關 DTPAI 的信息到此為止。Seriously,2015 年之后它就再也沒消息了。阿里云是耍猴還是在憋大招? 我們只有走著瞧。
4. 山世光:大陸學界碩果僅存的 SeetaFace
盤點了 BAT 的開源平臺規劃,再來看一個始于學界的項目。與國外 AI 學界百花齊放的現狀不同,大多數人從未聽說過始于國內學界的機器學習開源項目,這方面幾乎是空白一片——說是“幾乎”,因為有中科院計算所山世光老師帶領開發的人臉識別引擎 SeetaFace 。
山老師是我國 AI 界的學術大牛之一,2016 年下半年已經下海創業,創業后不久就公開了 SeetaFace。山老師的研究團隊表示,開源 SeetaFace 是因為“該領域迄今尚無一套包括所有技術模塊的、完全開源的基準人臉識別系統”。而 SeetaFace 將供學界和工業界免費使用,有望填補這一空白。
SeetaFace 基于 C++,不依賴于任何第三方的庫函數。作為一套全自動人臉識別系統,它集成了三個核心模塊,即:人臉檢測模塊(SeetaFace Detection)、面部特征點定位模塊(SeetaFace Alignment)以及人臉特征提取與比對模塊 (SeetaFace Identification)。
該系統用單個英特爾 i7 CPU 就可運行,成功降低了人臉識別的硬件門檻。它的開源,有望幫助大量有人臉識別任務需求的公司與實驗室,在它們的產品服務中接入 SeetaFace,大幅減少開發成本。










 工商網監
工商網監
評論