 電子發燒友App
電子發燒友App


最近的Google I/O大會很是熱鬧。
在大會的最后一日,Alphabet董事長John Hennessy親口承認:Google Duplex已經在預約領域通過了圖靈測試。
通過圖靈測試!
多么令人興奮的六個字。被人工智能所改變的世界藍圖仿佛就在我們眼前鋪展。
人工智能成果噴薄爆發以來,熱門領域除了機器學習,還有作為計算機語言學、人工智能和數理邏輯的交叉學科——機器翻譯。
機器翻譯起源于何時?如今發展到了什么程度?
國內在機器翻譯上有哪些研究成果,又有哪些公司推出了令人驚嘆的落地應用?
在其發展道路上,有哪些大牛發表了哪些成果,推動了地球人無障礙溝通的夢想計劃?
未來,機器翻譯將可能在哪些領域進行深耕?其發展趨勢如何?
這些問題的答案,你都可以在未來一周內找到。
首先,我們需要了解一下機器翻譯是如何興起的。
蹣跚起步
Warren Weaver說:我覺得機器翻譯可行
于是全世界都開始搞機器翻譯
1946年,第一臺數字電子計算機誕生。從那以后,人們就開始思索如何運用計算機代替人從事翻譯工作的問題,甚至在此之前,圖靈就已經開始思考計算機是否能夠進行思維這一問題。
三年之后——1949年,我國正式建立,機器翻譯思想也正式提出:Warren Weaver發表《翻譯》備忘錄,這也被視為機器翻譯初始階段的第一件標志性事件。
▲Warren Weaver
Warren Weaver在備忘錄里展現了機器翻譯的可計算性,并提出了兩個主要觀點。
第一個觀點:他認為翻譯類似于解讀密碼的過程,“翻譯即解碼”。
第二個觀點:他認為原文與譯文“說的是同樣的事情”。
因此,當把語言A翻譯為語言B時,就意味著從語言A出發,會經過某一“通用語言”或“中間語言”(可以假定這個語言是全人類共同的),最終到達語言B。
1954年,美國喬治敦大學(Georgetown)在IBM的協同下,進行了英俄翻譯實驗,開始了在翻譯自動化方面的嘗試。這是機器翻譯發展初始階段的第二件標志性事件。
總體來說,這一階段人們頭腦中已經形成了機器翻譯的概念,并且已經可以意識到利用語法規則的轉換和字典來實現翻譯目的。
人們樂觀地認為,只要通過擴大詞匯量和語法規則,在不久的將來,機器翻譯問題會比較完美地得以解決。
所以在此之后的很長一段時間,全球各國大力支持機器翻譯項目,一個機器翻譯研究的高潮就此形成。
發展冷卻
ALPAC說:我覺得機器翻譯不行
于是大家又不搞機器翻譯了
蓬勃發展17年之后,機器學習迎來了第一個發展低谷。
1966年11月,美國語言自動處理咨詢委員會(ALPAC)公布著名的ALPAC報告,從速度、質量、花費、需求等各個角度,幾乎是全方位地給給機器翻譯研究工作澆了一盆涼水。
APLAC對當時的各個翻譯系統進行了一次評估,并在報告提出,機器翻譯的譯文質量明顯要遠低于人工翻譯。
難以克服的“語義障礙”是當時機器翻譯遇到的問題,在報告中,ALPAC全面否定了機器翻譯的可行性,并建議各大機構停止對機器翻譯的投資和研究。
盡管這份報告的結論過于倉促、武斷,但是這一階段關于機器翻譯的研究的確沒有解決許多至關重要的問題,并沒有對語言進行深入的分析。
此后在世界范圍內,機器翻譯出現了空前的蕭條局面。
重啟篇章
大公司說:我們覺得還是得重新搞一下
于是機器翻譯得以復蘇
20世紀80年代末,由于微處理器的出現,計算機能力獲得了突飛猛進的發展。
機器翻譯這一學科有著極大的開發潛力和經濟利益,開始被人們重新提起。
許多大公司開始投入資金和人力進行研究,使得機器翻譯得到了復蘇和重新發展的機會。
這一時期,計算語言學的一些基礎工作,比如許多重要的算法等的研究已經到達了一個比較深入的階段,對語法和語義的研究也已經有了一些比較重大的成果。
詞法分析、句法分析的算法相繼得到開發,并且加強了軟件資源,例如電子詞典的建設。
翻譯方法以轉換方法為代表,開始普遍采用以分析為主,輔以語義分析的基于規則方法來進行翻譯,采用抽象轉換表示的分層實現策略。

▲抽象轉換的分層實現
語法與算法的分開是這一時期機器翻譯的另一個特點。
所謂語法與算法分開,就是指把語言分析和程序設計分開來成為兩部分操作,程序設計工作者提出規則描述的方法,而語言學工作者使用這種方法來描述語言的規則。
炙手可熱
世界:我們需要更精準更快速的翻譯
現在,機器翻譯已經成為世界自然語言處理研究的熱門。
原因之一是網絡化和國際化對翻譯的需求日益增大,翻譯軟件商業化的趨勢也非常明顯。
這一時期的翻譯方法,我們一般稱之為基于經驗主義的翻譯方法。
即主要基于實例和基于統計的方法,注重大規模語料庫的建設,開始針對大規模的真實文本進行處理。
同時,這一階段的研究工作開始解決一個比文本翻譯更加復雜和艱難的問題——語音翻譯。
由于Internet上的機器翻譯系統具有巨大的潛在市場和商業利益,網上翻譯機器系統也進入了實用領域的新突破階段。
機器翻譯功能越來越強大,從最初只能進行簡單的單詞翻譯,到之后可以翻譯出基本符合語法的句子,慢慢可以翻譯具有一定邏輯性的句子。
現在,部分軟件已經可以自主聯系上下文進行翻譯,翻譯結果的準確性與可讀性都已經取得了非常大的進步。
近年來,加入了深度學習技術等人工智能的機器翻譯已經不止于簡單的將一個個單詞翻譯成另一種語言,而是可以像人工翻譯一樣,不斷向前回顧理解結構復雜的句子,并且聯系上下文進行翻譯。
最為明顯的就是現在的部分機器翻譯軟件已經可以理解每一個代詞具體指代誰,這在許多年前是不可想象的。
實現這種功能的關鍵,分別依賴于兩種神經網絡架構:一個是循環神經網絡(RNN),另一個是卷積神經網絡(CNN)。
目前關于兩種網路架構哪種更適用于機器翻譯的爭論還有很多,循環神經網絡與卷積神經網絡我們還會在之后為大家單獨介紹,至此機器翻譯的脈絡已為大家簡略梳理完畢。
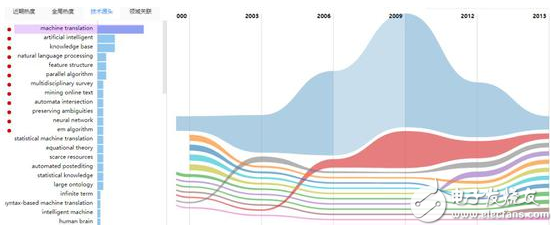
▲機器翻譯技術源頭
實際上,機器翻譯想要做好一個落地應用是很難的。因為許多人對其效果都持有著絕高的、難以完美達到的預期。
有語言學者指出,機器翻譯目前沒有思想,很難替代人類。
然而現在已經2018年了,Google Duplex都通過圖靈測試了,未來還有什么不可能發生?
我們期待著未來的“某天”。









 工商網監
工商網監
評論