 電子發(fā)燒友App
電子發(fā)燒友App


7月27日,英特爾在北京召開(kāi)了主題為“智能端到端,英特爾變革物聯(lián)網(wǎng)”的視覺(jué)解決方案及策略發(fā)布會(huì)。在此次發(fā)布會(huì)上,英特爾面向中國(guó)市場(chǎng)推出了基于英特爾硬件平臺(tái)的專(zhuān)注于加速深度學(xué)習(xí)的OpenVINO工具包,可幫助企業(yè)在邊緣側(cè)快速實(shí)現(xiàn)高性能計(jì)算機(jī)視覺(jué)與深度學(xué)習(xí)的開(kāi)發(fā)。
物聯(lián)網(wǎng)加速人工智能在邊緣計(jì)算中的應(yīng)用
此前人工智能的很多運(yùn)算處理都是發(fā)生在服務(wù)器、數(shù)據(jù)中心這樣的云端,因?yàn)橹挥性谶@樣的一個(gè)環(huán)境里面才能提供強(qiáng)大計(jì)算力和便利的支撐。但是,隨著物聯(lián)網(wǎng)時(shí)代的到來(lái),將會(huì)有越來(lái)越多的設(shè)備和傳感器接入網(wǎng)絡(luò),情況正在發(fā)生改變。
根據(jù)IDC預(yù)測(cè),到2020年全球會(huì)有超過(guò)500億的智能設(shè)備,超過(guò)2120億個(gè)傳感器。這也意味著每天都將會(huì)產(chǎn)生海量的數(shù)據(jù)。
根據(jù)研究機(jī)構(gòu)預(yù)測(cè),隨著物聯(lián)網(wǎng)的快速發(fā)展,到2020年每個(gè)互聯(lián)網(wǎng)用戶(hù)每天將生成約1.5GB的數(shù)據(jù),一個(gè)智能醫(yī)院每天將產(chǎn)生超過(guò)3000GB的數(shù)據(jù);每臺(tái)自動(dòng)駕駛汽車(chē)每天將生成超過(guò)4000 GB的數(shù)據(jù);聯(lián)網(wǎng)飛機(jī)每天將產(chǎn)生超過(guò)40000GB數(shù)據(jù);一個(gè)智慧工廠(chǎng)聯(lián)網(wǎng),假如說(shuō)有一千多臺(tái)設(shè)備,每臺(tái)設(shè)備上有很多個(gè)傳感器,時(shí)時(shí)刻刻都會(huì)產(chǎn)生數(shù)據(jù),那么整個(gè)智慧工廠(chǎng)每天產(chǎn)生的數(shù)據(jù)量將是1PB。到2020年全世界每天產(chǎn)生的數(shù)據(jù)總量將是44ZB。(注:1ZB就是1000EB,1EB是1000PB、1個(gè)PB是1000TB,1TB是1000個(gè)GB。)
面對(duì)如此海量的數(shù)據(jù),如果仍然只是依靠云端來(lái)做數(shù)據(jù)處理的化,這將對(duì)云端的計(jì)算力和網(wǎng)絡(luò)帶寬都帶來(lái)了極大的挑戰(zhàn)。雖然計(jì)算力和通信技術(shù)也在不斷發(fā)展,但是這個(gè)速度還是難以趕上數(shù)據(jù)增長(zhǎng)的速度。所以,邊緣計(jì)算,即數(shù)據(jù)在終端側(cè)進(jìn)行人工智能分析和處理早已是大勢(shì)所趨勢(shì)。
IDC預(yù)測(cè),到2018年將有45%的物聯(lián)網(wǎng)數(shù)據(jù)需要在邊緣進(jìn)行存儲(chǔ)處理和分析(足見(jiàn)物聯(lián)網(wǎng)對(duì)于在終端側(cè)部署人工智能需求的增長(zhǎng)之快),有50%的物聯(lián)網(wǎng)的網(wǎng)絡(luò)會(huì)面臨帶寬的問(wèn)題。正是由于物聯(lián)網(wǎng)所帶來(lái)的海量數(shù)據(jù)的增長(zhǎng)以及對(duì)于帶寬的極大挑戰(zhàn),在終端側(cè)部署人工智能已經(jīng)變得非常必要。
而且,在終端側(cè)部署人工智能,還有著數(shù)據(jù)處理的實(shí)時(shí)性更高、低延時(shí),更低的帶寬需求的優(yōu)勢(shì)。比如在自動(dòng)駕駛領(lǐng)域,對(duì)應(yīng)這方面的要求就非常的高。
另外,在終端側(cè)部署人工智能也有利于數(shù)據(jù)隱私的保護(hù)。因?yàn)楹芏嘤脩?hù)是不希望把數(shù)據(jù)上傳到云端的,希望這些數(shù)據(jù)在本地進(jìn)行處理,本地處理完以后,上傳的是一些是經(jīng)過(guò)處理完以后的特殊的數(shù)據(jù),對(duì)隱私保護(hù)相對(duì)比較高的場(chǎng)景,也需要一些數(shù)據(jù)放在邊緣進(jìn)行處理。
可以說(shuō),隨著物聯(lián)網(wǎng)的發(fā)展,正在加速人工智能在邊緣計(jì)算中的應(yīng)用,但是這并不意味著云端人工智能就不需要了、就會(huì)走向消亡。云端人工智能它能夠把數(shù)據(jù)源進(jìn)行匯總,它能夠做一些更綜合的應(yīng)用。如果要給用戶(hù)提供一個(gè)完整的人工智能服務(wù)和解決方案,一定是一種邊緣與云端協(xié)同的端到端的人工智能解決方案。
目前,包括英特爾在內(nèi)的一些廠(chǎng)商都能夠提供端到端的架構(gòu)了,所以現(xiàn)在“分布式計(jì)算”的概念已經(jīng)是一個(gè)比較成熟的概念。也就是說(shuō),做云端解決方案的人需要把它的架構(gòu)切到邊緣來(lái),幫助解決邊緣的問(wèn)題。
在英特爾看來(lái),“視頻(攝像頭)是物聯(lián)網(wǎng)的終極傳感器”。確實(shí),在邊緣側(cè),視頻所帶來(lái)的信息流是最為龐大的。值得注意的是,2016年-2012年網(wǎng)絡(luò)視頻監(jiān)控流量增長(zhǎng)了700%。也就是說(shuō),在物聯(lián)網(wǎng)時(shí)代,視頻將是人工智能應(yīng)用爆發(fā)的一個(gè)關(guān)鍵點(diǎn)。因此,視頻監(jiān)控領(lǐng)域也成為了英特爾端到端人工智能方案的切入重點(diǎn)。
英特爾的全棧式AI硬件解決方案
對(duì)于英特爾來(lái)說(shuō),在云端的服務(wù)器及數(shù)據(jù)中心市場(chǎng),英特爾是絕對(duì)的老大,市場(chǎng)占有率超過(guò)9成。針對(duì)這塊市場(chǎng),英特爾擁有Xeon處理器與Xeon Phi處理器,以及能支持各種對(duì)特定運(yùn)行負(fù)載進(jìn)行最佳化的加速器,包括現(xiàn)場(chǎng)可編程化邏輯閘陣列(FPGA),以及Nervana。
相對(duì)來(lái)說(shuō),CPU并不適合用來(lái)做人工智能運(yùn)算,不過(guò)英特爾依然能夠通過(guò)集成的GPU,再結(jié)合FPGA來(lái)實(shí)現(xiàn)云端的人工智能運(yùn)算加速。更何況,英特爾2016年還以4億美元的高價(jià)收購(gòu)了機(jī)器學(xué)習(xí)初創(chuàng)公司Nervana,將推出一款專(zhuān)為深度學(xué)習(xí)而打造的神經(jīng)網(wǎng)絡(luò)處理器。
在終端側(cè),英特爾除了可以利用其現(xiàn)有的針對(duì)終端的CPU、集顯、FPGA產(chǎn)品之外,2016年9月,英特爾收購(gòu)了計(jì)算機(jī)視覺(jué)芯片公司Movidius,開(kāi)始加碼終端側(cè)的人工智能布局。Movidius的Myriad 系列 VPU目前有被大疆Spark無(wú)人機(jī)、谷歌Clips相機(jī)等知名廠(chǎng)商的產(chǎn)品采用。去年,英特爾還推出了針對(duì)終端設(shè)備進(jìn)行人工智能加速的Movidius神經(jīng)計(jì)算棒。
▲英特爾副總裁兼物聯(lián)網(wǎng)事業(yè)部中國(guó)區(qū)總經(jīng)理陳偉博士
“我們英特爾有自己的CPU,有自己集顯GPU,在加上我們的Movidius、Nervana這些加速技術(shù),還有FPGA,至少?gòu)挠布慕嵌葋?lái)講,我們是可以根據(jù)應(yīng)用去勾勒出一個(gè)功耗、成本最優(yōu)化的端到端的全棧式解決方案,這是我們的一個(gè)起點(diǎn)。”英特爾副總裁兼物聯(lián)網(wǎng)事業(yè)部中國(guó)區(qū)總經(jīng)理陳偉博士表示:“要獲得好的人工智能體驗(yàn),就需要有多元的、高質(zhì)量的硬件平臺(tái),但是,將這些硬件直接應(yīng)用到人工智能應(yīng)用上,還有很多的壁壘。主要的壁壘是怎么樣能夠深度的挖掘和充分的運(yùn)用硬件的能力。”
我們都知道,同樣一種人工智能算法,應(yīng)用到不同的硬件平臺(tái)上,所得到的效果差異會(huì)非常的大。因?yàn)橐环N算法通過(guò)是根據(jù)某個(gè)硬件平臺(tái)來(lái)優(yōu)化的。
由于不同的網(wǎng)元所能提供的計(jì)算量是不一樣的,它能夠支撐的操作系統(tǒng)也各不相同的,因此有各自適用的不同的芯片架構(gòu)。而不同的芯片往往有各自不同的開(kāi)發(fā)方法,這樣對(duì)開(kāi)發(fā)者而言就帶來(lái)一定的困擾,也就是說(shuō)如果我們?yōu)槟骋环N芯片所開(kāi)發(fā)的軟件換了一個(gè)架構(gòu)以后,它可能是不適用的,這樣無(wú)形中就增加了開(kāi)發(fā)的門(mén)檻。
那么如何讓終端廠(chǎng)商能夠輕松的采用同樣一套AI算法,輕松實(shí)現(xiàn)從云端到終端側(cè)的跨平臺(tái)部署,并發(fā)揮出各個(gè)硬件平臺(tái)的能力呢?對(duì)此英特爾推出了全新的視覺(jué)推理和神經(jīng)網(wǎng)絡(luò)優(yōu)化工具套件OpenVINO。
強(qiáng)大的OpenVINO工具包
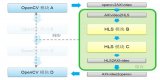
OpenVINO是英特爾基于自身現(xiàn)有的硬件平臺(tái)開(kāi)發(fā)的一種可以加快高性能計(jì)算機(jī)視覺(jué)和深度學(xué)習(xí)視覺(jué)應(yīng)用開(kāi)發(fā)速度工具套件,支持各種英特爾平臺(tái)的硬件加速器上進(jìn)行深度學(xué)習(xí),并且允許直接異構(gòu)執(zhí)行。
具體來(lái)看,OpenVINO包括英特爾深度學(xué)習(xí)部署工具包,具有模型優(yōu)化器和推理引擎,以及面向OpenCV和OpenVx的優(yōu)化的傳統(tǒng)計(jì)算機(jī)視覺(jué)庫(kù)。OpenVINO工具包可通過(guò)基于英特爾架構(gòu)的處理器(CPU)及核顯(Integrated GPU)和深度學(xué)習(xí)加速器(FPGA、Movidius VPU)的深度學(xué)習(xí)加速芯片,增強(qiáng)視覺(jué)系統(tǒng)功能和性能。
▲英特爾中國(guó)區(qū)物聯(lián)網(wǎng)事業(yè)部首席技術(shù)官兼首席工程師張宇博士
“在計(jì)算機(jī)視覺(jué)領(lǐng)域,業(yè)界有兩類(lèi)方法被廣泛的使用。一類(lèi)是深度學(xué)習(xí)的方法(主要做物體檢測(cè)、目標(biāo)識(shí)別),另外一類(lèi)是傳統(tǒng)的計(jì)算機(jī)視覺(jué)的方法(比如做光流的計(jì)算或者圖像的增強(qiáng)),這兩類(lèi)方法實(shí)際上都有在被使用。在OpenVINO里面,我們對(duì)這兩類(lèi)方法都有很好的支持(針對(duì)后一種,英特爾在OpenVINO中集成了媒體軟件開(kāi)發(fā)套件Media SDK,可幫助開(kāi)發(fā)者調(diào)用英特爾CPU里面集成GPU資源來(lái)實(shí)現(xiàn)視頻的編碼、解碼以及轉(zhuǎn)碼的操作)。OpenVINO包含一個(gè)深度學(xué)習(xí)的部署工具套件,這個(gè)工具套件可以幫助開(kāi)發(fā)者,把已經(jīng)訓(xùn)練好的網(wǎng)絡(luò)模型部署到目標(biāo)平臺(tái)之上進(jìn)行推理操作,所以O(shè)penVINO是幫助大家做推理的,而不是幫助大家做訓(xùn)練的。我們是幫助大家把這些訓(xùn)練的結(jié)果更好的、更快的能夠部署到英特爾的目標(biāo)平臺(tái)上做推理操作。”英特爾中國(guó)區(qū)物聯(lián)網(wǎng)事業(yè)部首席技術(shù)官兼首席工程師張宇博士解釋到。
目前比較流行的深度學(xué)習(xí)的框架主要有Caffe、Tensor Flow、MxNet,英特爾在設(shè)計(jì)OpenVINO的時(shí)候考慮到了目前開(kāi)發(fā)者的習(xí)慣,所以模型優(yōu)化器通過(guò)配置以后可以把這三個(gè)主要的開(kāi)發(fā)框架上所開(kāi)發(fā)的網(wǎng)絡(luò)能夠?qū)氲接⑻貭柕钠脚_(tái)上,而且導(dǎo)入的過(guò)程中,英特爾會(huì)根據(jù)目標(biāo)平臺(tái)的特性做一定的優(yōu)化,把這些優(yōu)化的結(jié)果轉(zhuǎn)換成中間表述文件——IR文件。這個(gè)文件里會(huì)包含優(yōu)化以后的網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu),以及優(yōu)化之后的模型參數(shù)和模型變量。這個(gè)IR文件后面會(huì)被推理引擎進(jìn)行讀取,推理引擎會(huì)根據(jù)開(kāi)發(fā)者所選用的目標(biāo)平臺(tái)去選用相應(yīng)的硬件插件。目前,OpenVINO可支持英特爾的CPU的插件、GPU插件、FPGA的插件以及Myriad VPU的插件。
大家應(yīng)該都知道,如果在一個(gè)針對(duì)數(shù)據(jù)中心的通用處理器上做的訓(xùn)練,它所產(chǎn)生的訓(xùn)練模型,如果把它部署在前端的一個(gè)嵌入式的推理平臺(tái)之上,它將會(huì)可能無(wú)法工作或者效果大打折扣,因?yàn)椴煌耐评砥脚_(tái)數(shù)據(jù)的精度不同,所支持的操作系統(tǒng)也不同,能夠提供的內(nèi)存的容量和計(jì)算性能也是不同的。因此,在應(yīng)用到前端之前需要對(duì)之前的模型進(jìn)行一定的優(yōu)化。
據(jù)介紹,例如自動(dòng)剔除Dropout層(主要用于訓(xùn)練),對(duì)一些激活函數(shù)的優(yōu)化等都可以O(shè)penVINO的模型優(yōu)化器來(lái)實(shí)現(xiàn)。目前英特爾已經(jīng)驗(yàn)證了超過(guò)150個(gè)在Caffe、MxNet和Tensor Flow上所設(shè)計(jì)的模型。
在推理引擎方面,OpenVINO的推理引擎實(shí)際上是一套C++函數(shù)庫(kù)以及C++的類(lèi),這樣一個(gè)推理引擎,實(shí)現(xiàn)的是對(duì)輸入數(shù)據(jù)的處理,并得到最終的結(jié)果,推理引擎是經(jīng)過(guò)簡(jiǎn)單、統(tǒng)一的API接口,來(lái)支持所有的英特爾架構(gòu),實(shí)現(xiàn)深度學(xué)習(xí)推理所需要的操作。這些操作包括對(duì)數(shù)據(jù)的讀取、對(duì)輸入輸出數(shù)據(jù)格式的定義以及調(diào)用相應(yīng)的硬件的插件,把這些中間的數(shù)據(jù)文件下載到你最終的執(zhí)行平臺(tái)之上,這是推理引擎要做的工作。
另外,OpenVINO這個(gè)工具套件訪(fǎng)問(wèn)實(shí)際上是分層的,不同的開(kāi)發(fā)者可以根據(jù)自己的使用的要求以及開(kāi)發(fā)的能力去選擇不同的API接口進(jìn)行調(diào)用OpenVINO。比如,對(duì)于一個(gè)新手,只是有一個(gè)好的想法,但沒(méi)有相應(yīng)的算法或者也不了解深度學(xué)習(xí)到底如何在硬件上進(jìn)行實(shí)現(xiàn)的話(huà),也可以通過(guò)OpenVINO里包含的很多應(yīng)用的示例來(lái)進(jìn)行學(xué)習(xí)實(shí)現(xiàn)。如果開(kāi)發(fā)者是能力極強(qiáng)的“超級(jí)用戶(hù)”,OpenVINO也可以提供直接調(diào)用硬件底層的接口實(shí)現(xiàn)對(duì)硬件直接的訪(fǎng)問(wèn)能力。
總結(jié)一下英特爾的OpenVINO?工具套件能帶來(lái)的一些優(yōu)勢(shì):首先是性能方面的提升,因?yàn)橥ㄟ^(guò)OpenVINO,大家可以方便的使用英特爾的各種硬件的加速資源,包括CPU、GPU、VPU、FPGA,這些資源能夠幫助大家提升深度學(xué)習(xí)的算法在做推理的時(shí)候的性能,而且這些執(zhí)行的過(guò)程中是支持異構(gòu)處理和異步執(zhí)行的,這樣的話(huà)能夠減少由于系統(tǒng)資源等待所占用的時(shí)間。另外,OpenVINO使用了經(jīng)過(guò)優(yōu)化以后的OpenCV和OpenVX,同時(shí)提供了很多應(yīng)用示例,可以縮短開(kāi)發(fā)時(shí)間。這些庫(kù)都支持異構(gòu)的執(zhí)行,所以大家如果編程的話(huà),編寫(xiě)一次,以后就可以通過(guò)異構(gòu)的接口支撐跑在其他的硬件平臺(tái)之上。
另外在深度學(xué)習(xí)方面,OpenVINO帶有模型優(yōu)化器、推理引擎以及超過(guò)20個(gè)預(yù)先訓(xùn)練的模型,大家可以利用給大家提供的這些工具,快速的實(shí)現(xiàn)自己基于深度學(xué)習(xí)的應(yīng)用,而且OpenVINO?使用了OpenCV、OpeenVX的基礎(chǔ)庫(kù),大家可以利用這些基礎(chǔ)庫(kù)去開(kāi)發(fā)自己特定的算法,實(shí)現(xiàn)自己的定制和創(chuàng)新。
根據(jù)英特爾公布的數(shù)據(jù)顯示,通過(guò)OpenVINO的提升,如果在英特爾的酷睿i77800X這個(gè)處理器平臺(tái)上去跑Google Nex這樣的一些開(kāi)放網(wǎng)絡(luò),它的相應(yīng)的性?xún)r(jià)比是目前市面上解決方案(NVIDIA Tesla P4)的兩倍以上。如果選用英特爾的FPGA的產(chǎn)品Altera 10 1150KLE PCIe卡,它的推理性能/功耗/成本比值的綜合考量的因素性能大概能達(dá)到NVIDIA Tesla P4的1.4倍以上。如果是基于Movidius平臺(tái)的Myriad 2 VPU,其經(jīng)過(guò)優(yōu)化的性能/功耗/成本的比值相比NVIDIA Tegra TX2 Jetson模塊將提升5倍以上,所以我們從中可以看到,使用OpenVINO在英特爾硬件平臺(tái)上所帶來(lái)的提升還是非常明顯的。
客戶(hù)怎么看?
現(xiàn)在圖象處理的算法實(shí)際上是非常多樣化的,圖象處理除了人臉識(shí)別以外,還有車(chē)輛分析、結(jié)構(gòu)化分析、行為分析等等,比如智能安防領(lǐng)域里基本上已經(jīng)很難有一個(gè)場(chǎng)景說(shuō)只需要一種算法,絕大部分都是要多種算法融合。所以,異構(gòu)計(jì)算應(yīng)該是一個(gè)趨勢(shì)。
作為英特爾的合作伙伴代表,宇視研發(fā)副總裁兼AI產(chǎn)品線(xiàn)總監(jiān)湯立波表示:“OpenVINO有幾個(gè)非常重要的價(jià)值,第一個(gè)就是可以通過(guò)一次訓(xùn)練來(lái)滿(mǎn)足不同的硬件平臺(tái)。在我們這個(gè)行業(yè),所有的產(chǎn)品在不同位置、不同場(chǎng)景的產(chǎn)品,對(duì)芯片的要求是不一樣的。比如它的功耗承受能力不一樣,性能要求也不一樣。所以我們?cè)诓煌漠a(chǎn)品上要用不同的芯片。以前是怎么辦呢?是在不同的硬件平臺(tái)就芯片上面落地的時(shí)候,研究開(kāi)發(fā)人員是要多次的開(kāi)發(fā),產(chǎn)生了大量的人力的浪費(fèi),而且大家知道現(xiàn)在人工智能這么火,人力的成本是非常高昂的,通過(guò)OpenVINO這樣一個(gè)方式,我們可以大量的節(jié)省成本,這也是一個(gè)好處。”
在本次發(fā)布會(huì)上,國(guó)內(nèi)知名的人工智能廠(chǎng)商云從科技還率先在國(guó)內(nèi)發(fā)布了首款基于OpenVINO工具包開(kāi)發(fā)的產(chǎn)品,并已開(kāi)始進(jìn)行大規(guī)模量產(chǎn)。
“2017年,我們自己開(kāi)始準(zhǔn)備推出我們自己基于英特爾平臺(tái)的產(chǎn)品,隨后就做了一款產(chǎn)品,外觀(guān)上一般,但是產(chǎn)品很不錯(cuò),因?yàn)橛杏⑻貭朮86里面的并行計(jì)算的模塊,更主要的是有OpenVINO的核心模塊在里面。基于這個(gè),我們?cè)谌斯ぶ悄芤约案餍袠I(yè)的廣泛應(yīng)用上,得到了很好的開(kāi)發(fā)。現(xiàn)在這款產(chǎn)品,我們已經(jīng)在幾十家行業(yè)客戶(hù),以及幾百個(gè)行業(yè)網(wǎng)點(diǎn)做推廣,也是有賴(lài)于英特爾成熟的生態(tài)體系。一款產(chǎn)品同時(shí)支持幾十家不同客戶(hù)需求的時(shí)候,無(wú)論是算法還是應(yīng)用不同的需求都能夠得心應(yīng)手,當(dāng)然這里面有很多英特爾同事的支持,因?yàn)槲覀冞x擇了一個(gè)合適的平臺(tái)。”云從科技項(xiàng)目總監(jiān)李軍這樣總結(jié)到。













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論