使用Isaac Gym來強化學習mycobot抓取任務
2023-04-11 14:57:12 5344
5344 
什么是深度強化學習? 眾所周知,人類擅長解決各種挑戰(zhàn)性的問題,從低級的運動控制(如:步行、跑步、打網球)到高級的認知任務。
2023-07-01 10:29:501002 
Facebook近日推出ReAgent強化學習(reinforcement learning)工具包,首次通過收集離線反饋(offline feedback)來實現(xiàn)策略評估(policy evaluation)。
2019-10-19 09:38:411347 現(xiàn)在說AI是未來人類技術進步的一大方向,相信大家都不會反對。說到AI和芯片技術的關系,我覺得主要體現(xiàn)在兩個方面:第一,AI的發(fā)展要求芯片技術不斷進步;第二,AI可以幫助芯片技術向前發(fā)展。
2019-08-12 06:38:51
的發(fā)展,一個好的 AI 技術產品該如何迭代與運營……
為了能夠與廣大開發(fā)者一起更好地擁抱 AI 技術的發(fā)展,5 月 13 日,由天工開物開源基金會、開源中國社區(qū)聯(lián)合發(fā)起的,面向廣大開發(fā)者的中國開源未來
2023-05-09 09:49:41
不斷變化的,因此深度學習是人工智能AI的重要組成部分。可以說人腦視覺系統(tǒng)和神經網絡。2、目標檢測、目標跟蹤、圖像增強、強化學習、模型壓縮、視頻理解、人臉技術、三維視覺、SLAM、GAN、GNN等。
2020-11-27 11:54:42
強化學習的另一種策略(二)
2019-04-03 12:10:44
如何訓練AI玩飛機大戰(zhàn)游戲(創(chuàng)號版)
2019-07-01 12:27:34
怎么在labview前面板寫一些字主要是為了前面板更好看一些 用的是labview8.5 ?
2012-05-08 10:50:09
時間安排大綱具體內容實操案例三天關鍵點1.強化學習的發(fā)展歷程2.馬爾可夫決策過程3.動態(tài)規(guī)劃4.無模型預測學習5.無模型控制學習6.價值函數(shù)逼近7.策略梯度方法8.深度強化學習-DQN算法系列9.
2022-04-21 14:57:39
一:深度學習DeepLearning實戰(zhàn)時間地點:1 月 15日— 1 月18 日二:深度強化學習核心技術實戰(zhàn)時間地點: 1 月 27 日— 1 月30 日(第一天報到 授課三天;提前環(huán)境部署 電腦
2021-01-10 13:42:26
電化學傳感器用來測定目標分子或物質的電學和電化學性質,從而進行定性和定量的分析和測量。電化學傳感器的發(fā)展具有悠久的歷史,它的基本理論和技術發(fā)展與電分析化學密切相關,最早的電化學傳感器可以追溯到20世紀50年代,并隨著微電子和材料加工技術不斷更新而發(fā)展。
2020-03-25 06:17:18
AI是如何設計微波集成電路的AI能學會設計集成電路,靠的是一個“基于聚類和異步的優(yōu)勢行動者評論家算法模型”。文章介紹道,該模型包含兩部分——聚類算法和強化學習神經網絡模型。其中,聚類算法用來對網格化
2019-08-16 07:00:00
針對強化學習在連續(xù)狀態(tài)連續(xù)動作空間中的維度災難問題,利用BP神經網絡算法作為值函數(shù)逼近策略,設計了自動駕駛儀。并引入動作池機制,有效避免飛行仿真中危險動作的發(fā)生。首先
2013-06-25 16:27:22 27
27 強化學習在RoboCup帶球任務中的應用_劉飛
2017-03-14 08:00:000 界聲譽卓著。在此前接受CSDN采訪時,楊強介紹了他目前的主要工作致力于一個將深度學習、強化學習和遷移學習有機結合的Reinforcement Transfer Learning(RTL)體系的研究。那么,這個技術框架對工業(yè)界的實際應用有什么用的實際意義?在本文中,CSDN結合楊強的另外一個身份國內人工智能創(chuàng)業(yè)
2017-10-09 18:23:180 與監(jiān)督機器學習不同,在強化學習中,研究人員通過讓一個代理與環(huán)境交互來訓練模型。當代理的行為產生期望的結果時,它得到正反饋。例如,代理人獲得一個點數(shù)或贏得一場比賽的獎勵。簡單地說,研究人員加強了代理人的良好行為。
2018-07-13 09:33:0024319 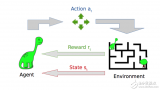
深度強化學習DRL自提出以來, 已在理論和應用方面均取得了顯著的成果。尤其是谷歌DeepMind團隊基于深度強化學習DRL研發(fā)的AlphaGo,將深度強化學習DRL成推上新的熱點和高度,成為人工智能歷史上一個新的里程碑。因此,深度強化學習DRL非常值得研究。
2018-06-29 18:36:0027596 薩頓在專訪中(再次)科普了強化學習、深度強化學習,并談到了這項技術的潛力,以及接下來的發(fā)展方向:預測學習
2017-12-27 09:07:1510857 針對路徑規(guī)劃算法收斂速度慢及效率低的問題,提出了一種基于分層強化學習及人工勢場的多Agent路徑規(guī)劃算法。首先,將多Agent的運行環(huán)境虛擬為一個人工勢能場,根據先驗知識確定每點的勢能值,它代表最優(yōu)
2017-12-27 14:32:020 本文提出了一種LCS和LS-SVM相結合的多機器人強化學習方法,LS-SVM獲得的最優(yōu)學習策略作為LCS的初始規(guī)則集。LCS通過與環(huán)境的交互,能更快發(fā)現(xiàn)指導多機器人強化學習的規(guī)則,為強化學習系統(tǒng)
2018-01-09 14:43:490 在風儲配置給定前提下,研究風電與儲能系統(tǒng)如何有機合作的問題。核心在于風電與儲能組成混合系統(tǒng)參與電力交易,通過合作提升其市場競爭的能力。針對現(xiàn)有研究的不足,在具有過程化樣本的前提下,引入強化學習算法
2018-01-27 10:20:502 傳統(tǒng)上,強化學習在人工智能領域占據著一個合適的地位。但強化學習在過去幾年已開始在很多人工智能計劃中發(fā)揮更大的作用。
2018-03-03 14:16:563924 強化學習是智能系統(tǒng)從環(huán)境到行為映射的學習,以使獎勵信號(強化信號)函數(shù)值最大,強化學習不同于連接主義學習中的監(jiān)督學習,主要表現(xiàn)在教師信號上,強化學習中由環(huán)境提供的強化信號是對產生動作的好壞作一種評價
2018-05-30 06:53:001234 Facebook近日宣布,將于近期開源PyTorch 1.0 AI框架,據悉,該框架是PyTorch與Caffe 2的結合,可以讓開發(fā)者無需遷移就從研究轉為生產。
2018-05-08 14:58:433182 導讀: Facebook近日宣布,將于近期開源PyTorch 1.0 AI框架,據悉,該框架是PyTorch與Caffe 2的結合,可以讓開發(fā)者無需遷移就從研究轉為生產。 Facebook近日宣布
2018-06-18 10:30:002901 當我們使用虛擬的計算機屏幕和隨機選擇的圖像來模擬一個非常相似的測試時,我們發(fā)現(xiàn),我們的“元強化學習智能體”(meta-RL agent)似乎是以類似于Harlow實驗中的動物的方式在學習,甚至在被顯示以前從未見過的全新圖像時也是如此。
2018-05-16 09:03:394475 
自動駕駛汽車首先是人工智能問題,而強化學習是機器學習的一個重要分支,是多學科多領域交叉的一個產物。今天人工智能頭條給大家介紹強化學習在自動駕駛的一個應用案例,無需3D地圖也無需規(guī)則,讓汽車從零開始在二十分鐘內學會自動駕駛。
2018-07-10 09:00:294676 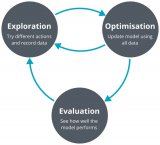
前段時間,OpenAI的游戲機器人在Dota2的比賽中贏了人類的5人小組,取得了團隊勝利,是強化學習攻克的又一游戲里程碑。
2018-07-13 08:56:014439 
強化學習是人工智能基本的子領域之一,在強化學習的框架中,智能體通過與環(huán)境互動,來學習采取何種動作能使其在給定環(huán)境中的長期獎勵最大化,就像在上述的棋盤游戲寓言中,你通過與棋盤的互動來學習。
2018-07-15 10:56:3717106 
這些具有一定難度的任務 OpenAI 自己也在研究,他們認為這是深度強化學習發(fā)展到新時代之后可以作為新標桿的算法測試任務,而且也歡迎其它機構與學校的研究人員一同研究這些任務,把深度強化學習的表現(xiàn)推上新的臺階。
2018-08-03 14:27:264305 結合 DL 與 RL 的深度強化學習(Deep Reinforcement Learning, DRL)迅速成為人工智能界的焦點。
2018-08-09 10:12:435789 強化學習作為一種常用的訓練智能體的方法,能夠完成很多復雜的任務。在強化學習中,智能體的策略是通過將獎勵函數(shù)最大化訓練的。獎勵在智能體之外,各個環(huán)境中的獎勵各不相同。深度學習的成功大多是有密集并且有效的獎勵函數(shù),例如電子游戲中不斷增加的“分數(shù)”。
2018-08-18 11:38:573362 而這時,強化學習會在沒有任何標簽的情況下,通過先嘗試做出一些行為得到一個結果,通過這個結果是對還是錯的反饋,調整之前的行為,就這樣不斷的調整,算法能夠學習到在什么樣的情況下選擇什么樣的行為可以得到最好的結果。
2018-08-21 09:18:2519123 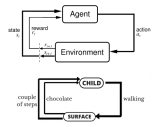
強化學習(RL)研究在過去幾年取得了許多重大進展。強化學習的進步使得 AI 智能體能夠在一些游戲上超過人類,值得關注的例子包括 DeepMind 攻破 Atari 游戲的 DQN,在圍棋中獲得矚目的 AlphaGo 和 AlphaGo Zero,以及在 Dota2 對戰(zhàn)人類職業(yè)玩家的Open AI Five。
2018-08-31 09:20:493498 強化學習是一種非常重要 AI 技術,它能使用獎勵(或懲罰)來驅動智能體(agents)朝著特定目標前進,比如它訓練的 AI 系統(tǒng) AlphaGo 擊敗了頂尖圍棋選手,它也是 DeepMind 的深度
2018-09-03 14:06:302653 強化學習是一種訓練主體最大化獎勵的學習機制,對于目標條件下的強化學習來說可以將獎勵函數(shù)設為當前狀態(tài)與目標狀態(tài)之間距離的反比函數(shù),那么最大化獎勵就對應著最小化與目標函數(shù)的距離。
2018-09-24 10:11:006779 之前接觸的強化學習算法都是單個智能體的強化學習算法,但是也有很多重要的應用場景牽涉到多個智能體之間的交互。
2018-11-02 16:18:1521016 本文作者通過簡單的方式構建了強化學習模型來訓練無人車算法,可以為初學者提供快速入門的經驗。
2018-11-12 14:47:394570 OpenAI 近期發(fā)布了一個新的訓練環(huán)境 CoinRun,它提供了一個度量智能體將其學習經驗活學活用到新情況的能力指標,而且還可以解決一項長期存在于強化學習中的疑難問題——即使是廣受贊譽的強化算法在訓練過程中也總是沒有運用監(jiān)督學習的技術。
2019-01-01 09:22:002122 
強化學習(RL)能通過獎勵或懲罰使智能體實現(xiàn)目標,并將它們學習到的經驗轉移到新環(huán)境中。
2018-12-24 09:29:562949 Facebook 還開源了 Horizon ,這是一個基于 PyTorch 1.0 構建的端到端平臺,也是第一個使用應用強化學習(RL)來優(yōu)化大規(guī)模生產環(huán)境中的系統(tǒng)的平臺。同時還擴展了 ONNX
2019-01-09 16:12:254213 在強化學習方面,Facebook開發(fā)了Horizon框架,利用強化學習在大規(guī)模生成系統(tǒng)中進行優(yōu)化。它吸收了研究領域大量使用的基于決策的方式,并應用于十億級別的數(shù)據集上。在部署了這套框架后,使得優(yōu)化視頻流和信息流更為高效。這套工具的開源搭建了強化學習研究和產品化之間的橋梁。
2019-01-11 09:37:134131 在一些情況下,我們會用策略函數(shù)(policy, 總得分,也就是搭建的網絡在測試集上的精度(accuracy),通過強化學習(Reinforcement Learning)這種通用黑盒算法來優(yōu)化。然而,因為強化學習本身具有數(shù)據利用率低的特點,這個優(yōu)化的過程往往需要大量的計算資源。
2019-01-28 09:54:224705 Google AI 與 DeepMind 合作推出深度規(guī)劃網絡 (PlaNet),這是一個純粹基于模型的智能體,能從圖像輸入中學習世界模型,完成多項規(guī)劃任務,數(shù)據效率平均提升50倍,強化學習又一突破。
2019-02-17 09:30:283036 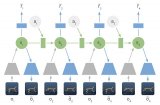
在傳統(tǒng)的多智體學習過程當中,有研究者在對其他智能體建模 (也即“對手建模”, opponent modeling) 時使用了遞歸推理,但由于算法復雜和計算力所限,目前還尚未有人在多智體深度強化學習 (Multi-Agent Deep Reinforcement Learning) 的對手建模中使用遞歸推理。
2019-03-05 08:52:434556 近日,Reddit一位網友根據近期OpenAI Five、AlphaStar的表現(xiàn),提出“深度強化學習是否已經到達盡頭”的問題。
2019-05-10 16:34:592313 該強化學習環(huán)境的核心是一種先進的足球游戲模擬,稱為“足球引擎”,它基于一個足球游戲版本經大量修改而成。根據兩支對方球隊的輸入動作,模擬了足球比賽中的常見事件和場景,包括進球、犯規(guī)、角球和點球、越位等。
2019-06-15 10:33:183947 在谷歌最新的論文中,研究人員提出了“非政策強化學習”算法OPC,它是強化學習的一種變體,它能夠評估哪種機器學習模型將產生最好的結果。數(shù)據顯示,OPC比基線機器學習算法有著顯著的提高,更加穩(wěn)健可靠。
2019-06-22 11:17:083374 Facebook AI近期對機器人技術非常熱衷,剛剛又開源了機器人框架PyRobot,該框架是與卡內基梅隆大學合作創(chuàng)建,可運行由Facebook的機器學習框架PyTorch訓練的深度學習模型。
2019-06-24 15:14:213675 近幾年來,強化學習在任務導向型對話系統(tǒng)中得到了廣泛的應用,對話系統(tǒng)通常被統(tǒng)計建模成為一個 馬爾科夫決策過程(Markov Decision Process)模型,通過隨機優(yōu)化的方法來學習對話策略。
2019-08-06 14:16:291836 Horizon社交VR世界將會進入Oculus Quest和Rift Platform,2020年正式上線。為了專心打造新的VR體驗,Facebook決定10月25日關閉Facebook Spaces和Oculus Rooms。
2019-09-26 16:55:393056 強化學習非常適合實現(xiàn)自主決策,相比之下監(jiān)督學習與無監(jiān)督學習技術則無法獨立完成此項工作。
2019-12-10 14:34:571092 Facebook AI Research(FAIR)開發(fā)了一種新的AI,在與Hanabi對抗時產生了令人印象深刻的結果。新的發(fā)展是Facebook AI邁出的重要一步。
2019-12-22 11:06:08890 惰性是人類的天性,然而惰性能讓人類無需過于復雜的練習就能學習某項技能,對于人工智能而言,是否可有基于惰性的快速學習的方法?本文提出一種懶惰強化學習(Lazy reinforcement learning, LRL) 算法。
2020-01-16 17:40:00745 本文檔的主要內容詳細介紹的是深度強化學習的筆記資料免費下載。
2020-03-10 08:00:000 近年來隨著強化學習的發(fā)展,使得智能體選擇恰當行為以實現(xiàn)目標的能力得到迅速地提升。目前研究領域主要使用兩種方法:一種是無模型(model-free)的強化學習方法,通過試錯的方式來學習預測成功的行為
2020-03-26 11:41:121801 強化學習(RL)是現(xiàn)代人工智能領域中最熱門的研究主題之一,其普及度還在不斷增長。 讓我們看一下開始學習RL需要了解的5件事。
2020-05-04 18:14:003117 
加州大學伯克利分校的一組研究人員本周開放了使用增強數(shù)據進行強化學習(RAD)的資源。
2020-05-11 23:09:041179 深度學習DL是機器學習中一種基于對數(shù)據進行表征學習的方法。深度學習DL有監(jiān)督和非監(jiān)督之分,都已經得到廣泛的研究和應用。強化學習RL是通過對未知環(huán)境一邊探索一邊建立環(huán)境模型以及學習得到一個最優(yōu)策略。強化學習是機器學習中一種快速、高效且不可替代的學習算法。
2020-05-16 09:20:403150 深度學習DL是機器學習中一種基于對數(shù)據進行表征學習的方法。深度學習DL有監(jiān)督和非監(jiān)督之分,都已經得到廣泛的研究和應用。強化學習RL是通過對未知環(huán)境一邊探索一邊建立環(huán)境模型以及學習得到一個最優(yōu)策略。強化學習是機器學習中一種快速、高效且不可替代的學習算法。
2020-06-13 11:39:405527 近期,有不少報道強化學習算法在 GO、Dota 2 和 Starcraft 2 等一系列游戲中打敗了專業(yè)玩家的新聞。強化學習是一種機器學習類型,能夠在電子游戲、機器人、自動駕駛等復雜應用中運用人工智能。
2020-07-27 08:50:15715 Viet Nguyen就是其中一個。這位來自德國的程序員表示自己只玩到了第9個關卡。因此,他決定利用強化學習AI算法來幫他完成未通關的遺憾。
2020-07-29 09:30:162429 訓練最新 AI 系統(tǒng)需要驚人的計算資源,這意味著囊中羞澀的學術界實驗室很難趕上富有的科技公司。但一種新的方法可以讓科學家在單臺計算機上訓練先機的 AI。2018 年 OpenAI 報告每 3.4 個月訓練最強大 AI 所需的處理能力會翻一番,其中深度強化學習對處理尤為苛刻。
2020-07-29 09:45:38581 強化學習屬于機器學習中的一個子集,它使代理能夠理解在特定環(huán)境中執(zhí)行特定操作的相應結果。目前,相當一部分機器人就在使用強化學習掌握種種新能力。
2020-11-06 15:33:491552 深度強化學習是深度學習與強化學習相結合的產物,它集成了深度學習在視覺等感知問題上強大的理解能力,以及強化學習的決策能力,實現(xiàn)了...
2020-12-10 18:32:50374 RLax(發(fā)音為“ relax”)是建立在JAX之上的庫,它公開了用于實施強化學習智能體的有用構建塊。。報道:深度強化學習實驗室作者:DeepRL ...
2020-12-10 18:43:23499 本文主要介紹深度強化學習在任務型對話上的應用,兩者的結合點主要是將深度強化學習應用于任務型對話的策略學習上來源:騰訊技術工程微信號
2020-12-10 19:02:45781 進入到2021年,AI領域的你最應該學的是什么?我覺得是強化學習。 為什么這么說?首先要知道什么是強化學習。 ? 強化學習是機器學習的一種,是一種行為學習模型。由算法提供數(shù)據分析反饋,引導用戶逐步
2021-01-18 16:16:421504 強化學習( Reinforcement learning,RL)作為機器學習領域中與監(jiān)督學習、無監(jiān)督學習并列的第三種學習范式,通過與環(huán)境進行交互來學習,最終將累積收益最大化。常用的強化學習算法分為
2021-04-08 11:41:5811 深度強化學習(DRL)作為機器學習的重要分攴,在 Alphago擊敗人類后受到了廣泛關注。DRL以種試錯機制與環(huán)境進行交互,并通過最大化累積獎賞最終得到最優(yōu)策略。強化學習可分為無模型強化學習和模型
2021-04-12 11:01:529 當機器人遇見強化學習,會碰出怎樣的火花? 一名叫 Cassie 的機器人,給出了生動演繹。 最近,24 歲的中國南昌小伙李鐘毓和其所在團隊,用強化學習教 Cassie 走路 ,目前它已學會蹲伏走路
2021-04-13 09:35:092164 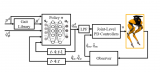
強化學習是人工智能領域中的一個研究熱點。在求解強化學習問題時,傳統(tǒng)的最小二乘法作為一類特殊的函數(shù)逼近學習方法,具有收斂速度快、充分利用樣本數(shù)據的優(yōu)勢。通過對最小二乘時序差分算法
2021-04-23 15:03:035 利用深度強化學習技術實現(xiàn)路口信號控制是智能交通領域的硏究熱點。現(xiàn)有硏究大多利用強化學習來全面刻畫交通狀態(tài)以及設計有效強化學習算法以解決信號配時問題,但這些研究往往忽略了信號燈狀態(tài)對動作選擇的影響以及
2021-04-23 15:30:5321 目前壯語智能信息處理研究處于起步階段,缺乏自動詞性標注方法。針對壯語標注語料匱乏、人工標注費時費力而機器標注性能較差的現(xiàn)狀,提出一種基于強化學習的壯語詞性標注方法。依據壯語的文法特點和中文賓州
2021-05-14 11:29:3514 壓邊為改善板料拉深制造的成品質量,釆用深度強化學習的方法進行拉深過程旳壓邊力優(yōu)化控制。提岀一種基于深度強化學習與有限元仿真集成的壓邊力控制模型,結合深度神經網絡的感知能力與強化學習的決策能力,進行
2021-05-27 10:32:390 一種新型的多智能體深度強化學習算法
2021-06-23 10:42:4736 基于深度強化學習的無人機控制律設計方法
2021-06-23 14:59:1046 基于強化學習的虛擬場景角色乒乓球訓練
2021-06-27 11:34:3362 使用Matlab進行強化學習電子版資源下載
2021-07-16 11:17:090 騰訊一直積極地推動強化學習在游戲AI領域的發(fā)展,并在2019年推出了“開悟”AI開放研究平臺,提供不同游戲的訓練場景、支撐AI進行強化訓練的大規(guī)模算力、統(tǒng)一的強化學習框架以加速研發(fā)速度、通用的訓練
2021-10-22 09:23:241320 多Agent 深度強化學習綜述 來源:《自動化學報》,作者梁星星等 摘 要?近年來,深度強化學習(Deep reinforcement learning,DRL) 在諸多復雜序貫決策問題中取得巨大
2022-01-18 10:08:011226 
本文主要內容是如何用Oenflow去復現(xiàn)強化學習玩 Flappy Bird 小游戲這篇論文的算法關鍵部分,還有記錄復現(xiàn)過程中一些踩過的坑。
2022-01-26 18:19:342 最近,國內的人工智能(AI)開源生態(tài)突然熱鬧了起來,這廂清華大學剛開源了一個強化學習平臺,那邊華為和曠視又相繼開源了AI計算和深度...
2022-02-07 11:45:361 ./oschina_soft/horizon.zip
2022-06-21 09:56:333 來源:DeepHub IMBA 強化學習的基礎知識和概念簡介(無模型、在線學習、離線強化學習等) 機器學習(ML)分為三個分支:監(jiān)督學習、無監(jiān)督學習和強化學習。 監(jiān)督學習(SL) : 關注在給
2022-12-20 14:00:02828 電子發(fā)燒友網站提供《ESP32上的深度強化學習.zip》資料免費下載
2022-12-27 10:31:450 作者:Siddhartha Pramanik 來源:DeepHub IMBA 目前流行的強化學習算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。這些算法
2023-02-03 20:15:06747 本文介紹了強化學習與智能駕駛決策規(guī)劃。智能駕駛中的決策規(guī)劃模塊負責將感知模塊所得到的環(huán)境信息轉化成具體的駕駛策略,從而指引車輛安全、穩(wěn)定的行駛。真實的駕駛場景往往具有高度的復雜性及不確定性。如何制定
2023-02-08 14:05:161441 強化學習(RL)是人工智能的一個子領域,專注于決策過程。與其他形式的機器學習相比,強化學習模型通過與環(huán)境交互并以獎勵或懲罰的形式接收反饋來學習。
2023-06-09 09:23:23355 ,可以節(jié)省至多 95% 的訓練開銷。 深度強化學習模型的訓練通常需要很高的計算成本,因此對深度強化學習模型進行稀疏化處理具有加快訓練速度和拓展模型部署的巨大潛力。 然而現(xiàn)有的生成小型模型的方法主要基于知識蒸餾,即通過迭
2023-06-11 21:40:02356 
前言 DeepMind 最近在 Nature 發(fā)表了一篇論文 AlphaDev[2, 3],一個利用強化學習來探索更優(yōu)排序算法的AI系統(tǒng)。 AlphaDev 系統(tǒng)直接從 CPU 匯編指令的層面入手
2023-06-19 10:49:27357 
來源:DeepHubIMBA強化學習的基礎知識和概念簡介(無模型、在線學習、離線強化學習等)機器學習(ML)分為三個分支:監(jiān)督學習、無監(jiān)督學習和強化學習。監(jiān)督學習(SL):關注在給定標記訓練數(shù)據
2023-01-05 14:54:05419 
作者:SiddharthaPramanik來源:DeepHubIMBA目前流行的強化學習算法包括Q-learning、SARSA、DDPG、A2C、PPO、DQN和TRPO。這些算法已被用于在游戲
2023-02-06 15:06:38665 電子發(fā)燒友網站提供《人工智能強化學習開源分享.zip》資料免費下載
2023-06-20 09:27:281 摘要:基于強化學習的目標檢測算法在檢測過程中通常采用預定義搜索行為,其產生的候選區(qū)域形狀和尺寸變化單一,導致目標檢測精確度較低。為此,在基于深度強化學習的視覺目標檢測算法基礎上,提出聯(lián)合回歸與深度
2023-07-19 14:35:020 體的發(fā)展,從最早的 AlphaGo、AlphaZero 到后來的多模態(tài)、多任務、多具身 AI 智能體 Gato,智能體的訓練方法和能力都在不斷演進。 從中不難發(fā)現(xiàn),隨著大模型越來越成為人工智能發(fā)展的主流趨勢,DeepMind 在智能體的開發(fā)中不斷嘗試將強化學習與自然語言處理、計算機視覺
2023-07-24 16:55:02296 
訊維模擬矩陣在深度強化學習智能控制系統(tǒng)中的應用主要是通過構建一個包含多種環(huán)境信息和動作空間的模擬矩陣,來模擬和預測深度強化學習智能控制系統(tǒng)在不同環(huán)境下的表現(xiàn)和效果,從而優(yōu)化控制策略和提高系統(tǒng)的性能
2023-09-04 14:26:36295 
擴散模型(diffusion model)在 CV 領域甚至 NLP 領域都已經有了令人印象深刻的表現(xiàn)。最近的一些工作開始將 diffusion model 用于強化學習(RL)中來解決序列決策問題
2023-10-02 10:45:02403 
強化學習是機器學習的方式之一,它與監(jiān)督學習、無監(jiān)督學習并列,是三種機器學習訓練方法之一。 在圍棋上擊敗世界第一李世石的 AlphaGo、在《星際爭霸2》中以 10:1 擊敗了人類頂級職業(yè)玩家
2023-10-30 11:36:401051 
 電子發(fā)燒友App
電子發(fā)燒友App









 工商網監(jiān)
工商網監(jiān)
評論