 電子發燒友App
電子發燒友App


開源的深度學習神經網絡正步入成熟,而現在有許多框架具備為個性化方案提供先進的機器學習和人工智能的能力。那么如何決定哪個開源框架最適合你呢?本文試圖通過對比深度學習各大框架的優缺點,從而為各位讀者提供一個參考。你最看好哪個深度學習框架呢?
現在的許多機器學習框架都可以在圖像識別、手寫識別、視頻識別、語音識別、目標識別和自然語言處理等許多領域大展身手,但卻并沒有一個完美的深度神經網絡能解決你的所有業務問題。所以,本文希望下面的圖表和講解能夠提供直觀方法,幫助讀者解決業務問題。
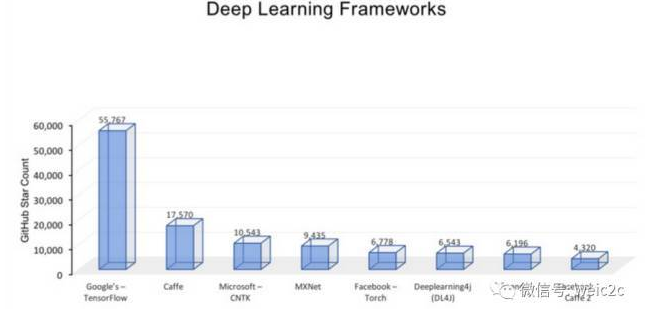
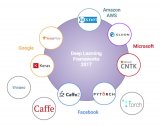
下圖總結了在 GitHub 中最受歡迎的開源深度學習框架排名,該排名是基于各大框架在 GitHub 里的收藏數,這個數據由 Mitch De Felice 在 2017 年 5 月初完成。
TensorFlow
地址: https://www.tensorflow.org/
TensorFlow 最開始是由谷歌一個稱之為 DistBelief V2 的庫發展而來,它是一個公司內部的深度神經網絡庫,隸屬于谷歌大腦項目。有一些人認為 TensorFlow 是由 Theano 徹底重構而來。
谷歌開源 TensorFlow 后,立即吸引了一大批開發愛好者。TensorFlow 可以提供一系列的能力,例如圖像識別、手寫識別、語音識別、預測以及自然語言處理等。2015 年 11 月 9 號,TensorFlow 在 Apache 2.0 協議下開源發布。
TensorFlow 1.0 版本已于 2017 年 2 月 15 日發布,這個版本是之前 8 個版本的優化改進版,其致力于解決 Tensorflow 之前遇到的一系列問題以及完善一些核心能力。TensorFlow 獲得成功的因素有:
TensorFlow 提供了如下工具:
TensorBoard:對于網絡模型和效果來說是一個設計優良的可視化工具。
TensorFlow Serving:可以保持相同的服務器架構和 API,使得部署新算法和實驗變得簡單。TensorFlow Serving 提供了與 TensorFlow 模型開箱即用的整合,但同時還能很容易擴展到其它類型的模型和數據。
TensorFlow 編程接口支持 Python 和 C++。隨著 1.0 版本的公布,Java、Go、R 和 Haskell API 的 alpha 版本也將被支持。此外,TensorFlow 還可在谷歌云和亞馬孫云中運行。
隨著 0.12 版本的發行,TensorFlow 將支持 Windows 7、 Windows 10 和 Server 2016。由于 TensorFlow 使用 C++ Eigen 庫,所以庫可在 ARM 架構上編譯和優化。這也就意味著你可以在各種服務器和移動設備上部署你的訓練模型,而無需執行單獨的模型解碼器或者加載 Python 解釋器。
TensorFlow 支持細粒度的網格層,而且允許用戶在無需用低級語言實現的情況下構建新的復雜的層類型。子圖執行操作允許你在圖的任意邊緣引入和檢索任意數據的結果。這對調試復雜的計算圖模型很有幫助。
分布式 TensorFlow(Distributed TensorFlow)被加進了 0.8 版本,它允許模型并行,這意味著模型的不同部分可在不同的并行設備上被訓練。
自 2016 年 3 月,斯坦福大學、伯克利大學、多倫多大學和 Udacity 都將這個框架作為一個免費的大規模在線開放課程進行教授。
TensorFlow 的缺點如下:
TensorFlow 的每個計算流都必須構造為一個靜態圖,且缺乏符號性循環(symbolic loops),這會帶來一些計算困難。
沒有對視頻識別很有用的三維卷積(3-D convolution)。
盡管 TensorFlow 現在比起始版本(v0.5)快了 58 倍,,但在執行性能方面依然落后于競爭對手。
Caffe
地址: http://caffe.berkeleyvision.org/
Caffe 是賈揚清的杰作,目前他在 Facebook AI 平臺擔任首席工程師。Caffe 可能是自 2013 年底以來第一款主流的工業級深度學習工具包。正因為 Caffe 優秀的卷積模型,它已經成為計算機視覺界最流行的工具包之一,并在 2014 年的 ImageNet 挑戰賽中一舉奪魁。Caffe 遵循 BSD 2-Clause 協議。
Caffe 的快速使其完美應用于實驗研究和商業部署。Caffe 可在英偉達單個 K40 GPU 上每天處理 6000 萬張圖像。這大概是 1 毫秒預測一張圖片,4 毫秒學習一張圖片的速度,而且最新的版本處理速度會更快。
Caffe 基于 C++,因此可在多種設備上編譯。它跨平臺運行,并包含 Windows 端口。Caffe 支持 C++、Matlab 和 Python 編程接口。Caffe 擁有一個龐大的用戶社區,人們在其中為被稱為「Model Zoo(https://github.com/BVLC/caffe/wiki/Model-Zoo)」的深度網絡庫做貢獻。AlexNet 和 GoogleNet 就是社群用戶構建的兩個流行網絡。
雖然 Caffe 在視頻識別領域是一個流行的深度學習網絡,但是 Caffe 卻不能像 TensorFlow、CNTK 和 Theano 那樣支持細粒度網絡層。構建復雜的層類型必須以低級語言完成。由于其遺留架構,Caffe 對循環網絡和語言建模的支持總體上很薄弱。
Caffe2
地址: https://caffe2.ai/
目前,賈揚清和他在 Facebook 的團隊正在開發新一代框架 Caffe2。今年 4 月 18 日,Facebook 開源了 Caffe2。Caffe 2 與 Caffe 的區別是什么?Caffe2 更注重模塊化,在移動端、大規模部署上表現卓越。如同 TensorFlow,Caffe2 使用 C++ Eigen 庫,支持 ARM 架構。
用一個實用腳本,Caffe 上的模型可輕易地被轉變到 Caffe2 上。Caffe 設計的選擇使得它處理視覺類型的難題時很完美。Caffe2 延續了它對視覺類問題的支持,且增加了對自然語言處理、手寫識別、時序預測有幫助的 RNN 和 LSTM 支持。
期待不久之后能看到 Caffe 2 超越 Caffe,就像它宣稱的那樣在深度學習社區流行。
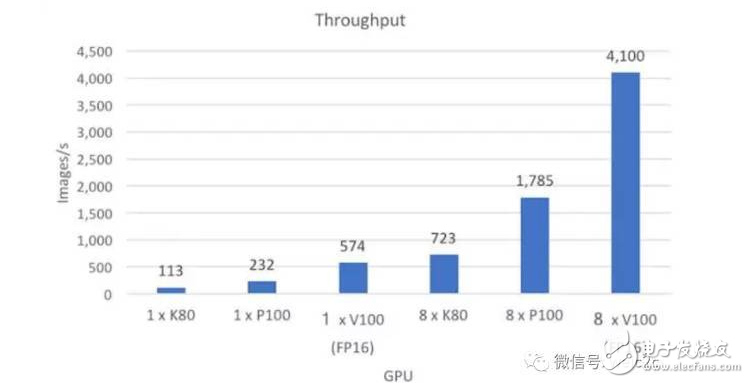
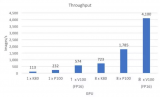
在本周三英偉達推出 Volta 架構的第一塊加速卡 Tesla V100 后,Caffe 的開發者第一時間展示了 Tesla V100 在 Caffe2 上運行 ResNet-50 的評測。數據顯示在新框架和新硬件的配合下,模型每秒鐘可以處理 4100 張圖片。
鏈接: https://caffe2.ai/blog/2017/05/10/caffe2-adds-FP16-training-support.html
CNTK
鏈接: https://github.com/Microsoft/CNTK/wiki
微軟的 CNTK(Microsoft Cognitive Toolkit)最初是面向語音識別的框架。CNTK 支持 RNN 和 CNN 類型的網絡模型,從而在處理圖像、手寫字體和語音識別問題上,它是很好的選擇。使用 Python 或 C++ 編程接口,CNTK 支持 64 位的 Linux 和 Windows 系統,在 MIT 許可證下發布。
與 TensorFlow 和 Theano 同樣,CNTK 使用向量運算符的符號圖(symbolic graph)網絡,支持如矩陣加/乘或卷積等向量操作。此外,像 TensorFlow 和 Theano 一樣,CNTK 有豐富的細粒度的網絡層構建。構建塊(操作)的細粒度使用戶不需要使用低層次的語言(如 Caffe)就能創建新的復雜的層類型。
CNTK 也像 Caffe 一樣基于 C++ 架構,支持跨平臺的 CPU/GPU 部署。CNTK 在 Azure GPU Lab 上顯示出最高效的分布式計算性能。目前,CNTK 不支持 ARM 架構,這限制了其在移動設備上的功能。
MXNet
鏈接: http://mxnet.io/
MXNet(發音為 mix-net)起源于卡內基梅隆大學和華盛頓大學的實驗室。MXNet 是一個全功能、可編程和可擴展的深度學習框架,支持最先進的深度學習模型。MXNet 支持混合編程模型(命令式和聲明式編程)和多種編程語言的代碼(包括 Python、C++、R、Scala、Julia、Matlab 和 JavaScript)。2017 年 1 月 30 日,MXNet 被列入 Apache Incubator 開源項目。
MXNet 支持深度學習架構,如卷積神經網絡(CNN)、循環神經網絡(RNN)和其包含的長短時間記憶網絡(LTSM)。該框架為圖像、手寫文字和語音的識別和預測以及自然語言處理提供了出色的工具。有些人稱 MXNet 是世界上最好的圖像分類器。
MXNet 具有可擴展的強大技術能力,如 GPU 并行和內存鏡像、快速編程器開發和可移植性。此外,MXNet 與 Apache Hadoop YARN(一種通用分布式應用程序管理框架)集成,使 MXNet 成為 TensorFlow 有力的競爭對手。
MXNet 不僅僅只是深度網絡框架,它的區別在于支持生成對抗網絡(GAN)模型。該模型啟發自實驗經濟學方法的納什均衡。
Torch
鏈接: http://torch.ch/
Torch 由 Facebook 的 Ronan Collobert 和 Soumith Chintala,Twitter 的 Clement Farabet(現任職于英偉達),以及 Google DeepMind 的 Koray Kavukcuoglu 共同開發。很多科技巨頭(如 Facebook、Twitter 和英偉達)都使用定制版的 Torch 用于人工智能研究,這大大促進了 Torch 的開發。Torch 是 BSD 3 協議下的開源項目。然而,隨著 Facebook 對 Caffe 2 的研究,以及其對移動設備的支持,Caffe 2 正成為主要的深度學習框架。
Torch 的編程語言為 Lua。Lua 不是主流語言,在開發人員沒有熟練掌握 Lua 之前,使用 Torch 很難提高開發的整體生產力。
Torch 缺乏 TensorFlow 的分布式應用程序管理框架,也缺乏 MXNet 和 Deeplearning4J 對 YARN 的支持。缺乏多種編程語言的 API 也限制了開發人員。
PyTorch
地址: http://pytorch.org/
PyTorch 由 Adam Paszke、Sam Gross 與 Soumith Chintala 等人牽頭開發,其成員來自 Facebook FAIR 和其他多家實驗室。它是一種 Python 優先的深度學習框架,在今年 1 月被開源,提供了兩種高層面的功能:
使用強大的 GPU 加速的 Tensor 計算(類似 numpy)
構建于基于 tape 的 autograd 系統的深度神經網絡
該框架結合了 Torch7 高效靈活的 GPU 加速后端庫與直觀的 Python 前端,它的特點是快速成形、代碼可讀和支持最廣泛的深度學習模型。如有需要,你可以復用你最喜歡的 Python 軟件包(如 numpy、scipy 和 Cython)來擴展 PyTorch。該框架因為其靈活性和速度,在推出以后迅速得到了開發者和研究人員的青睞。隨著 GitHub 上越來越多代碼的出現,PyTorch 作為新框架缺乏資源的問題已經得以緩解。
Deeplearning4J
地址: https://deeplearning4j.org/
Deeplearning4J(DL4J)是用 Java 和 Scala 編寫的 Apache 2.0 協議下的開源、分布式神經網絡庫。DL4J 最初由 SkyMind 公司的 Adam Gibson 開發,是唯一集成了 Hadoop 和 Spark 的商業級深度學習網絡,并通過 Hadoop 和 Spark 協調多個主機線程。DL4J 使用 Map-Reduce 來訓練網絡,同時依賴其它庫來執行大型矩陣操作。
DL4J 框架支持任意芯片數的 GPU 并行運行(對訓練過程至關重要),并支持 YARN(Hadoop 的分布式應用程序管理框架)。DL4J 支持多種深度網絡架構:RBM、DBN、卷積神經網絡(CNN)、循環神經網絡(RNN)、RNTN 和長短時間記憶網絡(LTSM)。DL4J 還對矢量化庫 Canova 提供支持。
DL4J 使用 Java 語言實現,本質上比 Python 快。在用多個 GPU 解決非平凡圖像(non-trivial image)識別任務時,它的速度與 Caffe 一樣快。該框架在圖像識別、欺詐檢測和自然語言處理方面的表現出眾。
Theano
地址: http://deeplearning.net/software/theano/
Theano 由蒙特利爾大學算法學習人工智能實驗室(MILA)維護。以 Theano 的創始人 Yoshua Bengio 為首,該實驗室是深度學習研究領域的重要貢獻者,擁有約 30 至 40 名學生和教師。Theano 支持快速開發高效的機器學習算法,在 BSD 協議下發布。
Theano 的架構如同一個黑箱;整個代碼庫和接口使用 Python,其中 C/CUDA 代碼被打包成 Python 字符串。這使得開發人員很難導航(navigate)、調試和重構。
Theano 開創了將符號圖用于神經網絡編程的趨勢。Theano 的符號式 API 支持循環控制(即 scan),這使得實現 RNN 容易且高效。
Theano 缺乏分布式應用程序管理框架,只支持一種編程開發語言。Theano 是很好的學術研究工具,在單個 CPU 上運行的效率比 TensorFlow 更有效。然而,在開發和支持大型分布式應用程序時,使用 Theano 可能會遇到挑戰。
開源 vs. 非開源
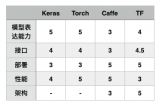
隨著深度學習的不斷發展,我們必將看到 TensorFlow、Caffe 2 和 MXNet 之間的不斷競爭。另一方面,軟件供應商也會開發具有先進人工智能功能的產品,從數據中獲取最大收益。風險:你將購買非開源的人工智能產品還是使用開源框架?有了開源工具,確定最適合的深度學習框架也是兩難問題。在非開源產品中,你是否準備了退出策略?人工智能的收益會隨著工具的學習能力的進步而上升,所以看待這些問題都需要用長遠的觀點。



















 工商網監
工商網監
評論