 電子發(fā)燒友App
電子發(fā)燒友App











 創(chuàng)作
創(chuàng)作 發(fā)文章
發(fā)文章 發(fā)帖
發(fā)帖  提問
提問  發(fā)資料
發(fā)資料 發(fā)視頻
發(fā)視頻資料介紹
本文轉(zhuǎn)載自:網(wǎng)絡交換FPGA微信公眾號
近年來,隨著集成電路工藝的不斷進步,大數(shù)據(jù)與人工智能的興起,數(shù)據(jù)中心的網(wǎng)絡負載愈來愈高,然而由于摩爾定律和Dennard縮放定律的失效,通用處理器依靠加深流水線深度和增加多核并行都受到功耗墻和存儲器墻的限制。星球級算力需求的增加促使定制化硬件逐漸興起(見公眾號文章:未來已來:ASIC云和行星級應用程序的數(shù)據(jù)中心),從RDMA到RoCE V2到TOE設備,數(shù)據(jù)中心網(wǎng)絡從10Gbps發(fā)展到40Gbps,目前100Gbps和400Gbps的接口正在成為主流。本文設計的100Gbps網(wǎng)卡基于一款開源100Gbps NIC剛玉(見公眾號文章:業(yè)界第一個真正意義上開源100 Gbps NIC Corundum介紹),在理解消化代碼的基礎上,基于其架構(gòu)將部分核心代碼進行修改,使其更適合于硬件實現(xiàn),并為后續(xù)擴展功能進行了前期預研和準備。
公眾號文章《業(yè)界第一個真正意義上開源100 Gbps NIC Corundum介紹》發(fā)出后,得到了很多粉絲的關注,大家紛紛留言討論。因此,本文也是對眾多問題的簡單回應。另外,特別感謝Xilinx提供免費試用的Alveo U50網(wǎng)卡,我們把原本搭載在VCU118板卡上的剛玉工程移植到了Alveo U50板卡上,與VCU118板卡一起實現(xiàn)了兩臺普通電腦的100Gbps光纖連接,并進行了非優(yōu)化加速情況下普通應用的測試。
隨著云計算的興起,越來越多的計算被部署到云端來執(zhí)行,數(shù)據(jù)中心的運營模式逐漸云化,從接入模式來看,當前部署的云計算主要分為公有云、私有云和混合云。私有云主要是單位或者個人使用的云計算資源,不對外提供,因此可以不兼容傳統(tǒng)以太網(wǎng),在諸如高性能的分布式計算應用場景下有較好的應用前景。公有云通過Internet為用戶提供服務,因此需要兼容以太網(wǎng)。再加上需要定制加速的應用越來越多,可編程的Smart NIC逐漸的走上了舞臺中央。
高性能數(shù)據(jù)中心的網(wǎng)絡演進趨勢
軟硬件協(xié)同優(yōu)化方法
在1Gbps時代,由操作系統(tǒng)網(wǎng)絡、協(xié)議棧和進程調(diào)度引起的開銷是可以接受的,但是隨著定制化硬件的性能越來越高,網(wǎng)絡協(xié)議棧和進程上下文切換引起的開銷變得不可接受。針對協(xié)議棧的開銷,人們提出了分段卸載功能,將數(shù)據(jù)面卸載到可編程網(wǎng)卡設備而在處理器上僅對控制面進行處理;在用戶側(cè),應用程序通過BSD Socket接口和協(xié)議棧通信,然而協(xié)議棧進程和網(wǎng)卡驅(qū)動程序位于內(nèi)核態(tài),頻繁發(fā)生的用戶態(tài)和內(nèi)核態(tài)上下文切換和數(shù)據(jù)緩沖區(qū)的拷貝帶來了極大的CPU開銷。為了解決這個問題,提出了諸如英特爾的DPDK的用戶態(tài)協(xié)議棧,這些協(xié)議棧大多涉及或支持無鎖的Ring操作,更換了用戶Socket API,采用內(nèi)存重映射等技術實現(xiàn)DMA零拷貝技術。可見,采用軟硬件協(xié)同設計方法是優(yōu)化網(wǎng)絡中心的最佳方案。
RDMA技術
RDMA(RemoteDirect Memory Access)技術全稱遠程直接內(nèi)存訪問,就是為了解決網(wǎng)絡傳輸中服務器端數(shù)據(jù)處理的延遲而產(chǎn)生的。RDMA有以下三個特性:
Remote:無CPU參與,數(shù)據(jù)通過網(wǎng)絡與遠程機器間進行數(shù)據(jù)傳輸。
Direct:沒有內(nèi)核態(tài)的切換,有關發(fā)送傳輸?shù)乃袃?nèi)容都卸載到網(wǎng)卡上。
Memory:在用戶空間虛擬內(nèi)存與RNIC網(wǎng)卡直接進行數(shù)據(jù)傳輸不涉及到系統(tǒng)內(nèi)核,沒有額外的數(shù)據(jù)移動和復制。
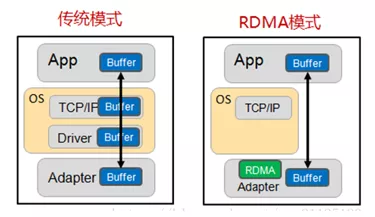
值得注意的是,RDMA沒有使用標準的TCP/IP協(xié)議,而是提出了自己的一套傳輸協(xié)議,因此不支持廣域網(wǎng)的傳輸,為了支持公有云的設計,RDMA在承載網(wǎng)絡上設計了三套標準。
1)實現(xiàn)在InfiniBand網(wǎng)絡。InfiniBand是專為RDMA設計的一套網(wǎng)絡,在硬件級別保證數(shù)據(jù)可靠傳輸。需要專用的IB交換機和IB網(wǎng)卡,不支持Internet連接,主要適用于私有云和分布式計算。
2)RoCE(RDMAover Converged Ethernet),分為V1版本和V2版本。RoCEV1將RDMA協(xié)議運行在以太網(wǎng)協(xié)議上,而RoCEV2將RDMA協(xié)議運行在UDP協(xié)議上。構(gòu)建RoCE網(wǎng)絡需要專用網(wǎng)卡,但是交換機可以兼容標準以太網(wǎng)交換機,因此可以用于構(gòu)建公有云和數(shù)據(jù)中心。
3)iWarp(internetWide Area RDMA Protocol),iWarp將RDMA協(xié)議運行在TCP協(xié)議上,與RoCE具有類似特性。
目前,RoCE由于支持Internet并且較iWarp協(xié)議更加簡單,擁有較大的市場和更好的前景。
另外,針對Smart NIC的研究現(xiàn)在也被推上高潮,由于采用了嵌入式的CPU,智能網(wǎng)卡可以進一步降低對Host主機的依賴,因此正在被數(shù)據(jù)中心廣泛采用。
開源100Gbps NIC(Corundum)架構(gòu)簡介
高性能NIC采用基于隊列和描述符的機制完成數(shù)據(jù)發(fā)送和接收的調(diào)制解調(diào)。描述符即指向內(nèi)存中數(shù)據(jù)物理地址的一組地址描述邏輯,隊列被實現(xiàn)為內(nèi)存中連續(xù)的、可以存放多個描述符的環(huán)形緩沖區(qū)。網(wǎng)卡的驅(qū)動程序發(fā)出內(nèi)存屏障,生成數(shù)據(jù)和對應的描述符后通過門鈴操作告知板卡,板卡獲取描述符后解析,并產(chǎn)生對數(shù)據(jù)的處理操作。
從系統(tǒng)結(jié)構(gòu)上來看,NIC的頂層包含PCIe IP和DMA接口、100Gbps MAC IP和PHY及相應的以太網(wǎng)接口,頂層還需要包含一個或者多個Interface接口,一個Interface接口被實現(xiàn)為Host下的一個NIC,即操作系統(tǒng)級別的網(wǎng)絡接口。網(wǎng)絡接口內(nèi)部主要用于戶邏輯的實現(xiàn),包括用于維護NIC隊列的隊列管理邏輯,描述符獲取和操作完成報文寫邏輯、發(fā)送和接收引擎以及發(fā)送調(diào)度程序,用于中間暫存數(shù)據(jù)的分段存儲器。
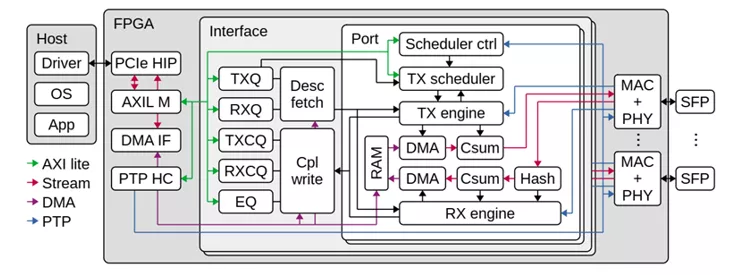
在發(fā)送方向上,由驅(qū)動更新生產(chǎn)者指針并通過PCIe的下行鏈路通知到板卡寄存器,發(fā)送隊列管理邏輯通過Doorbell操作告知發(fā)送調(diào)度程序。發(fā)送調(diào)度采用RR調(diào)度算法從已啟用的隊列進行調(diào)度,而后發(fā)送調(diào)度向發(fā)送引擎發(fā)起req請求。發(fā)送引擎收到傳輸請求后,向?qū)犃邪l(fā)送描述符獲取請求,最終,描述符獲取請求由描述符獲取模塊路由到發(fā)送隊列管理模塊,發(fā)送隊列管理模塊將對應的狀態(tài)響應到描述符獲取模塊,描述符獲取模塊使用DMA接口上的控制接口將描述符從隊列取出后放到中間段RAM,而后將描述符獲取狀態(tài)返回到發(fā)送引擎。發(fā)送引擎根據(jù)描述符獲取狀態(tài)到中間段RAM取得描述符,而后使用DMA的數(shù)據(jù)接口將數(shù)據(jù)從Host搬移到分段存儲器RAM,然后又DMA客戶端將數(shù)據(jù)從分段存儲器發(fā)送到MAC控制器。上述數(shù)據(jù)操作流程相當復雜,如果采用狀態(tài)機控制,將會浪費部分數(shù)據(jù)通路的帶寬,這樣數(shù)據(jù)很難達到高性能。高性能NIC往往采用流水線設計,而剛玉NIC中基于操作表和操作指針的設計非常適合網(wǎng)絡流水線的處理,因此我們沿用了這個設計思路并將其擴展到部分數(shù)據(jù)控制通路上去,后續(xù)小節(jié)將會詳細介紹采用操作表和操作指針的流水線設計思路。
在接收方向上,傳入的數(shù)據(jù)包通過流哈希模塊確定目標接收隊列,并為接收引擎生成命令,該命令協(xié)調(diào)對接收數(shù)據(jù)路徑的操作。由于同一接口模塊中的所有端口共享同一組接收隊列,因此不同端口上的傳入流將合并到同一組隊列中。接收方向的數(shù)據(jù)的流程不在贅述。
基于流水線的隊列管理
實際上,NIC中為了提高數(shù)據(jù)帶寬利用率,幾乎所有的模塊都采用了流水線處理方式來促進高并發(fā)。本節(jié)以隊列管理模塊來介紹基于操作表和操作指針的流水線設計思路。
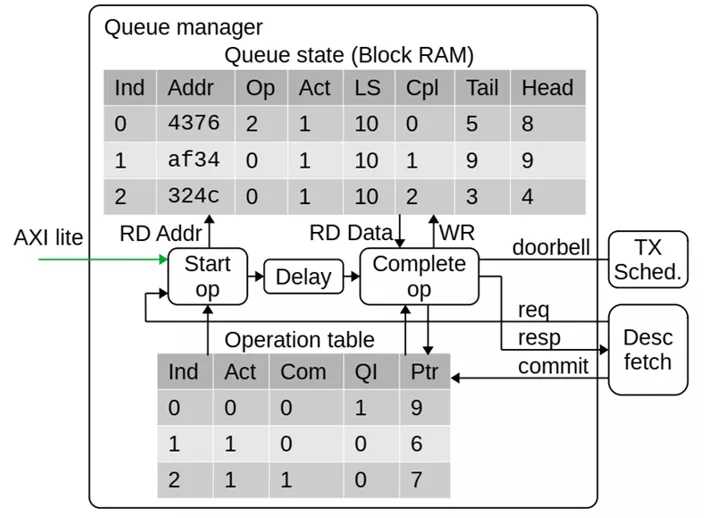
Corundum NIC的隊列管理邏輯必須能夠有效地存儲和管理數(shù)千個隊列的狀態(tài)。為了支持高吞吐量,NIC必須能夠并行處理多個描述符。因此,隊列管理邏輯必須跟蹤多個正在進行的操作,并在操作完成時向驅(qū)動程序報告更新的隊列指針。NIC的操作表項包含激活和提交標志、所屬隊列號、和影子指針,操作指針包括操作表開始指針和操作表提交指針,通過不同的指針對操作表不同字段的索引就可以跟蹤當前進行中的不同操作項目進展到哪一個步驟,從而可以觸發(fā)流水操作。更詳細的來說,當隊列管理接收到出隊請求時將命令放置到Pipeline同時觸發(fā)隊列消息,當命令到達處理周期時,對應隊列的信息已經(jīng)被索引到,此時可以進行處理,如果出隊被允許,必要的信息會被記錄到操作表,處理邏輯只需要不斷寫入操作表并更新操作指針,可以認為出隊邏輯在處理操作表的表頭,操作被提交時會觸發(fā)提交邏輯,提交邏輯處理操作表末并合理的釋放操作表。需要注意的是,操作表只跟蹤正在進行中的處理進程,因此不需要設置太大。它和隊列管理的信息RAM構(gòu)成了一個雙向鏈表,即隊列信息中需要存入為該隊列服務的最新的操作表項索引,用于維護正確的影子指針。
分段存儲器
為了實現(xiàn)高性能,Corundum在內(nèi)部使用了自定義分段存儲器接口,該思想與CPU中的剩余緩存技術設計思路類似但又不完全一致。該接口被分成最大128位的段,并且整體寬度是PCIe硬IP內(nèi)核的AXI流接口的兩倍。例如,將PCIe Gen 3 x16與PCIe硬核中的512位AXI流接口一起使用的設計將使用1024位分段接口,該接口分成8個段,每個128位。與使用單個AXI接口相比,該接口提供了改進的“阻抗匹配”,通過消除背壓和對準問題來提高PCIe鏈路利用率。通過設置基地址和偏移量,分段存儲器可以在每次訪問時保證100%的數(shù)據(jù)帶寬。
基于Xilinx Alevo U50和VCU118 板卡的測試
Xilinx Alevo U50卡采用賽靈思 UltraScale+? 架構(gòu),率先使用半高半長的外形尺寸和 低于75 瓦的低包絡功耗。該卡支持高帶寬存儲器 (HBM2),每秒 100G 網(wǎng)絡連接,面向任意類型的服務器部署。而VCU118則包含了兩個100Gbps光模塊,支持PCIe Gen3 X16,最大128Gbps帶寬,兩塊板卡均可以滿足我們的測試需求。

我們在測試過程中選用了兩臺主流性能機器,它們采用分別Intel 8700K和4770K,配置單如下:

兩臺機器使用光纖連接,U50直接插在主機的PCIe插槽上,VCU118通過擴展的PCIe延長線插到主機的PCIe插槽上,實物圖如下:

Alveo U50由于采用半高設計,可以直接插入到服務器或者普通主機機箱內(nèi),VCU118則需要PCIe電纜進行連接。

板卡安裝就緒后,燒寫B(tài)it文件,并重新啟動系統(tǒng),裝載Linux驅(qū)動,此時可以使用Linux系統(tǒng)的網(wǎng)絡工具進行查看,在本次測試中,設置U50板卡的IP地址為192.168.0.128,VCU118板卡的IP為192.168.0.129。而后進行網(wǎng)絡測試,發(fā)現(xiàn)可以正常Ping通,網(wǎng)絡延時在2ms左右。(視頻請點擊公眾號查看)
為了測試TCP連接,我們安裝了FTP傳輸工具用于在兩臺機器之間傳輸文件。受限于FTP軟件是雙線程,并且我們使用的機器采用機械硬盤,傳輸?shù)乃俾什⒉焕硐耄强梢宰C明TCP鏈接是沒有問題的。(視頻請點擊公眾號查看)
為了測試到高性能NIC的極限性能,我們使用C語言創(chuàng)建UDPSocket鏈接,并不斷發(fā)送1400字節(jié)幀長數(shù)據(jù)。

UDP Socket極限發(fā)包速率
在單線程下,使用BSD Socket可以達到將近10Gbps的速率,在多線程使用時受限于CPU瓶頸,我們的最高測試速率達到了35Gbps,此時可以發(fā)現(xiàn)CPU性能已經(jīng)接近滿負載,即使增加更多的線程,網(wǎng)絡處理速率也不會增大,非常遺憾的是更高的性能需要在服務器級別的主機上才能進一步測試。(視頻請點擊公眾號查看)
也有網(wǎng)友在服務器上實現(xiàn)并分享了自己的測試結(jié)果:
用戶態(tài)協(xié)議棧和用戶套接字簡介
用戶態(tài)協(xié)議棧旨在替換Linux內(nèi)核自帶的協(xié)議棧,并提供零拷貝DMA技術。網(wǎng)絡協(xié)議棧一般作為操作系統(tǒng)的組件,運行在內(nèi)核態(tài)中,用戶調(diào)用套接字來調(diào)用協(xié)議棧進程,此時會涉及用戶態(tài)和內(nèi)核態(tài)的上下文切換。Linux協(xié)議棧為了通用性考慮,本身性能并不高。
從概念上講:Linux協(xié)議棧分為三層,VFS層為應用程序提供套接字API;傳統(tǒng)的TCP/IP層提供I/O復用、擁塞控制、丟包恢復、路由和服務質(zhì)量保證;網(wǎng)卡層與網(wǎng)卡硬件完成數(shù)據(jù)收發(fā)。VFS層貢獻了網(wǎng)絡協(xié)議中極大一部分開銷。內(nèi)核穿越和套接字描述符鎖為每次操作帶來了開銷,傳輸協(xié)議在TCP/IP處理上消耗CPU,其他諸如中斷、進程切換、I/O復用也在消耗CPU;此外,BSD Socket中的send和recv語義會導致協(xié)議棧和應用之前的數(shù)據(jù)復制。
為了解決上述問題,目前有多款開源的用戶態(tài)協(xié)議棧被提出。其中包括Intel針對高速大并發(fā)網(wǎng)絡提出的數(shù)據(jù)平面開發(fā)套件DPDK。Intel-DPDK提供了一套可從linux用戶態(tài)空間使用的API來替代傳統(tǒng)的LINUX系統(tǒng)調(diào)用,數(shù)據(jù)將不再跨越Linux內(nèi)核,而是直接通過Intel-DPDK路徑。注意到,DPDK本身并不具備協(xié)議棧功能,而是為用戶提供一套開發(fā)套件。目前,已經(jīng)存在諸如MTCP等基于DPDK的開源用戶協(xié)議棧。
DPDK存在以下優(yōu)勢:
1)輪詢:在包處理時避免中斷上下文切換的開銷,對于高速大突發(fā)數(shù)據(jù)量的網(wǎng)絡中心,隨時都有數(shù)據(jù)到達。
2)用戶態(tài)驅(qū)動:通過UIO技術將報文拷貝到應用空間處理,規(guī)避不必要的內(nèi)存拷貝和系統(tǒng)調(diào)用,便于快速迭代優(yōu)化。
3)親和性與獨占:傳統(tǒng)內(nèi)核運行時,調(diào)度器采用負載均衡機制,一個進程會在多個CPU核心上切換,造成額外開銷,而DPDK特定任務可以被指定只在某個核上工作,避免線程在不同核間頻繁切換,保證更多的cache命中。
4)降低訪存開銷:Linux默認采用4KB分頁管理機制,然而在大量使用內(nèi)存時,將嚴重制約程序的運行性能。Linux2.6后開始支持HUGEPAGE,利用內(nèi)存大頁HUGEPAGE可以降低TLB miss,利用內(nèi)存多通道交錯訪問提高內(nèi)存訪問有效帶寬。
5)軟件調(diào)優(yōu):cache行對齊,預取數(shù)據(jù),多元數(shù)據(jù)批量操作。
6)無鎖隊列:DPDK 提供了一種低開銷的無鎖隊列機制 Ring,Ring 既支持單生產(chǎn)者單消費者,也支持多生產(chǎn)者多消費者。內(nèi)部實現(xiàn)沒有使用鎖,大大節(jié)省了使用開銷。
7)使用rte_mbuf結(jié)構(gòu)體來代替?zhèn)鹘y(tǒng)的sk_buff結(jié)構(gòu)體,可以節(jié)省一次內(nèi)存開銷。

后續(xù)的工作和發(fā)展方向
通過測試表明,高性能NIC依然存在一些問題,如在接收方向上沒有進行描述符預讀取機制,這將會大大提高接收延遲;沒有加入對虛擬化的支持,由于網(wǎng)絡中心主要面向多用戶服務,因此大多云都需要加入對SRIO-V等虛擬化功能的支持;沒有采用大容量DDR或者更高性能的HBM緩存,這將導致其防抖動性能較差;沒有軟件協(xié)議棧與其配合工作,軟硬件協(xié)同設計優(yōu)化趨勢是大勢所趨,在網(wǎng)絡中心上也是如此,高性能NIC需要采用用戶態(tài)協(xié)議棧來進行優(yōu)化才能更好的發(fā)揮其性能;另外,硬件協(xié)議棧分段卸載也是未來發(fā)展的方向,未來的高性能NIC勢必也要具備這個功能。
后記
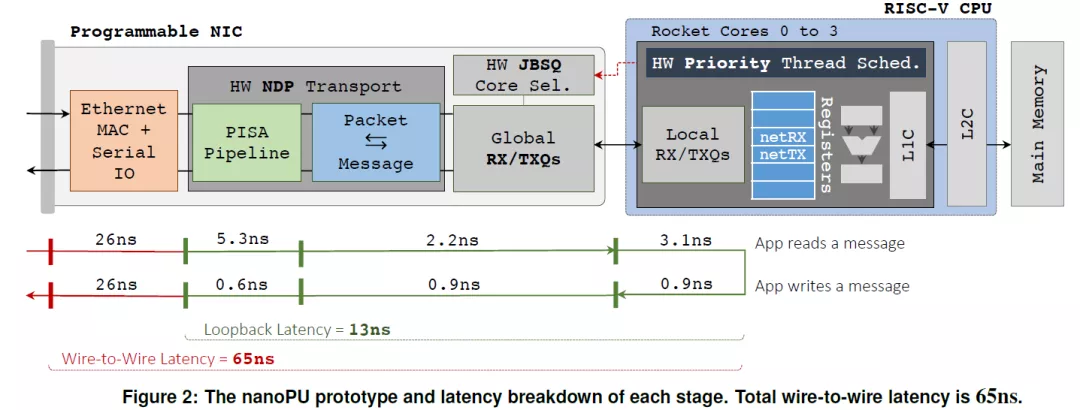
業(yè)界和學術界也在為提高Smart NIC性能在不懈的努力。如最近斯坦福大學著名的Nick教授團隊提出的NanoPU(文章題目:The nanoPU: Redesigning the CPU-Network Interface to Minimize RPC Tail Latency,2020年),100G光口經(jīng)過協(xié)議無關Match-Aciton多級流表等內(nèi)部處理邏輯再到內(nèi)部嵌入式RISC-V處理器的回環(huán)時延僅有65ns。
另外,在100G開源 Corundum 可編程NIC的基礎上的對該開源IP核進行改進的文章也已經(jīng)出來了,而且,最可貴的是這篇改進的文章PANIC也是開源的(OSDI 2020:https://www.usenix.org/conference/osdi20/presentation/lin)。文章針對目前所有的SmartNIC都不擅長同時運行多個租戶的卸載問題進行了研究并提出了切實可行的解決方案。相關研究工作后續(xù)本公眾號會持續(xù)跟進。

- 谷景科普功率電感和普通電感的區(qū)別
- 淺談100G OTN運維技術
- Alveo U50數(shù)據(jù)中心加速器卡數(shù)據(jù)手冊
- Alveo U50數(shù)據(jù)中心加速器卡安裝指南
- Alveo U50數(shù)據(jù)中心加速卡數(shù)據(jù)表
- 消防電梯的特點優(yōu)勢及和普通電梯的區(qū)別 1次下載
- 如何使用FPGA實現(xiàn)100G光傳送網(wǎng)的設計 12次下載
- 100G光模塊測試系統(tǒng)的詳細資料說明 38次下載
- 宏基電腦ACER471G-U6的資料文件免費下載 15次下載
- 基于反向復用技術的 100G 光傳輸系統(tǒng) 10次下載
- 100G和400G以太網(wǎng)及數(shù)據(jù)通信技術 18次下載
- 最全的ARM嵌入式視頻教程100G 0次下載
- 100G光模塊應用 155次下載
- 基于超高精度色散管理的100G DWDM傳輸系統(tǒng)
- acer TravelMate C100系列 lan網(wǎng)卡驅(qū)動
- 工控機與普通電腦的區(qū)別 645次閱讀
- 100G交換芯片和2.5G交換芯片介紹 839次閱讀
- 服務器cpu和普通電腦cpu的區(qū)別 5435次閱讀
- 100G以太網(wǎng)光口的FPGA測試實例 2156次閱讀
- 基于StratixIVGT FPGA實現(xiàn)100G系統(tǒng)的設計方案 1880次閱讀
- OTM2620便攜式100G測試儀的功能特點及應用范圍 1711次閱讀
- 100G QSFP28有源光纜特征及應用 1935次閱讀
- 介紹40G/100G產(chǎn)品測量的新特點及測試方法 2653次閱讀
- Xilinx Alveo U200數(shù)據(jù)中心加速器卡的主要性能和優(yōu)勢 6080次閱讀
- 100G QSFP28 SR4光模塊的封裝、特點和參數(shù)詳細介紹 2.1w次閱讀
- 普通電腦能挖萊特幣嗎_普通電腦挖萊特幣教程 2.9w次閱讀
- 對于光纖來說100G和400G系統(tǒng)要求有何不同 5648次閱讀
- 解析100G傳輸技術與組網(wǎng)應用 5076次閱讀
- 40G/100G相干光通信原理與關鍵技術 1.4w次閱讀
- 解析100G傳輸方案及應用 3472次閱讀

 上傳資料賺積分
上傳資料賺積分下載排行
本周
- 1電子電路原理第七版PDF電子教材免費下載
- 0.00 MB | 1491次下載 | 免費
- 2單片機典型實例介紹
- 18.19 MB | 95次下載 | 1 積分
- 3S7-200PLC編程實例詳細資料
- 1.17 MB | 27次下載 | 1 積分
- 4筆記本電腦主板的元件識別和講解說明
- 4.28 MB | 18次下載 | 4 積分
- 5開關電源原理及各功能電路詳解
- 0.38 MB | 11次下載 | 免費
- 6100W短波放大電路圖
- 0.05 MB | 4次下載 | 3 積分
- 7基于單片機和 SG3525的程控開關電源設計
- 0.23 MB | 4次下載 | 免費
- 8基于AT89C2051/4051單片機編程器的實驗
- 0.11 MB | 4次下載 | 免費
本月
- 1OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234313次下載 | 免費
- 2PADS 9.0 2009最新版 -下載
- 0.00 MB | 66304次下載 | 免費
- 3protel99下載protel99軟件下載(中文版)
- 0.00 MB | 51209次下載 | 免費
- 4LabView 8.0 專業(yè)版下載 (3CD完整版)
- 0.00 MB | 51043次下載 | 免費
- 5555集成電路應用800例(新編版)
- 0.00 MB | 33562次下載 | 免費
- 6接口電路圖大全
- 未知 | 30320次下載 | 免費
- 7Multisim 10下載Multisim 10 中文版
- 0.00 MB | 28588次下載 | 免費
- 8開關電源設計實例指南
- 未知 | 21539次下載 | 免費
總榜
- 1matlab軟件下載入口
- 未知 | 935053次下載 | 免費
- 2protel99se軟件下載(可英文版轉(zhuǎn)中文版)
- 78.1 MB | 537793次下載 | 免費
- 3MATLAB 7.1 下載 (含軟件介紹)
- 未知 | 420026次下載 | 免費
- 4OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234313次下載 | 免費
- 5Altium DXP2002下載入口
- 未知 | 233046次下載 | 免費
- 6電路仿真軟件multisim 10.0免費下載
- 340992 | 191183次下載 | 免費
- 7十天學會AVR單片機與C語言視頻教程 下載
- 158M | 183277次下載 | 免費
- 8proe5.0野火版下載(中文版免費下載)
- 未知 | 138039次下載 | 免費





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論