 電子發燒友App
電子發燒友App











 創作
創作 發文章
發文章 發帖
發帖  提問
提問  發資料
發資料 發視頻
發視頻資料介紹
作者:Gerry Raptis
在現代渲染環境中,很多情況下在一個數據幀期間會產生計算負荷。在GPU上計算通常(非固定功能)是并行編程的,通常用于具有挑戰性,完全不可能或僅通過標準圖形管道(頂點/幾何/細化/柵格/碎片)實現的效率低下的技術。一般情況下,計算在實現技術方面提供了幾乎絕對的靈活性。但是這種普遍性帶來了其他挑戰:在同步渲染任務方面,GPU可以做出的假設要少得多,尤其是在我們嘗試優化GPU并使負載飽和的情況下。
無需過多的討論,保持GPU的占用率至關重要。實際上,這是最重要的性能因素。如果GPU沒有做任何事情,或者沒有被充分利用,而我們的幀速率目標尚未實現,那么嘗試對應用程序進行微優化實際上是毫無意義的。
另一方面,當達到我們的最大幀速率指標時,這種情況會逆轉:如果我們已經在分配的最小幀時間內渲染了我們需要渲染的所有內容——換句話說是顯示了我們需要的盡可能多的數據幀——我們應該允許GPU處于空閑狀態,從而減少功耗并釋放更少的熱量。但是這不是沒有正確同步的借口,如果同步不正確將不會很好的吸收小的負載峰值并可能導致不必要的FPS波動。
要在Vulkan中進行同步,從概念上講我們需要清楚不同操作之間的依賴關系。Vulkan在這方面非常靈活且功能強大。但是這種靈活性可以說是一把雙刃劍,隨著同步變得復雜和冗長,該任務可能會變得艱巨并且要推理出最佳路徑也不是一個簡單的任務。用于同步的工具有barriers、Events、Semaphore (信號量)和Fences(柵欄),每個都在不同情況下強制執行操作順序。最常見且最輕量級的是barrier,它僅在GPU本身之前和之后強制執行指定類型的命令。
本質上,barrier通常是用來搞清楚源程序和目標程序的依賴關系。具體可描述為:“對于到目前為止已記錄的所有圖形命令,確保至少已執行其片段步驟,在開始執行頂點步驟之前記錄此點后續的圖形命令數。
例如,一個通道的彩色附件(color attachment)被用于另一個通道的輸入附件(input attachment)(不考慮subpass dependencies的特殊情況)。
然后將包含此barrier的渲染命令緩沖區提交到隊列中,它將對該隊列中的所有命令生效(對后文的提示)。如果我們需要在不同的隊列中使用這種效果,正確的原語是一個semaphore(信號量)。如果需要同步以等待CPU的事件,則可以使用fence或event(事件)。如果我們想在CPU/GPU之間進行任意的同步則可以使用event(事件)。
在我們特定的案例中,barrier的作用如下:
“對于到目前為止已記錄的所有計算命令確保他們執行完成,在開始頂點步驟之前記錄后續的圖形命令數量。”我們將其稱為計算——圖形barrier。
首要的事情:工具選擇
在PowerVR平臺上進行任何性能調整時,你最好的朋友是PVRTune。PVRTune是我們的GPU分析應用程序,可提供絕對全面的信息。這包括在GPU上實時執行的所有任務,大量硬件計數器,負載等級,處理速率等。我們不能對此施加太大壓力——PVRTune應該始終是在設備上對應用程序進行性能分析的第一站和最后一站。它支持所有PowerVR平臺,因此請確保下載PVRTune和所有其他免費的PowerVR工具。
下載地址:https://www.imgtec.com/developers/powervr-sdk-tools/
關于圖表的注釋
對于本文中下面的所有示例,為了簡單起見我們將忽略tiler任務(在圖表中標記為TN)。
Tiler在這里指的是與頂點(Vertex)任務相同的處理階段,這兩個術語可以互換使用。
渲染器(Renderer)指的是相同的處理階段碎片/像素任務,這些術語可以互換使用。
總的來說,我們在本文中所指的內容可以擴展到“頂點任務”,但是頂點任務通常更容易處理,因為它們傾向于自然的重疊中間幀計算任務,這是此處討論的最困難的情況,通常與片段階段有依賴性。
但是如果你具有計算(compute)->vertex(甚至是vertex->compute)的barrier,則頂點任務可能會發生具有完全相同解決方案的類似情況。
關于多緩沖(multi-buffering)的說明
在臺式機上雙倍緩沖(double-buffering,在交換鏈中使用兩個幀緩沖圖像)似乎是目前的標準。
但是雙緩沖(double-buffering)實際上不允許你在移動設備上重疊來自不同幀的操作。PowerVR是基于分塊延遲渲染(TBDR)的體系結構,可以充分利用并行處理多個幀的功能。根據Vulkan規范,如果不夠詳細,通常就無法渲染在當前屏幕上呈現的幀緩沖區圖像。這意味著在任何的時間點GPU都只能主動渲染“空閑狀態”的圖像(后臺緩沖區)。
因此強烈建議使用三個幀緩沖圖像創建交換鏈,特別是在啟用垂直同步(Vsync)的情況下(或在Android平臺上強制啟用)。這種技術通常被稱為三重緩沖,并且可以提供比雙緩沖更高的性能。
與雙緩沖相比三重緩沖的缺點是它引入了額外的幀延遲,在某些延遲敏感的情況下(如臺式機上高FPS的競爭類游戲)這可能是不允許的,但在移動設備上很少出現此問題。
但是本文不是關于多緩沖的文章,因此我們將不做進一步的詳細說明,僅說明本文假設你正在使用三個幀緩沖圖像來利用這種并行性即可。如果你使用的是PowerVR SDK和其他可能的解決方案則默認為是三重緩沖模式。
瑣碎情況
對于計算和圖形負載而言,一個瑣碎(但不常見)的案例在并行處理方面可能是令人尷尬的:彼此完全獨立并且可以完全并行執行。如果我們在每一幀中都有一些無關的任務,例如為兩個彼此不交互的屏幕渲染兩個不同的工作負載就會發生這種情況。在這些之間通常不需要發生任何barrier(或其他同步原語),因此GPU可以并行的調度它們。
在API方面調用如下所示:
計算調度->繪制->展示
在PVRTune中計算和圖形任務可能如下所示:
(數字表示不同框架中的任務)
————————
計算負載:B0 B1 B2 B3....
圖形負載:A0 A1 A2 A3....
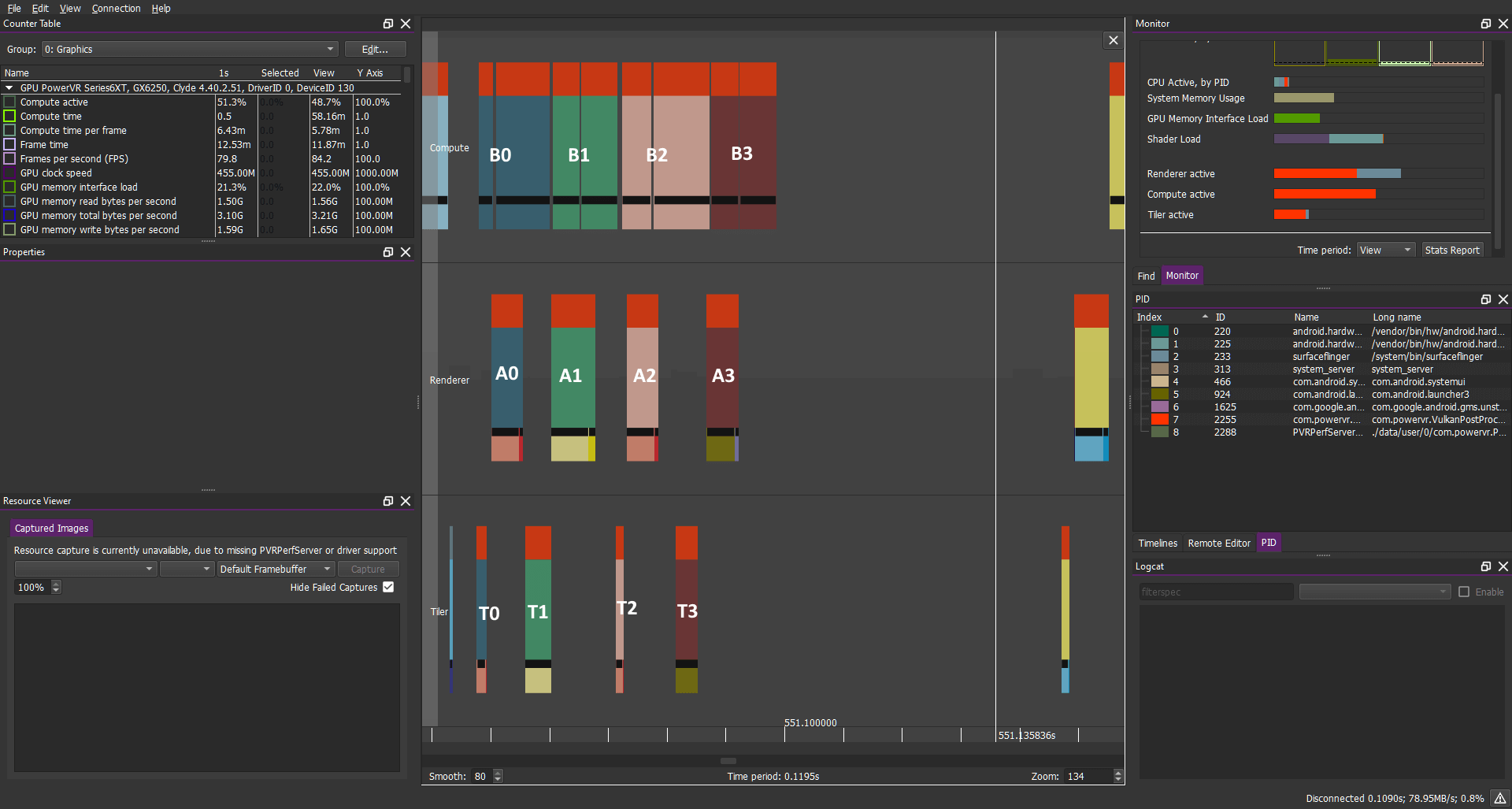
這可以帶來巨大的好處:通過更多的任務來安排進出時間,GPU可以隱藏延遲并提供良好的性能優勢,而不是一個接一個的執行這些任務。但是這種“令人尷尬的并行操作”的情況在這里并不會特別令人感興趣,也不是那么的普遍。但是它強調了一個有用但并不總是顯而易見的原則:僅同步所需的內容。
簡單情況
這種情況不常見,我們對此并不感興趣。更常見的是需要圖形工作負載之前發生的計算工作負載。這可能是某種頂點處理,計算剔除,幾何圖形生成或圖像幀中要求的其他操作。通常頂點著色器需要這些數據,在這種情況下我們將需要在vkCmdDispatchCompute和vkCmdDrawXXX之間插入vkCmdPipelineBarrier,以實現這種事前發生的關系。
調用流程看起來如下所示:
計算調度-->Barrier(源:計算,目標:圖形/頂點)->繪制->展示
或者可能正好相反,例如執行一些計算后處理任務。但是這意味著直接通過計算(compute)寫入緩沖區,這通常不是理想的情況:片段流水線為寫入幀緩沖區進行了優化,具有幀緩沖區壓縮等諸多優點。
繪制->Barrier(源:圖形/片段,目標:計算)->計算調度->展示
可能會錯誤的期望會發生這樣的事情,實際上如果我們只對緩沖區進行雙緩沖或進行某種形式的過度同步操作,我們可能最終會失敗。
如果我們使用雙緩沖而不是三重緩沖則需要等待Vsync才能繼續渲染,因此可能會丟失很多并行操作
————————
計算負載:B0 B1 B2 B3 B4...
圖形負載:A0 A1 A2 A3 A4...
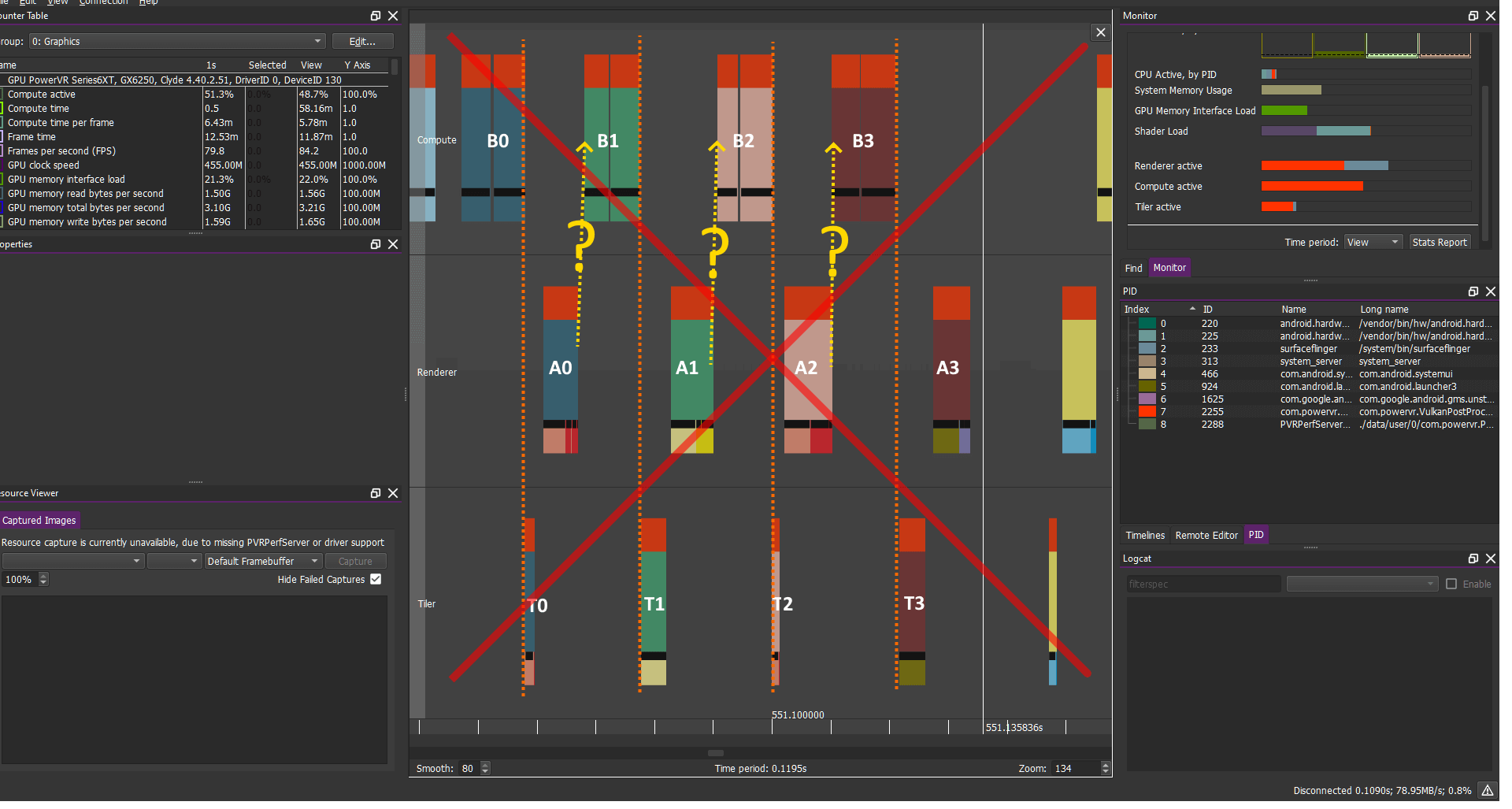
注:此圖只是理論上的,假設滿足以下條件:
- 我們正在使用三重緩沖
- 未啟用Vsync或我們尚未達到硬件平臺的最大FPS
如果我們正確同步并以最大Vsync fps(通常為60fps)進行同步,則這種情況變得完全有效:如果沒有足夠的負載要執行,GPU將更加省力甚至處于空閑狀態,從而節省功耗,并且任務會像這樣自然的序列化執行。在這些情況下這是有效且可取的。此處的轉折點是對于低于最大FPS運行的應用程序不應該發生這種情況。
在這種情況下我們期望的重疊要好得多,如果我們使用三重緩沖并且不過度同步通常會發生什么。GPU應該能夠通過下一幀(N+1)的計算操作來調度這一幀(N),因為通常不會存在Barrier來阻止這種情況的發生。如前文所述我們需要這種并行性來實現最佳性能。
————————
計算負載:B0 B1 B2 B3...
圖形負載:A0 A1 A2 A3....
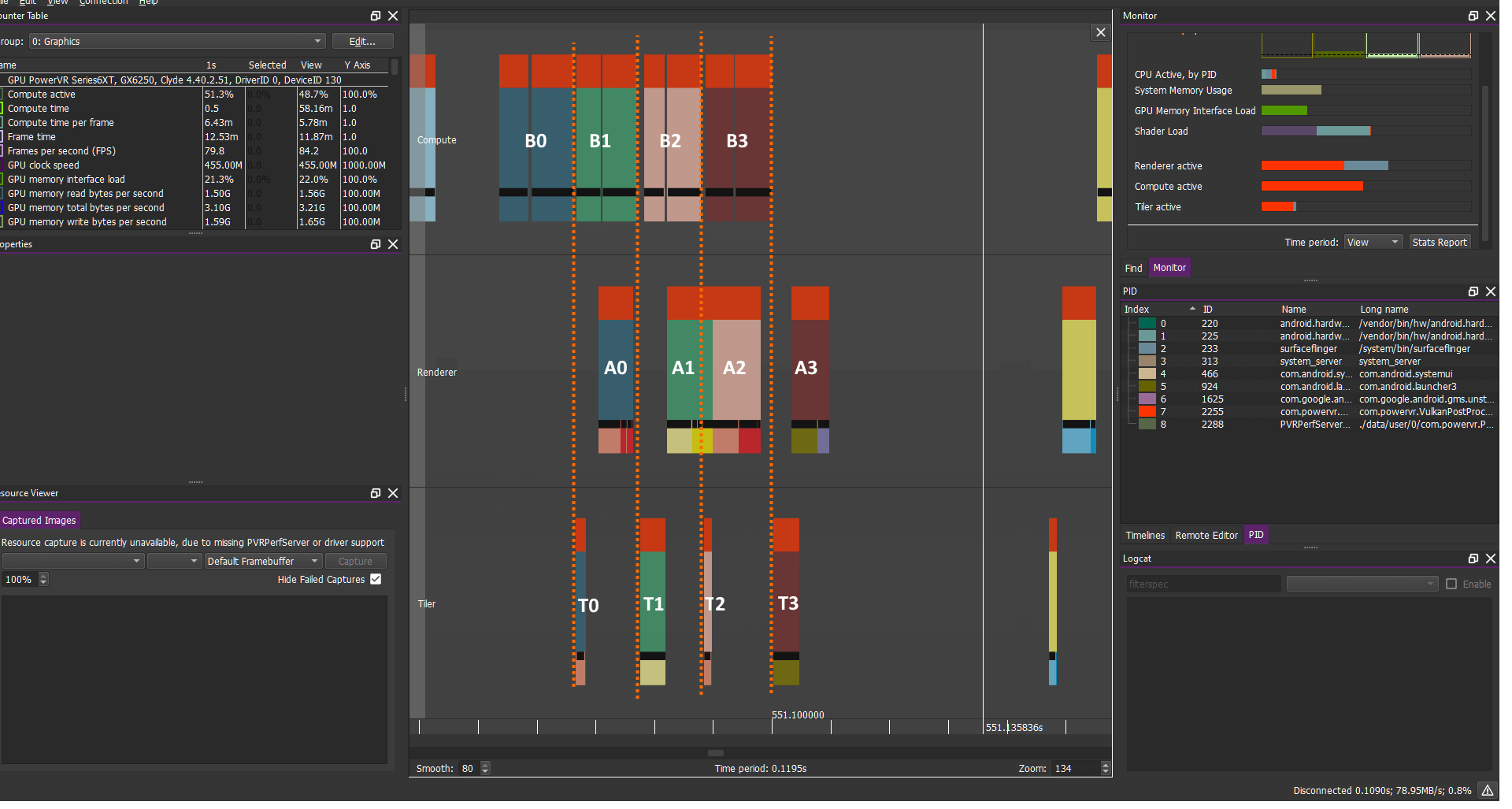
在繪制對象之前我們需要準備好它們,不過在很多情況下我們不需要前一幀的渲染即可渲染后一幀,因此在這種情況下GPU可以自由的允許BN+1/AN 重疊并很好的進行封裝以提高性能。
更加復雜難纏的情況
像往常一樣事情并非如此簡單,當你轉向高級多通道流水線時,我們的渲染操作往往比這復雜得多。即使正確的對操作進行了排序也很可能會在圖形操作之間插入一個計算調度的操作而使整個任務中斷,例如在使用片段著色器對屏幕畫面進行進一步的后處理和UI合成之前,我們可能會在幀的中間插入計算操作來計算一些優化的Blur值。
鳥瞰圖繪制過程的簡單版本如下所示:
繪制->Barrier(源:圖形/片段,目標:計算)->計算調度->Barrier(源:計算,目標:圖形/頂點)->繪制->展示
這些情況可能會很成問題,原因很快就會顯現出來。
在這種情況下單個幀的任務操作如下所示:
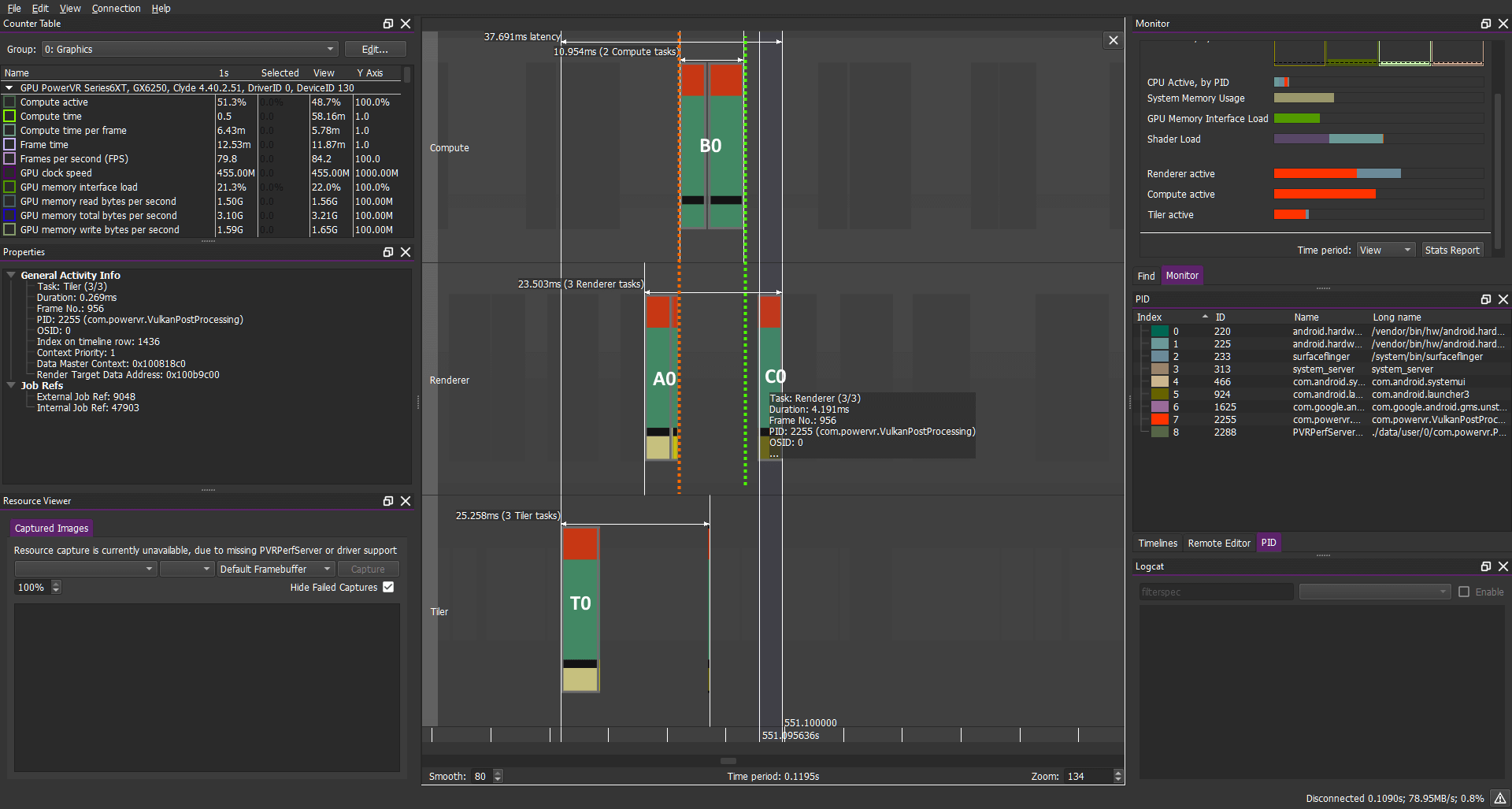
在前面的示例中你應該希望此時A1應該在A0和C0之間并與B0重疊
不幸的是如果“正確的”與上述Barrier進行基本同步,那將不是你所能獲取的,你得到的信息如下:
計算負載:B1 B2 B3 B4 B5
圖形負載:A1 C1 A2 C2 A3 C3 A4 C4 A5 C5...

因此我們看到一幀最開始的片段任務實際上在整個前一幀之后被完全替換。
但這是為什么呢?
看看上面的工作負載以及Barrier,答案變得相當明顯:
A和B之間的(橙色標識部分)Barrier可以用英文解讀為:“無計算任務,在安排好AN 之后進行調度,然后在AN 完成執行之前開始執行”,嗯...這看起來很合理。
B和C之間的(綠色部分)Barrier顯示為:“無圖形任務,在安排好BN之后進行調度,在BN完成執行之前允許開始執行”,這個Barrier也很有意義,因為我們需要CN在BN完成后才能啟動。
但是我們還希望盡快調度AN+1(也就是圖形任務),最好在CN啟動后立即開始。但是BN/CN之間的Barrier不允許這樣做導致一些級聯:AN+1在BN之后被置換但是由于CN已經被調度,它甚至進一步置換了AN+1(不同的像素任務不能彼此重疊)從而導致所有任務的完整序列化。
簡而言之計算/圖形Barrier不允許下一幀的早期圖形任務與計算任務同時執行(綠色箭頭)
這是壞消息,在這種情況下USC(統一陰影集群,所有數學和計算都在其中發生,是PowerVR GPU的核心)極有可能未被充分利用,并且在這些任務之間的通信至少必須有一定的開銷。可計劃的任務負載越少,好的利用機會就越少。此外計算和圖形任務的組成通常不同,其中一項是受內存和紋理限制,另一項是ALU/數學限制,并且非常適合同時調度。此外如果所有任務都是串行的,則通常也可能在它們之間引入微小的間隔(管道間隙),最后v-sync將進一步加劇該問題,所有這些因素加起來會導致巨大的性能差異,我們已經看到了這一方面的很多差異,雖然你遇到的可能會有所不同,但20%左右的概率并不常見。通過更好的重疊設計潛在的提升可達5%,而在實際應用中我們的性能提升高達30%。
綜上所述:我們希望能夠將下一幀(AN+1)開始的圖形操作放在第N幀(CN)的后面進行調度以便它們與當前幀(BN)的計算能夠并行執行以實現更好的GPU利用率。
這是你在Vulkan中處理同步問題時可能遇到的想法,潛在的解決方案我們將在后續的文章中進行檢驗。
相關主題的后續文章將很快發布,敬請關注!
英文鏈接:https://www.imgtec.com/blog/vulkan-synchronisation-and-graphics-compute-...
來源:電子創新網
- 基于FPGA和DSP的機載圖形顯示系統 36次下載
- 如何使用FPGA實現飛機座艙圖形顯示加速系統的設計 5次下載
- Vulkan同步機制和圖形-計算-圖形轉換的風險(二)
- Microchip圖形庫與鍵盤的配合使用 0次下載
- 混合式數據同步機制 0次下載
- 一種采用Lock_Free同步機制的數據結構的研究 0次下載
- MFC編程基礎-圖形學 0次下載
- MFC圖形界面編程入門教程 0次下載
- 計算機圖形學講義 0次下載
- 用于無線網絡MMORPG的同步機制 13次下載
- 域一致性新型鎖同步機制的實現
- 多線程同步機制在應用程序與驅動程序通信中的應用
- 基于企業流程的需求分析方法的圖形描述機制
- 圖形處理器的流執行模型
- 圖形的數學處理--基點計算,節點計算,輔助計算
- 計算機圖形學:探索虛擬世界的構建之道 264次閱讀
- 圖形渲染的技術和原理:探索視覺效果的奇妙世界 683次閱讀
- 從圖形到通用計算:GPGPU技術的進化之路 880次閱讀
- 30個MATLAB圖形繪制 1439次閱讀
- 淺談Linux kernel中的同步機制 747次閱讀
- 在計算機圖形學中GPGPU需要用到的OpenGL概念 811次閱讀
- 數字/同步機轉換器的設計方案 2028次閱讀
- 基于有限狀態機的FlexRay時鐘同步機制 3295次閱讀
- 可變電阻器的圖形符號 2.3w次閱讀
- PCB圖形轉移關鍵工藝過程分析 5551次閱讀
- 計算機圖形學年鑒:研究現狀、應用和未來 1081次閱讀
- 常用電氣電路的圖形符號 5w次閱讀
- 計算機圖形學總覽:圖像和圖像的概念辨析 6457次閱讀
- 清華AMiner團隊發布計算機圖形學研究報告 3002次閱讀
- 基于FPGA圖形和字符加速的液晶顯示設計 2522次閱讀

 上傳資料賺積分
上傳資料賺積分下載排行
本周
- 1電子電路原理第七版PDF電子教材免費下載
- 0.00 MB | 1491次下載 | 免費
- 2單片機典型實例介紹
- 18.19 MB | 95次下載 | 1 積分
- 3S7-200PLC編程實例詳細資料
- 1.17 MB | 27次下載 | 1 積分
- 4筆記本電腦主板的元件識別和講解說明
- 4.28 MB | 18次下載 | 4 積分
- 5開關電源原理及各功能電路詳解
- 0.38 MB | 11次下載 | 免費
- 6100W短波放大電路圖
- 0.05 MB | 4次下載 | 3 積分
- 7基于單片機和 SG3525的程控開關電源設計
- 0.23 MB | 4次下載 | 免費
- 8基于AT89C2051/4051單片機編程器的實驗
- 0.11 MB | 4次下載 | 免費
本月
- 1OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234313次下載 | 免費
- 2PADS 9.0 2009最新版 -下載
- 0.00 MB | 66304次下載 | 免費
- 3protel99下載protel99軟件下載(中文版)
- 0.00 MB | 51209次下載 | 免費
- 4LabView 8.0 專業版下載 (3CD完整版)
- 0.00 MB | 51043次下載 | 免費
- 5555集成電路應用800例(新編版)
- 0.00 MB | 33562次下載 | 免費
- 6接口電路圖大全
- 未知 | 30320次下載 | 免費
- 7Multisim 10下載Multisim 10 中文版
- 0.00 MB | 28588次下載 | 免費
- 8開關電源設計實例指南
- 未知 | 21539次下載 | 免費
總榜
- 1matlab軟件下載入口
- 未知 | 935053次下載 | 免費
- 2protel99se軟件下載(可英文版轉中文版)
- 78.1 MB | 537793次下載 | 免費
- 3MATLAB 7.1 下載 (含軟件介紹)
- 未知 | 420026次下載 | 免費
- 4OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234313次下載 | 免費
- 5Altium DXP2002下載入口
- 未知 | 233046次下載 | 免費
- 6電路仿真軟件multisim 10.0免費下載
- 340992 | 191183次下載 | 免費
- 7十天學會AVR單片機與C語言視頻教程 下載
- 158M | 183277次下載 | 免費
- 8proe5.0野火版下載(中文版免費下載)
- 未知 | 138039次下載 | 免費





 工商網監
工商網監
評論