 電子發燒友App
電子發燒友App











 創作
創作 發文章
發文章 發帖
發帖  提問
提問  發資料
發資料 發視頻
發視頻資料介紹
描述
TinyML是一項尖端技術,它通過支持創建可在微控制器等小型設備上運行的超緊湊、低功耗機器學習模型,徹底改變了機器學習領域。
深度學習最流行的應用之一是音頻分類,涉及對聲音進行分類并預測其各自類別的任務。這類問題有很多實際應用,例如通過對音樂片段進行分類來識別音樂的流派,或者通過對簡短的話語進行分類來根據他們的聲音識別各個說話者。借助生成式 AI 和文本轉語音技術,我們現在可以使用合成數據來訓練這些模型以識別特定模式,例如您的名字。通過使用合成數據,我們可以創建高度真實和多樣化的數據集,這些數據集可用于以更高效和更具成本效益的方式訓練機器學習模型。
該項目旨在演示如何開發可以區分未知、背景噪音和人名類別的音頻分類系統。為實現這一目標,我們將使用Edge Impulse平臺來訓練我們的模型,然后將其部署到邊緣設備,例如 Arduino Nicla Voice。
用于音頻信號處理的機器學習管道
圖中所示的音頻處理管道是使用機器學習技術分析音頻數據的常用方法。通過使用快速傅立葉變換 (FFT) 從音頻數據中提取頻域特征,可以訓練機器學習模型來執行語音識別、音樂分類或音頻分割等任務。

總體而言,此圖說明了使用機器學習處理音頻數據所涉及的基本步驟,包括數據預處理、特征提取、模型訓練和模型推理。
讓我們開始吧!
數據集生成
要根據不同的類別對音頻進行分類,您需要收集一些未知類、背景噪聲類和名稱類的樣本 WAV 文件。這將使系統能夠區分這三個類別。
機器學習模型的數據集生成流程圖,該模型使用Google TensorFlow Speech Command數據集、AudioLDM文本轉音頻生成工具和Piper文本轉語音技術生成未知、背景噪聲和人名類,可以概括如下:
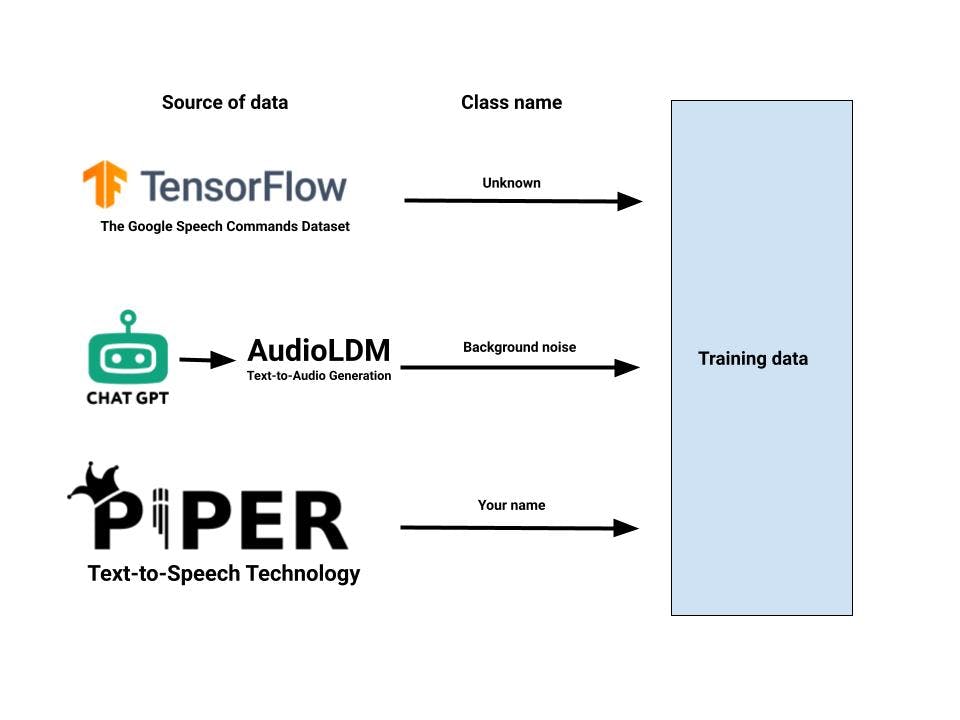
- 下載Google TensorFlow Speech Command 數據集,其中包含大量音頻樣本,以及每個樣本的類標簽,用于標識聲音的類型。這些文件可以作為代表未知類的單獨類添加到數據集中。
- 利用ChatGPT為背景噪音類別生成不同的文本提示。
- 生成文本提示后,我們將它們發送到將文本轉換為音頻的模塊。AudioLDM文本轉音頻生成工具 cat 生成大量音頻文件。這些文件可以作為表示背景噪聲的單獨類添加到數據集中。
- 使用Piper文本轉語音技術生成包含人名的音頻文件。這些文件可以作為一個單獨的類添加到數據集中,代表人名或您要分類的其他詞。
使用 Text to speech 技術生成高質量的語音數據 - Piper
文本轉語音 (TTS) 是一種尖端的語音合成技術,可以將書面文本發聲成具有人聲的可聽語音。TTS 的一個示例是由Michael Hansen開發的Piper,它可用于從文本輸入生成語音數據。
從 Github 存儲庫下載 Piper TTS 的預編譯二進制包。您可以使用 wget 命令通過在終端中運行以下命令來下載程序包:
wget https://github.com/rhasspy/piper/releases/download/v0.0.2/piper_amd64.tar.gz
這將下載適用于 AMD64 架構的 Piper TTS 二進制包。如果您在 Raspberry Pi 或 Nvidia Jetson 等設備上使用不同的架構,例如 ARM64,您應該從piper的 github 存儲庫下載適當的版本。 提取 tar.gz 文件。
下載英文語言模型,在終端中運行以下命令:
wget https://github.com/rhasspy/piper/releases/download/v0.0.2/voice-en-us-ryan-high.tar.gz
提取您下載的語言模型的 tar.gz 文件。您可以使用以下命令進行提取:
tar -zxvf voice-en-us-ryan-high.tar.gz
使用以下代碼片段通過 Piper TTS 生成 WAV 音頻文件。將model_path變量替換為您下載的語言模型的路徑,并將text變量替換為您要轉換為語音的文本。該代碼將在輸出目錄中生成 904 個音頻文件,每個文件都有不同的揚聲器。
import subprocess
text = "Your name"
model_path = "./en-us-libritts-high.onnx"
for i in range(0, 904):
output_file = f'./output/{i}.wav'
cmd = f'echo "{text}" | ./piper/piper --model {model_path} --output_file {output_file} --speaker {i}'
subprocess.run(cmd, shell=True, check=True)
此外,您還可以使用為您準備的 Google Colab 筆記本。該筆記本包含使用Piper TTS生成音頻文件的所有必要步驟和代碼。
您可以通過提供給您的鏈接訪問筆記本。
為了在筆記本上使用 GPU,請選擇運行時 > 更改運行時類型菜單,然后將硬件加速器下拉菜單設置為 GPU
Piper TTS 無需 GPU 即可運行,而AudioLDM文本到音頻生成工具需要 GPU 激活。以下是通過AudioLDM生成音頻的步驟。
使用 AudioLDM 生成高質量的合成音頻數據集
要從文本生成音頻文件,下一步涉及使用名為AudioLDM的文本到音頻生成工具。該工具利用潛在擴散模型從文本生成高質量音頻。要使用 AudioLDM,您需要一臺配備強大 GPU 的獨立計算機。
要使用文本提示生成音頻文件,您有兩種選擇:您可以在自己的計算機上使用 GPU 安裝 audioldm,或者使用我為您準備的Google Colab 。
首先,您需要通過運行以下命令使用 pip 安裝 PyTorch
pip3 install torch==2.0.0
接下來,您可以通過運行命令來安裝 audioldm 包
pip3 install audioldm
安裝必要的包后,您可以使用 GitHub 部分中提供的代碼片段從文本提示生成音頻文件。為此,只需運行命令
python3 generate.py
這將啟動生成過程,您應該會看到類似于以下內容的輸出:
genereated: A hammer is hitting a wooden surface
genereated: A noise of nature
genereated: The sound of waves crashing on the shore
genereated: A thunderstorm in the distance
genereated: Traffic noise on a busy street
genereated: The hum of an air conditioning unit
genereated: Birds chirping in the morning
genereated: The sound of a train passing by
一旦收集了 wav 音頻樣本,就可以將它們輸入神經網絡以啟動訓練過程。
就這樣。現在我們可以簡單地將這些 wav 文件上傳到Edge Impulse Studio以訓練我們的模型。
使用 Edge Impulse 平臺進行模型訓練
對于模型訓練、測試和部署,可以使用Edge Impulse Studio平臺。它是一個幾乎不提供代碼解決方案的 TinyML 框架,您無需具備良好的機器學習專業知識即可構建您的 TinyML 模型。
首先,創建一個帳戶并登錄。然后創建一個新項目。將樣本加載到 Edge Impulse 中的最簡單方法是使用上傳數據選項。
選擇數據采集選項卡并選擇上傳數據選項,將出現以下窗口。
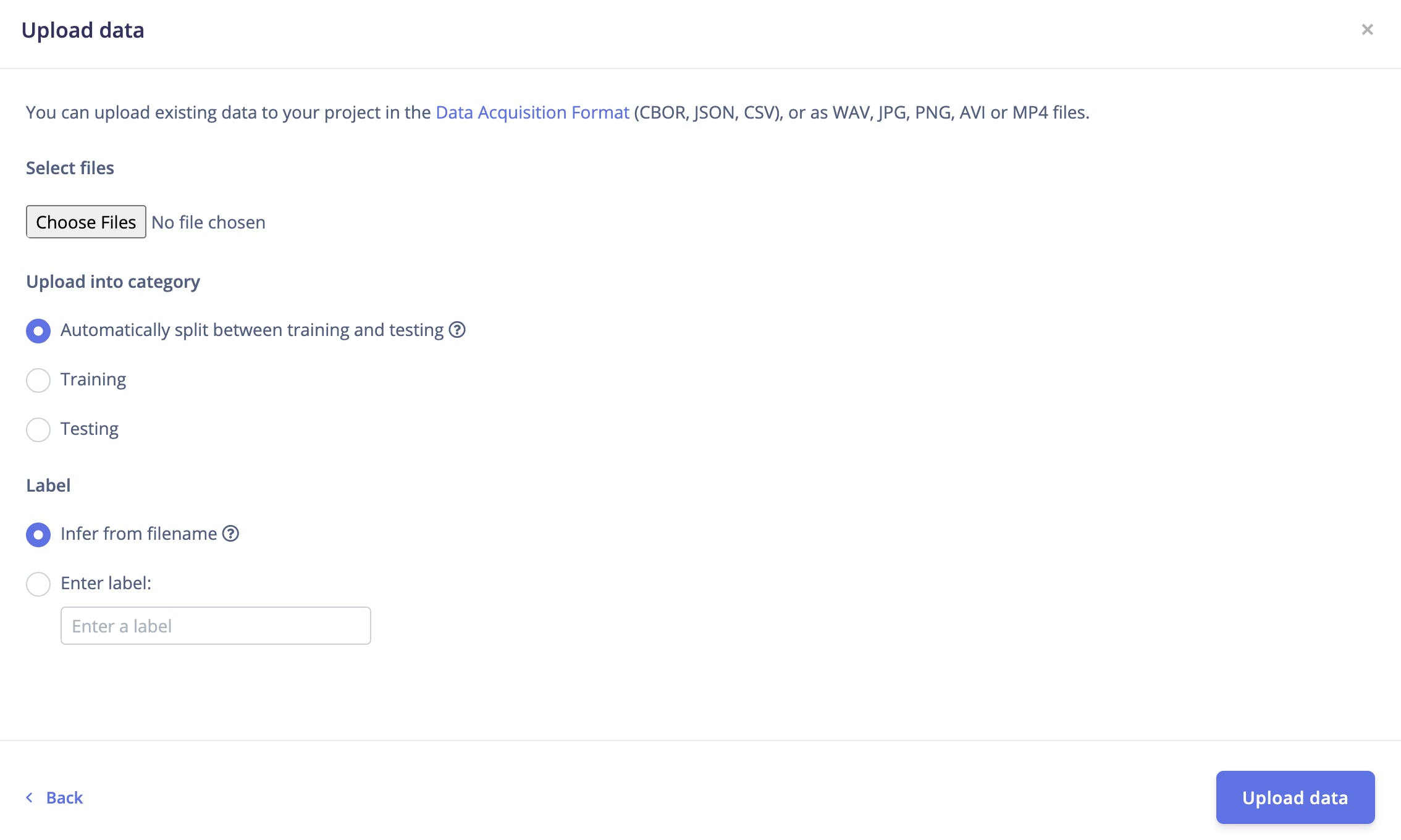
確保在標簽選項下,您在輸入標簽選項下提到了標簽名稱。上傳您的 wav 文件。
對上傳其他班級的音頻樣本重復相同的過程。您應該確保每個音頻樣本都被正確標記并分組到各自的類別中,以避免在訓練期間出現任何混淆。
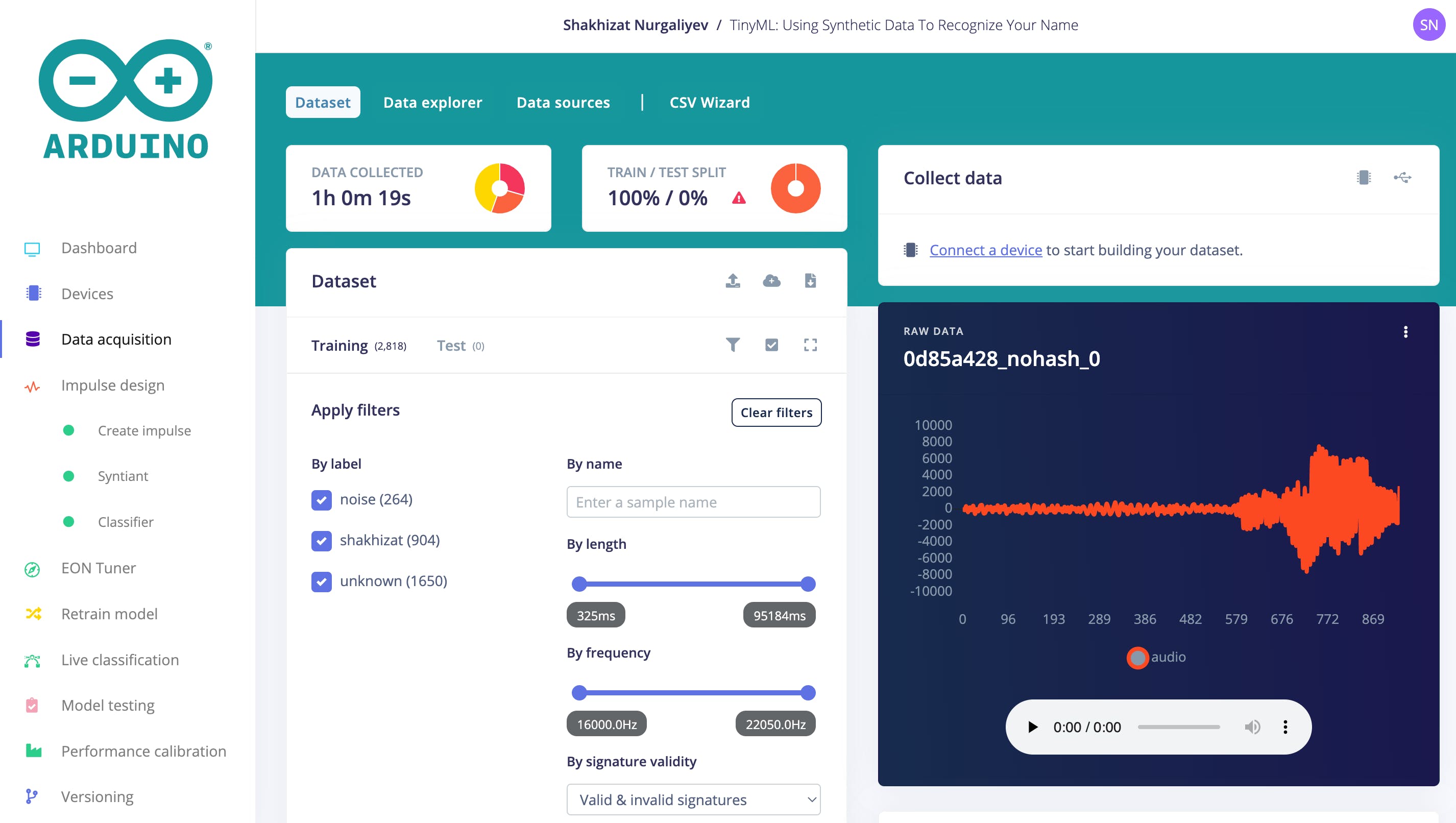
我總共收集了 1 小時 19 秒的數據,這些數據可以分為三個不同的類別。
- 未知類
- 背景噪音等級
- Shakhizat班(我的名字)
一旦你設置了所有的類并且對你的數據集感到滿意,就可以訓練模型了。在左側導航菜單中導航至 Impulse Design。
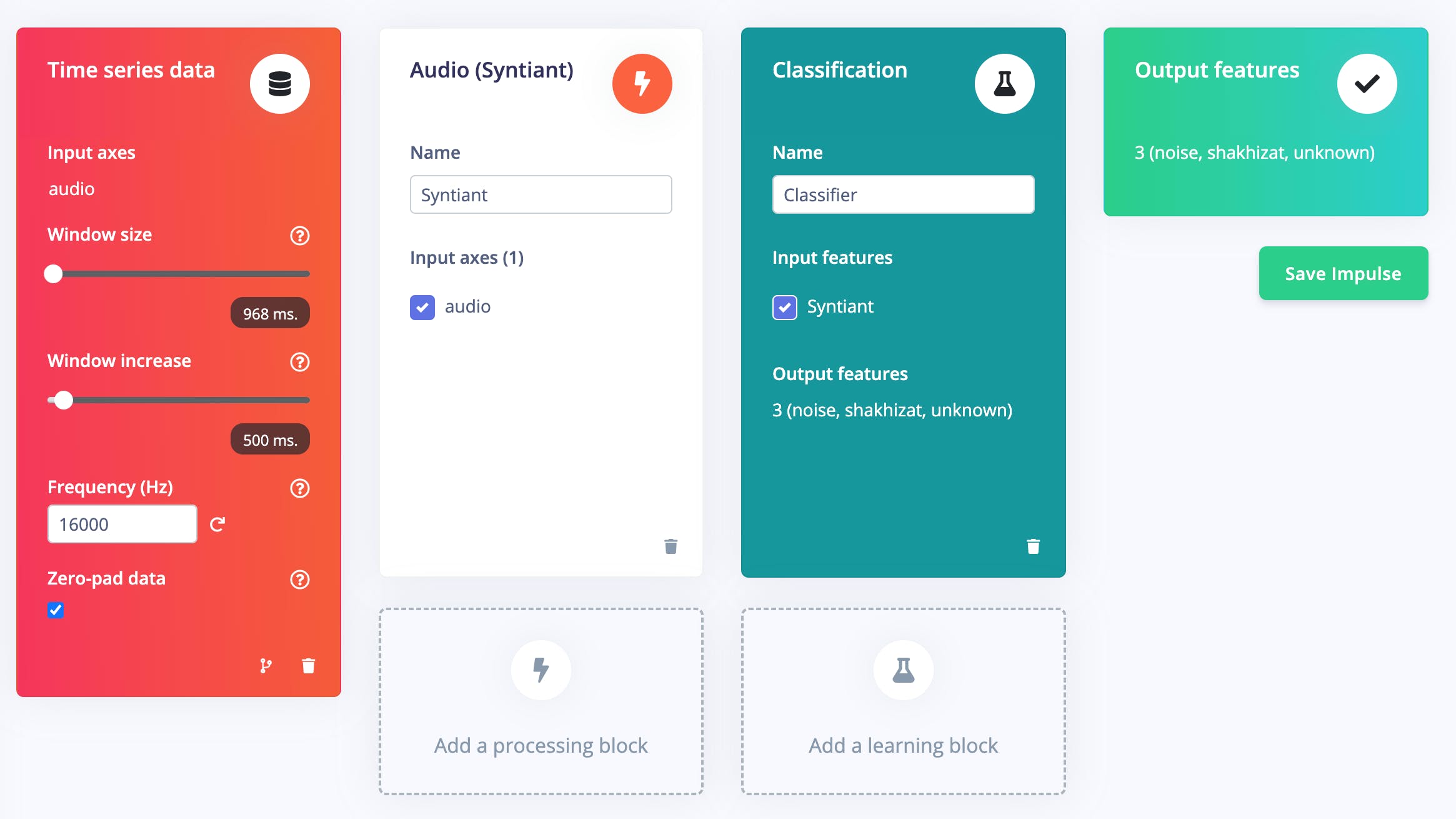
選擇Add a processing block并添加Audio(Syntiant) ,因為它非常適合基于Syntiant NDP120 Neural Decision Processor 的人聲應用。它會嘗試將音頻轉換成某種基于時間和頻率特征的特征,這將有助于我們進行分類。然后選擇添加學習塊并添加分類。
最后,點擊Save Impulse 。
然后導航到Syntiant 。在此步驟中,您將從輸入數據生成特征。特征是分類算法用來對音頻進行分類的獨特屬性。
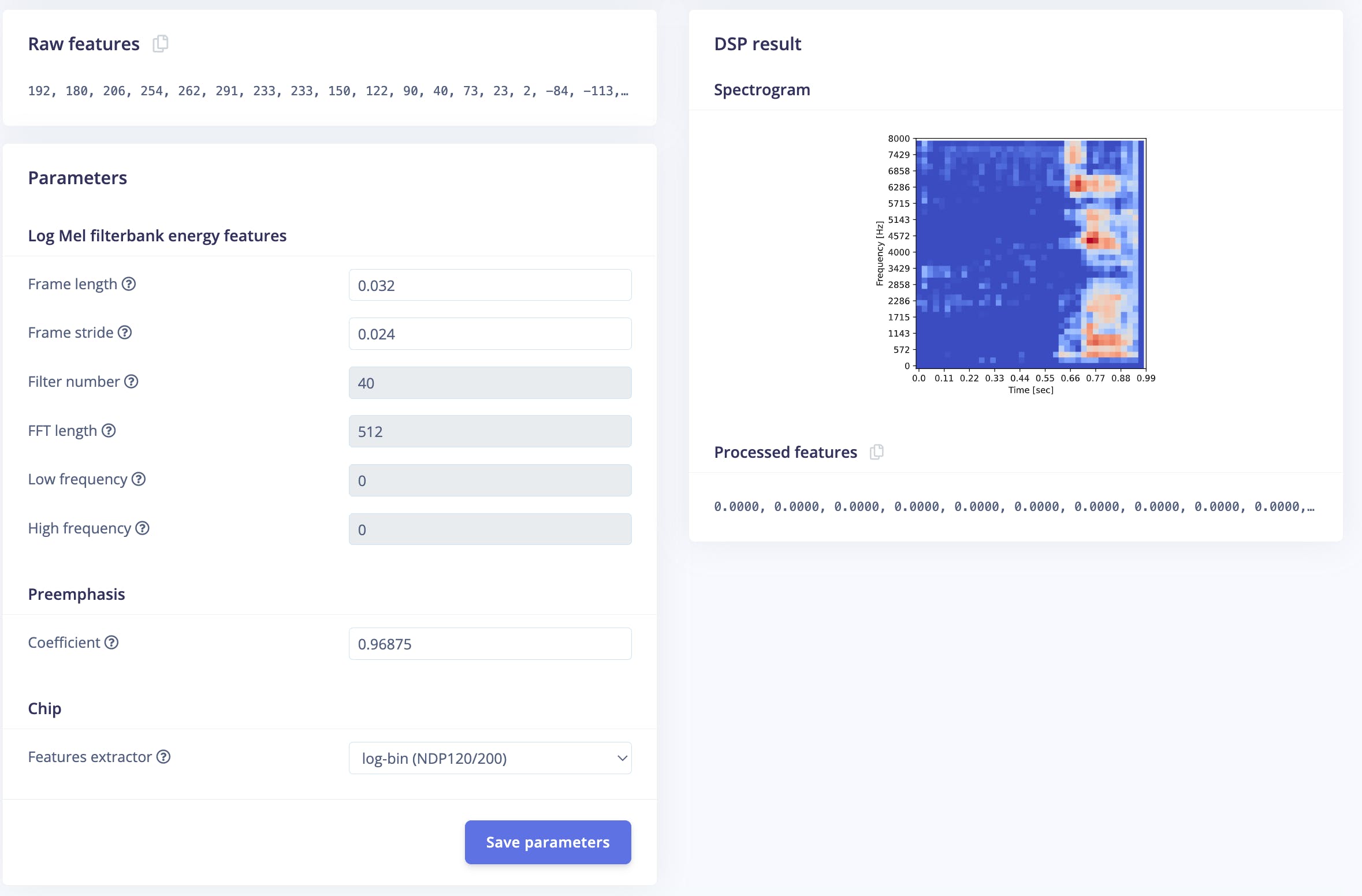
將特征提取器設置為log-bin(NDP120/200) ,然后單擊保存參數。
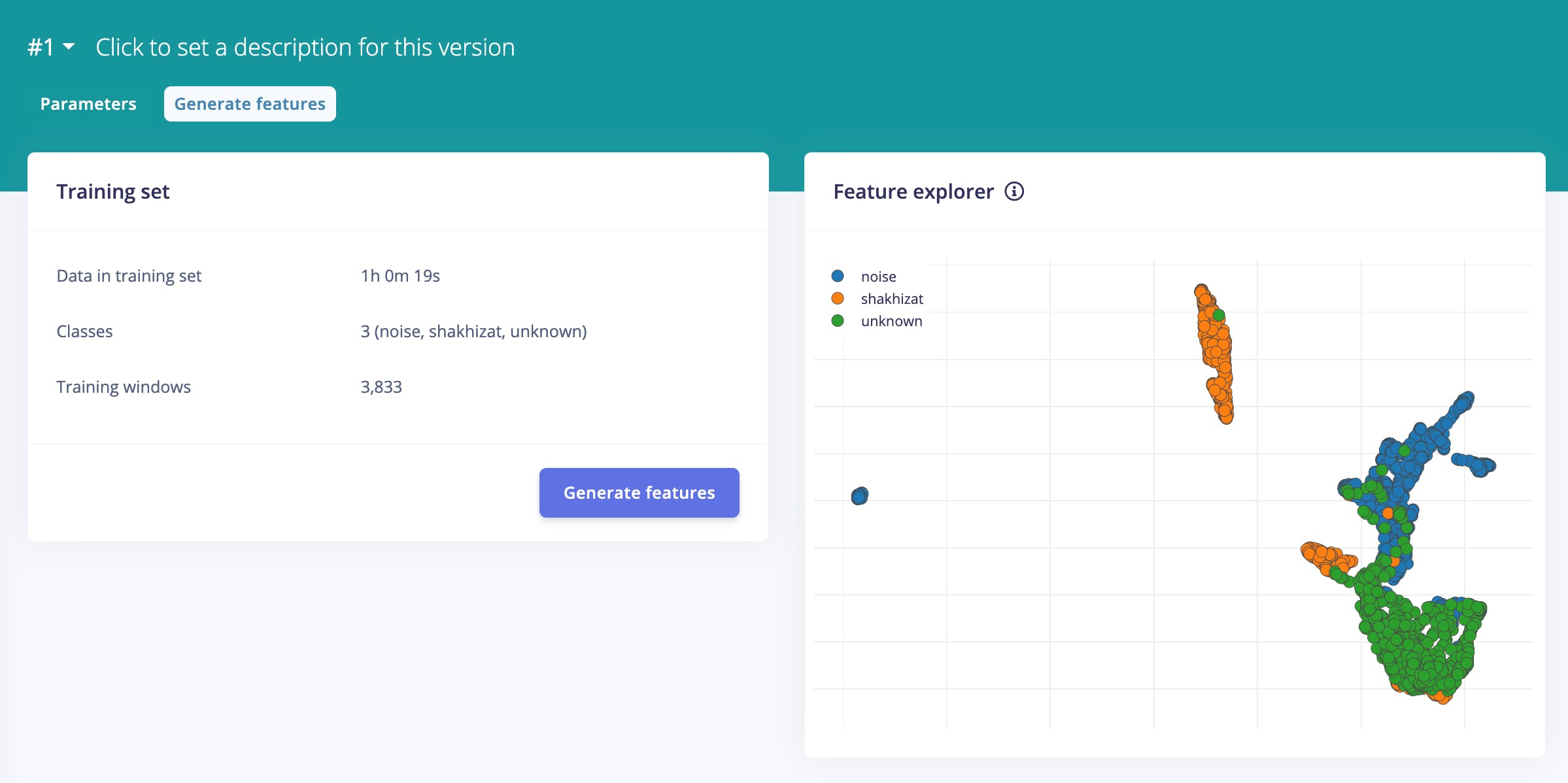
接下來,單擊生成特征并使用特征資源管理器檢查生成的特征。每個數據樣本將根據其標簽在圖中著色。
使用完功能瀏覽器后,單擊左側導航菜單中的分類器項。
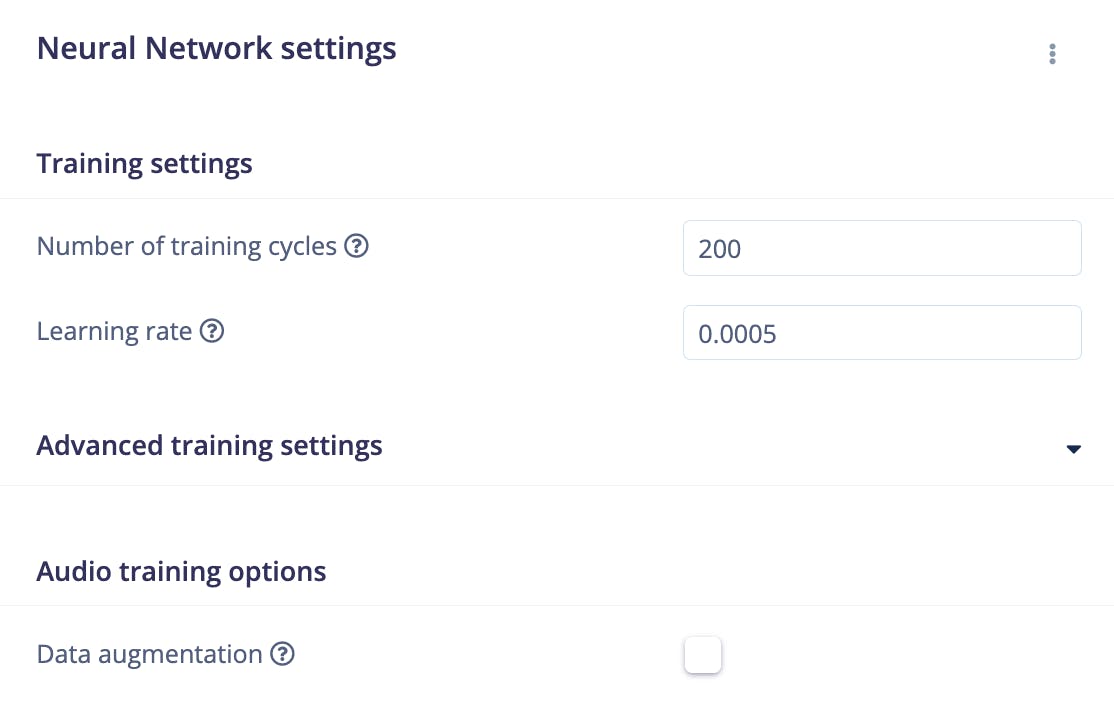
對于此項目,訓練周期數設置為200 ,學習率設置為0.0005 。
該模型具有以下結構:
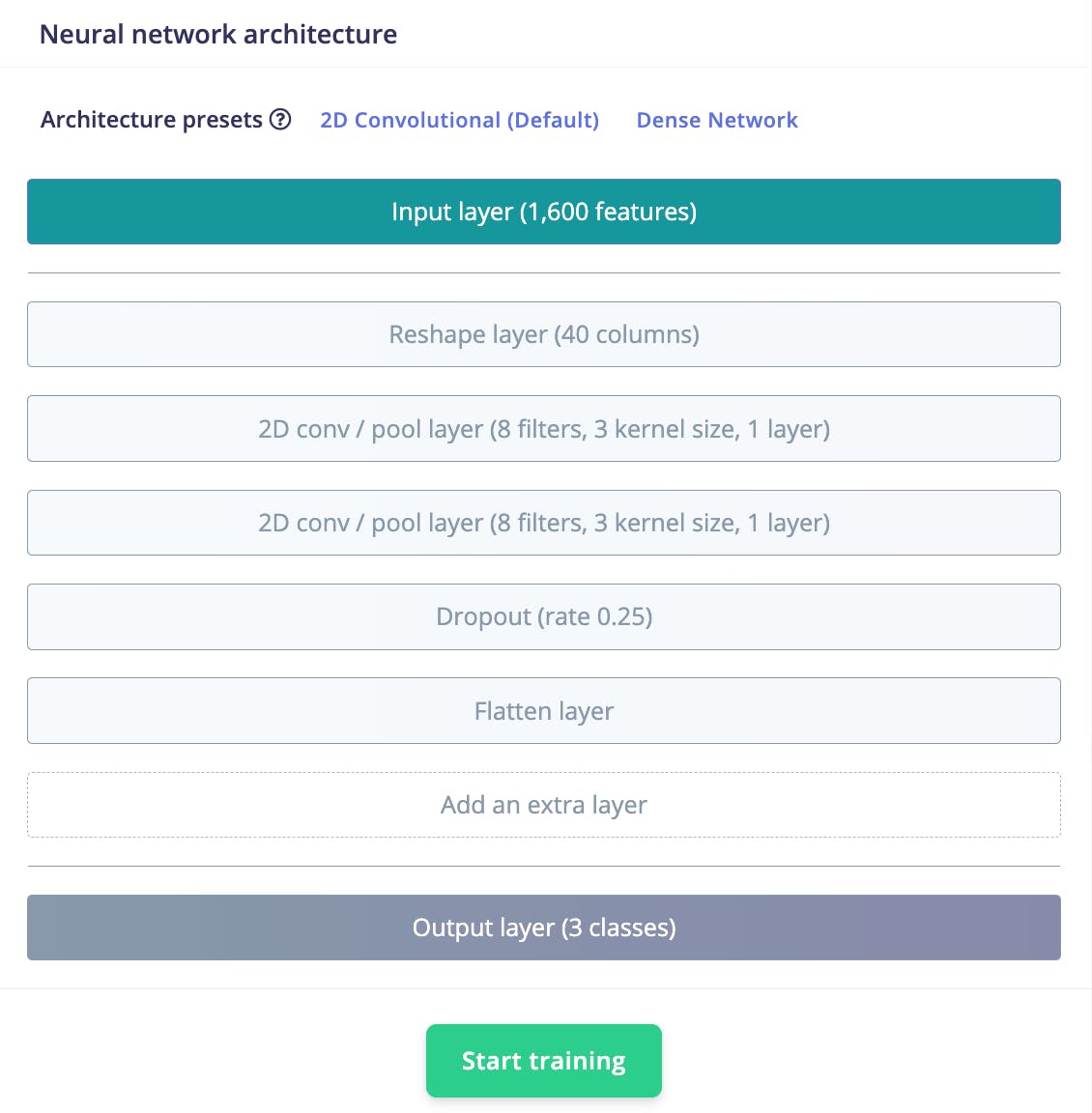
接下來,單擊Start training以訓練機器學習模型,這可能需要一些時間才能完成,具體取決于數據集的大小。
訓練完成后,Edge Impulse Studio 將顯示模型的性能、混淆矩陣、特征資源管理器和設備上的性能細節。
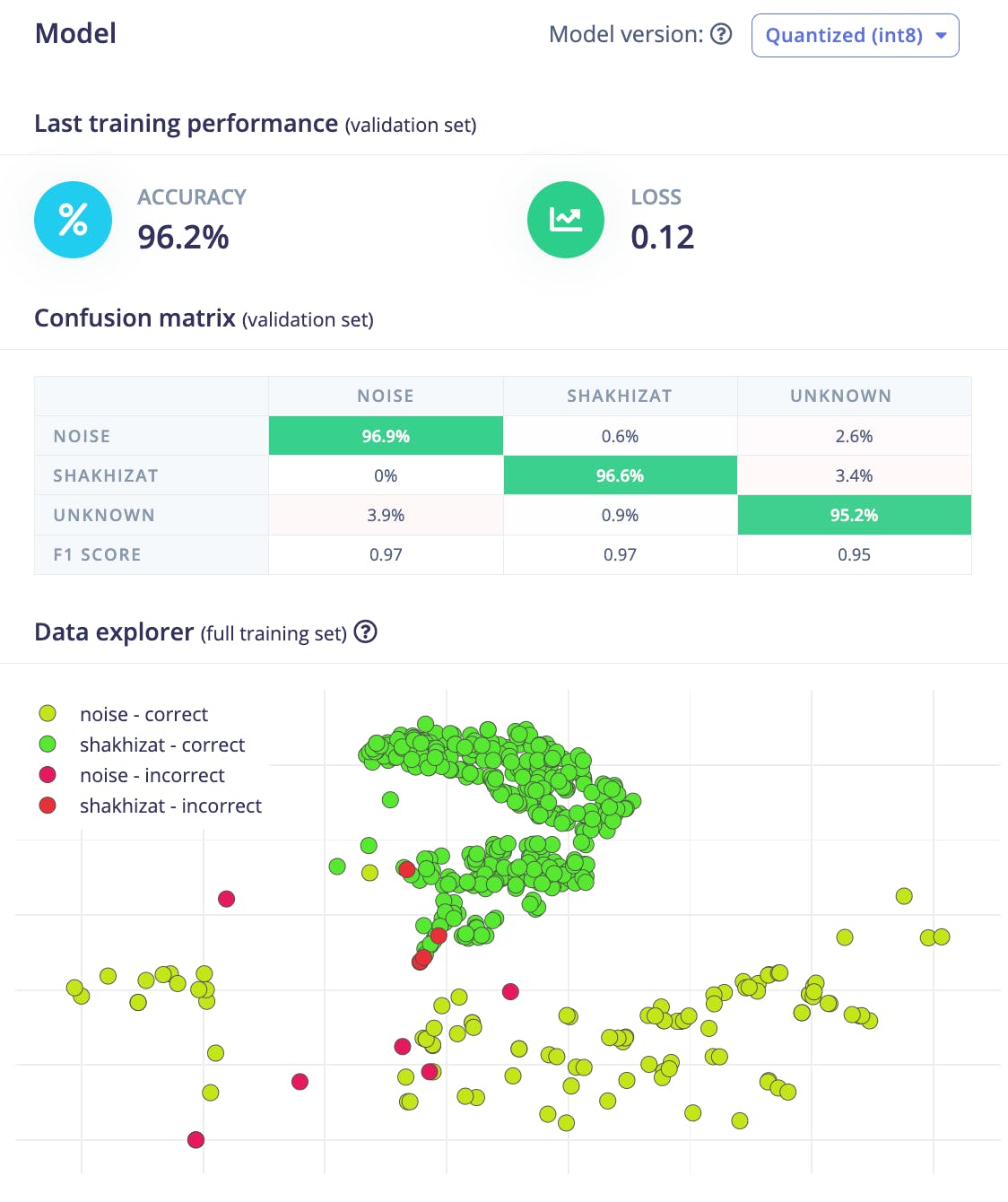
對我來說,準確率為 96.2%,損失為 0.12。訓練集的準確性非常好。
您可能會看到以下日志消息:
| | Total MACs: 284736 | | Total Cycles: 24762 (time=0.0011515066964285713s @ 21.504 MHz) | | Total Parameter Count: 948 | | Total Parameter Memory: 1.4375 KB out of 640.0 KB on the NDP120_B0 device. | | Estimated Model Energy/Inference at 0.9V: 5.56237 (uJ)
此信息很重要,因為它表明模型的內存效率以及它是否可以部署在 Arduino Nicla Voice 等資源有限的設備上。
一旦您對模型的性能感到滿意,就可以將它部署到您的 Arduino Nicla Voice 中了。為此,單擊 Edge Impulse Studio 中的 Deployment 菜單項,然后單擊 Arduino Nicla Voice 按鈕。
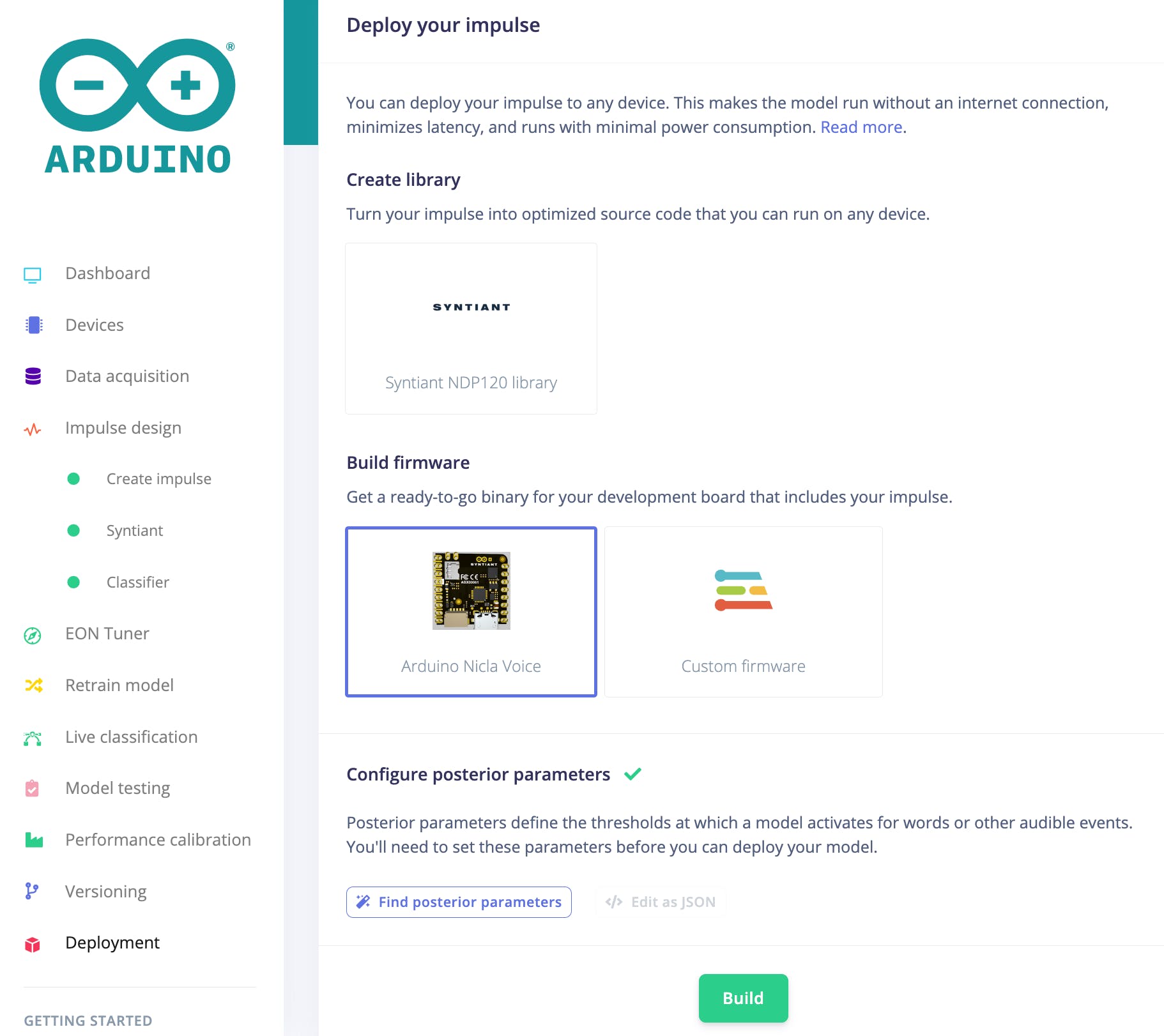
選擇模型后,單擊構建。
打開 Arduino IDE 串行監視器。將波特率設置為 115200。如果一切正常,您應該會看到以下內容:
如您所見,我們的模型表現非常好。盡管有一些錯誤分類,但我覺得它的結果非常棒。該系統能夠將每個說出的詞分類為“未知”類別。此外,它還能將口語單詞“我的名字”正確識別為已知單詞,并將其分配到適當的類別。另一方面,系統將背景中的噪音識別為噪音類別并相應地分配。
總之,該項目演示了如何使用 Edge Impulse 平臺構建音頻分類系統并將其部署在 Arduino Nicla Voice 等邊緣設備上。通過使用包含未知聲音、背景噪聲和人名的多樣化數據集來訓練模型,我們可以創建一個強大的系統,可以實時準確地對音頻樣本進行分類。
我已經讓公眾可以訪問一個項目。有關此項目的更多詳細信息,請訪問 Edge Impulse。并且可以通過此鏈接訪問它。
感謝您的閱讀!如果您有興趣了解有關音頻識別中機器學習的更多信息,我強烈建議您查看下面這篇文章中提到的參考資料
參考
- TinyML變得簡單:圖像分類
- 合成數據的不合理有效性
- TinyML:使用ChatGPT和合成數據檢測嬰兒哭聲
- 用于對象檢測的合成數據生成
- 使用Esp32和TinyML進行手勢分類
- TinyML:ESP32 CAM和TFT上的實時圖像分類
- 基于判斷聚合模型的數據挖掘分類算法 13次下載
- 基于LSTM網絡的在線學習課程推薦模型 6次下載
- 如何使用多線性分類器擬合實現攻擊模擬算法 2次下載
- 基于級聯式分類器的網頁分類方法 0次下載
- 板材心理感知顏色在線模糊分類器設計_常湛源 0次下載
- 朗訊PHS無線數據分組通信模式方案 13次下載
- 無線數據終端
- 基于隱馬爾可夫模型的音頻自動分類
- 合成孔徑雷達圖像目標分類研究
- 濾波器的定義、分類及應用 1674次閱讀
- 音頻混合器電路圖分享 4952次閱讀
- 如何制作一個音頻合成器? 1840次閱讀
- 如何創建基于DCO的音頻合成器 815次閱讀
- 【tinyML】使用EdgeImpulse讓您的Arduino可以辨識手勢! 4081次閱讀
- 如何使用TinyML在內存受限的設備上部署ML模型呢 958次閱讀
- 使用無監督學習和合成數據作為數據增強方法來分類異常 920次閱讀
- 蒸餾無分類器指導擴散模型的方法 1057次閱讀
- 如何在 MCU 上快速部署 TinyML 1689次閱讀
- 如何利用TinyML實現語音識別機器人車的設計 2110次閱讀
- ups電源有幾種_ups電源分類 1.1w次閱讀
- 音頻變壓器工作原理_音頻變壓器作用 1.4w次閱讀
- 一文看懂頻率合成原理與特點 1.3w次閱讀
- 音頻壓縮技術編碼分類 9679次閱讀
- 直流和交流真的永遠對立嗎? 1362次閱讀

 上傳資料賺積分
上傳資料賺積分下載排行
本周
- 1山景DSP芯片AP8248A2數據手冊
- 1.06 MB | 532次下載 | 免費
- 2RK3399完整板原理圖(支持平板,盒子VR)
- 3.28 MB | 339次下載 | 免費
- 3TC358743XBG評估板參考手冊
- 1.36 MB | 330次下載 | 免費
- 4DFM軟件使用教程
- 0.84 MB | 295次下載 | 免費
- 5元宇宙深度解析—未來的未來-風口還是泡沫
- 6.40 MB | 227次下載 | 免費
- 6迪文DGUS開發指南
- 31.67 MB | 194次下載 | 免費
- 7元宇宙底層硬件系列報告
- 13.42 MB | 182次下載 | 免費
- 8FP5207XR-G1中文應用手冊
- 1.09 MB | 178次下載 | 免費
本月
- 1OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234315次下載 | 免費
- 2555集成電路應用800例(新編版)
- 0.00 MB | 33566次下載 | 免費
- 3接口電路圖大全
- 未知 | 30323次下載 | 免費
- 4開關電源設計實例指南
- 未知 | 21549次下載 | 免費
- 5電氣工程師手冊免費下載(新編第二版pdf電子書)
- 0.00 MB | 15349次下載 | 免費
- 6數字電路基礎pdf(下載)
- 未知 | 13750次下載 | 免費
- 7電子制作實例集錦 下載
- 未知 | 8113次下載 | 免費
- 8《LED驅動電路設計》 溫德爾著
- 0.00 MB | 6656次下載 | 免費
總榜
- 1matlab軟件下載入口
- 未知 | 935054次下載 | 免費
- 2protel99se軟件下載(可英文版轉中文版)
- 78.1 MB | 537798次下載 | 免費
- 3MATLAB 7.1 下載 (含軟件介紹)
- 未知 | 420027次下載 | 免費
- 4OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234315次下載 | 免費
- 5Altium DXP2002下載入口
- 未知 | 233046次下載 | 免費
- 6電路仿真軟件multisim 10.0免費下載
- 340992 | 191187次下載 | 免費
- 7十天學會AVR單片機與C語言視頻教程 下載
- 158M | 183279次下載 | 免費
- 8proe5.0野火版下載(中文版免費下載)
- 未知 | 138040次下載 | 免費





 工商網監
工商網監
評論