 電子發(fā)燒友App
電子發(fā)燒友App


通信系統(tǒng)不可避免地要受到各種干擾的影響,使接收端收到的信息與發(fā)送端發(fā)出的信息不一致,即接收端收到的信息產(chǎn)生了誤碼。為了降低數(shù)據(jù)通信線路傳輸?shù)恼`碼率,通常有改善數(shù)據(jù)通信線路傳輸質(zhì)量和差錯(cuò)檢測(cè)控制兩種方法。差錯(cuò)檢測(cè)控制的方法很多,本文討論在10G以太網(wǎng)接人系統(tǒng)中并行實(shí)現(xiàn)CRC-32編解碼的方法、并行CRC算法的Unfolding算法可以實(shí)現(xiàn)并行CRC的計(jì)算,但是并行電路所用的資源增加到了原來的J倍。8位并行CRC算法、并行CRC-16的編碼邏輯、USB技術(shù)中并行CRC算法給出的并行算法都建立在公式遞推的基礎(chǔ)上。當(dāng)并行深度較小時(shí),遞推算法比較適用。而當(dāng)并行深度很大的情況下(10G以太網(wǎng)接人系統(tǒng)使用64比特并行數(shù)據(jù)通路),遞推過程就顯得過于煩瑣而缺乏實(shí)用性。為此,本文提出了矩陣法、代入法和流水線法等三種算法,解決了深度并行情況下CRC算法的實(shí)現(xiàn)問題。利用本文提出的算法,可以得出64比特并行CRC計(jì)算的邏輯表達(dá)式,并用于10G以太網(wǎng)接入系統(tǒng)的設(shè)計(jì)。設(shè)M/(x)為信息多項(xiàng)式,G(x)為生成多項(xiàng)式。一般的CRC編碼方法是:先將信息碼多項(xiàng)式左移r位,即M(x)·xr,然后作模2除法
(M(x)· x r)/G(x)=Q(x)+R(x)/G(x) (1)
所得到的月(x)就是CRC校驗(yàn)碼。以二進(jìn)制碼0x9595H的CRC-32編碼為例:
· 將信息碼左移32比特變成0x959500000000H,記為m。
·CRC-32G的生成多項(xiàng)G(x)=x32+x26+x23+x22+x16+x12+xll+x10+x8+x7+x5+x4+x2+x+1,轉(zhuǎn)換成16進(jìn)制碼為g=0x104C01DB7H。用m除以g(模2除法),所得余數(shù)0x3738F30BH就是0x9595H的CRC-32碼。實(shí)現(xiàn)0x9595H的基本CRC-32編碼的Matlab程序如下:
g(33:-1:1)=[1,0 0 0 0 0 1 0 0,1 1 0 0 0 0 0 1,0 0 0 1 1 1 0 1,1 0 1 1 0 1 1 1];
a(48:-1:1)=[1 0 0 1 0 1 0 1,1 0 0 1 0 1 0 1,0 0 0 0 0 0 0 0,0 0 0 0 0 0 0 0,0 0 0 0 0 0 0 0,0 0 0 0 0 0 0 0];
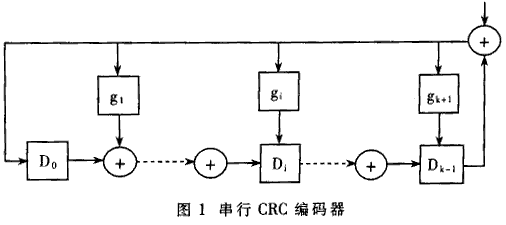
for i=48:-1:33,
if a(i)= =1
a(i:-1:i-32)=xor(a(i:-1:i-32),i(33:-1:1));
end
end
crc=a(32:-1:1)
如果想用以上CRC-32程序計(jì)算其他長(zhǎng)為L(zhǎng)的序列的基本CRC-32碼,只需將數(shù)組α的上界和for循環(huán)中i的初始值改為32+L,并用該序列代替數(shù)組。開始的序列"1001010110010101"即可。用數(shù)字電路實(shí)現(xiàn)的串行CRC編碼器如圖1所示。圖1中每個(gè)矩形表示D觸發(fā)器。gi的取值范圍是1或者0。取1時(shí)表示通路,取0時(shí)表示斷路。進(jìn)行基本CRC-32編碼時(shí),每個(gè)D觸發(fā)器初始狀態(tài)為0,從數(shù)據(jù)端串行輸入二進(jìn)制的信息碼。信息碼輸入結(jié)束后,D觸發(fā)器中鎖存的數(shù)值就是信息碼的基本CRC-32編碼。此電路適用于信息碼長(zhǎng)為任意值的情況。在某些信息系統(tǒng)中以基本CRC產(chǎn)生算法為基礎(chǔ)附加了新的規(guī)定。例如IEEE802.3協(xié)議規(guī)定,以太網(wǎng)的FES(幀校驗(yàn)序列)域以CRC-32為基礎(chǔ),并且在編碼時(shí)首先將信息碼的最初4個(gè)字節(jié)取反碼,對(duì)目的地址、源地址、長(zhǎng)度/類型域、數(shù)據(jù)域、PAD域求出基本CRC-32碼之后再將結(jié)果取反,最后的結(jié)果才是FCS。同上述過程等價(jià)的另一種實(shí)現(xiàn)方法是將圖1中所有D觸發(fā)器的初值置1,這樣結(jié)果不必取反。為使電路設(shè)計(jì)者驗(yàn)證其FCS編碼正確,IEEE802.3還給出了一個(gè)樣本,即:將序列0xBED723476B8FB3145EFB3559H重復(fù)126次,最后得到的FCS值應(yīng)該為0x94D254ACH。10G以太網(wǎng)是IEEE802.3ae工作組提出的建議。它保持了以前以太網(wǎng)的幀結(jié)構(gòu),但是線速度達(dá)到了10Gbps的量級(jí)。為了降低10G以太網(wǎng)接入系統(tǒng)的功耗并達(dá)到芯片加工工藝的要求,必須采用并行數(shù)據(jù)通路。為計(jì)算FCS需要研究并行CRC算法。所設(shè)計(jì)的10G以太網(wǎng)接入系統(tǒng)采用64比特并行數(shù)據(jù)通路,因此本文主要討論64比特并行CRC-32的實(shí)現(xiàn)方法。本文共介紹三種實(shí)現(xiàn)方法,其中矩陣法和代入法是基于組合邏輯的直接實(shí)現(xiàn)方法,第三種方法是基于流水線的實(shí)現(xiàn)方法。

1 矩陣法
記圖1中的32個(gè)D觸發(fā)器的輸出從右至左依次為d31,d30,…,d0。信息碼元的輸入端為i。令D=[d0d1…d31]T表示編碼器當(dāng)前所處的狀態(tài),I=[i63i62…i0]表示第1至第64個(gè)時(shí)鐘的信息碼元輸入,向量Dˊ=[d0ˊd1ˊ,…d31ˊ] T表示編碼器的下一個(gè)狀態(tài),D(64)表示64個(gè)時(shí)鐘之后CRC編碼器所處的狀態(tài)。則設(shè)計(jì)64位并行CRC邏輯編碼器,就是找出函數(shù)關(guān)系D(64)=f(D,I)。
do'=d31+i63
d1'=d0+d31+i63
d2'=d1+d31+i63
d3'=d2
…
d31'=d30
寫成行列式,有D'=TD+Si63
其中:

2個(gè)時(shí)鐘之后編碼器的狀態(tài)為:
D''=TD'+Si62=T)TD+Si63)+Si62=T2D+TSi63+Si62
依此類推,有:
D(64)=T64D+T63Si63+T62Si62+…+TSi1+Si0 (2)
這里所有矩陣運(yùn)算和代數(shù)運(yùn)算中的加號(hào)的語義都是模2加法。為了。設(shè)計(jì)64位并行CRC電路,必須計(jì)算(2)式中的大規(guī)模矩陣乘法T64、T63S等。
2 代入法
矩陣法的優(yōu)點(diǎn)在于其直觀性。但是需要做大規(guī)模乘法運(yùn)算。下面討論的代入法能夠得到與矩陣法相同的結(jié)果。同時(shí)可以避免大規(guī)模矩陣乘法運(yùn)算。設(shè)8比特并行CRC-32電路的初始狀態(tài)是d31,d30,…,d0,輸入是i7,i6,…,j0,輸出是z31,Z30,…,z0。利用前面所述的矩陣法,可以得出8比特并行CRC-32編碼器的組合邏輯表達(dá)式。如表1所示。
即:
z31=d23+d29+i5;
z30=d22+d31+i7+d28+i4
…
z0=d24+d30+i6+i0
表1 8位行CRC邏輯表
| z0 | d24,d30,i6,i0 |
| z1 | d25,d31,i7,i1,d24,d30,i6,i0 |
| z2 | d26,i2,d25,d31,i7,i1,d24,d30,i6,i0 |
| z3 | d27,i3,d26,i2,d25,d31,i7,i1 |
| z4 | d28,i4,d27,i3,d26,i2,d24,d30,i6,i0 |
| z5 | d29,i5,d28,i4,d27,i3,d25,d31,i7,i1,d24,d30,i6,i0 |
| z6 | d30,i6,d29,i5,d28,i4,d26,i2,d25,d31,i7,i1 |
| z7 | d31,i7,d29,i5,d27,i3,d26,i2,d24,i0 |
| z8 | d0,d28,i4,d27,i3,d25,i1,d24,i0 |
| z9 | d1,d29,i5,d28,i4,d26,i2,d25,i1 |
| z10 | d2,d29,i5,d27,i3,d26,i2,d24,i0 |
| z11 | d3,d28,i4,d27,i3,d25,i1,d24,i0 |
| z12 | d4,d29,i5,d28,i4,d26,i2,d25,i1,d24,d30,i6,i0 |
| z13 | d5,d30,i6,d29,i5,d27,i3,d26,i2,d25,d31,i7,i1 |
| z14 | d6,d31,i7,d30,i6,d28,i4,d27,i3,d26,i2 |
| z15 | d7,d31,i7,d29,i5,d28,i4,d27,i3 |
| z16 | d8,d29,i5,d28,i4,d24,i0 |
| z17 | d9,d30,i6,d29,i5,d25,i1 |
| z18 | d10,d31,i7,d30,i6,d26,i2 |
| z19 | d11,d31,i7,d27,i3 |
| z20 | d12,d28,i4 |
| z21 | d13,d29,i5 |
| z22 | d14,d24,i0 |
| z23 | d15,d25,i1,d24,d30,i6,i0 |
| z24 | d16,d26,i2,d25,d31,i7,i1 |
| z25 | d17,d27,i3,d26,i2 |
| z26 | d18,d28,i4,d27,i3,d24,d30,i6,i0 |
| z27 | d19,d27,i5,d28,i4,d25,d31,i7,i1 |
| z28 | d20,d30,i6,d29,i5,d26,i2 |
| z29 | d21,d31,i7,d30,i6,d27,i3 |
| z30 | d22,d31,i7,d28,i4 |
| z31 | d23,d29,i5 |
下文用"+"表示按位模2和運(yùn)算,"{,}"表示鏈接運(yùn)算。從CRC的(1)式很容易得出以下算法:
算法1:已知序列N的CRC-32為A[31:0],序列B(=[b7,b6,…,b0])的CRC-32碼為Y[31:0]。序列A[31:24]的CRC-32為X[31:0],則延拓序列{N,B}的CRC-32碼為{Y[31:24]+X[31:24]+A[23:16],Y[23:16]+X[23:16]+A[15:8]+A[7:0],Y[7:0]+X[7:0]}。
推論:已知序列N的CRC-32為A[31:0],序列A[31:24]的CRC-32為X[31:0],則補(bǔ)0延拓序列{N,O}的CRC-32碼為{X[31:24]+A[23:16]+A[15:8],X[15:8]+A[7:0],X[7:0]}。
利用上述算法構(gòu)造APPEND模塊,其端口A和B分別表示前導(dǎo)序列的CRC和延拓的8比特序列,則其輸出端口Z為拓展之后序列的CRC。圖2利用APPEND模塊構(gòu)造了級(jí)聯(lián)結(jié)構(gòu)的64比特并行CRC編碼器。這種級(jí)聯(lián)構(gòu)造的編碼器設(shè)計(jì)比較簡(jiǎn)單。其中間節(jié)點(diǎn):
Z1(n)=f(r,d[0:7] n[31,0]
Z2(n)=f(Z1,d[8:15])=f(f(r,d[0:7]),d{8:15])
… (3)

顯然(3)還可以進(jìn)一步化簡(jiǎn)。冗余的邏輯使得這種級(jí)聯(lián)結(jié)構(gòu)占用芯片面積大,且只能用于低速場(chǎng)合。對(duì)(3)進(jìn)一步化簡(jiǎn),可以得到Z2的最簡(jiǎn)異或表達(dá)式。同理可以得到Z3…Z8的表達(dá)式。Zl,Z2,…,Z8分別對(duì)應(yīng)8比特、16比特、……、64比特的并行CRC運(yùn)算表達(dá)式。具體表達(dá)式限于篇幅不在這里給出。Z8中最長(zhǎng)的異或運(yùn)算表達(dá)式有52項(xiàng)參加運(yùn)算,如果使用4-異或門則只需要用三級(jí),即能在一般CMOS工藝的一級(jí)傳輸延遲時(shí)間之內(nèi)完成。當(dāng)用于以太網(wǎng)接入系統(tǒng)時(shí),因?yàn)橐蕴W(wǎng)幀不一定結(jié)束在64比特邊界,因此編碼器應(yīng)該有同時(shí)計(jì)算8、16、24、……、64比特并行編碼的能力。具體電路如圖3。因?yàn)橐话闱闆r下大量用到64比特并行編碼,因此平時(shí)使能信號(hào)mux使其他7個(gè)編碼模塊不工作以降低功耗。在幀尾部根據(jù)具體情況使用這7個(gè)模塊進(jìn)行剩余字節(jié)的編碼。
3 流水線法
矩陣法和代入法本質(zhì)上都是設(shè)計(jì)直接并行編碼電路的方法,二者的最終效果是一樣的。直接并行實(shí)現(xiàn)的CRC編碼電路控制邏輯比較簡(jiǎn)單,但是需要進(jìn)行復(fù)雜的組合邏輯運(yùn)算。為了在更高頻率下進(jìn)行并行CRC編碼,可以進(jìn)一步用流水線的方法簡(jiǎn)化編碼邏輯,所付出的代價(jià)是整個(gè)幀的處理延遲了8個(gè)時(shí)鐘周期。圖4給出了CRC編碼的流水線實(shí)現(xiàn)。將并行輸入的64比特分成7個(gè)字節(jié),分別用D0、D1、……、D7表示。P模塊(P0~P7)計(jì)算形如"Di,O,O,O,O,O,O,O,Di"的序列的CRC,其中Diˊ,是Di位置上的上一次輸入。Diˊ的CRC碼由端口R[31:0]輸入,Di由端口D[7:0]輸入,結(jié)果由Z[31:0]端口輸出。
C模塊(C1~C7)的輸入是"D0,O,O,O,O,O,O,O,D0'和"D1ˊ,O,O,O,O,O,O,O,D1"的CRC(分別由端口R1和R2輸入),輸出是"D0ˊ,D1ˊ,O,O,O,O,O,O,D0,D1" CRC。求P的邏輯表達(dá)式時(shí),重復(fù)應(yīng)用算法1的推論,可以求出"Diˊ,O,O,O,O,O,O,Di"的CRC碼,再應(yīng)用算法1,就可以求出"Diˊ,O,O,O,O,O,O,O,Di"的CRC碼。直接應(yīng)用算法1可以求出C模塊的邏輯表達(dá)式。P模塊和C模塊進(jìn)行異或運(yùn)算的長(zhǎng)度遠(yuǎn)小于直接并行CRC電路中的ENC8模塊,因此更有利于在高速電路中應(yīng)用。

4 10G以太網(wǎng)接入系統(tǒng)中的CRC編解碼器設(shè)計(jì)
10G以太網(wǎng)接人系統(tǒng)所需接口速率高達(dá)10Gbps以上。從降低系統(tǒng)功耗和芯片制造成本的角度考慮希望接口能工作在200MHz以下。采用并行化設(shè)計(jì)雖然可以降低系統(tǒng)時(shí)鐘頻率,但也從以下兩方面增加了設(shè)計(jì)難度。首先,數(shù)據(jù)通路的并行程度越高,對(duì)它的控制就越復(fù)雜。系統(tǒng)采用8字節(jié)并行數(shù)據(jù)通路,則發(fā)送的以太網(wǎng)幀可能在8個(gè)并行字節(jié)中的任意一個(gè)位置上結(jié)束,控制邏輯的設(shè)計(jì)就必須考慮所有這些可能性并逐一做出相應(yīng)的處理。其次,系統(tǒng)中的CRC編碼器、擾碼器等的設(shè)計(jì)須采用并行算法。為了滿足IEEE802.3協(xié)議對(duì)以太網(wǎng)幀CRC編碼的要求,實(shí)際的編解碼器模塊還需要能對(duì)輸入輸出信號(hào)進(jìn)行任意字節(jié)數(shù)的求反運(yùn)算。考慮到10G接入系統(tǒng)的復(fù)雜性,該模塊功能應(yīng)該高度集成化,以便用宏信號(hào)端口對(duì)其進(jìn)行操作。在對(duì)收到的以太網(wǎng)幀進(jìn)行校驗(yàn)時(shí),沒必要先計(jì)算不包括FCS域的序列的CRC編碼(結(jié)果取反)再與FCS域做對(duì)比。在編碼正確且沒有誤碼的情況下,對(duì)整個(gè)以太網(wǎng)幀(包括FCS域)進(jìn)行結(jié)果不取反的CRC編碼的結(jié)果應(yīng)該為序列0xC704DD7BH。采用這種判別方法,無需在幀的結(jié)束前停止計(jì)算CRC編碼,因而可以大大簡(jiǎn)化電路設(shè)計(jì)。
5 CRC編碼器的實(shí)現(xiàn)
本文提出的各種算法的硬件實(shí)現(xiàn)已經(jīng)通過了FPGA驗(yàn)證,并被應(yīng)用到具體芯片。使用Xilinx公司的Virtex2系列FPGA中的XC2V1000分別仿真了采用上述代入法和流水線法設(shè)計(jì)的CRC編碼器和解碼器,驗(yàn)證了設(shè)計(jì)方法的正確性。在綜合考慮邏輯復(fù)雜度、所占用的芯片面積和工藝要求后,最終在所設(shè)計(jì)的10G以太網(wǎng)接入芯片中,采用了代入法設(shè)計(jì)的CRC編碼器和解碼器。
10G以太網(wǎng)接入系統(tǒng)中需要采用并行CRC編碼器。本文提出了基于組合邏輯的直接實(shí)現(xiàn)和基于流水線的實(shí)現(xiàn)方法。其中直接實(shí)現(xiàn)的方法又分為矩陣法和代入法兩種。經(jīng)過具體推導(dǎo)發(fā)現(xiàn)直接實(shí)現(xiàn)的編碼器可以滿足延時(shí)要求,因而被本系統(tǒng)所采用。而基于流水線的設(shè)計(jì)因?yàn)槠溲訒r(shí)較小,可以用于更高速的場(chǎng)合。本文提出的三種并行化設(shè)計(jì)方法已經(jīng)通過了硬件驗(yàn)證。這些設(shè)計(jì)思想同樣適用于其他線性移位寄存器,如擾碼器的設(shè)計(jì)。









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論