 電子發燒友App
電子發燒友App


流媒體視頻、云服務和移動數據推動了全球網絡流量的持續增長。為了支持這種增長,網絡系統必須提供更快的線路速率和每秒處理數百萬個數據包的性能。在網絡系統中,數據包的到達順序是隨機的,且每個數據包的處理需要好幾個存儲動作。數據包流量需要每秒鐘訪問數億萬次存儲器,才能在轉發表中找到路徑或完成數據統計。
數據包速率與隨機存儲器訪問速率成正比。如今的網絡設備需要具有很高的隨機訪問速率(RTR)性能和高帶寬才能跟上如今高速增長的網絡流量。其中,RTR是衡量存儲器可以執行的完全隨機存儲(讀或寫)的次數,即隨機存儲速率。該度量值與存取處理過程的處理位數無關。RTR是以百萬次/每秒(MT/s)為單位計量的。
相比于高性能網絡系統需要處理的隨機流量的速率,當今高性能DRAM能夠處理的要少一些。QDR-IV SRAM旨在提供同類最佳的RTR性能,以滿足苛刻的網絡功能要求。圖1量化了QDR-IV相比于其它類型的存儲器在RTR性能方面的優勢。即使與最高性能的存儲器相比,QDR-IV仍能提供兩倍于后者的RTR性能,因此,它是那些需要執行要求苛刻的操作-如更新統計數據、跟蹤數據流狀態、調度數據包、進行表查詢-的高性能網絡系統的理想選擇。
在本系列的第一部分中,我們將探討兩種類型的QDR-IV存儲器、時鐘、讀/寫操作和分組操作。
圖1. QDR-IV性能對比
不同類型的QDR-IV:XP和HP
QDR-IV 有兩種類型。HP在較低頻率下工作,而且不使用分組操作。 XP面向最高性能的應用,可以使用分組操作方案,并在較高頻率下工作。
QDR-IV的讀寫時延由運行速度決定。表1定義了工作模式和每個模式所支持的頻率。

表1. 工作模式
QDR-IV SRAM具有兩個端口,即端口A和端口B。由于可以獨立訪問這兩個端口,所以對存儲器陣列進行的任何讀/寫訪問組合均可得到最大的隨機數據傳輸速率。在QDR-IV中,對每個端口進行訪問時需要使用雙倍數據速率的通用地址總線(A)。端口A的地址在輸入時鐘(CK)的上升沿上被鎖存,而端口B的地址在輸入時鐘(CK)的下降沿上或在CK#的上升沿上被鎖存。控制信號(LDA#、LDB#、RWA#和RWB#)以單倍數據速率(SDR)工作,并用于確定執行讀操作還是寫操作。兩個數據端口(DQA和DQB)均配備了雙倍數據速率(DDR)接口。該器件具有2字突發的架構。器件的數據總線帶寬為 × 18或 × 36。
QDR-IV SRAM包括指定為端口A和端口B的兩個端口。因為對兩個端口的訪問是獨立的,所以對于對存儲器陣列的讀/寫訪問的任何組合,隨機事務速率被最大化。 對每個端口的訪問是通過以雙倍數據速率(即時鐘的兩個邊沿)運行的公共地址總線(A)。 端口A的地址在輸入時鐘(CK)的上升沿鎖存,端口B的地址在CK的下降沿或CK#的上升沿鎖存。 控制信號(LDA#,LDB#,RWA#和RWB#)以單數據速率(SDR)運行,它們決定是執行讀操作還是寫操作。 兩個數據端口(DQA和DQB)都配有雙倍數據速率(DDR)接口。 該器件采用2字突發架構。 它提供×18和×36數據總線寬度。
QDR-IV XP SRAM器件具有一個組切換選項。分組操作一節描述了如何使用組切換,讓器件能夠以更高的頻率和RTR工作。
時鐘信號說明
CK/CK#時鐘與以下地址和控制引腳相關聯:An-A0、AINV、LDA#、LDB#、RWA#以及RWB#。CK/CK#時鐘與地址和控制信號中心對齊。
DKA/DKA#和DKB/DKB#是與輸入寫數據相關聯的輸入時鐘。這些時鐘與輸入寫數據中心對齊。
根據QDR-IV SRAM器件的數據總線寬度配置,表2顯示了輸入時鐘與輸入寫數據之間的關系。為了確保指令和數據周期的正確時序,并確保正確的數據總線返回時間,DKA/DKA#和DKB/DKB#時鐘必須符合各自數據表中給出的CK to DKx斜率 (tCKDK)。
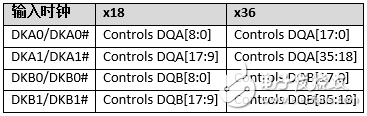
表2. 輸入時鐘與寫數據之間的關系
QKA/QKA#和QKB/QKB#是與讀取數據相關聯的輸出時鐘。這些時鐘與輸出讀取數據邊沿對齊。
QK/QK#是數據輸出時鐘,由內部鎖相環(PLL)生成。它與CK/CK#時鐘同步,并符合各自數據表中給出的CK to QKx斜率 (tCKQK)。
根據QDR-IV SRAM器件的數據總線帶寬的配置情況,表3顯示了輸出時鐘與讀取數據之間的關系。
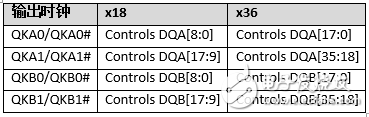
表3. 輸出時鐘與讀取數據之間的關系
讀/寫操作
讀和寫指令由控制輸入(LDA#、RWA#、LDB#和RWB#)和地址輸入驅動。在輸入時鐘(CK)的上升沿上對端口A控制輸入進行采樣。在輸入時鐘的下降沿上對端口B控制輸入進行采樣。 表4顯示的是端口A和端口B的讀/寫操作條件。
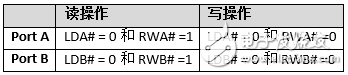
表4. 端口A和端口B的讀/寫條件
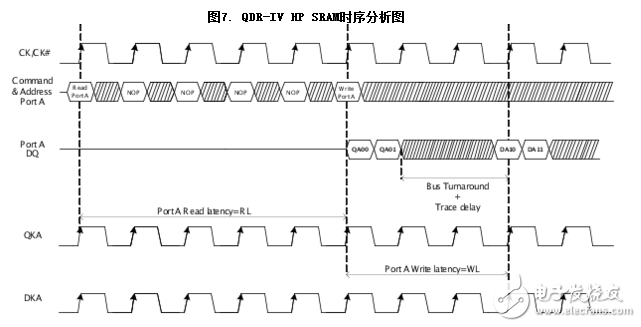
如圖2 和圖3 所示,對于QDR-IV HP SRAM,端口A的讀取數據在CK的上升沿后整五個讀取延遲(RL)時鐘周期后才從DQA 引腳上輸出;對于QDR-IVXP SRAM,則需要八個讀延遲(RL)時鐘周期。CK信號的上升沿發生,同時讀取指令發出,經過指定的RL時鐘周期后才可獲取數據。
對于QDR-IV HP SRAM,端口A的寫入數據在CK的上升沿后整三個寫入延遲(WL)時鐘周期才傳輸至DQA 引腳;對于QDR-IV XP SRAM,則需要五個寫延遲(WL) 時鐘周期。CK信號的上升沿發生,同時寫入指令發出,經過指定的RL時鐘周期后才可獲取數據。
對于QDR-IV HP SRAM,端口B的讀取數據在CK的上升沿后整五個RL 時鐘周期才從DQB引腳上輸出;對于QDR-IV XP SRAM,則需要八個RL 時鐘周期。CK信號的上升沿發生,同時讀取指令發出,經過指定的RL時鐘周期后才可獲取數據。
對于QDR-IV HP SRAM,端口B的寫入數據在CK的上升沿后整三個WL 時鐘周期才傳輸至DQB引腳;對于QDR-IV XP SRAM,則需要五個WL 時鐘周期。CK信號的上升沿發生,同時寫入指令發出,經過指定的RL時鐘周期后才可獲取數據。
QVLDA/QVLDB 信號表示相應端口上的有效輸出數據。在總線上驅動第一個數據字的半周期前置位QVLDA 和QVLDB信號,并在總線上驅動最后一個數據字的半周期前取消置位它們。最后數據字后的數據輸出是三態的。
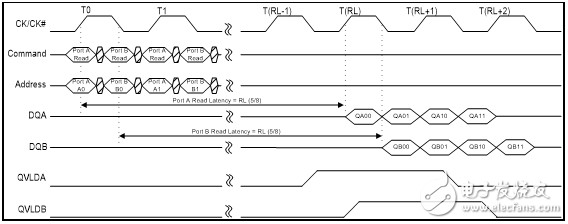
圖2. 讀取時序
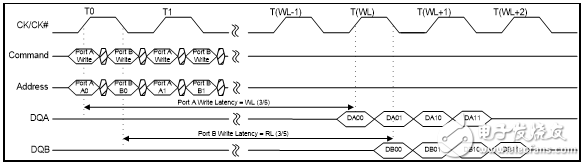
圖3. 寫時序
旨在實現高速運行的分組操作
QDR-IV XP SRAM 的設計是為了支持頻率更高的八組模式(最大工作頻率 = 1066 MHz),而QDR-IV HP SRAM 則支持頻率較低的無分組模式(最大工作頻率 = 667 MHz)。
QDR-IV XP 中較低的三個地址引腳(A2、A1 和A0)選擇了在讀或寫期間將要訪問的組。唯一的分組限制是在每個時鐘周期內該組僅能被訪問一次。QDR-IV XP SRAM 的組訪問規則要求在端口B 上訪問的組地址與在端口A 上訪問的組地址不相同。
如果不符合分組限制,那么由于在時鐘的上升沿時已經對讀/寫操作進行采樣,在端口A 上則不會限制讀/寫操作,但會禁止端口B 上的讀/寫操作。QDR-IV HP SRAM 并沒有任何分組限制。
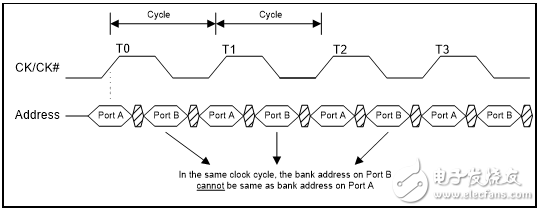
圖4. QDR-IV XP SRAM – 寫/讀操作
在相同的時鐘周期內,端口B上的組地址與端口A上的組地址不相同
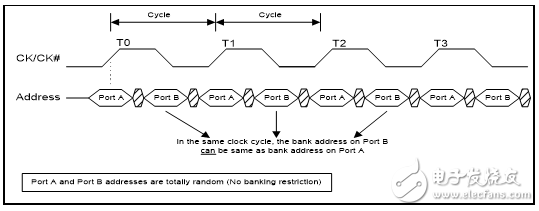
圖5. QDR-IV HP SRAM –寫/讀操作
QDR-IV XP SRAM 上的分組限制可作為某些應用的一個優點,在這些應用中,存儲器中的每一組都有不同的用途,并且都不能在同一個時鐘周期中被訪問兩次。一個網絡路由器能夠在QDR-IV XP SRAM 的每一組內儲存不同的路由表便是一個實例。如果在同一個時鐘周期內特定的路由表僅能被訪問一次,則有可能實現高TRT (隨機數據傳輸速率)。在該情況下,工作頻率為1066 MHz 時,可獲得的最高隨機數據傳輸速率為2132 MT/s。
分組限制不會影響到數據傳輸速率的另一種情況是使用物理層上的多個端口進行設計,通過每一個端口可以直接訪問存儲器中一組。這些端口將被復用到QDR-IV XP SRAM 的端口A 和端口B。在該設計中,因為每一個組都連接了物理層上不同的端口,因此任何一個組都不能在同一個時鐘周期內被訪問兩次。
不過,如果第一次訪問某一組是通過當前時鐘周期的下降沿上端口B 進行的,并且第二次訪問則是通過下一個時鐘周期的上升沿上端口A 進行的,那么可以在一個時鐘周期內再次對同一組進行訪問。如圖6所示,在進行寫操作期間,端口B 和端口A 都可以在一個時鐘周期內訪問組Y。同樣,在進行讀操作期間,端口B 和端口A 可以在一個時鐘周期內訪問組X。
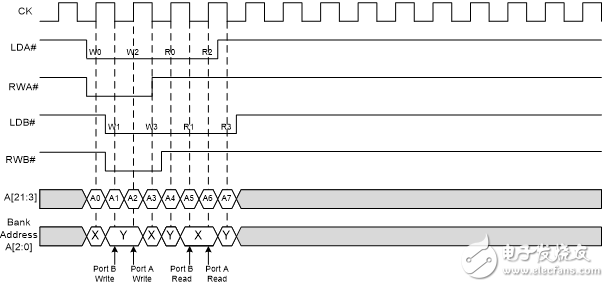
圖6. 在一個時鐘周期對同一個存儲器組進行訪問
總線轉換時間非常重要,其決定了讀和寫指令間是否需要額外的間隔來避免在同一個I/O 端口上發生總線沖突。
想象下QDR-IV HP SRAM 中端口A 先后收到寫指令和讀指令。從CK 信號的上升沿(與初始化寫指令周期相對應)算起,在整整三個時鐘周期后向DQA 引腳提供寫數據。讀數據則將在下一個周期發送,因為 DQ從CK 信號的上升沿(與初始化讀指令的周期相應)算起五個時鐘周期后才能獲得數據。此外,為符合總線轉換時間和傳輸時延(從ASIC/FPGA 到QDR IV 存儲器),還有兩個額外周期。因此,啟動寫指令后,可以立即啟動讀指令。
在其他情況下,如果先啟動讀指令后啟動寫指令,那么發送讀指令經過三個時鐘周期后,才能發送寫指令。這是因為,從在時鐘信號CK 的上升沿上對讀指令進行采樣算起,經過五個周期后可獲得DQA 引腳上的讀數據,并且從在時鐘信號CK 的上 升沿上對寫指令進行采樣算起,在整三個時鐘周期內向DQA 引腳提供寫數據。否則,將會發生總線沖突。因此,發送寫指令后的最小時鐘周期應該為RL – WL + 1(RL:讀時延;WL:寫時延;這兩個時延的單位為時鐘周期數)。另外一個時鐘周期用于正確捕獲數據并補償總線轉換時延(通常為一個時鐘周期)。
如果傳輸時延大于總線轉換時延,那么‘讀到寫’指令間的間隔為:
“讀到寫”指令間的時間周期 = 讀時延 – 寫時延 + 1 + 傳輸時延
請參考圖7。發送讀指令經過四個時鐘周期后,將發送端口A 的寫指令。這樣是為了避免因讀/寫時延、總線轉換時間和傳輸時延間的差別而導致的總線沖突。
總線翻轉
QDR-IV 器件支持總線翻轉以降低切換噪聲和I/O功耗。在存儲事務處理中,存儲器控制器和QDR-IV都可以選擇應用總線翻轉。
由于QDR-IV 器件的POD 信令模式為I/O 信號提供了到VDDQ 的高壓終端選項,所以信號轉為高電平邏輯狀態不會耗電。因此,總線翻轉對于POD I/O 信號是一個很重要的性能。QDR-IV 會保證翻轉地址和數據總線的數據完整性。
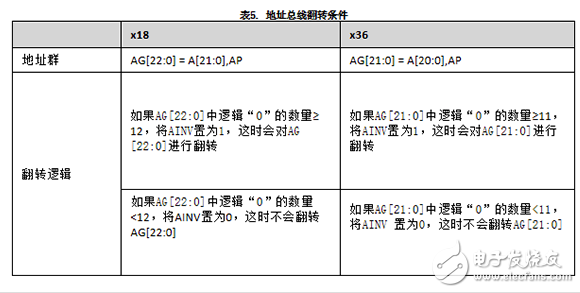
地址總線翻轉
AINV 是雙倍數據速率信號,每次將地址發送給存儲器器件時都會更新該信號。AINV 引腳指示是否對地址總線(An –A0)和AP 進行了翻轉。AINV 是高電平有效信號。當AINV = 1 時,將翻轉地址總線;當AINV = 0 時,不翻轉地址總線。AINV 引腳的功能由存儲器控制器控制。
地址總線和地址奇偶位都被視為地址組(AG)。
表5顯示的是AG 定義以及x18 和x36 QDR-IV 選項的AINV 設置條件。
x36器件示例
不進行地址總線翻轉:
假設要訪問的地址分別為22’h 000199和22’h 3FFCFF。17個地址引腳需要在第一個和第二個地址的邏輯狀態間進行切換,如下表所示(紅色單元格顯示)。這樣會增大地址引腳上的切換噪聲、I/O電流以及串擾。

進行地址總線翻轉:
根據表5顯示,第一個地址組(22‘h 000199)滿足翻轉邏輯條件。因此,存儲器控制器發送第一個地址組前,它會將地址組從22’h 000199翻轉為22’h 3FFE66,并將AINV引腳置為1。由于不需要翻轉第二個地址組,所以存儲器控制器可以將其直接發送,并將AINV設置為0。
下表顯示的是地址總線翻轉的結果。在這種情況下,只有5個地址引腳需要切換邏輯(紅色單元格顯示)。切換位的總數降低為5,所以降低了由于同時切換輸出(SSO)而引起的噪聲、I/O電流以及串擾。

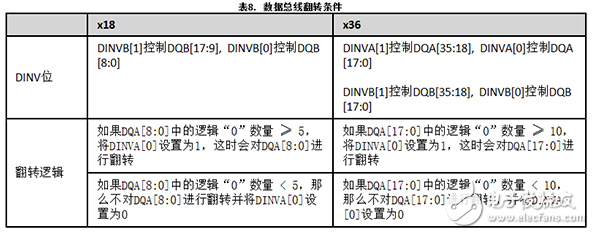
數據總線翻轉
數據總線翻轉在數據線路中也類似,但翻轉位由存儲器控制器在存儲器寫操作期間生成,并且翻轉位由QDR-IV存儲器中的翻轉邏輯在存儲器讀操作期間生成。
DINVA和DINVB引腳指示了是否翻轉相應的DQA和DQB引腳。DINVA和DINVB均為高電平有效信號。當DINV = 1時,將翻轉數據總線;當DINV = 0時,不翻轉數據總線。
DINVA[1]和DINVA[0]相互獨立并控制與其相應的DQA組。DINVA[0]控制DQA[17:0](對于x36的配置)或DQA[8:0](對于x18的配置)。DINVA[1]控制DQA[35:18](對于x36的配置)或DQA[17:9](對于x18的配置)。同樣,DINVB[0]控制x36配置中的DQB[17:0]或x18配置中的DQB[8:0]。DINVB[1]控制x36配置中的DQB[35:18]或x18配置中的DQA[17:9]。
表8顯示的是DINV位說明以及x18和x36 QDR-IV選項的DINVA設置條件。
注意:可以對DINVA[1]、DINVB[0]以及DINVB[1]使用相同的翻轉邏輯,以便控制相應的DQ組。
x18器件的示例
不進行數據總線翻轉:
假設需要分別發送DQA[8:0]上的9’h 007和9’h 1F3。6個數據引腳需要在第一個和第二個DQA[8:0]位的邏輯狀態之間進行切換,如下表所示(紅色單元格顯示)。這樣會增大數據引腳上的切換噪聲、I/O電流以及串擾。

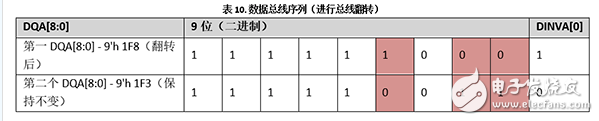
進行數據總線翻轉:
根據表8,第一個DQA[8:0]滿足翻轉邏輯條件。因此,存儲器控制器發送第一個DQA[8:0]前,它會將引腳地址從9’h 007翻轉為9’h 1F8,并將DINVA[0]引腳設置為1。由于第二個DQA[8:0]不需要翻轉,所以存儲器控制器可以直接發送它,并將DINVA[0]設置為0。
表10顯示的是數據總線翻轉的結果。在這種情況下,只有3個數據引腳需要切換邏輯(紅色單元格顯示)。切換位的總數降低為3,所以降低了SSO的噪聲、I/O電流以及串擾。
地址奇偶校驗
QDR-IV只有一條地址總線,但其以雙倍數據速率和高頻率運行。因此,地址奇偶校驗輸入(AP)和地址奇偶校驗錯誤標志輸出(PE#)引腳提供了片上地址奇偶校驗功能,以便能夠確保地址總線完整性。地址奇偶校驗功能是可選的;可以使用配置寄存器來啟用或禁用它。
通過該AP引腳可以在各地址引腳(An到A0)上進行偶校驗。設置AP值,使AP和An-A0中邏輯“1”的總數為偶數。
對于數據總線寬度為x18的器件,設置AP值,使A[21:0]和AP中邏輯“1”的總數為偶數。
對于數據總線寬度為x36的器件,設置AP值,使A[20:0]和AP中邏輯“1”的總數為偶數。
器件的示例
以數據總線寬度為x36的器件的21’h1E0000和21’h1F0000地址為示例。表11顯示的是如何為每個地址設置AP值。
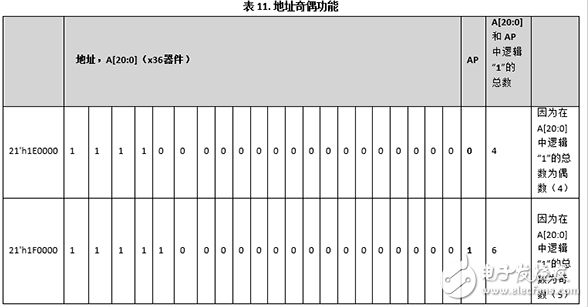
當發生奇偶錯誤時,在配置寄存器4、5、6和7中(請查看相關數據手冊,了解有關配置寄存器的更多信息)記錄第一個錯誤的完整地址以及端口A/B錯誤位和地址翻轉位。端口A/B錯誤位表示發生地址奇偶錯誤的端口:0表示端口A,1表示端口B。持續鎖存該信息,直到向配置寄存器3中的地址奇偶錯誤清除位寫入1來清除該信息為止。
通過兩個計數器,可以表示是否發生了多個地址奇偶錯誤。端口A錯誤計數是端口A地址上奇偶錯誤數量的運行計數器。同樣,端口B錯誤計數是端口b地址上奇偶錯誤數量的運行計數器。每個計數器獨立計數到最大值(3),然后將停止計數。這些計數器均是自由運行的;對配置寄存器3的地址奇偶錯誤清除位寫入1,可將其復位。
檢測到地址奇偶錯誤后,寫操作就會被忽略,以防止損壞存儲器。但是,如果輸入地址錯誤,仍會繼續執行讀操作,但存儲器會發送出假數據。
PE#為低電平有效信號,表示地址奇偶錯誤。檢測到地址奇偶錯誤后,PE#信號在8個周期(QDR-IV XP SRAM)或5個周期(QDR-IV HP SRAM)內被設置為0。它將保持置位狀態,直到通過配置寄存器清除了錯誤為止。處理完地址翻轉便表示完成了地址奇偶檢查。
PE#轉為低電平后,會停止存儲器操作,并使用配置寄存器將PE#復位為高電平。此外,由于發生AP錯誤的寫操作也被阻止,所以需要向存儲器重新編寫數據。
校正訓練序列
存儲器控制器和QDR IV較高的工作頻率意味著數據有效窗口很窄。QDR-IV器件支持“校正訓練序列”,它可通過減少字節通道之間的偏差擴大這個窗口,從而在控制器讀取存儲器的數據時,增加時序余量。校正訓練序列是賽普拉斯的QDR-IV SRAM的初始化過程的一部分。該訓練序列通常被那些不支持內置校正功能的應用使用。
訓練序列如圖8所示:
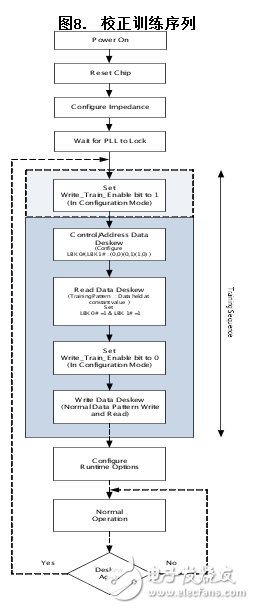
校正訓練序列是初始化過程的一部分。對序列進行加電和復位后,在配置模式下進行操作的過程中,控制器必須立即設置選項控制寄存器中的Write_Train_Enable位(位的位置:7)。通過該操作,控制器可以避免在進行訓練序列前再次進入配置模式。設置該位不會影響到校正訓練序列,直到進行讀取數據校正訓練為止。
通過以下三個步驟,可以實現校正過程:
1.控制/地址校正
2.讀取數據校正
3.寫入數據校正
控制/地址校正
根據需要校正的信號,將LBK0#和LBK1#設為它們相應的位值。請查看表12,了解環回信號的映射情況。39個輸入信號被環回到端口A上的數據引腳。根據LBK0#和LBK1#的狀態,一次將13個輸入信號映射到DQA0-DQA12。
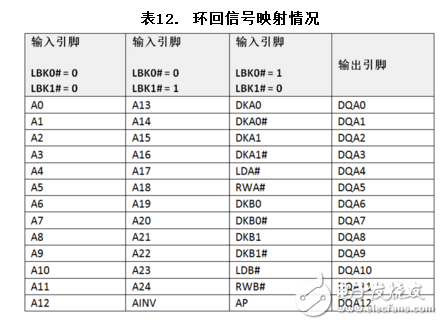
DKA0、DKA0#、DKA1、DKA1#、DKB0、DKB0#、DKB1和DKB#1等時鐘輸入都是自由運行的,并應在訓練序列中持續運行。
通過使用輸入時鐘(CK/CK#)可在上升沿和下降沿上對每個輸入引腳進行采樣。在輸出時鐘(QKA/QKA#)的上升沿上采樣的輸出值即為在輸入時鐘的上升沿上所采樣的值。在輸出時鐘(QKA/QKA#)的下降沿上采樣的輸出值即為在輸入時鐘的下降沿上所采樣的翻轉值。在這種模式下,數據翻轉無效,在進行地址/控制環回訓練過程中,CFG#信號將為高電平。
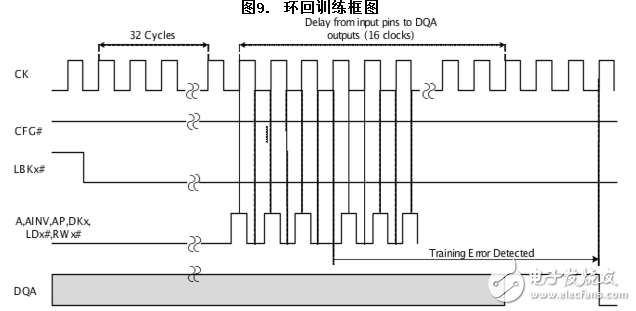
如圖9所示,如果地址/控制信號未校正,DQA 上的信號(應在訓練期間保持高電平)將變為低電平。該信號轉換應由驅動信號的模塊捕獲,控制器則會對信號相應進行校準。
讀取數據校正
在該階段,地址、控制和數據輸入時鐘都已經得到了校正。在讀取數據校正過程中,用于寫入存儲器內的訓練數據模型是一個常量值(D00,D01,D20,D21),如下面的波形框圖中顯示。在此訓練序列中,LBK0#和LBK1#均被設置為1。
配置選擇控制寄存器時,Write_Train_Enable 位將被設置為1。第一個和第二個數據突發均在同一個數據總線上被采樣的,但第二個數據突發則在寫到存儲器內前完成采樣的。Write_Train_Enable 位不會對讀取數據周期產生任何影響。
將數據模型寫到存儲器內后,標準的讀指令允許控制器訪問這些數據,并會校正QK/QK#信號。當 Write_Train_Enable = 1 時,在寫入過程中,DINVA/DINVB 將被忽略,在讀取過程中,它將始終切換。
如下面的讀取數據校正框圖中所示,寫入到存儲器內的數據(D00、D01、D20、D21)全為1,相應的讀取數據(Q00、Q01、Q20、Q21)則在1 和0 間切換。控制器必需捕捉到這些切換數據并進行驗證。否則,控制器需要一個精確的校準來確認讀取數據校正。
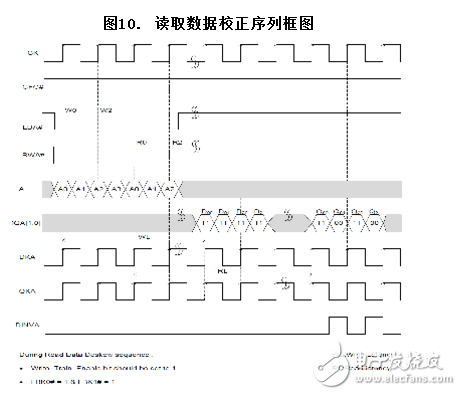
在讀數據校正序列中:
l設置Write_Train_Enable位為1
lLBK0# = 1 及LBK1# = 1
寫數據校正
此時,地址、控制、時鐘和數據輸出都已經得到了校正。執行寫入數據校正序列前,先再次進入配置模式,然后通過將相應位設置為0來禁用Write_Train_Enable。
在正常工作模式下,使用讀指令后,通過使用存儲器的寫指令可校正寫數據。所校正的讀取數據路徑用于確認器件是否已經正確地接收到寫入數據。這樣使處理器/FPGA能夠校正下列與DK/DK#輸入數據時鐘有關的信號:DQA、DINVA、DQB和DINVB。
糾錯碼(ECC)
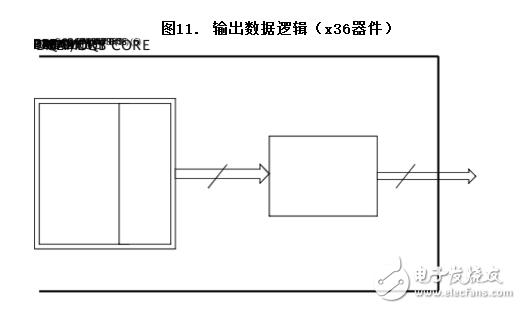
系統設計人員必需依賴片外糾錯或冗余等技術提高可靠性。這些技術會增加PCB空間或處理時間方面的開銷。QDR-IV是一個單芯片解決方案,引入了片上糾錯碼(ECC),從而節省了空間和成本,降低了設計復雜性。此外,它還降低了QDR-IV存儲器陣列的總軟失效率(SER)。該特性可應用于數據總線寬度為x18和x36的選項,并在SRAM中始終被啟用。ECC保護提供了單比特糾錯(SEC)。
QDR-IV從輸入數據生成ECC奇偶校驗位,并將它們存儲在存儲器陣列中。存儲器陣列包含用于存儲ECC奇偶校驗的額外位。但是,不會將這些額外的內部校驗位用于外部引腳。
例如,圖11顯示的是x36器件的輸出數據邏輯框圖。36數據位需要6個ECC校驗位;存儲器內核會將42位(36個數據位 + 6個 ECC校驗位)傳輸到ECC邏輯內。因此,ECC邏輯會提供已糾正的36位輸出數據。
無ECC位的QDR/DDR SRAM的SER故障率(FIT)通常為200 FIT/Mb。但帶有ECC時,該數值將為0.01 FIT/Mb,提高了4個數量級。
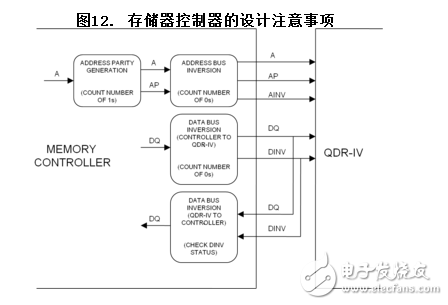
QDR-IV存儲器控制器的設計建議
本節提供一些存儲器控制器啟用QDR-IV的地址奇偶校驗和總線翻轉功能的設計建議。
存儲器控制器首先要根據地址總線生成地址奇偶。然后,需要在地址總線和地址奇偶位上進行地址翻轉。
對于數據總線轉換,將數據發送給QDR-IV前,存儲器控制器需要計算每個DQ總線上的邏輯“0”的數量,以便生成相應的DINV位(取決于數據總線翻轉條件)。
將數據發送給存儲器控制器時,QDR-IV使用相同的數據總線翻轉邏輯。為了識別QDR-IV的接收數據,控制器僅要檢查相應DINV位的狀態。如果控制器接收DINV = 1,需要翻轉相關的數據總線;否則,保持接收到的數據位不變。
圖12顯示的是存儲器控制器的設計注意事項。












 工商網監
工商網監
評論