 電子發燒友App
電子發燒友App


可編程數據平面從根本上改變網絡元素的構建和管理方式,也在一定程度上平衡了靈活性和性能之間的矛盾,這種平衡行為的關鍵是對數據包處理的良好抽象。數據包處理的常見抽象是匹配動作流水線,最早由OpenFlow提出。通過匹配動作抽象,可以將包處理器建模為一系列匹配和動作流水線階段。每個流水線階段對流經的數據包執行不同的操作。這種抽象可以映射到FPGA和下一代ASIC。
在這種情況下,與平臺和體系結構無關的P4語言應運而生。為支持P4語言,可編程數據平面大都采用可重配置匹配動作表(Reconfigurable Match Tables,RMT)抽象轉發模型,定義了可編程解析、可編程匹配與可編程動作等數據包處理行為,而使用P4編程語言,可以快速簡便地對數據包處理行為進行描述。
因此,在人們的印象中,提到P4語言,大腦中就自動出現解析器、逆解析器和多級流表的架構,想到了Barefoot的Tofino芯片。認為解析器、逆解析器加多級Match Action流表的架構就是P4語言唯一硬件架構。然而,實際上,除了這種架構外,還有好幾種其它的實現架構。
比如在今年8月下旬即將召開的SIGCOMM會議上,MIT和Juniper的研究人員聯合發表了一篇介紹Trio芯片架構的文章,Trio芯片就不是采用流水線架構來實現對P4語言支持的。文章主要面向新的應用場景與傳統的PISA流水線架構的交換芯片的性能進行對比,現將該文章部分譯文奉上,以饗讀者。感興趣的讀者也可以提前閱讀扎神的文章《Trio 6, Express 5 and Silicon One》以更全面了解相關內容和背景。
本文介紹了Trio,一種用于瞻博(Juniper)網絡MX系列路由器和交換機的可編程芯片組。Trio的架構基于一個多線程的可編程數據包處理引擎和一個分層的大容量內存系統,這使得它與基于流水線的架構有著根本的不同。Trio可以優雅地處理各種網絡用例和協議的非同質包處理率,使其成為新興網絡內應用的理想平臺。
我們首先描述了Trio芯片組的基本構件,包括其多線程的包轉發和包處理引擎。然后,我們討論Trio的編程語言,稱為微代碼。為了展示Trio靈活的基于Microcode的編程環境,我們描述了兩個使用案例。
首先,我們展示了Trio為分布式機器學習執行網絡內聚合的能力。其次,我們提出并設計了一種使用Trio的定時器線程的網絡內滯留者緩解技術。我們在測試平臺上使用三個真實的DNN模型(ResNet50、DenseNet161和VGG11)對這兩個用例進行了原型測試,以證明Trio在執行網絡內聚合的同時緩解串擾的能力。我們的評估表明,當集群中出現散工問題時,Trio的性能比目前基于流水線的解決方案高1.8倍。

01?引言
數據密集型應用是當今在線服務的基礎。隨著摩爾定律的逐漸放緩,硬件加速器正在努力滿足新興云應用的性能需求,如機器學習、數據庫、存儲和數據分析。進一步的進展明顯受到單臺服務器所能容納的計算量和內存的限制,推動了數據密集型應用對高效分布式系統的需求。 可編程交換機的出現,如英特爾的Tofino[2, 20, 22],為設計新的包處理協議和編譯器創造了機會[17, 20, 24, 44, 45, 58, 69, 71]。Tofino交換機也為使用網絡內計算[23, 60, 74]來加速應用鋪平了道路,如緩存[43]、數據庫查詢處理[50, 73]、機器學習訓練[36, 48, 55, 63, 77]、推理[76]和共識協議[27, 28, 52]。網絡內計算的關鍵思想是利用交換機的獨特優勢,直接在網絡內進行部分計算,從而減少延遲,提高性能。 ? 盡管可編程交換機一直是這種新模式的重要推動者,但獨立于協議的交換機架構(PISA)[2, 20, 22, 58]往往不適合新興的網內應用,從而限制了進一步發展,阻礙了網內計算應用的廣泛采用[35, 37, 67]。 ? 本文介紹了Trio的網絡內計算可編程架構。Trio是瞻博網絡的可編程芯片組,擁有數十億美元的預存客戶群。它已被部署在全球核心、邊緣和數據中心環境中的數十萬臺路由器和交換機中。Trio芯片組在生產設備中使用已超過十年。 ? Trio建立在一套定制的處理器內核上,其指令集針對網絡應用進行了優化。因此,該芯片組具有傳統ASIC的性能,同時享有完全可編程處理器的靈活性,允許通過軟件安裝新功能。Trio的靈活架構使其能夠支持在芯片組發布后很長時間內開發的功能和協議。Trio處理器內核可以訪問一個高性能的大內存系統,以存儲與系統配置和數據包有關的數據和狀態。該內存系統對具有大內存足跡的新興應用的可擴展性至關重要。 ? Trio的結構與Tofino的結構有根本的不同。Trio有一個非流水線結構,因此不同的數據包不一定流經芯片上的相同物理路徑。Trio中的入站數據包是使用成千上萬的并行線程獨立處理的(詳情見2)。這些線程使用運行-完成模型[12, 70],其中一個線程將執行所需的指令,以完成它目前正在處理的數據包的處理。Trio有專門的邏輯,以確保同一流量的數據包按順序交付,但不同流量的數據包可以不按順序處理,使其能夠有效地處理混合的并發應用。 ? 因此,Trio可以優雅地處理不同的數據包處理率:它可以為需要豐富的每包處理的應用提供低于線速的支持,同時為具有簡單的每包處理需求的應用保持線速。相比之下,基于PISA的交換機在處理數據包時,處于同一流水線的數據包需要遍歷流水線的各個階段,無論P4程序是怎樣的;P4程序[19]的部署只有完全成功和完全失敗兩個結果,基于PISA的交換機無法支持靈活的數據包處理速率,以可編程性為代價,換取數據包的線速處理能力。 ? 在本文中,我們首先描述了Trio芯片組的基本構件,包括其數據包處理引擎和周圍的內存系統的細節(2)。接下來,我們描述了Trio的編程語言,稱為Microcode(3)。然后,我們以機器學習訓練的網絡內聚合作為第一個用例,解釋Trio靈活的Microcode設計(4)。我們將網絡中的串擾緩解作為第二個用例,以證明Trio在啟動高效的基于定時器的線程方面的獨特能力(5)。我們證明了在Trio中實現滯留者緩解是直接的,而據我們所知,在基于PISA的設備中實現高效的滯留者緩解是具有挑戰性的,甚至是不可能的。 ? 我們在一個帶有Juniper MX480設備[10]、一個64個100Gbps Tofino交換機和六個華碩ESC4000AE10服務器的測試平臺上實現這兩個用例,每個服務器都有一個A100 Nvidia GPU[11]和一個100Gbps Mellanox ConnectX5網卡。我們訓練三個DNN模型(ResNet50[41]、DenseNet161[42]和VGG11[68]),以證明Trio在執行網內聚合的同時減輕散兵線的能力。我們的評估表明,當集群中出現散工時,Trio比最先進的網內聚合平臺SwitchML[63]的性能高出1.8倍。 ? 瞻博網絡將繼續發展Trio芯片組,為現有和新興應用提供更高的帶寬、更低的功耗和更多的功能,同時還將開發軟件基礎架構以支持更多的使用案例。我們邀請網絡界確定能夠利用Trio可編程架構的新用例。 ? ?
02?Trio的結構
自2009年推出以來,Trio芯片組已經經歷了六代[16],具有各種性能點和架構。本節詳細介紹了Trio的最新架構。首先,我們對基于Trio的路由器1中的數據包轉發和處理做了一個高層次的概述。然后,我們轉向Trio的數據包處理引擎的細節。最后,我們解釋Trio的各種內存類型和讀-改-寫操作。
1 、基于Trio的路由器體系結構
圖1說明了基于Trio的路由器(或交換機)與基于PISA的交換機之間的高層區別。每個基于Trio的設備都有兩個重要的組成部分:(i)包轉發引擎和(ii)包處理引擎,下面將介紹。 ?
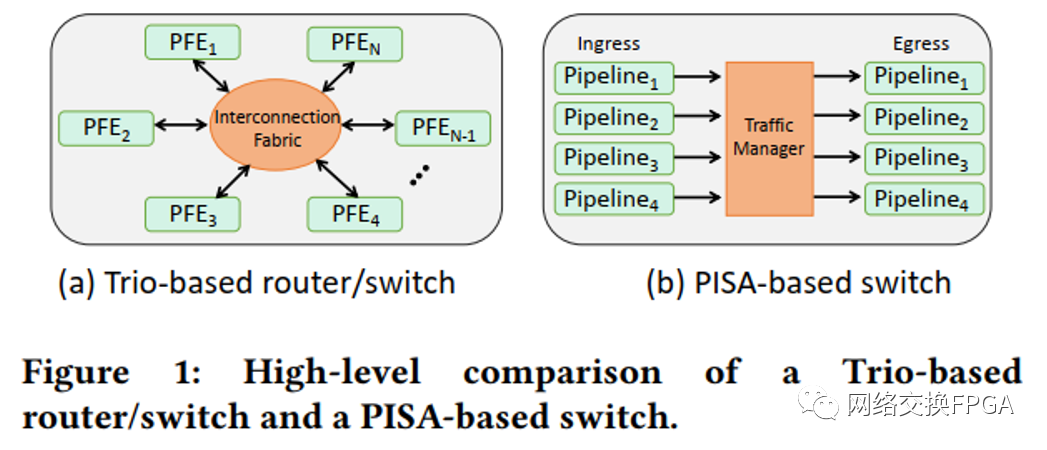
? 數據包轉發引擎(PFE)。PFE是Trio轉發平面的中心處理元素,用于系統地將數據包移入和移出設備。一個基于Trio的設備由一個或多個PFE組成。根據不同的年代,每個Trio芯片組支持不同的數據包處理帶寬。Trio的第一代PFE用多個芯片支持40Gbps的網絡帶寬。今天,Trio的第六代PFE在單個芯片中支持1.6 Tbps。小型路由器可能只有一個PFE,而大型路由器則有多個PFE,通過互連結構連接,如圖1(a)所示。通過在PFE之間提供any-to-any的全互連連接,互連結構擴大了設備的帶寬,遠遠超過了單個芯片所能支持的范圍。每個PPE在入口和出口方向上都處理數據包。數據包通過一個入口PFE到達系統,并通過一個出口PFE離開。 ? 包處理引擎(PPE)。每個PFE都有數百個多線程的包處理引擎(PPE),如圖2所示。每個PPE支持幾十個線程同時處理不同的數據包。與Tofino的架構不同,流水線不能訪問對方的寄存器,一個PFE中的PPE線程可以通過共享內存有效地共享狀態。第2.2節更詳細地解釋了PPE的基于線程的設計。 ?
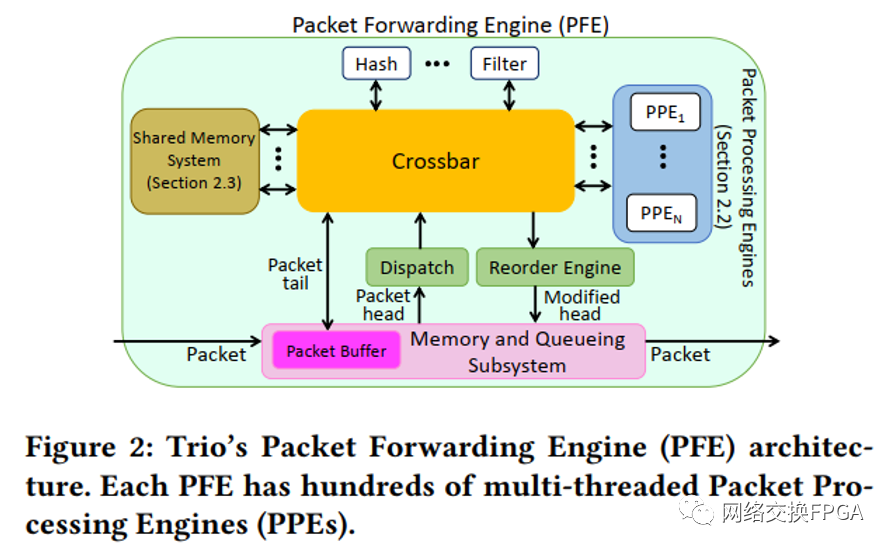
? ? 平行數據包處理。PFE的硬件邏輯自動將每個進入的數據包分為頭和尾部分(類似于PISA的頭和有效載荷)。數據包頭是數據包的第一部分,通常大到足以容納處理數據包所需的所有數據包頭(每一代Trio設備的數據包頭大小不同,但通常約為200字節)。尾部由數據包的剩余字節組成(如果有的話)。當一個新的數據包到達時,PFE內部的一個硬件模塊,稱為調度模塊,根據可用性將數據包頭發送到PPE進行處理,PPE為這個數據包頭生成一個新線程。數據包尾部被保存在PFE的內存和隊列子系統中的數據包緩沖區,以避免在PPE線程中存儲大量的字節。默認情況下,每個線程在一個數據包上工作。許多PPE線程并行工作以提供所需的處理帶寬。 ? 重新排序引擎。當數據包處理完成后,修改后的數據包頭被發送到重新排序引擎。重排引擎保留更新的包頭,直到同一流程中所有較早到達的數據包都被處理,以確保按順序交付。然后,Reorder Engine將修改后的數據包頭發送到內存和排隊子系統,以便排隊傳輸。 ?
2、包處理引擎
Trio的PPE提供了固定處理流水線或現有專門處理單元難以或無法實現的功能。每個PPE都是一個VLIW(超長指令字)多線程的微碼引擎核心。每個微指令都控制著多個ALU、操作數和結果選擇,以及復雜的多路分支。執行一個微指令所需工作的復雜性意味著每個指令需要多個時鐘周期。因為每個PFE通常同時為許多數據包提供服務,所以一個PPE不需要高的單線程性能。Trio中的每個線程一次只有一條數據通路指令。Trio不會將同一線程上的指令與前一條指令分派到PPE流水線中,直到后者退出流水線。因此,不需要在同一線程的指令之間傳遞數據,因為在數據回寫完成之前,后續指令不依賴于前一指令的結果。
PPE線程。一個PPE線程通常在數據包頭到達PPE時啟動,并在該PPE對該數據包的處理完成后銷毀。線程的銷毀由芯片中的硬件邏輯自動處理,盡管程序員可以控制何時放棄線程的執行。線程也可以響應某些內部事件而啟動,包括統計收集和定時器(更多細節見5)。外部事件有能力通過類似的機制來催生新線程的執行。入口和出口PFE中的PPE共同處理處理數據包所需的所有功能(例如,數據包解析、路由查找、數據包重寫)。
每線程本地存儲。每個PPE有兩種主要的內部存儲形式。首先,每個線程有一個專用的本地存儲器池(1.25 KBytes)。本地存儲器可以在任何字節邊界訪問,使用指針寄存器或微指令中包含的地址。在一個PPE線程啟動之前,數據包頭被加載到該線程的本地存儲器中。當發送數據包時,修改后的數據包頭會從線程的本地存儲器中卸載。指針寄存器的使用允許對包頭以及其他類型的數據結構進行有效的訪問。其次,每個線程都有32個64位的通用寄存器,這些寄存器對它是私有的。
本地存儲(內存和寄存器)持有正在處理的數據包的特定信息。跨包的共享狀態被保存在所有PPE都可以訪問的共享內存系統中。
ALU類型。有兩種ALU類型:(i)條件ALU和(ii)移動ALU。條件ALU用于算術或邏輯運算,產生32位數據結果和/或用于比較運算,產生1位條件結果。移動ALU產生32位的結果,可以寫進寄存器或本地存儲器。來自條件ALU的結果可以作為移動ALU的輸入。這種ALU組織允許每個指令的資源在排序控制(接下來描述)和生成邏輯/算術結果之間靈活分配,以存儲在寄存器/存儲器中。
重要的是,每個ALU操作數和每個移動ALU結果可以是一個任意長度的位域(最多32位)和一個任意的位偏移。這有兩個主要的好處。首先,它提高了訪問包頭中不同大小的字段的效率。第二,它提高了內存和寄存器容量的利用率,使每塊數據只使用它所需要的比特。Trio在PPE和共享內存系統中都有ALU。前者用于對寄存器和本地存儲器的操作,而后者則用于對存儲在共享存儲器系統中的數據進行操作。通過將數據包尾部的部分移動到PPE線程的本地存儲器,也支持對數據包尾部的操作。
排序邏輯。一個或多個條件ALU的條件結果可以被排序邏輯單元用來選擇下一個要執行的微指令。每個微指令包括一個至八個微指令的目標塊的地址。任何或所有的條件結果都可以被忽略,所使用的條件結果的組合也非常靈活。數據包處理中的許多工作涉及代碼中復雜的條件分支,特別是在解析期間。Trio在一條指令中執行復雜的多路分支的能力與數據包處理應用的需求非常匹配。PPE支持對子程序的調用-返回機制,子程序可以嵌套到八層深處。
高效的哈希計算。高效的負載平衡是所有路由器/交換機的一個重要要求。在一個基于Trio的系統中,一個Microcode程序負責指定哪些數據包字段被包括在哈希計算中。這使得哪些數據包字段有助于負載平衡的決定具有完全的靈活性,包括從協議尚未發明的數據包頭中選擇字段的能力。Trio中的哈希函數是一個使用專用邏輯實現的高質量哈希函數。因此,哈希函數的實現比用軟件實現的類似哈希函數更有效。可編程字段選擇和硬接線哈希函數的結合,使PPE在靈活性和效率方面達到了前所未有的平衡。
靈活的編程。對PPE可處理的報頭數量或類型沒有固定限制。因此,PPE可以使用Trio的微碼程序(3)輕松創建新的報頭或消耗/刪除數據包中的現有報頭。隨著新協議的開發,Trio數據包處理架構可以通過增強運行在PPE上的軟件來適應。由于PPE的多線程結構,PPE還可以創建或消耗數據包來完成任務,如保持功能,其速度遠遠高于控制平面CPU所能支持的速度。重要的是,處理周期在不同的應用之間是可以互換的,從而能夠優雅地處理不同應用的數據包處理要求。因此,基于Trio的系統可以為數據包處理較豐富的應用提供較低的數據包速率,為數據包處理較簡單的應用提供較高的數據包速率,或兩者混合使用。
3、共享內存系統
最近的Trio芯片組在每個PFE中支持幾個GBytes的內存。本節對Trio的共享內存系統進行了概述。 共享內存的優點。對于交換機和路由器來說,一些數據結構,如計數器和(流量)管制器,需要以很高的速度修改。為了支持數百個PPE線程對這些數據結構的有效訪問,Trio的共享內存系統成為所有線程訪問和修改數據的地方。
所有對共享內存系統的數據訪問(讀、寫和讀-修改-寫)都由位于共享內存系統附近的讀-修改-寫引擎處理。當多個線程在同一時間訪問同一內存位置時,不需要將數據從一個線程移到另一個線程。相反,數據修改發生在讀-修改-寫引擎內部。這允許在內存附近高速更新數據,很好地滿足了數據包處理應用的需要。
相比之下,傳統處理器使用的基于緩存線的一致性模型需要在訪問過程中把數據移到線程中;當多個線程試圖修改同一內存位置時,這會造成較長的延遲。雖然這種模型可以支持對數據進行更復雜和更普遍的操作,但對于可以被數百個線程訪問的數據結構來說,它的表現很差。
內存類型。Trio存儲器系統經過優化,為相對較小(8字節)的請求提供了較高的訪問速率。為了實現所需的帶寬、延遲和容量的組合,存儲器系統使用兩種類型的存儲器,如圖3所示:(i)高帶寬的片上存儲器,從PPE的訪問延遲約為70ns;(ii)基于DRAM的大型高帶寬片外存儲器,從PPE的訪問延遲約為300 ns至400 ns。片上存儲器是由一個嚴重的多槽SRAM實現的,通常用于頻繁訪問的數據結構。
片外存儲器有一個幾百萬字節的片上緩存,它與片上SRAM類似,并且是大量的多Bank,以提供高吞吐量。片上SRAM和片外DRAM緩存的大小是可以軟件配置的(通常分別為2-8 MBytes和8-24 MBytes)。片外DRAM是幾GB字節。片內和片外存儲器在結構上是等同的,存在于一個統一的地址空間的不同范圍內。它們只在容量、延遲和可用帶寬上有所不同。這使得數據結構可以被放置在最符合其容量和帶寬要求的存儲器類型中。
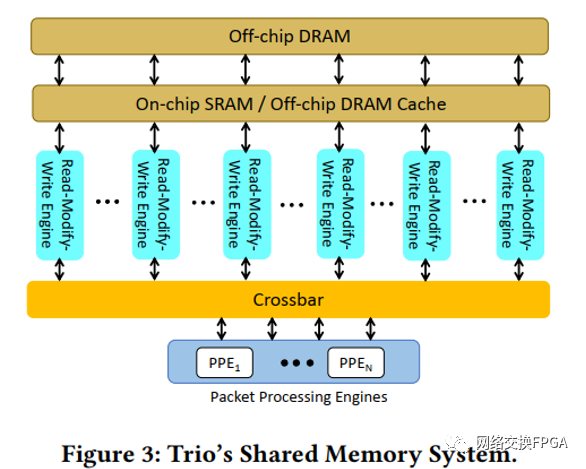
? 內存交易。內存系統支持不同大小的讀寫操作,從8字節到64字節(以8字節為增量)。Trio可以用8字節的訪問來支持全部的內存系統帶寬。此外,還支持豐富的讀-改-寫操作,包括數據包/字節計數器、Policers、邏輯獲取和操作(And/Or/Xor/Clear)、獲取和交換、屏蔽式寫入和32位添加。讀-修改-寫操作由讀-修改-寫引擎啟用,具體規定如下。
讀-修改-寫引擎。數據包處理需要極其高速的讀-修改-寫操作。處理一個數據包可能涉及到對多個計數器的更新,對一個或多個策略器的操作,以及應用程序需要的其他操作。處理讀-改-寫操作的天真方法是,在操作進行時,讓一個線程擁有一個內存位置的所有權。但這種方法不能滿足數據包處理的高效率要求。相比之下,Trio將讀-改-寫操作卸載到它的內存系統中,由一個讀-改-寫引擎來處理一系列的內存位置。
如果對同一內存位置的多個請求在同一時間到達,該引擎將依次處理這些請求,以保證更新的一致性。在混合讀、寫和讀-修改-寫操作時,不需要向內存中的某個位置發出明確的一致性命令。每個讀-改-寫引擎以每個時鐘周期8字節的速度處理內存請求。因此,整個共享內存系統的單個讀-修改-寫引擎不能提供足夠高的速率處理數據包所需的內存帶寬。為了應對這一挑戰,Trio支持幾組SRAM和片外緩存,并有自己的讀-修改-寫引擎,使讀-修改-寫處理帶寬能夠與原始內存帶寬一起擴展。
Crossbar和共享內存性能。Trio的Crossbar被設計為支持所有的讀-修改-寫引擎,因此Crossbar本身不會限制內存性能。如果提供給某個讀-改-寫引擎的負載超過了每周期8字節的吞吐量,就會通過Crossbar產生背壓。瞻博網絡在每一代Trio芯片中都增加了讀-改-寫引擎的數量,以便內存帶寬隨著數據包處理帶寬的增加而增加。
03?Trio的編程環境
本節對Trio的編程環境進行了概述。第1節描述了Trio的編程語言和基于Trio設備的編程工具鏈。第2節提供了一個用Trio微代碼編程的數據包過濾例子。 ?
1、Trio的編程語言和工具鏈
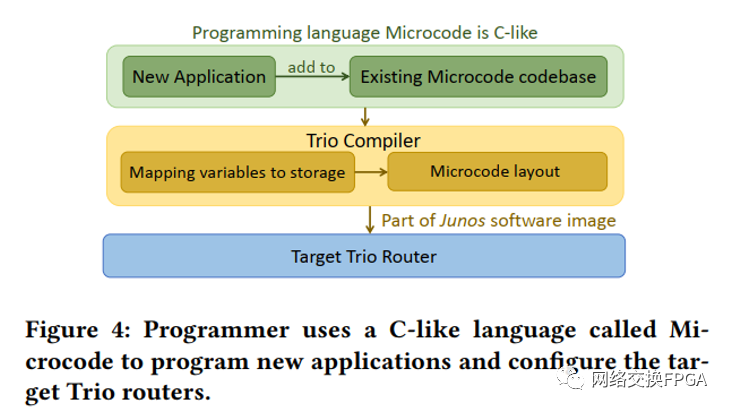
基于Trio的設備的編程語言是一種叫做Microcode的類C語言。程序員在Microcode中實現所有的數據包處理操作,包括數據包解析、路由查找、數據包重寫和網絡內計算(如果有)。圖4顯示了在Trio上為新的應用程序編程所需的工具。要在Trio上編程一個新的應用程序,程序員使用Microcode語言來編寫新的應用程序,并將新的Microcode程序添加到現有的代碼庫中。然后,程序員使用Trio的編譯器生成軟件圖像并配置目標設備。 ?
表達式語法。Microcode支持C風格的表達式。支持的變量類型包括標量(label, bool, 和不同大小的整數)和復合(struct 和union)。Microcode還支持指針和數組,條件,函數調用和Gotos,以及switch語句。 指令邊界。一個Microcode程序有多個指令。一條Microcode指令可以執行有限的操作,程序員需要明確指定指令的邊界。通常情況下,一條Microcode指令可以執行四個寄存器或兩個本地存儲器的讀取,以及兩個寄存器或兩個本地存儲器的寫入。
變量存儲類。當在Microcode中定義一個新的變量時,程序員需要指定存儲該變量的位置。有三種類型的變量存儲類:內存(PPE的本地內存和寄存器),總線(表示變量作為ALU的輸入),和虛擬(表示常量值)。對存儲在共享內存系統中的數據的訪問,如轉發表,是通過下面規定的外部事務實現的。
外部交易。PPE可以通過Crossbar向其他模塊發出外部事務(XTXN),如共享內存系統、哈希查找/插入/刪除、高性能過濾器和計數器/警戒器塊。這些XTXN可以是同步的或異步的。在同步XTXN中,PPE線程被暫停,直到收到XTXN回復;在異步XTXN中,PPE線程繼續正常運行。PPE也可以通過XTXNs從數據包尾部獲取數據。在這種情況下,數據包尾巴從內存和隊列子系統發出,通過Crossbar,然后到達PPE的本地內存。
一個XTXN由PPE向目標發出的請求和目標向PPE發回的回復組成。XTXN的格式取決于目標塊。例如,發送到共享內存系統的讀取請求以內存地址為參數,數據在XTXN響應寄存器中返回。 編譯器。為了編譯Microcode程序,程序員使用一個叫做Trio Compiler(TC)的工具。TC將指令的源代碼映射到指令可以控制的各種資源,包括將變量映射到它們的底層存儲,并將指令分配到PPE內的Microcode內存。TC同時具有編譯器和匯編器的特點。在編譯器方面,TC支持將高級C風格的表達式翻譯成硬件指令。
在匯編器方面,TC的源代碼必須包含指令的劃分,即程序員標記代表一條指令的代碼塊的開始和結束。如果指定給一條指令的代碼不合適,TC的編譯就會失敗,因為它不能在多條指令中實現要求的動作。TC沒有一個單獨的編譯和連接階段。它需要完整的源代碼而不是單個模塊來生成二進制文件。這個二進制文件包含初始化PPE資源的數據,如Microcode內存和本地內存。它還定義了所需的符號,如本地內存中數據包頭開始的地址。該二進制文件是Trio的ASIC驅動程序用于設備初始化的Junos2軟件鏡像的一部分。
vMX虛擬路由器。瞻博網絡正在共同努力,使第三方能夠訪問基于Trio的設備編程。作為第三方訪問Trio功能的第一步,瞻博網絡開發了vMX虛擬路由器[5]。vMX是一個虛擬化的通用路由平臺,由一個虛擬控制平面(VCP)和一個虛擬轉發平面(VFP)組成。VCP由Junos操作系統驅動,VFP運行為x86環境優化的Microcode引擎。vMX可作為授權軟件,部署在基于x86的服務器和云服務上,如亞馬遜網絡服務。
高級轉發接口。在Trio中,數據包轉發是一個由PFE執行的操作序列。每個操作都可以用潛在包轉發操作圖上的一個節點表示。PFE根據單個數據包的類型/字段,為其執行一系列操作。瞻博網絡高級轉發接口(AFI)[3]提供了部分可編程性,允許第三方開發者通過一個稱為沙盒的小型虛擬容器控制和管理這個轉發路徑圖的一部分。該沙盒使開發者能夠添加、刪除和改變特定數據包的操作順序。
2、Microcode程序示例(略)
04?Trio討論和未來的用例
Trio用于網絡內遙測。大多數網絡運營商需要遙測或深入了解其網絡中的流量,以便進行容量規劃、服務級協議監測、安全緩解和其他用途。目前的網絡設備通常依靠數據包采樣,使用設備中嵌入的內部處理器或外部監測設備進行進一步處理。由于通過設備的流量很大,而可用于監測的處理和帶寬有限,只有一小部分數據包(幾萬分之一或更少)被選中進行監測,而且采樣數據包的決定往往是盲目的,基于一個簡單的時間間隔[62]。Trio的數據包處理的靈活性和操作資源的可用性使其適合網絡內遙測。例如,服務提供商可以利用Trio的大內存來跟蹤傳入的數據包,以保持足夠的信息用于遙測。此外,Trio的定時器線程適用于定期監測和異常分析。為了給網絡運營商提供更智能的遙測,可以根據Trio已經提取的用于路由的數據包字段,對每個數據包執行基于機器學習的分類技術。最后,數據結構可以更有效地存儲,從而減少外部監測設備的傳輸帶寬和處理周期。
Trio用于網絡內安全。為了減輕DDoS攻擊,基于Trio的MX系統支持識別和丟棄惡意數據包的功能,充分利用了芯片組的高性能和靈活的數據包過濾機制。Trio還在SRX安全平臺上充當基于安全流的快速轉發路徑[1]。Trio能夠對傳入的數據包進行額外的復雜的網絡內安全處理,通過聚合特征或對服務提供商安裝的ML模型進行推理,以識別和緩解流量中的異常情況。與基于設備的解決方案不同,Trio在網絡數據通路上進行異常檢測的可編程架構可實現低延遲的威脅緩解。 ? Trio-ML中的數據包丟失。運行各種不同應用的數據中心可能會出現瞬時流量高峰,而這又可能導致聚合數據包丟失。一個實用的網絡內聚合系統需要一定程度的彈性,使長期運行的工作能夠在這種突發事件中生存下來。SwitchML[63]建議如何實現這種彈性。Trio-ML的實現有支持這種解決方案的規定,盡管它不是當前代碼的一部分,我們把它留給未來的工作。 ? 未來的開放源碼計劃。我們正在考慮幾個未來開源的想法。首先,我們計劃為Trio增加對P4編程的全面支持。Juniper工程公司已經為實現這一目標做出了初步努力[6],但最近對P4核心規范的修改和增強,應該可以讓更多的靈活性和更多的功能通過P4接口公開。其次,我們計劃創建一種特定領域的語言,讓第三方開發者能夠使用Trio芯片組的全部轉發路徑功能。瞻博網絡正在探索這一領域的發展,并歡迎社區提供反饋。 ? ?
05?相關工作
使用可編程交換機的網絡內計算。之前的幾篇論文通過利用網絡內部的某種形式的可編程性提出了網絡內計算。這些方法分為兩類:(1)使用基于PISAb的架構進行線速計算[18, 48, 63];(2)使用片上FPGA進行亞線速計算[21]。我們的網絡內ML聚合用例與Sharp[18]、SwitchML[63]、ATP[48]、PANAMA[36]和Flare[29]密切相關。Sharp[18]是Mellanox針對專用ML訓練集群的專有設計;它假定網絡帶寬可以被完全保留。相比之下,我們考慮的是多個用戶和應用共享鏈接的網絡。SwitchML[63]和ATP[48]使用市面上的Tofino交換機來執行梯度聚合。盡管Tofino交換機可以進行線速數據包處理,但其流水線結構的可編程性較為有限,這使得網絡內的散兵游勇緩解極具挑戰性。我們使用SwitchML作為Trio-ML的基線比較。對于我們的用例來說,SwitchML是一個蘋果對蘋果的比較,使其成為比ATP更合適的基線。更具體地說,ATP的性能改進受到網絡內聚合和額外的參數服務器的影響,而SwitchML和Trio-ML更相似,因為這兩種方法只使用交換機/路由器進行聚合。PANAMA的[36]網內聚合硬件可以支持靈活的數據包處理,但它是基于FPGA充當線內顛簸,使得它在大規模部署中不切實際。然而,本文旨在利用Trio的可編程架構,從頭開始設計新的有狀態的網絡內應用。Trio的幾個關鍵特征使這些新的應用成為可能。首先,Trio的大內存和對數據包尾部數據的快速訪問使網絡內的高效計算成為可能。其次,Trio的共享內存系統提供了幾GB的存儲空間;即使在有散兵游勇的情況下,或者在多個應用程序同時運行的情況下,這也足夠用于數據存儲。最后,Trio對單個數據包的指令數量沒有限制,使Microcode程序能夠啟動大型數據包所需的計算指令。
緩解散工問題。在理解和緩解分布式系統中散工問題的影響方面,之前有大量的工作[13 15, 25, 26, 30, 31, 33, 34, 38, 46, 51, 56, 57, 59, 61, 72, 75, 78, 79] 。特別是,Harlap等人提出了FlexRR,以減輕散工問題對分布式學習工作的影響[38]。FlexRR要求工人之間進行點對點的通信,以檢測速度慢的工人并進行工作重新分配。相比之下,我們考慮在網絡內部減輕散兵游勇的影響,不需要工人之間的任何消息傳遞,也不需要參數服務器。Tandon等人[72]和Raviv等人[61]提出了編碼理論框架,通過在工人之間重復訓練數據來緩解分布式學習中的散兵游勇;然而,Trio-ML不需要數據重復。
替代傳統交換機架構。研究界一直在研究替代的交換機架構,以解決基于PISA的架構的一些限制,如缺乏共享內存和淺層流水線深度。最有競爭力的例子是dRMT(Disaggregated Programmable Switching)[24]。dRMT開關架構實現了一個集中的、共享的內存池,所有的匹配動作階段都可以訪問。dRMT不是在一個流水線上執行匹配動作階段,而是將這些階段聚集在一個集群中,并以輪流的順序執行。
一個控制邏輯單元對這些階段進行調度,以便在尊重程序依賴性的前提下最大限度地提高集群的吞吐量。然而,集中式內存池由一個連接各階段和內存的多路復用器控制,在一個給定的時鐘周期內,只有一個階段可以訪問內存。當一個應用程序需要在多個階段訪問內存時,這可能導致程序執行速度減慢。
在Trio中,多個線程可以在同一時間向同一內存位置發送內存訪問請求,Trio的讀-改-寫引擎依次處理這些請求,保證了更新的一致性。此外,dRMT通過crossbar的內存訪問是在編譯時調度的,這降低了增量更新和重新編譯應用程序代碼的靈活性。
橫杠調度算法的復雜性會限制該架構擴展到更多數量的匹配行動處理器的能力。相比之下,Trio的crossbar是實時調度的,從而提供對內存的有效訪問。這種動態調度機制使Trio能夠從第一代的16個PPE擴展到第六代的160個PPE,而且將來還會繼續擴大規模。
此外,在dRMT中,數據包解析器和分離器位于匹配動作處理器之外。對依賴查找結果的數據包的內部頭的任何解析(例如MPLS封裝的數據包)都必須重新循環到解析器中進行處理。相比之下,Trio的PPE是完全可編程的處理器,能夠以運行完成的方式處理數據包解析/分離,以及其余的數據包查找和處理。Trio的多線程PPE還允許數據包由不同的Microcode程序根據其處理要求進行處理。
06?結論
本文介紹了瞻博網絡的可編程芯片組Trio,以及它在新興數據密集型網絡內應用中的應用。Trio已經生產了十多年,建立了一個龐大的客戶群,擁有數十億美元的市場份額。我們描述了Trio的多線程和可編程的包轉發和包處理引擎。然后,我們使用分布式機器學習訓練的網絡內聚合和網絡內散工問題緩解作為兩個用例來說明Trio的微代碼和編程環境。我們的評估表明,Trio的性能比今天基于流水線的解決方案高出1.8倍。
編輯:黃飛
?










 工商網監
工商網監
評論