 電子發(fā)燒友App
電子發(fā)燒友App


背景
如今,隨著分解式存儲(chǔ)和微服務(wù)架構(gòu)的日益流行,在現(xiàn)代數(shù)據(jù)中心,高扇出和扇入的遠(yuǎn)程過程調(diào)用(RPC)產(chǎn)生了大部分的流量,據(jù)統(tǒng)計(jì),在谷歌的數(shù)據(jù)中心網(wǎng)絡(luò)中,超過95%的流量均由RPC產(chǎn)生。而RPC性能的好壞是應(yīng)用性能的好壞的一個(gè)重要指標(biāo),因此,研究什么會(huì)影響RPC的性能至關(guān)重要。RPC在大多數(shù)情況下性能良好,但是,在網(wǎng)絡(luò)負(fù)荷超載的情況下,網(wǎng)絡(luò)負(fù)載可能是平常的8倍以上,RPC的時(shí)延是造成網(wǎng)絡(luò)時(shí)延峰值的主要原因。在這時(shí),網(wǎng)絡(luò)的需求量大于容量,所以需要對重要的RPC提供網(wǎng)絡(luò)時(shí)延SLO保證。RPC被分為3類:對時(shí)延敏感的性能重要RPC(Performance-critical,PC)、對吞吐敏感的非重要RPC(Non-critical,NC)和沒有SLO要求的盡最大努力交付RPC(Best-effort,BE)。 ?
相關(guān)工作
先前的工作中有基于優(yōu)先級調(diào)度的方法。基于大小的優(yōu)先級調(diào)度,如最小工作優(yōu)先(Smallest Job First,SJF)和最小剩余時(shí)間優(yōu)先(Smallest Remaining Time First,SRTF)可以減小平均RPC時(shí)延,但是RPC的大小不等同于RPC的優(yōu)先級且這個(gè)方法在實(shí)際中很難實(shí)施。第二種是對RPC使用嚴(yán)格的優(yōu)先級隊(duì)列(Strict Priority Queue,SPQ),這種方法可以提供直接的優(yōu)先級映射,但同時(shí)也會(huì)讓每個(gè)人都傾向使用最高的優(yōu)先級,且存在饑餓的問題。另一個(gè)方法,就是使用加權(quán)公平隊(duì)列(Weighted-Fair Queuing,WFQ),很多包括谷歌在內(nèi)的云服務(wù)提供商,使用的也是這種方法。這種方法有兩個(gè)有點(diǎn):第一,RPC的優(yōu)先級可以直接對應(yīng)到WFQ的QoS隊(duì)列上;第二,WFQ已實(shí)際部署在商用交換機(jī)上了,使得大規(guī)模地部署很簡單。但這方法也存在兩種問題:第一,QoS的類別和SLO并不相關(guān);第二,應(yīng)用層面上的優(yōu)先級映射太粗粒度,其體現(xiàn)在PRC優(yōu)先級和QoS級別的不一致。為了解決WFQ的兩個(gè)問題,本文作者設(shè)計(jì)了Aequitas。 ?
設(shè)計(jì)
Aequitas的設(shè)計(jì)目標(biāo),是為了解決上述提到的WFQ的兩個(gè)問題,具體做法是將優(yōu)先級映射從粗粒度調(diào)整到細(xì)粒度;管理不同QoS級別間的流量分布(QoS-mix),為重要的RPC提供有保障的SLO。流程如下圖所示。 ? 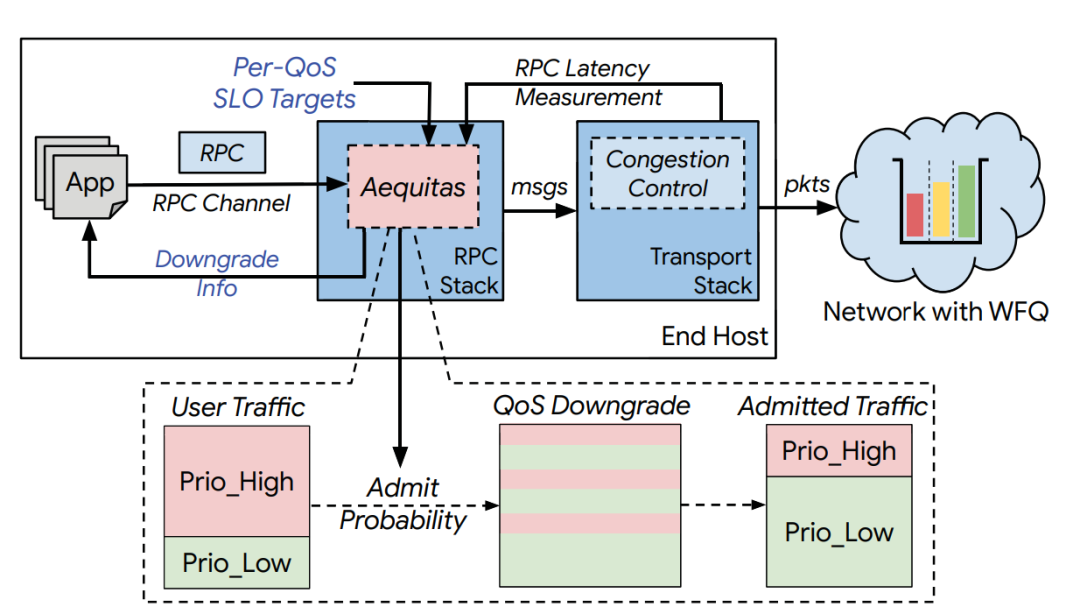 ? 第一, 將優(yōu)先級與WFS 的QoS在RPC的粒度上對應(yīng)。具體來說,對每個(gè)應(yīng)用的每個(gè)RPC設(shè)定優(yōu)先級,并按照PC,NC,BE到高、中、低,依次進(jìn)行映射。 ?
? 第一, 將優(yōu)先級與WFS 的QoS在RPC的粒度上對應(yīng)。具體來說,對每個(gè)應(yīng)用的每個(gè)RPC設(shè)定優(yōu)先級,并按照PC,NC,BE到高、中、低,依次進(jìn)行映射。 ? 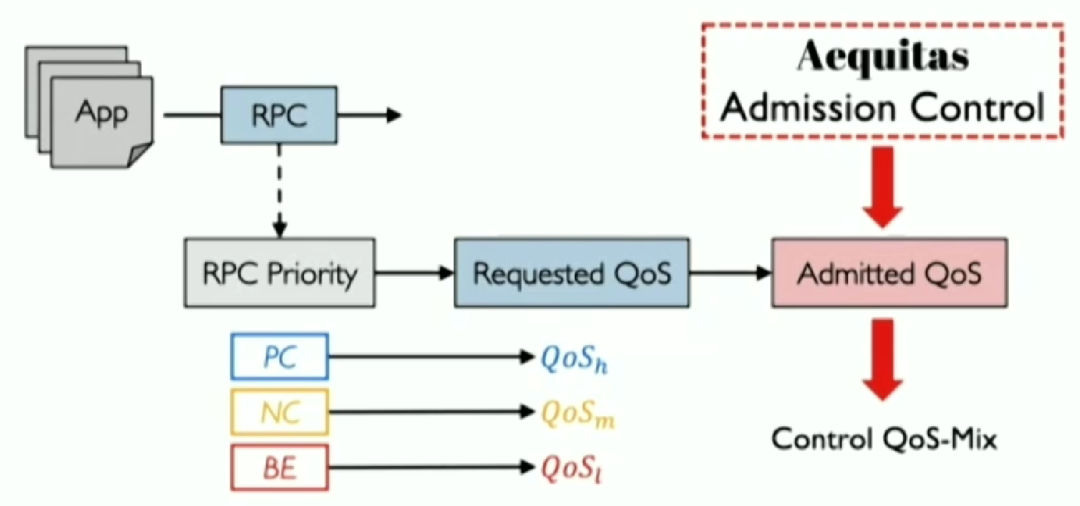 ? 第二, 通過允許控制來直接控制QoS-mix。如下圖所示,Aequitas通過概率允許控制機(jī)制,對所有的QoS進(jìn)行調(diào)整:保持原來的QoS來傳輸或降到最低級,若發(fā)生了QoS降級,則會(huì)告知應(yīng)用修改其不同等級QoS的分布。這樣就能得到最終的QoS-mix。
? 第二, 通過允許控制來直接控制QoS-mix。如下圖所示,Aequitas通過概率允許控制機(jī)制,對所有的QoS進(jìn)行調(diào)整:保持原來的QoS來傳輸或降到最低級,若發(fā)生了QoS降級,則會(huì)告知應(yīng)用修改其不同等級QoS的分布。這樣就能得到最終的QoS-mix。 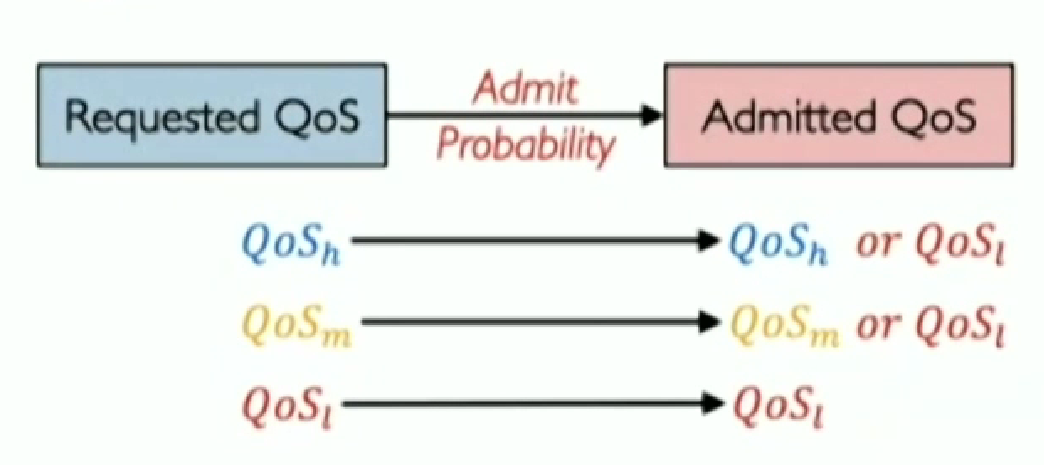 Aequitas的概率允許機(jī)制是一個(gè)分布式的算法,概率的調(diào)整方式為加法增加和乘法減小(Additive Increase Multiplicative Decrease, AIMD)。具體來說,在各終端主機(jī)上,對每個(gè)(源地址,目的地址,要求QoS)這樣的元組,維持著一個(gè)允許概,測量并收集網(wǎng)絡(luò)中RPC的時(shí)延(RPC Network Latency,RNL)。如果RNL小于目標(biāo)SLO,則將允許概率加上增加窗口的大;反之,則乘法減小允許概率。 ?
Aequitas的概率允許機(jī)制是一個(gè)分布式的算法,概率的調(diào)整方式為加法增加和乘法減小(Additive Increase Multiplicative Decrease, AIMD)。具體來說,在各終端主機(jī)上,對每個(gè)(源地址,目的地址,要求QoS)這樣的元組,維持著一個(gè)允許概,測量并收集網(wǎng)絡(luò)中RPC的時(shí)延(RPC Network Latency,RNL)。如果RNL小于目標(biāo)SLO,則將允許概率加上增加窗口的大;反之,則乘法減小允許概率。 ?
實(shí)驗(yàn)評估
本文的評估實(shí)驗(yàn)包括模擬、測試集實(shí)驗(yàn)和實(shí)際生產(chǎn)應(yīng)用的結(jié)果。重點(diǎn)在兩個(gè)方面,首先是通過控制99%或99.9%的RNL,測試Aequitas是否仍然符合正確性;其次是在不論流量如何分布的情況下,Aequitas是否提供接近理想的流量。 ? 從下圖實(shí)驗(yàn)結(jié)果可以看出,不論高優(yōu)先級的流量占比多少,Aequitas都能提供較好的SLO保證(藍(lán)色線為Aequitas結(jié)果,黃色線為SLO目標(biāo),二者很接近)。與其他調(diào)度算法,如SPQ相比,Aequitas效果顯著(紅色線為SPQ算法的調(diào)度結(jié)果,其與SLO相差甚遠(yuǎn))。由此可見,Aequitas可以在網(wǎng)絡(luò)過載情況下,保證SLO。 ? 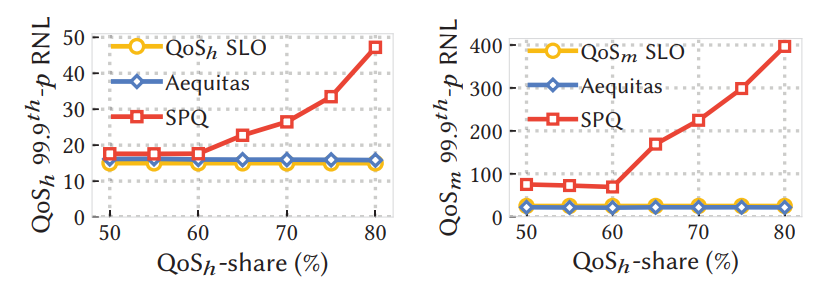
個(gè)人觀點(diǎn)
在網(wǎng)絡(luò)過載的情況下,要求高QoS的RPC數(shù)據(jù)量遠(yuǎn)超網(wǎng)絡(luò)的傳輸能力,在這時(shí)就要在時(shí)延和服務(wù)質(zhì)量之間做出取舍。在這篇論文中,Aequitas通過犧牲尾時(shí)延來獲取更低的99%(99.9%)時(shí)延,即犧牲一小部分來獲取整體性能的提升。 ?
Time-division TCP for reconfigurable data center networks
Shawn Shuoshuo Chen (Carnegie Mellon University), Weiyang Wang (MIT), Christopher Canel (Carnegie Mellon University), Srinivasan Seshan (Carnegie Mellon University), Alex C. Snoeren (UC San Diego), Peter Steenkiste (Carnegie Mellon University)
? 本篇文章由卡內(nèi)基梅隆大學(xué)、麻省理工學(xué)院以及加州大學(xué)圣地亞哥分校的研究者合作完成。本論文提出了時(shí)分TCP(TDTCP),這是專門為可重構(gòu)網(wǎng)絡(luò)設(shè)計(jì)的TCP新變體,旨在充分利用RDCN提供的額外容量。 ?
背景
大多數(shù)數(shù)據(jù)中心網(wǎng)絡(luò)大多基于Clos拓?fù)洌⑻峁﹩蝹€(gè)全平分網(wǎng)絡(luò)的“big switch”抽象,以應(yīng)對通過高帶寬、低延遲結(jié)構(gòu)連接大量終端主機(jī)的挑戰(zhàn)。但隨著主機(jī)數(shù)量的增加以及摩爾定律的放緩,這種方法達(dá)到極限。為了應(yīng)對寬帶供需差距的不斷擴(kuò)大,一些研究者提出了基于optical circuit switch的可重構(gòu)數(shù)據(jù)中心網(wǎng)絡(luò)。該方法可以動(dòng)態(tài)分配可用的網(wǎng)絡(luò)資源,成本更低,擴(kuò)展性更好。但由于TCP的擁塞控制不適用于延遲和帶寬劇烈變化的網(wǎng)絡(luò),現(xiàn)有的TCP變體無法充分利用RDCN提供的額外容量。為了充分利用RDCN提供的額外容量,該論文提出了時(shí)分TCP (TDTCP),這是專門為可重構(gòu)網(wǎng)絡(luò)設(shè)計(jì)的TCP新變體。作者的靈感來自于以下發(fā)現(xiàn)—“只要網(wǎng)絡(luò)在不同的配置之間清晰移動(dòng),就足以在每個(gè)配置中分別有效地運(yùn)行”。具體來說,完整的算法是單個(gè)模型的分段函數(shù),TDTCP隨著時(shí)間的推移復(fù)用獨(dú)立的網(wǎng)絡(luò)狀態(tài),隨著網(wǎng)絡(luò)從一種配置轉(zhuǎn)移到另一種配置,發(fā)送者在網(wǎng)絡(luò)模型之間切換。 ?
設(shè)計(jì)
(1) TDN 變化通知 ? RDCN的光學(xué)配置時(shí)間大約為幾個(gè)RTT,主機(jī)幾乎沒有時(shí)間對新的網(wǎng)絡(luò)環(huán)境做出反應(yīng)。作者利用終端主機(jī)連接的ToR交換機(jī)直接參與重新配置網(wǎng)絡(luò)結(jié)構(gòu)來解決這一個(gè)挑戰(zhàn)。具體來說,作者讓ToR交換機(jī)在路徑發(fā)生變化時(shí)直接通知其連接的主機(jī)。該信令使得終端主機(jī)能夠?qū)⒖芍貥?gòu)網(wǎng)絡(luò)視為一系列周期性變化的時(shí)分網(wǎng)絡(luò) (TDN) 。具體來說,作者使用ICMP數(shù)據(jù)包來攜帶該通知,ICMP數(shù)據(jù)包僅使用一個(gè)整數(shù)索引,指示當(dāng)前活動(dòng)的網(wǎng)絡(luò)路徑。因?yàn)門oR交換機(jī)和終端主機(jī)處于同一機(jī)架內(nèi),通知延遲可以保持在較低的水平。 ? (2) 序列空間與包重排序 ? 當(dāng)網(wǎng)絡(luò)重新配置時(shí),傳輸中的數(shù)據(jù)包可能屬于多個(gè)時(shí)分網(wǎng)絡(luò) (TDN)。例如,數(shù)據(jù)包可能會(huì)穿越與其ACK不同的TDN,或者延遲的減少可能會(huì)重新排序數(shù)據(jù)包。TDTCN需要區(qū)分瞬態(tài)重新排序與真正的丟失,防止不必要的重新傳輸,提高傳輸效率。為了應(yīng)對這一挑戰(zhàn),TDTCP跟蹤與每個(gè)TDN關(guān)聯(lián)的序列空間,并使用啟發(fā)式和選擇性確認(rèn)來避免TDN轉(zhuǎn)換期間的嚴(yán)重性能損失。具體來說,TDTCP采用單個(gè)連接級序列號空間,而不是使用MPTCP的子流兩級設(shè)計(jì)。使用這一設(shè)計(jì)有三個(gè)原因。首先是為了避免TDN切換后流量控制停止;其次是為了消除子流之間協(xié)調(diào)的需要,減少不必要的性能開銷;與此同時(shí),該設(shè)計(jì)可以減少接受端的額外大量處理。 ? 在TCP采用單個(gè)連續(xù)級序列號空間的基礎(chǔ)上,讓我們看一下作者如何解決包重排序問題。 ? 傳統(tǒng)的TDP Reno快速重傳啟發(fā)式算法RDCN網(wǎng)絡(luò)。具體來說,在RDCN網(wǎng)絡(luò)中,大多數(shù)重新排序是跨TDN重新排序,數(shù)據(jù)包以及相應(yīng)的ACK會(huì)以不同的延遲遍歷TDN,跨TDN重新排序不會(huì)表示丟失;由于增加的路徑延遲,ACK被簡單地延遲,如果TDTCP遵循TCP Reno快速重傳啟發(fā)式算法,它將在每次TDN轉(zhuǎn)換時(shí)虛假地重傳大量數(shù)據(jù)包。 ? 為了避免頻繁的虛假重傳,TDTCP在per-TDN狀態(tài)和SACK支持的幫助下放松了三重dupACK啟發(fā)式。下圖說明了TDTCP的寬松重排序檢測啟發(fā)式算法。當(dāng)通過 TDN 1 發(fā)送的(粉紅色)段在來自 TDN 0 的未完成(藍(lán)色)段之前得到確認(rèn)時(shí),SACK 標(biāo)記成功確認(rèn)的段并調(diào)用快速恢復(fù)。snduna 指針和最高 SACKed 序列號(虛線矩形)之間的所有段都可能丟失,并且可能需要重新傳輸。但是,TDTCP 會(huì)檢查這些數(shù)據(jù)包的相關(guān) TDN ID,并將它們與 TDN 更改指針進(jìn)行比較。來自 TDN 0 的(藍(lán)色虛線)段被忽略,因?yàn)樗鼈儗儆诓煌?TDN,并且它們的 ACK 很可能只是延遲了。只有屬于 TDN 1 的一個(gè)(粉紅色虛線)段被確認(rèn)為真正的丟失,將被重傳。TDN 0 保持打開狀態(tài),允許繼續(xù)全速發(fā)送;另一方面,TDN 1 由于丟失而進(jìn)入恢復(fù)狀態(tài)。 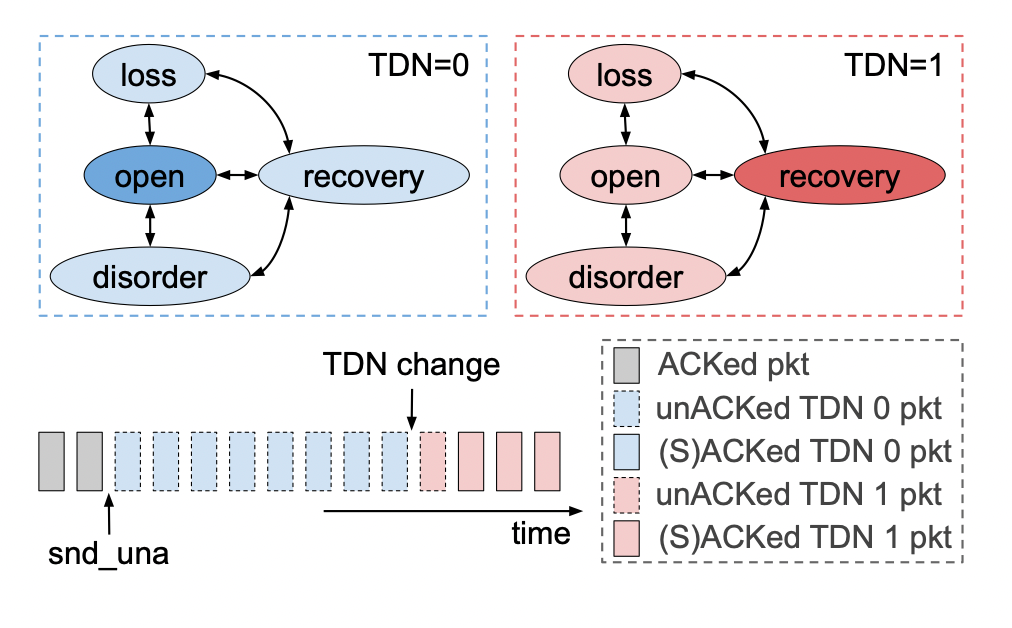 (3)實(shí)現(xiàn)與限制 ? 在現(xiàn)代操作系統(tǒng)內(nèi)核中實(shí)現(xiàn)TDTCP具有挑戰(zhàn)性,因?yàn)閾砣刂茽顟B(tài)緊密集成到網(wǎng)絡(luò)堆棧中。論文研究者確定了必須跨TDN復(fù)制的CUBIC擁塞控制狀態(tài)子集,并優(yōu)化了TDN切換過程,以確保及時(shí)通知終端主機(jī)網(wǎng)絡(luò)轉(zhuǎn)換。TDCN的主要限制是它的運(yùn)行機(jī)制。TDTCP僅在網(wǎng)絡(luò)條件以一定的頻率變化時(shí)才有用。TDTCP最適合在TDN變化周期在1-100x路徑RTT的網(wǎng)絡(luò)中運(yùn)行。 ?
(3)實(shí)現(xiàn)與限制 ? 在現(xiàn)代操作系統(tǒng)內(nèi)核中實(shí)現(xiàn)TDTCP具有挑戰(zhàn)性,因?yàn)閾砣刂茽顟B(tài)緊密集成到網(wǎng)絡(luò)堆棧中。論文研究者確定了必須跨TDN復(fù)制的CUBIC擁塞控制狀態(tài)子集,并優(yōu)化了TDN切換過程,以確保及時(shí)通知終端主機(jī)網(wǎng)絡(luò)轉(zhuǎn)換。TDCN的主要限制是它的運(yùn)行機(jī)制。TDTCP僅在網(wǎng)絡(luò)條件以一定的頻率變化時(shí)才有用。TDTCP最適合在TDN變化周期在1-100x路徑RTT的網(wǎng)絡(luò)中運(yùn)行。 ?
實(shí)驗(yàn)評估
作者針對內(nèi)核中現(xiàn)有的TCP 變體以及 MPTCP 和 reTCP評估 TDTCP 的性能。實(shí)驗(yàn)結(jié)果表明,長壽命流在 TDTCP 下實(shí)現(xiàn)了更好的吞吐量:在一種代表性的 RDCN 設(shè)置中比單路徑 CUBIC 和 DCTCP 高 24%,比 MPTCP 高 41%。此外,TDTCP 與 reTCP 的吞吐量性能相匹配,同時(shí)表現(xiàn)出較低的交換機(jī)緩沖區(qū)占用率,并且不依賴于主動(dòng)交換機(jī)緩沖區(qū)管理。 ?
總結(jié)
TDTCP 是一種新的 TCP 變體,旨在有效利用最新 RDCN 提供的額外容量。TDTCP 使用 TCP 狀態(tài)變量的獨(dú)立副本監(jiān)控不同時(shí)分網(wǎng)絡(luò)的路徑特征,利用交換機(jī)生成的路徑更改通知快速收斂到最佳擁塞狀態(tài),并放寬 TCP 的快速恢復(fù)啟發(fā)式算法以避免在網(wǎng)絡(luò)條件下出現(xiàn)虛假重傳改變。作者在 Linux 內(nèi)核 5.8 中實(shí)現(xiàn)了 TDTCP,并在小規(guī)模(模擬)RDCN 測試平臺(tái)上評估了它的性能。結(jié)果表明,對于長壽命流,TDTCP 顯著降低了網(wǎng)絡(luò)中的隊(duì)列占用率,并且優(yōu)于傳統(tǒng)的單路徑 TCP 變體,例如 CUBIC 和 DCTCP。TDTCP 可與 reTCP 競爭,但不需要交換機(jī)像 reTCP 那樣動(dòng)態(tài)調(diào)整緩沖區(qū)大小。 ?
個(gè)人觀點(diǎn)
個(gè)人認(rèn)為,本論文比較有意思的點(diǎn)是“packet reordering”部分的描寫。首先舉例說明為什么傳統(tǒng)的快速重傳算法不適用于TDTCP,然后在快速重傳算法的基礎(chǔ)之上,設(shè)計(jì)了寬松的檢測啟發(fā)式算法,并且舉了個(gè)例子說明算法是如何運(yùn)行的。這一部分從描寫敘述到舉例說明再到算法的設(shè)計(jì)都是比較精彩的。 ?
背景與問題
網(wǎng)絡(luò)設(shè)備配備了一個(gè)緩沖區(qū),以避免在瞬時(shí)擁塞期間下降,并吸收突發(fā)流量。為了降低成本和最大化利用率,on-chip緩沖區(qū)在其隊(duì)列之間被共享。這種共享自然會(huì)導(dǎo)致各種問題。具體地說,一個(gè)隊(duì)列的過度增長可能會(huì)損害另一個(gè)隊(duì)列的性能,這可能會(huì)缺乏、剝奪吞吐量等。更糟糕的是,這種有害的干擾可能發(fā)生在看似獨(dú)立的隊(duì)列之間,例如,映射到不同端口的隊(duì)列或由獨(dú)立的應(yīng)用程序形成的隊(duì)列。 ? 網(wǎng)絡(luò)設(shè)備通常采用分層的分組接納控制來協(xié)調(diào)共享空間的使用。首先,緩沖區(qū)管理(BM)算法動(dòng)態(tài)分割緩沖區(qū)空間。第二,主動(dòng)隊(duì)列管理(AQM)算法通過選擇性地允許傳入的數(shù)據(jù)包來管理BM分配給每個(gè)單獨(dú)隊(duì)列的緩沖區(qū)片。BM旨在通過管理設(shè)備級別上的緩沖區(qū)的空間分配來實(shí)現(xiàn)跨隊(duì)列的隔離。直觀地說,BM的目標(biāo)是避免長時(shí)間的隊(duì)列饑餓,有效地在穩(wěn)定狀態(tài)下加強(qiáng)公平。相反,AQM的目標(biāo)是通過管理隊(duì)列級別上的緩沖區(qū)的時(shí)間分配來保持穩(wěn)定的排隊(duì)延遲。直觀地說,AQM通過避免數(shù)據(jù)包在緩沖區(qū)中停留“太久”的來防止緩沖區(qū)膨脹。 ? 雖然BM和AQM在過去是合理和成功的,因?yàn)樗试SBM和AQM方案進(jìn)一步發(fā)展,但最近的兩個(gè)數(shù)據(jù)中心趨勢使它們之間的協(xié)調(diào)變得緊迫。首先,緩沖區(qū)的大小沒有跟上交換機(jī)容量的增加。實(shí)際上,BM不再有足夠的可用緩沖區(qū)來為每個(gè)隊(duì)列提供隔離。其次,隨著流量變得更加突發(fā)的場景更加普遍,緩沖區(qū)的瞬態(tài)需要控制在設(shè)備級。為了跟上這些趨勢,緩沖區(qū)共享方案需要提供隔離、有界排空時(shí)間和高突發(fā)容差。但是今天的BM和AQM方案根本不能獨(dú)立地滿足這些要求。在這一見解的驅(qū)動(dòng)下,作者提出了ABM,一種主動(dòng)緩沖區(qū)管理算法,它結(jié)合了來自BM和AQM的見解,以在不犧牲吞吐量的情況下實(shí)現(xiàn)高突發(fā)流量吸收。 ? 本文的做法旨在建模,綜合考慮了多種因素來為每個(gè)隊(duì)列分配一定長度的緩沖區(qū)空間和時(shí)間方面的問題。 ?
動(dòng)機(jī)
優(yōu)秀的緩沖區(qū)管理方案屬性: ? 為了最大限度地提高共享緩沖區(qū)的利用率,緩沖區(qū)共享方案需要滿足三個(gè)關(guān)鍵屬性:(1) isolation; (2) bounded drain time; and (3) predictable burst tolerance。 ? (1)Isolation ? 由于緩沖區(qū)是跨多個(gè)隊(duì)列共享的,因此一小組隊(duì)列過度使用緩沖區(qū)可能會(huì)干擾交換機(jī)中的其他隊(duì)列使用共享緩沖區(qū)的能力。如果相互競爭的隊(duì)列屬于不同的流量優(yōu)先級,那么這種干擾可能特別有害。我們要求每個(gè)優(yōu)先級必須在任何給定時(shí)間占用可配置的最小緩沖區(qū)數(shù)量,獨(dú)立于緩沖區(qū)狀態(tài)。形式上,讓Tp(t)表示在任何時(shí)間t中所有優(yōu)先級P的集合中分配給優(yōu)先級p(P中元素)的總緩沖區(qū)。然后,Bp(min)必須始終大于可配置的靜態(tài)值。但是,由于總緩沖空間有限,所以總分配必須在總緩沖區(qū)內(nèi)。因此,每個(gè)優(yōu)先級也必須是其分配的上限Bp(max),以防止獨(dú)占緩沖區(qū)。 ?
??(2)Bounded drain time ? 緩沖區(qū)有限的排空時(shí)間減少了緩沖區(qū)內(nèi)的數(shù)據(jù)包(或流量)的排隊(duì)延遲。為了避免高排隊(duì)延遲的有害后果,緩沖區(qū)共享方案需要綁定每個(gè)隊(duì)列的排空時(shí)間。具體地說,緩沖區(qū)共享方案需要通過一個(gè)可配置的靜態(tài)值q(t)來綁定具有服務(wù)速率u(t)的隊(duì)列中被占用的緩沖區(qū)A。實(shí)際上下面的條件總結(jié)了緩沖區(qū)膨脹問題:所需的屬性是為了避免數(shù)據(jù)包在緩沖區(qū)中停留“太長時(shí)間”。??
Bounded drain time: q(t)/u(t)<=A
? (3)Predictable burst tolerance ? 如果預(yù)留大量的緩存空間以應(yīng)對突發(fā)的數(shù)據(jù)包或者等突發(fā)數(shù)據(jù)包到來時(shí)直接占用現(xiàn)有的緩存區(qū),雖然足以應(yīng)對突發(fā)事件,但這可能會(huì)產(chǎn)生不利影響。一方面,始終保持突發(fā)大小的空緩沖區(qū)數(shù)量會(huì)剝奪隊(duì)列中寶貴的緩沖區(qū),從而導(dǎo)致潛在的吞吐量損失。另一方面,將所有新釋放的緩沖區(qū)(從引流隊(duì)列)分配給傳入突發(fā)將耗盡引流隊(duì)列(刪除每個(gè)傳入數(shù)據(jù)包)。總之,提供可預(yù)測的突發(fā)容忍性避免緩沖浪費(fèi),緩沖共享方案需要結(jié)合考慮隔離和限制排空時(shí)間。 ? 最先進(jìn)方法動(dòng)態(tài)閾值存在的不足: ? 典型的設(shè)備使用分層的數(shù)據(jù)包進(jìn)入控制方案:首先,一個(gè)緩沖區(qū)管理(BM)方案決定在設(shè)備級別上每個(gè)隊(duì)列的最大長度,然后一個(gè)活動(dòng)隊(duì)列管理(AQM)方案決定哪些數(shù)據(jù)包緩沖在隊(duì)列中。不幸的是,兩種控制方案之間缺乏合作導(dǎo)致(i)由于缺乏隔離而造成的跨隊(duì)列的有害干擾;(ii)由于忽略了每個(gè)排隊(duì)的排空時(shí)間,增加了排隊(duì)延遲;(iii)不可預(yù)測的突發(fā)流量的容忍性。當(dāng)今數(shù)據(jù)中心交換機(jī)中使用的最先進(jìn)的緩沖區(qū)管理算法動(dòng)態(tài)閾值(DT)根本無法實(shí)現(xiàn)上面描述的理想屬性,而且也具備上述缺陷。 ?
設(shè)計(jì)
ABM同時(shí)滿足了隔離、排空時(shí)間和可預(yù)測的突發(fā)流量的容忍三個(gè)屬性。在論文附錄A有完整的證明。 ? ABM算法: ABM為每個(gè)隊(duì)列分配閾值,同時(shí)考慮空間的、緩沖區(qū)范圍的和時(shí)間范圍的、每個(gè)隊(duì)列的統(tǒng)計(jì)信息。Tpi(t):在端口上的優(yōu)先級為p的隊(duì)列i的閾值。 ?
Tpi(t)=a(p) x 1/n(p) x (B-Q(t)) x U(pi)/b
? a(p)是操作員需要在ABM中配置的唯一參數(shù)。其值越高,平均分配值就越高。它定義了每個(gè)優(yōu)先級可用的最小和最大緩沖區(qū)。 ? n(p)表示優(yōu)先級p的擁塞隊(duì)列數(shù)。如果隊(duì)列長度接近相應(yīng)的閾值,則ABM考慮隊(duì)列擁塞。在本文的評估中,如果一個(gè)隊(duì)列的長度大于或等于其閾值的0.9,我們就認(rèn)為它是擁塞的。 ? U(pi)/b表示標(biāo)準(zhǔn)化排空率,其中U(pi)為隊(duì)列的排空率,b為每個(gè)端口的帶寬。 ? (B-Q(t))表示剩余的緩沖區(qū)空間。 ?
BM: a(p) x 1/n(p) x (B-Q(t)) AQM:U(pi)/b
? ABM具備實(shí)踐性:
(1)ABM使用了當(dāng)今交換機(jī)可用的統(tǒng)計(jì)數(shù)據(jù)。 (2)ABM講述了關(guān)于如何配置α的基本經(jīng)驗(yàn)。 (3)DT已經(jīng)部署于數(shù)據(jù)中心,而ABM可在DT之上近似地使用。 ?
性能評估
本文的評估是基于網(wǎng)絡(luò)模擬器NS3,將ABM與數(shù)據(jù)中心設(shè)置中的最先進(jìn)的方法DT動(dòng)態(tài)閾值進(jìn)行了比較。作者做了大規(guī)模模擬結(jié)果表明,與現(xiàn)有的BM和AQM方案相比,ABM將短流量的流量完成時(shí)間提高了高達(dá)94。此外,ABM不僅兼容先進(jìn)的擁塞控制算法(如及時(shí)、DCTCP和PowerTCP),而且在繁重的工作負(fù)載下,它們的尾部fct的性能提高了高達(dá)76。最后,作者證明了與傳統(tǒng)的緩沖區(qū)管理方案不同,ABM在不同大小的緩沖區(qū)大小上工作良好,包括淺緩沖區(qū)。 ?
總結(jié)
問題場景: 今天的網(wǎng)絡(luò)設(shè)備跨隊(duì)列共享緩沖區(qū),以避免在瞬時(shí)擁塞期間下降,并吸收突發(fā)。隨著數(shù)據(jù)中心中緩沖區(qū)帶寬單元的減少,對最佳緩沖區(qū)利用率的需求變得更加迫切。 ? ABM核心觀點(diǎn): 它結(jié)合了來自BM和AQM的見解。具體地說,ABM利用了設(shè)備級別的總緩沖區(qū)占用率和單個(gè)隊(duì)列的占用時(shí)間。本質(zhì)上,ABM是緩沖區(qū)的空間(BM使用)和時(shí)間(AQM使用)特征的函數(shù)。ABM同時(shí)考慮了總緩沖區(qū)占用率(通常由BM使用)和隊(duì)列排空時(shí)間(通常由AQM使用)。 ? 性能結(jié)果: 作者分析證明了ABM提供隔離、有界緩沖排空時(shí)間,并在不犧牲吞吐量的情況下實(shí)現(xiàn)可預(yù)測的突發(fā)流量吸收。
個(gè)人觀點(diǎn)
研究依據(jù)明確和方法創(chuàng)新 ? 論文作者觀察到當(dāng)今數(shù)據(jù)中心的網(wǎng)絡(luò)帶寬與內(nèi)存buffer問題,并且關(guān)注了現(xiàn)代數(shù)據(jù)中心的流量特征,例如突發(fā)流量。以此展開研究動(dòng)態(tài)閾值方法的限制性,再通過數(shù)學(xué)建模提出自己的創(chuàng)新方法。這種研究路線在許多數(shù)據(jù)中心相關(guān)研究中大多有所體現(xiàn)。首次把緩存和活動(dòng)隊(duì)列統(tǒng)一于一個(gè)建模公式中,一個(gè)框架內(nèi),提出新方法。 ? ABM的實(shí)踐性理由不能令人信服 ? 文中提及了它具備實(shí)踐性的理由,首先,模擬和使用特定的數(shù)據(jù)不會(huì)具備普適性。而且,在測試的情況下,本文所提議的解決方案也沒有使用當(dāng)前的硬件進(jìn)行部署,例如FPGA實(shí)現(xiàn)或ASIC。盡管ABM可以近似實(shí)現(xiàn)動(dòng)態(tài)閾值的方法,但是沒有實(shí)際部署,沒有使用現(xiàn)在的硬件,那成本便難以確定。 ?
背景
過去十年,數(shù)據(jù)中心網(wǎng)絡(luò)的傳輸層設(shè)計(jì)有兩個(gè)目標(biāo):短流低延遲,長流高吞吐量。這方面的進(jìn)展有:DCTCP、D3、PDQ、D2TCP、HULL、Timely、pHost、NDP、Homa、HPCC、Swift等,這些方法解決了短流接近最優(yōu)的延遲。但是,如何同時(shí)實(shí)現(xiàn)短流的低延遲和長流的高網(wǎng)絡(luò)利用率,這個(gè)問題仍然十分挑戰(zhàn),這主要由于:1. 長流可能和短流競爭;2. 長流可能和網(wǎng)絡(luò)中的其他長流競爭;3. 長流可能和主機(jī)中其他長流競爭。 ?
設(shè)計(jì)
作者觀察到現(xiàn)代數(shù)據(jù)中心和switch fabrics在拓?fù)洹⒐ぷ髫?fù)載上的相似性,提出應(yīng)用交換機(jī)上的PIM算法到數(shù)據(jù)中心,叫做dcPIM。dcPIM是一種基于匹配的設(shè)計(jì),即每個(gè)發(fā)送端和唯一一個(gè)接收端配對。PIM用多輪控制信息來計(jì)算免沖突的輸入端口和輸出端口之間的配對,每一輪都包括三個(gè)階段:request stage,grant stage和accept stage。在每一輪開始,每個(gè)沒有匹配的輸入端口給其有輸出數(shù)據(jù)的端口發(fā)動(dòng)一個(gè)request(request stage);然后,每個(gè)沒有匹配的輸出端口從接收到的request中隨機(jī)選擇一個(gè),發(fā)送grant信息(grant stage);最后,沒有匹配的輸入端口從接收到的grants中隨機(jī)選擇一個(gè),發(fā)送accept信息,接收到accept信息的輸出端口和相應(yīng)的輸入端口實(shí)現(xiàn)了配對。直接應(yīng)用PIM到數(shù)據(jù)中心有3個(gè)挑戰(zhàn):高延遲、低帶寬利用率和異常處理機(jī)制。 ? dcPIM和PIM類似,包括兩個(gè)階段:匹配階段和數(shù)據(jù)傳輸階段。為了克服上面的3個(gè)挑戰(zhàn),dcPIM實(shí)現(xiàn)了4個(gè)關(guān)鍵的設(shè)計(jì): ?
理論分析結(jié)果表明,dcPIM可以用更少的匹配輪數(shù)實(shí)現(xiàn)接近最優(yōu)的網(wǎng)絡(luò)利用;
為了處理over subscription和failure,dcPIM使用接收端驅(qū)動(dòng)的單包admission control機(jī)制;
為了處理數(shù)據(jù)中心的匹配階段的高延遲,dcPIM流水化處理匹配和數(shù)據(jù)傳輸階段;
流水化匹配和數(shù)據(jù)傳輸后,為了保證兩個(gè)階段的時(shí)間匹配,dcPIM擴(kuò)展PIM的算法:為每一個(gè)發(fā)送端匹配多個(gè)接收端,也為每個(gè)接收端匹配了多個(gè)發(fā)送端。
實(shí)驗(yàn)評估
作者在pHost上實(shí)現(xiàn)了dcPIM。使用了3種拓?fù)洌簂eaf-spine,fattree,和oversubscibed。3種工作負(fù)載:IMC10,Web Search和Data Mining。3種traffic patterns:all-to-all,bursty,dense traffic ?matrix。評估的協(xié)議有:Homa Aeolus,NDP,HPCC。評估的metrics:slowdown,utilization。鏈路屬性:end-hosts使用100Gbps,leaf-spine的交換機(jī)間使用400Gbps,F(xiàn)atTree的交換機(jī)間使用100Gbps。交換機(jī)屬性:每個(gè)端口buffer是500KB,交換機(jī)buffer是16MB,450ns處理延遲和包傳播。 ? 結(jié)論如下: ?
dcPIM實(shí)現(xiàn)了接近最優(yōu)的尾延遲和網(wǎng)絡(luò)利用率;
基于匹配的設(shè)計(jì)使dcPIM快速收斂到高網(wǎng)絡(luò)利用率;
dcPIM可以實(shí)現(xiàn)比理論bound更有的網(wǎng)絡(luò)利用率。
總結(jié)
從pHost,NDP和Homa的設(shè)計(jì)出發(fā),dcPIM提取了connection-less design, per-packet load balancing,packet priorition和fast loss recovery。為短流實(shí)現(xiàn)了接近最優(yōu)的延遲。從現(xiàn)代數(shù)據(jù)中心和交換機(jī)fabrics的相似性出發(fā),dcPIM處理了包括適配數(shù)據(jù)中心大規(guī)模拓?fù)洌[藏?cái)?shù)據(jù)中心RTT,擴(kuò)大到100Gbps規(guī)模,處理網(wǎng)絡(luò)內(nèi)擁塞,從而實(shí)現(xiàn)了數(shù)據(jù)中心的吞吐量最優(yōu)的調(diào)度機(jī)制。 ?
個(gè)人觀點(diǎn)
本文改進(jìn)了PIM,提升了數(shù)據(jù)中心短流低延遲,長流高利用率。個(gè)人第一次接觸PIM方法,對把PIM應(yīng)用到數(shù)據(jù)中心吞吐量調(diào)度方法感到有趣。 ?
Jupiter evolving: transforming google's datacenter network via optical circuit switches and software-defined networking
Leon Poutievski, Omid Mashayekhi, Joon Ong, Arjun Singh, Mukarram Tariq, Rui Wang, Jianan Zhang, Virginia Beauregard, Patrick Conner, Steve Gribble, Rishi Kapoor, Stephen Kratzer, Nanfang Li, Hong Liu, Karthik Nagaraj, Jason Ornstein, Samir Sawhney, Ryohei Urata, Lorenzo Vicisano, Kevin Yasumura, Shidong Zhang, Junlan Zhou, Amin Vahdat
? 本論文由Google團(tuán)隊(duì)完成,主要回顧了Google數(shù)據(jù)中心網(wǎng)絡(luò)Jupiter近十年的發(fā)展歷程。 ?
背景
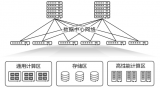
雖然使用商用芯片構(gòu)建的軟件定義網(wǎng)絡(luò)和Clos拓?fù)涫沟媒ㄖ?guī)模數(shù)據(jù)中心網(wǎng)絡(luò)成為云基礎(chǔ)設(shè)施的基礎(chǔ),并且在其他方面也影響巨大,但是很少有人關(guān)注如何管理建筑性規(guī)模網(wǎng)絡(luò)的異構(gòu)性和增量演進(jìn)。云基礎(chǔ)設(shè)施以增量方式增長,每次增加一個(gè)機(jī)架或者一個(gè)服務(wù)器,填滿一座空置的建筑物通常需要幾個(gè)月到幾年的時(shí)間。建筑物裝滿之后,就會(huì)對建筑物立面的基礎(chǔ)設(shè)施進(jìn)行更新,通常每次使用最新一代的服務(wù)器硬件更新一個(gè)機(jī)架。指數(shù)級增長和不斷變化的業(yè)務(wù)需求的現(xiàn)實(shí)意味著最好的放置計(jì)劃很快就會(huì)變得不高效甚至過時(shí),這使得增量和自適應(yīng)進(jìn)化成為必要。 ? 對于計(jì)算和存儲(chǔ)基礎(chǔ)設(shè)施的增量更新相對簡單——每次使用新一代硬件更新一個(gè)機(jī)架上的基礎(chǔ)設(shè)施。網(wǎng)絡(luò)基礎(chǔ)設(shè)施的增量更新相對更難,需要預(yù)先為整個(gè)Clos結(jié)構(gòu)的網(wǎng)絡(luò)構(gòu)建主干層,這樣會(huì)將數(shù)據(jù)中心的帶寬限制為在主干部署時(shí)可用的網(wǎng)絡(luò)帶寬。如下圖所示,一個(gè)通用的3層Clos架構(gòu)包括帶有ToR交換機(jī)的機(jī)架、連接機(jī)架的聚合塊以及連接聚合塊的主干塊。 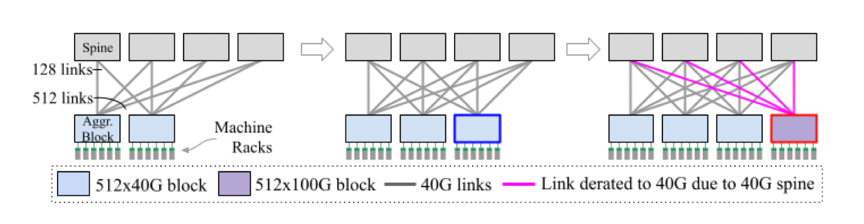 舉個(gè)例子,使用40Gbps技術(shù),每個(gè)主干塊可以支持512x40Gbps=20Tbps的突發(fā)帶寬。隨著下一代100Gbps的推出,更新的聚合塊可以支持512x100Gbps=51.2Tbps的突發(fā)帶寬,但是由于先前主干塊的40Gbps的帶寬限制,每個(gè)聚合塊的突發(fā)帶寬仍為20Tbps。網(wǎng)絡(luò)帶寬的不足會(huì)使得服務(wù)和存儲(chǔ)容量降低。如果要增加網(wǎng)絡(luò)中心的帶寬,需要更新整個(gè)建筑規(guī)模的主干,這也是不可取的,因?yàn)榇鷥r(jià)昂貴、耗時(shí)、需要重新布線。 ? 為了應(yīng)對這一問題,論文提出了一種新的端到端設(shè)計(jì)。 ?
舉個(gè)例子,使用40Gbps技術(shù),每個(gè)主干塊可以支持512x40Gbps=20Tbps的突發(fā)帶寬。隨著下一代100Gbps的推出,更新的聚合塊可以支持512x100Gbps=51.2Tbps的突發(fā)帶寬,但是由于先前主干塊的40Gbps的帶寬限制,每個(gè)聚合塊的突發(fā)帶寬仍為20Tbps。網(wǎng)絡(luò)帶寬的不足會(huì)使得服務(wù)和存儲(chǔ)容量降低。如果要增加網(wǎng)絡(luò)中心的帶寬,需要更新整個(gè)建筑規(guī)模的主干,這也是不可取的,因?yàn)榇鷥r(jià)昂貴、耗時(shí)、需要重新布線。 ? 為了應(yīng)對這一問題,論文提出了一種新的端到端設(shè)計(jì)。 ?
設(shè)計(jì)
本論文利用optical circuit switch將Jupiter從Clos架構(gòu)遷移到塊級直連結(jié)構(gòu),從而消除了主干交換層及其相關(guān)挑戰(zhàn)。這使得Juptiter能夠整合40Gbps、100Gbps及更高的網(wǎng)絡(luò)帶寬速度。除此之外,本論文將直連架構(gòu)與網(wǎng)絡(luò)管理、流量和拓?fù)涔こ碳夹g(shù)相結(jié)合,使得Juptiter能夠應(yīng)對流量的不確定性、大量的結(jié)構(gòu)異構(gòu)性,并且可以在不需要任何停機(jī)或服務(wù)消耗的情況下進(jìn)行演進(jìn)更新。具體來說,Jupiter數(shù)據(jù)中心互連層采用基于微機(jī)電系統(tǒng) (MEMS) 的光電路開關(guān) (OCS) 來實(shí)現(xiàn): ?
動(dòng)態(tài)拓?fù)渲匦屡渲茫?/p>
用于流量工程的集中式軟件定義網(wǎng)絡(luò) (SDN) 控制;
用于增量容量交付和拓?fù)涔こ痰淖詣?dòng)化網(wǎng)絡(luò)操作。
性能評估
與靜態(tài)的Clos結(jié)構(gòu)相比,本論文的設(shè)計(jì)在速度、容量和額外的靈活性方面提高了5倍,并且降低了30%的成本以及41%的功耗。 ?
總結(jié)
本文回顧了 Google 數(shù)據(jù)中心網(wǎng)絡(luò) Jupiter 近十年的發(fā)展歷程。這一旅程的核心是基于 MEMS 的光電路交換機(jī)、軟件定義網(wǎng)絡(luò)和自動(dòng)安全操作作為關(guān)鍵的支持技術(shù)。借助這些底層技術(shù),Jupiter 轉(zhuǎn)變?yōu)榭稍隽坎渴鸬慕Y(jié)構(gòu),其中異構(gòu)網(wǎng)絡(luò)塊共存并以模塊化方式更新。 ? Jupiter 從一個(gè)標(biāo)準(zhǔn)的 Clos 拓?fù)溟_始,它為任意可接受的流量模式提供最佳吞吐量。為了利用生產(chǎn)網(wǎng)絡(luò)中的閑置的容量并解決 Clos 結(jié)構(gòu)中的主干塊的技術(shù)更新挑戰(zhàn),作者將 Jupiter 演變?yōu)橹苯舆B接拓?fù)洌橛^察到的塊級流量模式啟用動(dòng)態(tài)流量和拓?fù)涔こ獭Ec傳統(tǒng)的 Clos 方法相比,這樣做可以實(shí)現(xiàn)相當(dāng)?shù)耐掏铝亢透痰钠骄窂剑送膺€可以節(jié)省大量的資本支出和運(yùn)營支出。?



















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論