 電子發燒友App
電子發燒友App


InfiniBand是目前發展最快的高速互連網絡技術之一,具有高帶寬、低延遲和易擴展的特點。通過研究和實踐,對InfiniBand技術的數據包、數據傳輸、層次結構、與以太網技術的對比、交換機制、發展愿景等進行了全面探索。
1. 引言
隨著中央處理器(CPU)運算能力的極速增長,高速互連網絡HIS (High Speed Interconnection)已成為高性能計算機研制的關鍵所在。HSI 是改善計算機外圍元件擴展接口(Peripheral Component Interface,PCI) 的性能不足而提出的一項新技術。經過多年的發展,支持高性能計算(High Performance Computing,HPC) 的HSI目前主要是Gigabit Ethernet 和InfiniBand,而InfiniBand 是其中增長最快的HSI。InfiniBand 是在InfiniBand貿易協會(IBTA)監督下發展起來的一種高性能、低延遲的技術。
2. InfiniBand Trade Association(IBTA)?
IBTA 成立于1999年,由Future I/O Developers Forum 和NGI/O Forum 兩個工業組織合二為一組成,在HP、IBM、Intel、Mellanox、Oracle、QLogic、Dell、Bull 等組成的籌劃運作委員會領導下工作。IBTA 專業從事產品的遵從性和互用性測試,其成員一直致力于推進InfiniBand 規范的設立與更新。
3.InfiniBand 概述
InfiniBand是一種針對處理器與I/O 設備之間數據流的通信鏈路,其支持的可尋址設備高達64000 個。InfiniBand架構(InfiniBand Architecture,IBA) 是一種定義點到點(point-to-point)交換式的輸入/ 輸出框架的行業標準規范,通常用于服務器、通信基礎設施、存儲設備和嵌入式系統的互連。
InfiniBand具有普適、低延遲、高帶寬、管理成本低的特性,是單一連接多數據流(聚類、通信、存儲、管理)理想的連接網絡,互連節點可達成千上萬。最小的完整IBA 單元是子網(subnet),多個子網由路由器連接起來組成大的IBA 網絡。IBA 子網由端節點(end-node)、交換機、鏈路和子網管理器組成。
InfiniBand發展的初衷是把服務器總線網絡化,所以InfiniBand 除了具有很強的網絡性能以外還直接繼承了總線的高帶寬和低時延。總線技術中采用的DMA(Direct Memory Access) 技術在InfiniBand 中以RDMA (Remote Direct Memory Access)的形式得以實現。RDMA服務可在處理器之間進行跨網絡數據傳輸,數據直接在暫時內存之間傳遞,不需要操作系統介入或數據復制。RDMA 通過減少對帶寬和處理器開銷的需要降低了時延,這種效果是通過在NIC 的硬件中部署一項可靠的傳輸協議以及支持零復制網絡技術和內核內存旁路實現的。
這使得InfiniBand 在與、及存儲設備的數據交換方面天生地優于萬兆以太網以及光纖通道(FiberChannel)。InfiniBand 實現了基于客戶機- 服務器和消息傳遞的通信方案及基于存儲映射實現網絡通信的方案,將復雜的I/O系統與處理器、存儲設備分離,使I/O 子系統獨立,是一種基于I/O 通道共享機制的總線互連技術。
InfiniBand系統由信道適配器(Channel Adapter)、交換機、路由器、線纜和連接器組成。CA 分為主機信道適配器(Host Channel Adapter) 和目標信道適配器(Target ChannelAdapter)。IBA 交換機原理上與其它標準網絡交換機類似,但必須能滿足InfiniBand 的高性能和低成本的要求。InfiniBand 路由器是用來把大網絡分割為更小的子網,并用路由器連接在一起。HCA 是一個設備點,諸如服務器或存儲設備的IB 端節點通過該設備點連接到IB 網絡。TCA是信道適配器的一種特別形式,多用于存儲設備等嵌入式環境。
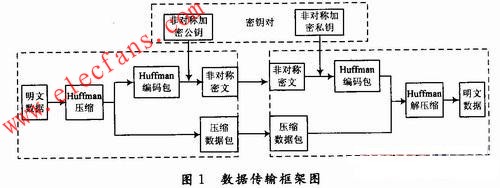
InfiniBand 體系結構如圖1所示
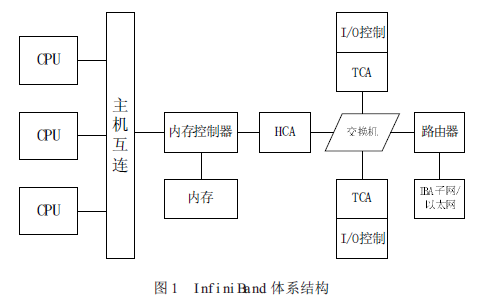
InfiniBand有幾大優勢,基于標準的協議、高速率、遠程直接內存存取(RDMA)、傳輸卸載(transport offload)、網絡分區和服務質量(QoS)。
標準:成立于1999年的IBTA 擁有300 多個成員,它們共同設計了IBA 開放標準。IBA 支持SRP(SCSI RDMA Protocol)和iSER(iSCSI Extensions for RDMA)存儲協議。
速率:InfiniBand傳輸速率目前已達168Gbps(12xFDR),遠遠高于萬兆光纖通道的10Gbps 和10 萬兆以太網的100Gbps。
內存:支持InfiniBand的服務器使用主機通道適配器(HCA),把協議轉換到服務器內部的PCI-X或PCI-E 總線。HCA 具有RDMA 功能,RDMA 通過一個虛擬的尋址方案,數據直接在服務器內存中傳輸,無需涉及操作系統的內核,這對于集群來說很適合。
傳輸卸載:RDMA實現了傳輸卸載,使數據包路由從操作系統轉到芯片級,大大節省了處理器的處理負擔。網絡分區:支持可編程的分區密鑰和路由。
服務質量:多層次的QoS 保障,滿足服務請求者對QoS需求的多樣性。
4.InfiniBand 數據包和數據傳輸
數據包(Packet)是InfiniBand 數據傳輸的基本單元。為使信息在InfiniBand 網絡中有效傳播,信息由信道適配器分割成許多的數據包。一個完整的IBA 數據包由本地路由報頭(Local Route Header)、全局路由報頭(Global Route Header)、基本傳輸報頭(Base TransportHeader)、擴展傳輸報頭(Extended Transport Header)、凈荷(Payload,PYLD)、固定循環冗余檢測(Invariant CRC,ICRC)和可變循環冗余檢測(Variant CRC,VCRC)等域(field)組成,如圖2 所示。
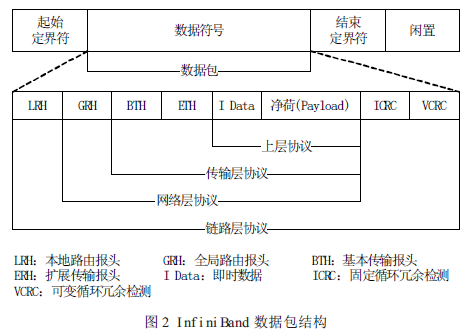
LRH:8 字節,用于交換機轉發數據包時確定本地源端口和目的端口以及規范數據包傳輸的服務等級和虛通路(Virtual Lane,VL)。
GRH:40 字節,用于對子網間的數據包進行路由,確保數據包在子網之間的正確傳輸。它由LRH 中的Link Next Header(LNH)域指定,采用RFC 2460 定義的IPv6 報頭規范。
BTH:12 字節,指明目的隊列偶(Queue Pair,QP)、指示操作碼、數據包序列號和分段。
ETH:4-28 字節,提供可靠數據報(Datagram)服務。Payload (PYLD):0-4096 字節,被發送的端到端應用數據。
ICRC:4 字節,封裝數據包中從源地址發往目的地址時保持不變的數據。
VCRC:2 字節,封裝鏈接過程中可變的IBA 和原始(raw)數據包。VCRC 在結構(fabric)中可被重構。
InfiniBand數據包使用一個128 位的IPv6 擴展地址,其數據包包括InfiniBand GRH 中的源(HCA)和目的(TCA)地址,這些地址使InfiniBand 交換機可以立即將數據包直接交換到正確的設備上。
基于銅纜和光纖,InfiniBand物理層支持單線(1X)、4 線(4X)、8 線(8X)和12 線(12X)數據包傳輸。
InfiniBand標準支持單倍速(SDR)、雙倍速(DDR)、四倍速(QDR)、十四倍速(FDR)和增強倍速(EDR)數據傳輸速率,使InfiniBand 能夠傳輸更大的數據量( 見表1)。由于InfiniBand DDR/QDR 極大地改善了性能,所以它特別適合于傳輸大數據文件的應用,如分布式數據庫和數據挖掘應用。
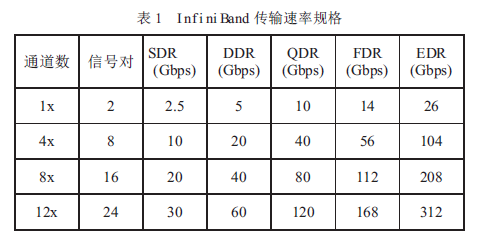
與InfiniBandSDR 一樣,DDR 和QDR 也采用了直通轉發技術(Cut-Through)。如果采用不同的傳輸速率,則InfiniBand 子網管理器須是拓撲透明(Topology-aware)的,并只把SDR 數據包轉發至SDR 連接(或把DDR 數據包轉發至DDR 連接),或者交換網絡須能存儲和轉發數據包以提供速率匹配。
當在SDR 和DDR 連接之間進行數據交換時,附加的存儲轉發延時是數據包串行化延時的一半。為了在SDR 主機和DDR 主機進行數據交換,DDR主機根據連接建立時交換產生的QP 參數進行限速傳輸。
5.InfiniBand 架構層次結構
根據IBTA 的定義,InfiniBand 架構由物理層、鏈路層、網絡層和傳輸層組成,其層次結構如圖3所示。
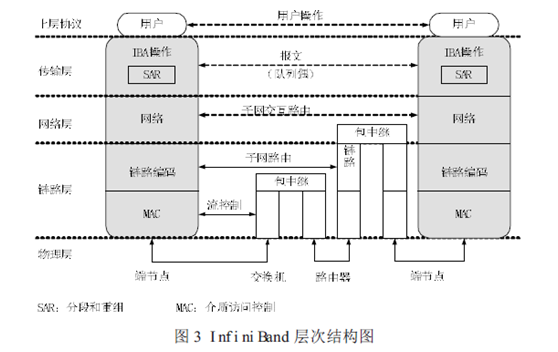
物理層:物理層為鏈路層提供服務,并提供這兩層的邏輯接口。物理層由端口信號連接器、物理連接(電信號和光信號)、硬件管理、電源管理、編碼線等模塊組成,其主要的作用:
(1)建立物理連接;
(2)通知鏈路層物理連接是否有效;
(3)監聽物理連接狀態,在物理連接有效時,把控制信號和數據傳遞給鏈路層,傳輸從鏈路層來的控制和數據信息。
鏈路層:鏈路層負責處理數據包中鏈接數據的收發,提供地址、緩沖、流控制、錯誤檢測和數據交換等服務。服務質量(QoS)主要由該層體現。狀態機(state machine)用來把鏈路層的邏輯操作定義為外部可訪問操作,并不指定內部操作。
例如,雖然我們希望鏈路層的操作能夠并行處理數據流的多個字節,但數據包接收狀態機還是將從鏈路層接收到的數據作為字節流來處理。
網絡層:網絡層負責對IBA 子網間的數據包進行路由,包括單點傳送(unicast)和多點傳送(multicast)操作。網絡層不指定多協議路由(如非IBA 類型之上的IBA 路由),也不指定IBA 子網間原始數據包是如何路由。
傳輸層:每個IBA數據包含有一個傳輸報頭(header)。傳輸報頭包含了端節點所需的信息以完成指定的操作。通過操控QP,傳輸層的IBA 通道適配器通信客戶端組成了“發送”工作隊列和“接收”工作隊列。
對于主機來說,傳輸層的客戶端是一個Verbs 軟件層,客戶端傳遞緩沖器或命令至這些隊列,硬件則往來傳送緩沖器數據。當建立QP時,它融合了四種IBA 傳輸服務類型(可靠的連接、可靠的自帶尋址信息、不可靠的自帶尋址信息、不可靠的連接)中的一種或非IBA協議封裝服務。傳輸服務描述了可靠性和QP 傳送數據的工作原理和傳輸內容。
6.InfiniBand 的交換機制
InfiniBand所采用的交換結構(Switched Fabric)是一種面向系統故障容忍性和可擴展性的基于交換的點到點互聯結構。
交換機主要作用是把數據包送達數據包本地路由報頭指定的目標地址,同時交換機也耗用數據包以滿足自管理的需要。IBA 交換機是內部子網路由的基本路由構件(子網間路由功能由IBA 路由器提供)。交換機的相互連接由鏈路間的中繼數據包(relaying packets)來完成。
InfiniBand交換機實現的功能有:子網管理代理(SMA)、性能管理代理(PMA)和基板管理代理(BMA)。SMA 提供一個讓子網管理者通過子網管理包獲得交換機內部的記錄和表數據的接口,實現消息通知、服務等級(Service Level,SL)到虛路徑(Virtual Lane,VL)的映射、VL 仲裁、多播轉發、供應商特性等功能。PMA 提供一個讓性能管理者監控交換機的數據吞吐量和錯誤累計量等性能信息的接口。BMA 在基板管理者和底架管理者之間提供一個通信通道。
InfiniBand交換機的數據轉發主要功能:
(1)選擇輸出端口:根據數據包的本地目的標識符(Destination Local Identifier,DLID),交換機從轉發表中查出輸出端口的端口號。
(2)選擇輸出VL:支持SL 和VL。交換機根據SL-VL 映射表確定不同優先級別的數據包所使用輸出端口的VL。
(3)數據流控制:采用基于信用的鏈路級流控機制。
(4)支持單播、多播和廣播:交換機能把多播包或廣播包轉換為多個單播包進行交換。
(5)分區劃分:只有同一分區的主機才能相互通信。每個分區具有唯一的分區密鑰,交換機檢查數據包的DLID 是否在密鑰所對應的分區內。
(6)錯誤校驗:包括不一致錯誤檢驗、編碼錯誤校驗、成幀錯誤校驗、包長度校驗、包頭版本校驗、服務級別有效性校驗、流控制遵從和最大傳輸單元校驗。
(7)VL 仲裁:支持子網VL(包括管理VL15 和數據VL)。交換機采用VL 仲裁保證優先級高的數據包得到更好的服務。
目前生產InfiniBand交換機的廠商主要有Mallanox、QLogic、Cisco、IBM 等。
7.InfiniBand 與以太網
從InfiniBand的誕生、發展,到現在占據HPC 領域的主流地位,人們總會拿它與普遍采用的以太網技術做比較。作者整理兩者的比較如表2 所示。
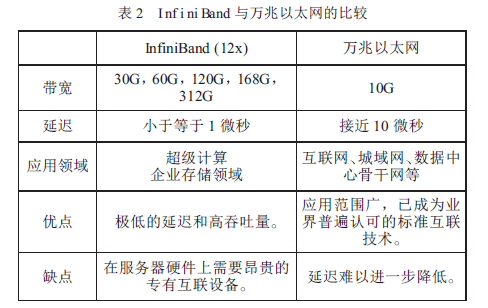
從表2 可知,InfiniBand 在數據傳輸和低延遲兩方面大大超過了以太網。InfiniBand 的低延遲設計使得它極其適合高性能計算領域。此外,InfiniBand 在單位成本方面也具有相當的優勢。
從最新的全球HPCTOP500中可以發現,Infiniband 的占有率不斷提高,其在TOP100 中更是占主導地位,而以太網的占有率則逐年下降,目前兩者在HPC 領域的占有率基本持平。
8.結束語 ? ?
隨著InfiniBand的不斷發展,它已成為取代千兆/ 萬兆以太網的最佳方案,必將成為高速互連網絡的首選,其與以太網絡、iSCSI 融合將更加緊密。IBTA 對InfiniBand的發展作出了預測,表明在未來三年里InfiniBand FDR、EDR 和HDR 將有快速增長的市場需求,2020 年之前InfiniBand 的帶寬將有望達到1000Gbps。InfiniBand 未來在GPU、固態硬盤和集群數據庫方面將有廣闊的應用前景。
編輯:黃飛
?











 工商網監
工商網監
評論