 電子發(fā)燒友App
電子發(fā)燒友App


握手失敗
第一次握手丟失了,會發(fā)生什么?
當(dāng)客戶端想和服務(wù)端建立 TCP 連接的時候,首先第一個發(fā)的就是 SYN 報文,然后進入到?SYN_SENT?狀態(tài)。
在這之后,如果客戶端遲遲收不到服務(wù)端的 SYN-ACK 報文(第二次握手),就會觸發(fā)超時重傳機制。
不同版本的操作系統(tǒng)可能超時時間不同,有的 1 秒的,也有 3 秒的,這個超時時間是寫死在內(nèi)核里的,如果想要更改則需要重新編譯內(nèi)核,比較麻煩。
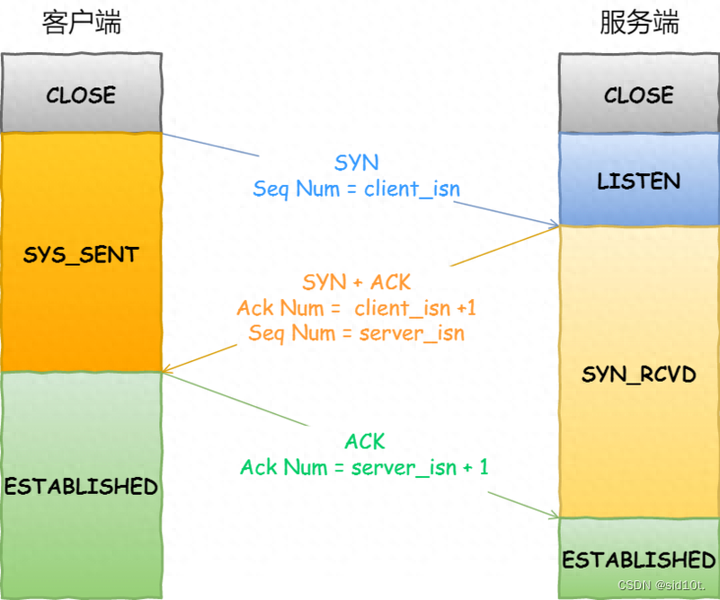
當(dāng)客戶端在 1 秒后沒收到服務(wù)端的 SYN-ACK 報文后,客戶端就會重發(fā) SYN 報文,那到底重發(fā)幾次呢?
在 Linux 里,客戶端的 SYN 報文最大重傳次數(shù)由?tcp_syn_retries?內(nèi)核參數(shù)控制,這個參數(shù)是可以自定義的,默認(rèn)值一般是 5。
[root@localhost ~]# cat /proc/sys/net/ipv4/tcp_syn_retries5
通常,第一次超時重傳是在 1 秒后,第二次超時重傳是在 2 秒,第三次超時重傳是在 4 秒后,第四次超時重傳是在 8 秒后,第五次是在超時重傳 16 秒后。沒錯,每次超時的時間是上一次的 2 倍。
當(dāng)?shù)谖宕纬瑫r重傳后,會繼續(xù)等待 32 秒,如果服務(wù)端仍然沒有回應(yīng) ACK,客戶端就不再發(fā)送 SYN 包,然后斷開 TCP 連接。
所以,總耗時是 1+2+4+8+16+32=63 秒,大約 1 分鐘左右。
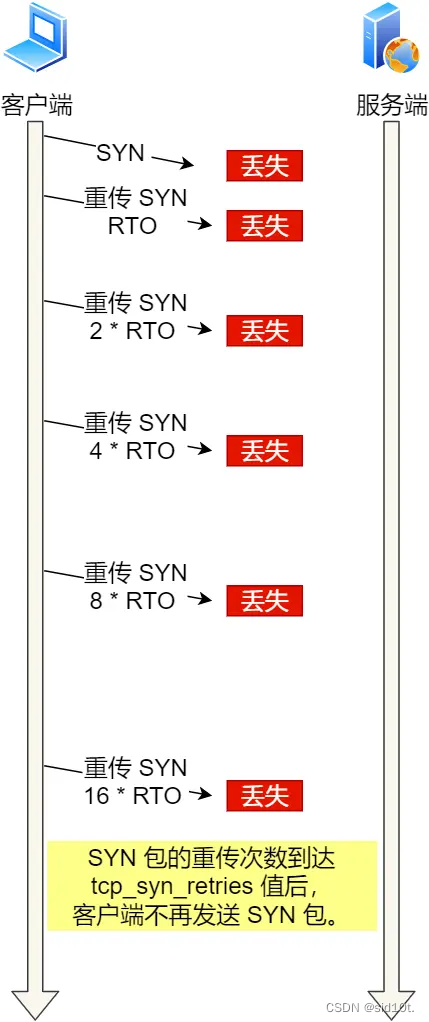
場景復(fù)現(xiàn)
在服務(wù)端先 ban 掉客戶端的 IP?iptables -I INPUT -s 客戶端 IP -j DROP,然后客戶端通過?curl?指令去訪問服務(wù)端:


可以自己設(shè)置?tcp_syn_retries:
[root@localhost ~]# echo 6 > /proc/sys/net/ipv4/tcp_syn_retries
第二次握手丟失了,會發(fā)生什么?
當(dāng)服務(wù)端收到客戶端的第一次握手后,就會回 SYN-ACK 報文給客戶端,這個就是第二次握手,此時服務(wù)端會進入 SYN_RCVD 狀態(tài)。
第二次握手的 SYN-ACK 報文其實有兩個目的 :
第二次握手里的 ACK, 是對第一次握手的確認(rèn)報文;
第二次握手里的 SYN,是服務(wù)端發(fā)起建立 TCP 連接的報文;
所以,如果第二次握手丟了,就會發(fā)送比較有意思的事情,具體會怎么樣呢?
因為第二次握手報文里是包含對客戶端的第一次握手的 ACK 確認(rèn)報文,所以,如果客戶端遲遲沒有收到第二次握手,那么客戶端就覺得可能自己的 SYN 報文(第一次握手)丟失了,于是客戶端就會觸發(fā)超時重傳機制,重傳 SYN 報文。
然后,因為第二次握手中包含服務(wù)端的 SYN 報文,所以當(dāng)客戶端收到后,需要給服務(wù)端發(fā)送 ACK 確認(rèn)報文(第三次握手),服務(wù)端才會認(rèn)為該 SYN 報文被客戶端收到了。
那么,如果第二次握手丟失了,服務(wù)端就收不到第三次握手,于是服務(wù)端這邊會觸發(fā)超時重傳機制,重傳 SYN-ACK 報文。
在 Linux 下,SYN-ACK 報文的最大重傳次數(shù)由 tcp_synack_retries 內(nèi)核參數(shù)決定,默認(rèn)值是 5。
因此,當(dāng)?shù)诙挝帐謥G失了,客戶端和服務(wù)端都會重傳:
客戶端會重傳 SYN 報文,也就是第一次握手,最大重傳次數(shù)由?tcp_syn_retries?內(nèi)核參數(shù)決定;
服務(wù)端會重傳 SYN-AKC 報文,也就是第二次握手,最大重傳次數(shù)由?tcp_synack_retries?內(nèi)核參數(shù)決定。
場景復(fù)現(xiàn)
這時候解除服務(wù)端 ban 掉的 客戶端的IP iptables -D INPUT -s 客戶端 IP -j DROP,轉(zhuǎn)而讓客戶端 ban 掉服務(wù)端的 IP,這樣的話,客戶端發(fā)送的 SYN 包能被服務(wù)端收到,但是服務(wù)端返回的 ACK 包會在網(wǎng)絡(luò)層就被嘎掉,無法到達傳輸層交給 TCP 解析,因此就人為的造成了第二次握手失敗的場景;
客戶端設(shè)置了防火墻,屏蔽了服務(wù)端的網(wǎng)絡(luò)包,為什么 tcpdump 還能抓到服務(wù)端的網(wǎng)絡(luò)包?
添加 iptables 限制后, tcpdump 是否能抓到包 ,這要看添加的 iptables 限制條件:
如果添加的是 INPUT 規(guī)則,則可以抓得到包;
如果添加的是 OUTPUT 規(guī)則,則抓不到包;
網(wǎng)絡(luò)包進入主機后的順序如下:
進來的順序 Wire -> NIC -> tcpdump -> netfilter/iptables;
出去的順序 iptables -> tcpdump -> NIC -> Wire;
第三次握手丟失了,會發(fā)生什么?
客戶端收到服務(wù)端的 SYN-ACK 報文后,就會給服務(wù)端回一個 ACK 報文,也就是第三次握手,此時客戶端狀態(tài)進入到 ESTABLISH 狀態(tài)。
因為這個第三次握手的 ACK 是對第二次握手的 SYN 的確認(rèn)報文,所以當(dāng)?shù)谌挝帐謥G失了,如果服務(wù)端那一方遲遲收不到這個確認(rèn)報文,就會觸發(fā)超時重傳機制,重傳 SYN-ACK 報文,直到收到第三次握手,或者達到最大重傳次數(shù)。
注意,ACK 報文是不會有重傳的,當(dāng) ACK 丟失了,就由對方重傳對應(yīng)的報文。
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3 +0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0 +0 bind(3, ..., ...) = 0 +0 listen(3, 1) = 0 +0 `echo socket is listening!` +0 < S 0:0(0) win 4000+0> S. 0:0(0) ack 1 <...> +0 `sleep 1000000`
?

揮手失敗
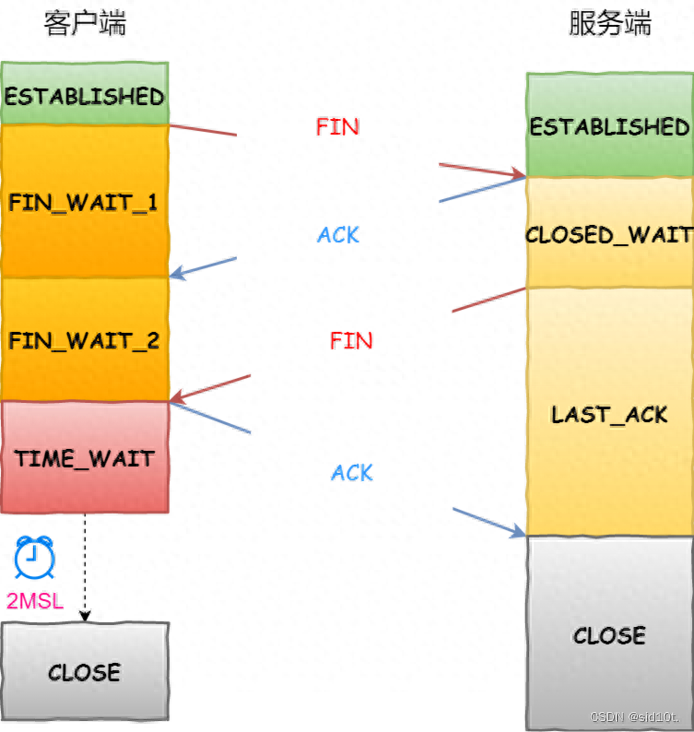
第一次揮手丟失了,會發(fā)生什么?
當(dāng)客戶端(主動關(guān)閉方)調(diào)用 close 函數(shù)后,就會向服務(wù)端發(fā)送 FIN 報文,試圖與服務(wù)端斷開連接,此時客戶端的連接進入到?FIN_WAIT_1?狀態(tài)。
正常情況下,如果能及時收到服務(wù)端(被動關(guān)閉方)的 ACK,則會很快變?yōu)?FIN_WAIT2 狀態(tài)。
如果第一次揮手丟失了,那么客戶端遲遲收不到被動方的 ACK 的話,也就會觸發(fā)超時重傳機制,重傳 FIN 報文,重發(fā)次數(shù)由 tcp_orphan_retries 參數(shù)控制。
當(dāng)客戶端重傳 FIN 報文的次數(shù)超過 tcp_orphan_retries 后,就不再發(fā)送 FIN 報文,直接進入到 CLOSE 狀態(tài)。
第二次揮手丟失了,會發(fā)生什么?
當(dāng)服務(wù)端收到客戶端的第一次揮手后,就會先回一個 ACK 確認(rèn)報文,此時服務(wù)端的連接進入到?CLOSE_WAIT?狀態(tài)。
在前面我們也提了,ACK 報文是不會重傳的,所以如果服務(wù)端的第二次揮手丟失了,客戶端就會觸發(fā)超時重傳機制,重傳 FIN 報文,直到收到服務(wù)端的第二次揮手,或者達到最大的重傳次數(shù)。
這里提一下,當(dāng)客戶端收到第二次揮手,也就是收到服務(wù)端發(fā)送的 ACK 報文后,客戶端就會處于 FIN_WAIT2 狀態(tài),在這個狀態(tài)需要等服務(wù)端發(fā)送第三次揮手,也就是服務(wù)端的 FIN 報文。
對于 close 函數(shù)關(guān)閉的連接,由于無法再發(fā)送和接收數(shù)據(jù),所以 FIN_WAIT2 狀態(tài)不可以持續(xù)太久,而 tcp_fin_timeout 控制了這個狀態(tài)下連接的持續(xù)時長,默認(rèn)值是 60 秒。
這意味著對于調(diào)用 close 關(guān)閉的連接,如果在 60 秒后還沒有收到 FIN 報文,客戶端(主動關(guān)閉方)的連接就會直接關(guān)閉。
第三次揮手丟失了,會發(fā)生什么?
當(dāng)服務(wù)端(被動關(guān)閉方)收到客戶端(主動關(guān)閉方)的 FIN 報文后,內(nèi)核會自動回復(fù) ACK,同時連接處于?CLOSE_WAIT?狀態(tài),顧名思義,它表示等待應(yīng)用進程調(diào)用 close 函數(shù)關(guān)閉連接。
此時,內(nèi)核是沒有權(quán)利替代進程關(guān)閉連接,必須由進程主動調(diào)用 close 函數(shù)來觸發(fā)服務(wù)端發(fā)送 FIN 報文。
服務(wù)端處于 CLOSE_WAIT 狀態(tài)時,調(diào)用了 close 函數(shù),內(nèi)核就會發(fā)出 FIN 報文,同時連接進入 LAST_ACK 狀態(tài),等待客戶端返回 ACK 來確認(rèn)連接關(guān)閉。
如果遲遲收不到這個 ACK,服務(wù)端就會重發(fā) FIN 報文,重發(fā)次數(shù)仍然由 tcp_orphan_retries 參數(shù)控制,這與客戶端重發(fā) FIN 報文的重傳次數(shù)控制方式是一樣的。
?
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3 +0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0 +0 bind(3, ..., ...) = 0 +0 listen(3, 1) = 0 +0 `echo socket is listening!` +0 < S 0:0(0) win 4000+0 > S. 0:0(0) ack 1 <...> +.1 < . 1:1(0) ack 1 win 1000 +0 accept(3, ..., ...) = 4 +0 `echo connection established!` +0 < F. 1:1(0) ack 1 win 1000 +0 > . 1:1(0) ack 2 +0.1 close(4)=0 +0 > F. 1:1(0) ack 2 <...> +0 `sleep 1000000`
?

第四次揮手丟失了,會發(fā)生什么?
當(dāng)客戶端收到服務(wù)端的第三次揮手的 FIN 報文后,就會回 ACK 報文,也就是第四次揮手,此時客戶端連接進入?TIME_WAIT?狀態(tài)。
在 Linux 系統(tǒng),TIME_WAIT?狀態(tài)會持續(xù) 60 秒后才會進入關(guān)閉狀態(tài)。
然后,服務(wù)端(被動關(guān)閉方)沒有收到 ACK 報文前,還是處于?LAST_ACK?狀態(tài)。
如果第四次揮手的 ACK 報文沒有到達服務(wù)端,服務(wù)端就會重發(fā) FIN 報文,重發(fā)次數(shù)仍然由前面介紹過的?tcp_orphan_retries?參數(shù)控制。
為什么是三次握手?
現(xiàn)在耳熟能詳?shù)?TCP 連接就是三次握手,四次揮手,那么你有想過?為什么是三次握手,而不是兩次或者四次呢?
相信比較平常回答的是:“因為三次握手才能保證雙方具有接收和發(fā)送的能力”。這樣的回答是沒問題的,但是這回答是片面的,并沒有說出主要的原因。
在前面我們知道了什么是 TCP 連接:用于保證可靠性和流量控制維護的某些狀態(tài)信息,這些信息的組合,包括 Socket、序列號和窗口大小稱為連接。
所以,重要的是為什么三次握手才可以初始化 Socket、序列號和窗口大小并建立 TCP 連接。
接下來以三個方面分析三次握手的原因:
三次握手才可以阻止重復(fù)歷史連接的初始化(主要原因);
三次握手才可以同步雙方的初始序列號;
三次握手才可以避免資源浪費;
原因一:避免歷史連接
RFC 793 指出的 TCP 連接使用三次握手的首要原因:
The principle reason for the three-way handshake is to prevent old duplicate connection initiations from causing confusion.
簡單來說,三次握手的首要原因是為了防止舊的重復(fù)連接初始化造成混亂。
網(wǎng)絡(luò)環(huán)境是錯綜復(fù)雜的,往往并不是如我們期望的一樣,先發(fā)送的數(shù)據(jù)包,就先到達目標(biāo)主機;可能會由于網(wǎng)絡(luò)擁堵等亂七八糟的原因,會使得舊的數(shù)據(jù)包,先到達目標(biāo)主機。那么這種情況下 TCP 三次握手是如何避免的呢?
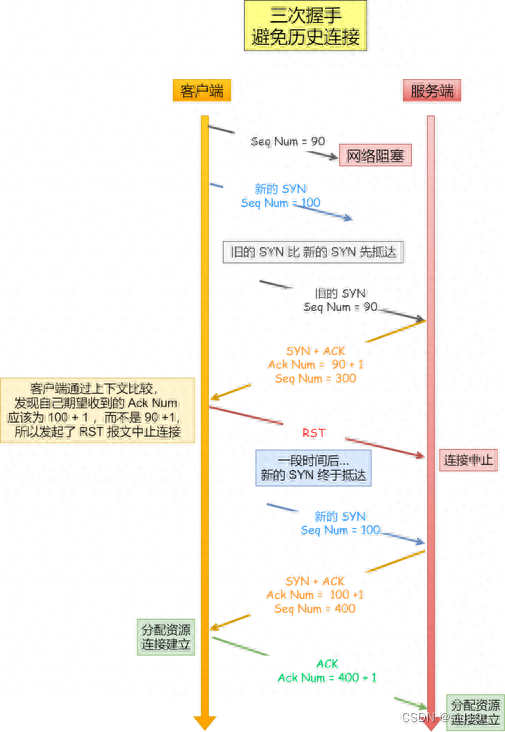
客戶端連續(xù)發(fā)送多次 SYN 建立連接的報文,在網(wǎng)絡(luò)擁堵情況下:
一個「舊 SYN 報文」比「最新的 SYN 」 報文早到達了服務(wù)端;
那么此時服務(wù)端就會回一個 SYN + ACK 報文給客戶端;
客戶端收到后可以根據(jù)自身的上下文,判斷這是一個歷史連接(序列號過期或超時),那么客戶端就會發(fā)送 RST 報文給服務(wù)端,表示中止這一次連接。
如果是兩次握手連接,就不能判斷當(dāng)前連接是否是歷史連接,三次握手則可以在客戶端(發(fā)送方)準(zhǔn)備發(fā)送第三次報文時,客戶端因有足夠的上下文來判斷當(dāng)前連接是否是歷史連接:
如果是歷史連接(序列號過期或超時),則第三次握手發(fā)送的報文是 RST 報文,以此中止歷史連接;
如果不是歷史連接,則第三次發(fā)送的報文是 ACK 報文,通信雙方就會成功建立連接;
所以,TCP 使用三次握手建立連接的最主要原因是防止歷史連接初始化了連接。
原因二:同步雙方初始序列號
TCP 協(xié)議的通信雙方, 都必須維護一個「序列號」, 序列號是可靠傳輸?shù)囊粋€關(guān)鍵因素,它的作用:
接收方可以去除重復(fù)的數(shù)據(jù);
接收方可以根據(jù)數(shù)據(jù)包的序列號按序接收;
可以標(biāo)識發(fā)送出去的數(shù)據(jù)包中, 哪些是已經(jīng)被對方收到的;
可見,序列號在 TCP 連接中占據(jù)著非常重要的作用,所以當(dāng)客戶端發(fā)送攜帶「初始序列號」的 SYN 報文的時候,需要服務(wù)端回一個 ACK 應(yīng)答報文,表示客戶端的 SYN 報文已被服務(wù)端成功接收,那當(dāng)服務(wù)端發(fā)送「初始序列號」給客戶端的時候,依然也要得到客戶端的應(yīng)答回應(yīng),這樣一來一回,才能確保雙方的初始序列號能被可靠的同步。
四次握手與三次握手:
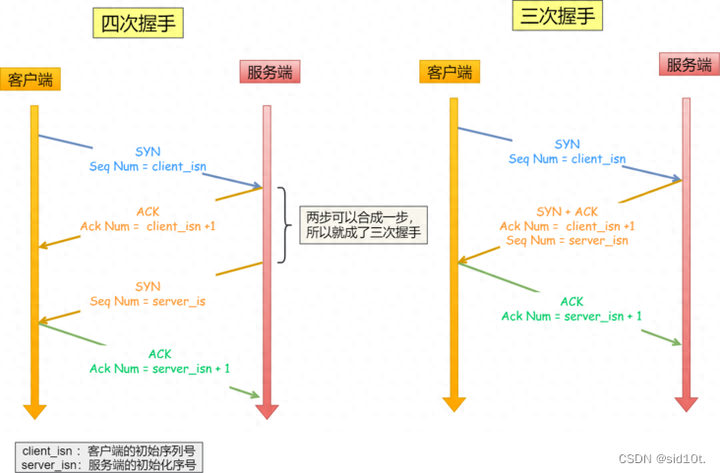
四次握手其實也能夠可靠的同步雙方的初始化序號,但由于第二步和第三步可以優(yōu)化成一步,所以就成了「三次握手」。
而兩次握手只保證了一方的初始序列號能被對方成功接收,沒辦法保證雙方的初始序列號都能被確認(rèn)接收。
原因三:避免資源浪費
如果只有「兩次握手」,當(dāng)客戶端的 SYN 請求連接在網(wǎng)絡(luò)中阻塞,客戶端沒有接收到 ACK 報文,就會重新發(fā)送 SYN ,由于沒有第三次握手,服務(wù)器不清楚客戶端是否收到了自己發(fā)送的建立連接的 ACK 確認(rèn)信號,所以每收到一個 SYN 就只能先主動建立一個連接,這會造成什么情況呢?
如果客戶端的 SYN 阻塞了,重復(fù)發(fā)送多次 SYN 報文,那么服務(wù)器在收到請求后就會建立多個冗余的無效鏈接,造成不必要的資源浪費。
兩次握手會造成資源浪費:
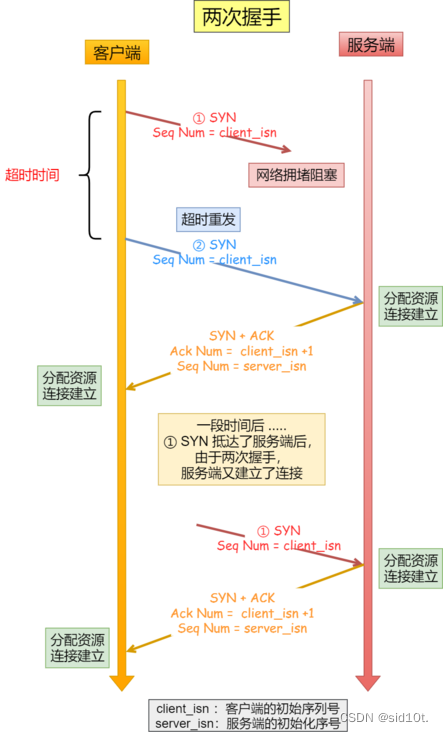
即兩次握手會造成消息滯留情況下,服務(wù)器重復(fù)接受無用的連接請求 SYN 報文,而造成重復(fù)分配資源。
小結(jié)
TCP 建立連接時,通過三次握手能:
防止歷史連接的建立,能減少雙方不必要的資源開銷;
能幫助雙方同步初始化序列號,序列號能夠保證數(shù)據(jù)包不重復(fù)、不丟棄和按序傳輸;
不使用「兩次握手」和「四次握手」的原因:
「兩次握手」:無法防止歷史連接的建立,會造成雙方資源的浪費,也無法可靠的同步雙方序列號;
「四次握手」:三次握手就已經(jīng)理論上最少可靠連接建立,所以不需要使用更多的通信次數(shù);
如何避免 SYN 攻擊?
什么是 SYN 攻擊?
在了解如何避免 SYN 攻擊前,我們得先了解什么是 SYN 攻擊;
我們都知道 TCP 連接建立是需要三次握手,假設(shè)攻擊者短時間偽造不同 IP 地址的 SYN 報文,服務(wù)端每接收到一個 SYN 報文,就進入SYN_RCVD 狀態(tài),但服務(wù)端發(fā)送出去的 SYN + ACK 報文,無法得到未知 IP 主機的 ACK 應(yīng)答,久而久之就會占滿服務(wù)端的 SYN 接收隊列(未連接隊列),使得服務(wù)器不能為正常用戶服務(wù)。
也就是上面曾講述的?第三次握手失敗;
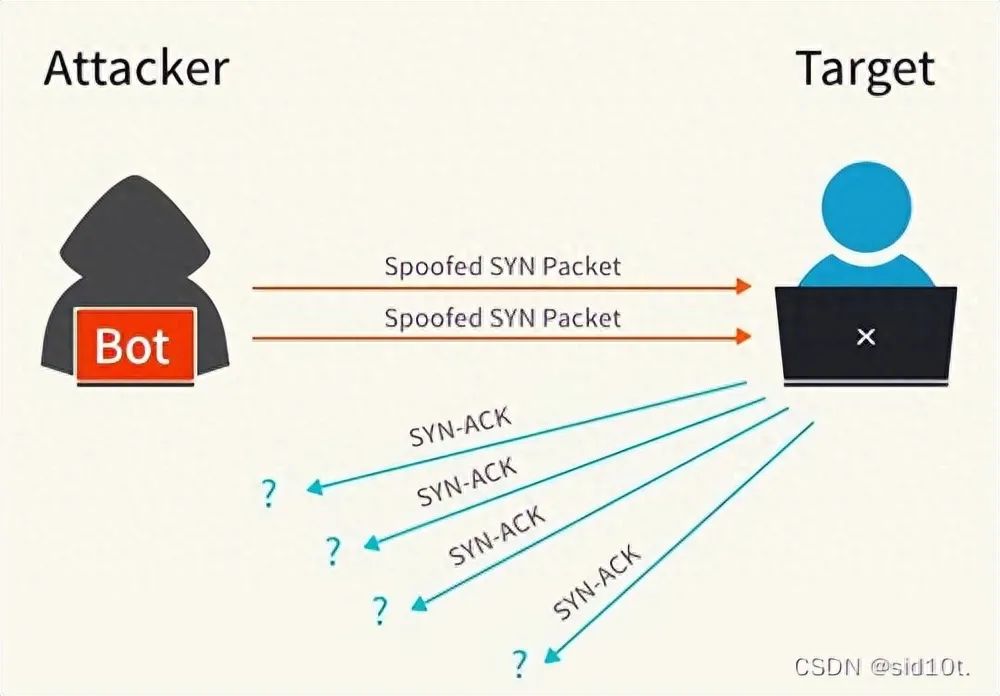
常用的工具有 LOIC,Hping3 等,演示攻擊如下:
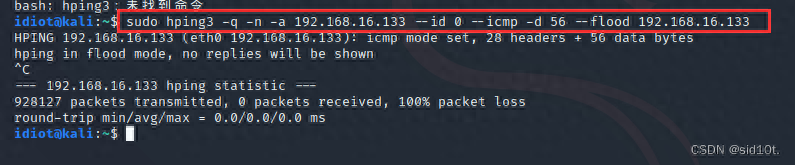
因為虛擬機的配置低,所以很容易就實現(xiàn) CPU 爆滿的狀況了,這時候服務(wù)器就很難響應(yīng)其他服務(wù)請求,更嚴(yán)重的可能會直接宕機;
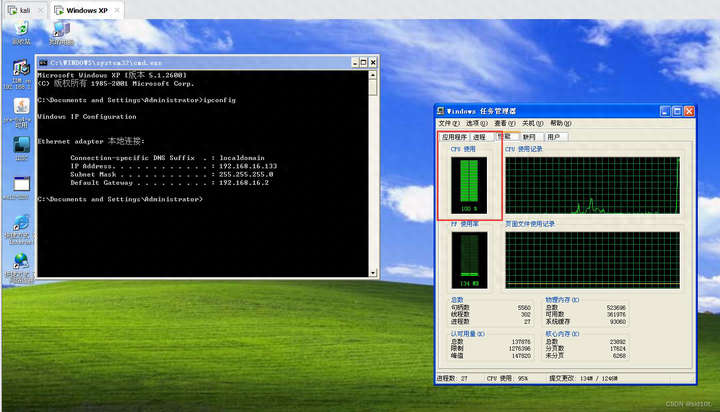
避免 SYN 攻擊方式一
第一種解決方式是通過修改 Linux 內(nèi)核參數(shù),控制隊列大小和當(dāng)隊列滿時應(yīng)做什么處理。
當(dāng)網(wǎng)卡接收數(shù)據(jù)包的速度大于內(nèi)核處理的速度時,會有一個隊列保存這些數(shù)據(jù)包。
控制該隊列的最大值:net.core.netdev_max_backlog;
SYN_RCVD 狀態(tài)連接的最大個數(shù):net.ipv4.tcp_max_syn_backlog;
超出處理能時,對新的 SYN 直接回報 RST,丟棄連接:net.ipv4.tcp_abort_on_overflow;
避免 SYN 攻擊方式二
我們先來看下 Linux 內(nèi)核的 SYN (未完成連接建立)隊列與 Accpet (已完成連接建立)隊列是如何工作的:
1、正常流程;
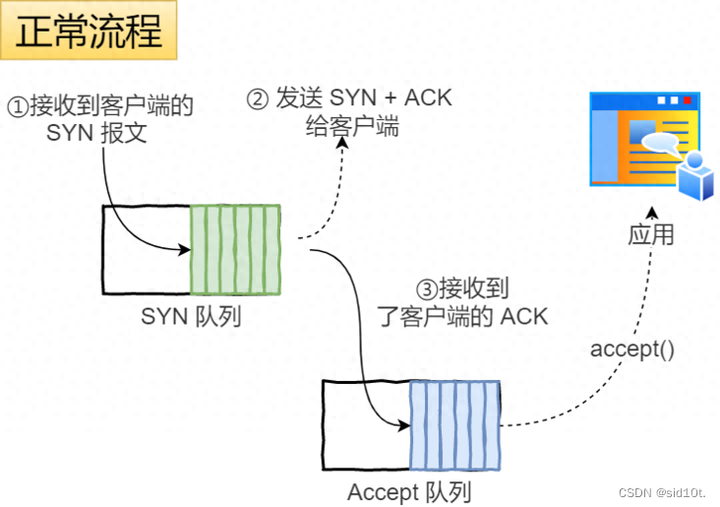
當(dāng)服務(wù)端接收到客戶端的 SYN 報文時,會將其加入到內(nèi)核的「 SYN 隊列」;
接著發(fā)送 SYN + ACK 給客戶端,等待客戶端回應(yīng) ACK 報文;
服務(wù)端接收到 ACK 報文后,從「 SYN 隊列」移除放入到「 Accept 隊列」;
應(yīng)用通過調(diào)用?accpet()?socket 接口,從「 Accept 隊列」取出連接。
2、應(yīng)用程序過慢;
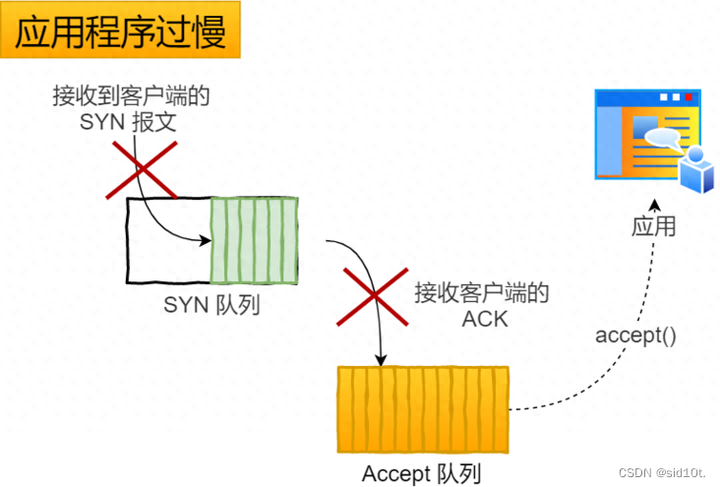
如果應(yīng)用程序過慢時,就會導(dǎo)致「 Accept 隊列」被占滿。
3、受到 SYN 攻擊;
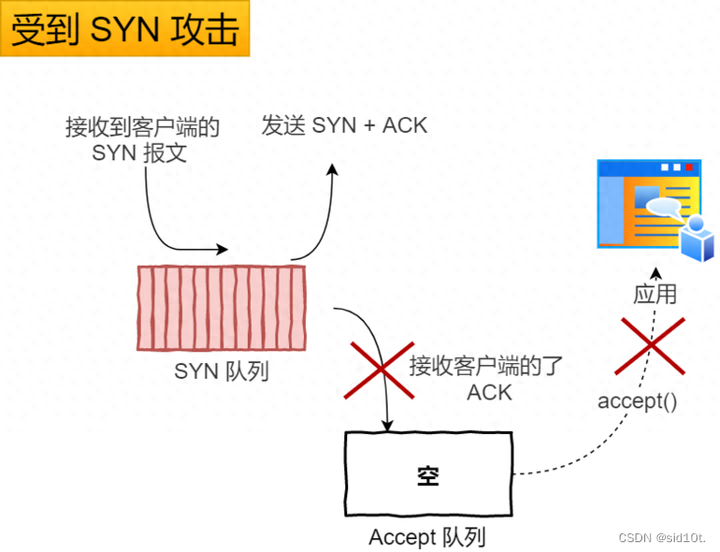
如果不斷受到 SYN 攻擊,就會導(dǎo)致「 SYN 隊列」被占滿。
tcp_syncookies?的方式可以應(yīng)對 SYN 攻擊的方法:net.ipv4.tcp_syncookies = 1
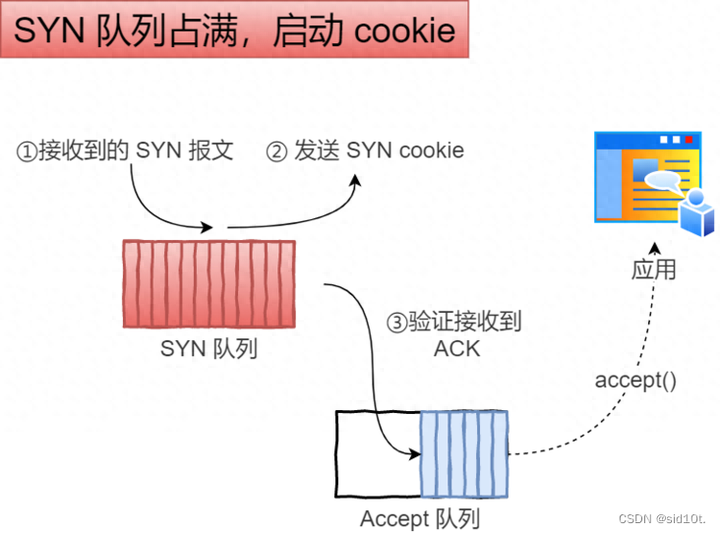
當(dāng) 「 SYN 隊列」?jié)M之后,后續(xù)服務(wù)器收到 SYN 包,不進入「 SYN 隊列」;
計算出一個 cookie 值,再以 SYN + ACK 中的「序列號」返回客戶端;
服務(wù)端接收到客戶端的應(yīng)答報文時,服務(wù)器會檢查這個 ACK 包的合法性,如果合法,直接放入到「 Accept 隊列」;
最后應(yīng)用通過調(diào)用?accpet()?socket 接口,從「 Accept 隊列」取出的連接。
MTU與 MSS 那些事兒
最大報文段長度?MSS?與 最大傳輸單元?MTU?均是協(xié)議用來定義最大長度的。不同的是,MTU 應(yīng)用于 OSI 模型的第二層數(shù)據(jù)鏈接層,并無具體針對的協(xié)議,限制了數(shù)據(jù)鏈接層上可以傳輸?shù)臄?shù)據(jù)包的大小,也因此限制了上層(網(wǎng)絡(luò)層)的數(shù)據(jù)包大小;MSS 針對的是 OSI 模型里的第四層傳輸層的 TCP 協(xié)議,因為 MSS 應(yīng)用的協(xié)議在數(shù)據(jù)鏈接層的上層,所以 MSS 會受到 MTU 的限制。
MTU:Maximum Transmission Unit,最大傳輸單元,由硬件規(guī)定,如以太網(wǎng)的 MTU 為1500字節(jié)。
MSS:Maximum Segment Size,最大分段大小,是 TCP 數(shù)據(jù)包每次傳輸?shù)淖畲髷?shù)據(jù)分段大小,一般由發(fā)送端向?qū)Χ?TCP 通知,對端在每個分節(jié)中能發(fā)送的最大 TCP 數(shù)據(jù)。MSS 值為 MTU 值減去IPv4 Header(20 Byte)和 TCP header(20 Byte)得到。
分片:Fragmentation,若 IP 數(shù)據(jù)報大小超過相應(yīng)鏈路的 MTU 的時候,IPV4 和 IPV6 都執(zhí)行分片操作,各片段到達目的地前通常不會被重組 (re-assembling)。IPV4 主機對其產(chǎn)生的數(shù)據(jù)報執(zhí)行分片,IPV4 路由器對其轉(zhuǎn)發(fā)的數(shù)據(jù)也執(zhí)行分片,然而 IPV6 只在數(shù)據(jù)產(chǎn)生的主機執(zhí)行分片,IPV6 路由器對其轉(zhuǎn)發(fā)的數(shù)據(jù)不執(zhí)行分片。
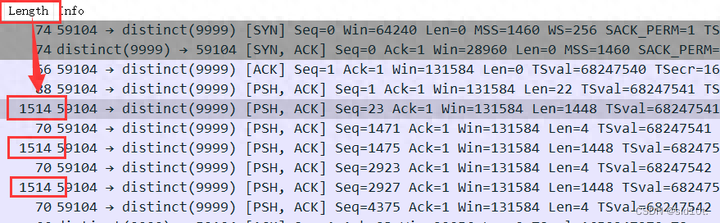
那么問題來了,為什么由 Wireshark 抓到的數(shù)據(jù)包的MSS = 1460,但卻在Len = 1448的時候就進行分包了呢?如下圖所示:
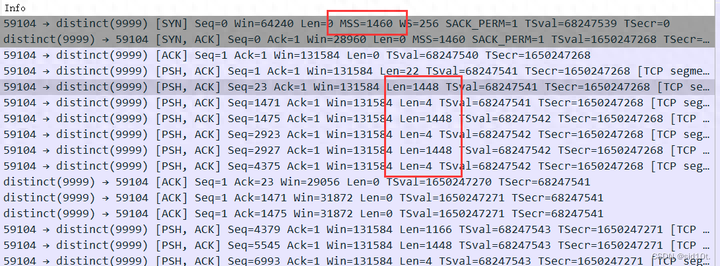
既然在握手階段就協(xié)商了?MSS = 1460,那為什么 TCP 的最大數(shù)據(jù)段長度卻只有 1448 bytes 呢?
原來在實際場景中,TCP 包頭中會帶有12字節(jié)的選項,時間戳(Timestamps),這樣,單個 TCP 包實際傳輸?shù)淖畲罅烤涂s減為1448字節(jié)了,如下所示:
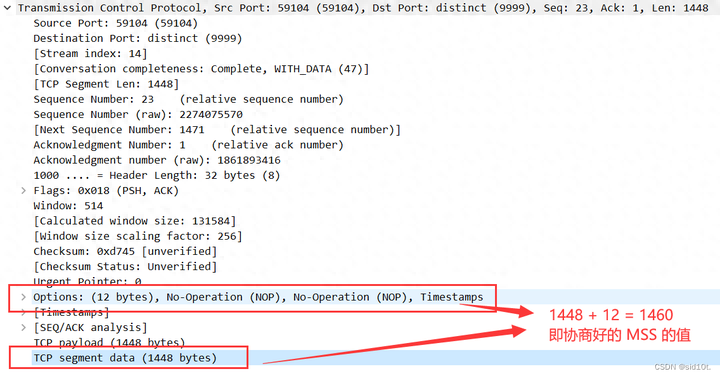
那 MTU = MSS + IP 頭長度 + TCP 頭長度,一般 IP 頭長度和 TCP 頭長度都為20,即MTU = MSS + 20 +20 = 1500,但是呢,從下圖中不難發(fā)現(xiàn),一個 TCP 包的總長度 Length 卻大于 MTU,這是為什么呢?
這是根據(jù)以太網(wǎng)幀結(jié)構(gòu)所決定的,至于如何判斷是否為以太網(wǎng),可以根據(jù)物理層中的[Protocols in frame: ethip:tcp]判定,這表示幀內(nèi)封裝的協(xié)議層次結(jié)構(gòu);
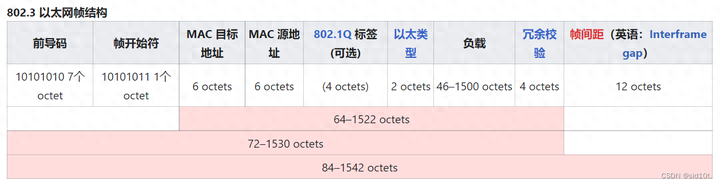
在不選擇填充 802.1Q 標(biāo)簽,負載拉滿(即為 MTU 值)的前提下,以太網(wǎng)的最大幀大小應(yīng)該是 前導(dǎo)碼+幀開始符+MAC目標(biāo)地址+MAC源地址+以太類型+負載+冗余校驗 = 7+1+6+6+2+1500+4 = 1526 字節(jié),那為什么 Wireshark 抓來的數(shù)據(jù)包的最大幀卻只有1514字節(jié)呢?
原來是因為當(dāng)數(shù)據(jù)幀到達網(wǎng)卡時,在物理層上網(wǎng)卡要先去掉前導(dǎo)碼和幀開始定界符,然后對幀進行 CRC 校驗:如果幀校驗和錯誤,就丟棄此幀;如果幀校驗和正確,就判斷該幀的 MAC 目的地址是否符合自己的接收條件,如果符合,就將此幀交付 設(shè)備驅(qū)動程序 做進一步處理。這時 Wireshark 才能抓到數(shù)據(jù),因此,Wireshark 抓到的是去掉前導(dǎo)碼、幀開始分界符、CRC校驗之外的數(shù)據(jù),其最大值是 6+6+2+1500=1514 字節(jié);
TIME_WAIT 的巧妙設(shè)計
為什么 TIME_WAIT 等待的時間是 2MSL?
MSL (Maximum Segment Lifetime),報文最大生存時間,它是任何報文在網(wǎng)絡(luò)上存在的最長時間,超過這個時間報文將被丟棄。因為 TCP 報文基于是 IP 協(xié)議的,而 IP 頭中有一個 TTL 字段,是 IP 數(shù)據(jù)報可以經(jīng)過的最大路由數(shù),每經(jīng)過一個處理他的路由器此值就減 1,當(dāng)此值為 0 則數(shù)據(jù)報將被丟棄,同時發(fā)送 ICMP 報文通知源主機。
MSL 與 TTL 的區(qū)別: MSL 的單位是時間,而 TTL 是經(jīng)過路由跳數(shù)。所以 MSL 應(yīng)該要大于等于 TTL 消耗為 0 的時間,以確保報文已被自然消亡。
TIME_WAIT 等待 2 倍的 MSL,比較合理的解釋是: 網(wǎng)絡(luò)中可能存在來自發(fā)送方的數(shù)據(jù)包,當(dāng)這些發(fā)送方的數(shù)據(jù)包被接收方處理后又會向?qū)Ψ桨l(fā)送響應(yīng),所以一來一回需要等待 2 倍的時間。
比如被動關(guān)閉方?jīng)]有收到斷開連接的最后的 ACK 報文,就會觸發(fā)超時重發(fā) FIN 報文,另一方接收到 FIN 后,會重發(fā) ACK 給被動關(guān)閉方, 一來一去正好 2 個 MSL。
2MSL 的時間是從客戶端接收到 FIN 后發(fā)送 ACK 開始計時的。如果在 TIME-WAIT 時間內(nèi),因為客戶端的 ACK 沒有傳輸?shù)椒?wù)端,客戶端又接收到了服務(wù)端重發(fā)的 FIN 報文,那么 2MSL 時間將重新計時。
在 Linux 系統(tǒng)里 2MSL 默認(rèn)是 60 秒,那么一個 MSL 也就是 30 秒。Linux 系統(tǒng)停留在 TIME_WAIT 的時間為固定的 60 秒。
其定義在 Linux 內(nèi)核代碼里的名稱為 TCP_TIMEWAIT_LEN:
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT state, about 60 seconds */
如果要修改?TIME_WAIT?的時間長度,只能修改 Linux 內(nèi)核代碼里?TCP_TIMEWAIT_LEN?的值,并重新編譯 Linux 內(nèi)核。
為什么需要 TIME_WAIT 狀態(tài)?
主動發(fā)起關(guān)閉連接的一方,才會有?TIME-WAIT?狀態(tài)。
需要?TIME-WAIT?狀態(tài),主要是兩個原因:
防止具有相同「四元組」的「舊」數(shù)據(jù)包被收到;
保證「被動關(guān)閉連接」的一方能被正確的關(guān)閉,即保證最后的 ACK 能讓被動關(guān)閉方接收,從而幫助其正常關(guān)閉;
原因一:防止舊連接的數(shù)據(jù)包
假設(shè)TIME-WAIT沒有等待時間或時間過短,被延遲的數(shù)據(jù)包抵達后會發(fā)生什么呢?
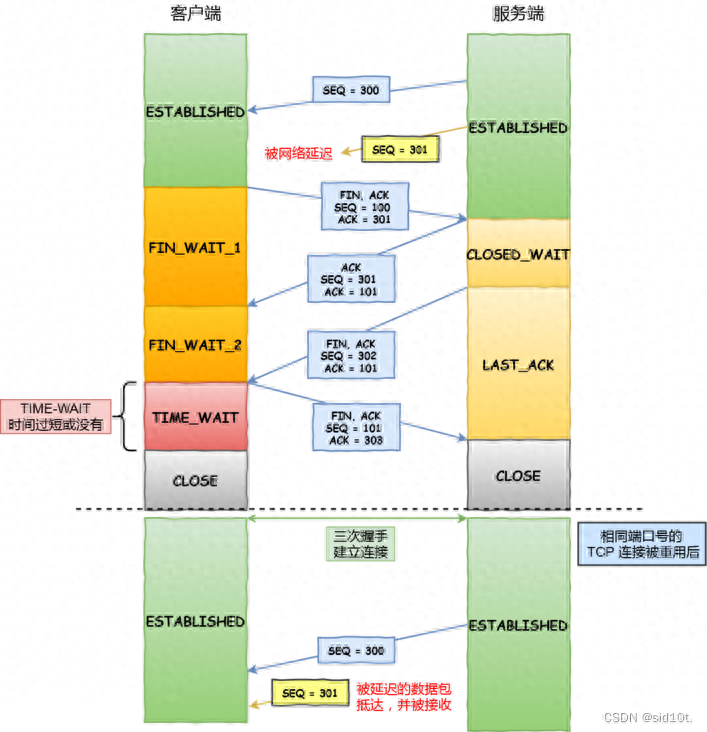
如上圖黃色框框服務(wù)端在關(guān)閉連接之前發(fā)送的?SEQ = 301?報文,被網(wǎng)絡(luò)延遲了。
這時有相同端口的 TCP 連接被復(fù)用后,被延遲的?SEQ = 301?抵達了客戶端,那么客戶端是有可能正常接收這個過期的報文,這就會產(chǎn)生數(shù)據(jù)錯亂等嚴(yán)重的問題。
所以,TCP 就設(shè)計出了這么一個機制,經(jīng)過 2MSL 這個時間,足以讓兩個方向上的數(shù)據(jù)包都被丟棄,使得原來連接的數(shù)據(jù)包在網(wǎng)絡(luò)中都自然消失,再出現(xiàn)的數(shù)據(jù)包一定都是新建立連接所產(chǎn)生的。
原因二:保證連接正確關(guān)閉
在 RFC 793 指出 TIME-WAIT 另一個重要的作用是:
TIME-WAIT - represents waiting for enough time to pass to be sure the remote TCP received the acknowledgment of its connection termination request.
也就是說,TIME-WAIT 作用是等待足夠的時間以確保最后的 ACK 能讓被動關(guān)閉方接收,從而幫助其正常關(guān)閉。
假設(shè) TIME-WAIT 沒有等待時間或時間過短,斷開連接會造成什么問題呢?
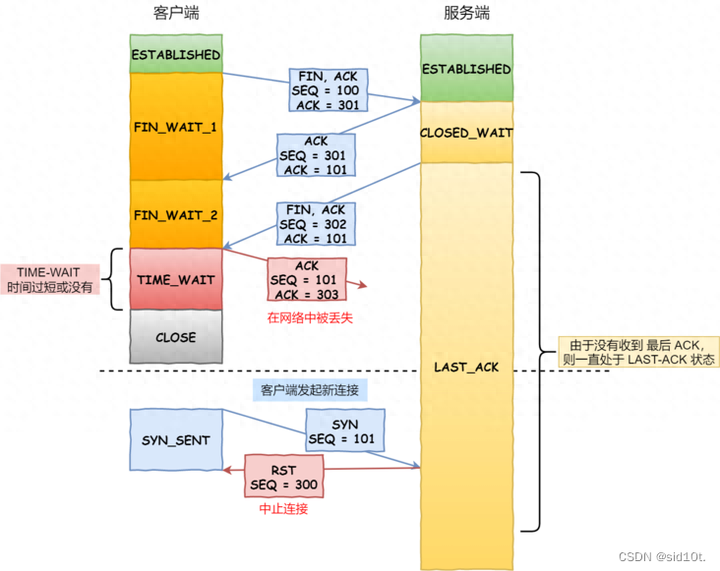
如上圖紅色框框客戶端四次揮手的最后一個 ACK 報文如果在網(wǎng)絡(luò)中被丟失了,此時如果客戶端 TIME-WAIT 過短或沒有,則就直接進入了 CLOSED 狀態(tài)了,那么服務(wù)端則會一直處在 LASE_ACK 狀態(tài)。
當(dāng)客戶端發(fā)起建立連接的 SYN 請求報文后,服務(wù)端會發(fā)送 RST 報文給客戶端,連接建立的過程就會被終止。
如果 TIME-WAIT 等待足夠長的情況就會遇到兩種情況:
服務(wù)端正常收到四次揮手的最后一個 ACK 報文,則服務(wù)端正常關(guān)閉連接。
服務(wù)端沒有收到四次揮手的最后一個 ACK 報文時,則會重發(fā) FIN 關(guān)閉連接報文并等待新的 ACK 報文。
所以客戶端在?TIME-WAIT?狀態(tài)等待 2MSL 時間后,就可以保證雙方的連接都可以正常的關(guān)閉。
TIME_WAIT 過長有什么危害?
如果服務(wù)器有處于?TIME-WAIT?狀態(tài)的 TCP,則說明是由服務(wù)器方主動發(fā)起的斷開請求。
過多的?TIME-WAIT?狀態(tài)主要的危害有兩種:
第一是內(nèi)存資源占用;
第二是對端口資源的占用,一個 TCP 連接至少消耗一個本地端口;
第二個危害是會造成嚴(yán)重的后果的,要知道,端口資源也是有限的,一般可以開啟的端口為 32768~61000,也可以通過參數(shù)設(shè)置指定
net.ipv4.ip_local_port_range,如果發(fā)起連接一方的?TIME_WAIT?狀態(tài)過多,占滿了所有端口資源,則會導(dǎo)致無法創(chuàng)建新連接。
客戶端受端口資源限制:
客戶端?TIME_WAIT?過多,就會導(dǎo)致端口資源被占用,因為端口就65536個,被占滿就會導(dǎo)致無法創(chuàng)建新的連接。
服務(wù)端受系統(tǒng)資源限制:
由于一個四元組表示 TCP 連接,理論上服務(wù)端可以建立很多連接,服務(wù)端確實只監(jiān)聽一個端口 但是會把連接扔給處理線程,所以理論上監(jiān)聽的端口可以繼續(xù)監(jiān)聽。但是線程池處理不了那么多一直不斷的連接了。所以當(dāng)服務(wù)端出現(xiàn)大量 TIME_WAIT 時,系統(tǒng)資源被占滿時,會導(dǎo)致處理不過來新的連接。
如何優(yōu)化 TIME_WAIT?
這里給出優(yōu)化?TIME-WAIT?的幾個方式,都是有利有弊:
方式一:net.ipv4.tcp_tw_reuse 和 tcp_timestamps
如下的 Linux 內(nèi)核參數(shù)開啟后,則可以復(fù)用處于 TIME_WAIT 的 socket 為新的連接所用。
有一點需要注意的是,tcp_tw_reuse 功能只能用于客戶端(連接發(fā)起方),因為開啟了該功能,在調(diào)用 connect() 函數(shù)時,內(nèi)核會隨機找一個 time_wait 狀態(tài)超過 1 秒的連接給新的連接復(fù)用。
net.ipv4.tcp_tw_reuse = 1
使用這個選項,還有一個前提,需要打開對 TCP 時間戳的支持,即 net.ipv4.tcp_timestamps=1(默認(rèn)即為 1),這個時間戳的字段是在 TCP 頭部的「選項」里,用于記錄 TCP 發(fā)送方的當(dāng)前時間戳和從對端接收到的最新時間戳。
由于引入了時間戳,我們在前面提到的 2MSL 問題就不復(fù)存在了,因為重復(fù)的數(shù)據(jù)包會因為時間戳過期被自然丟棄。
方式二:net.ipv4.tcp_max_tw_buckets
這個值默認(rèn)為 18000,當(dāng)系統(tǒng)中處于 TIME_WAIT 的連接一旦超過這個值時,系統(tǒng)就會將后面的 TIME_WAIT 連接狀態(tài)重置。
這個方法過于暴力,而且治標(biāo)不治本,帶來的問題遠比解決的問題多,不推薦使用。
方式三:程序中使用 SO_LINGER
我們可以通過設(shè)置 socket 選項,來設(shè)置調(diào)用 close 關(guān)閉連接行為。
?
struct linger so_linger; so_linger.l_onoff = 1; so_linger.l_linger = 0; setsockopt(s, SOL_SOCKET, SO_LINGER, &so_linger,sizeof(so_linger));
?
如果 l_onoff 為非 0, 且 l_linger 值為 0,那么調(diào)用 close 后,會立該發(fā)送一個 RST 標(biāo)志給對端,該 TCP 連接將跳過四次揮手,也就跳過了 TIME_WAIT 狀態(tài),直接關(guān)閉。
但這為跨越 TIME_WAIT 狀態(tài)提供了一個可能,不過是一個非常危險的行為,不值得提倡。
如果已經(jīng)建立了連接,但是客戶端突然出現(xiàn)故障了怎么辦?
TCP 有一個機制是保活機制。這個機制的原理是這樣的:
定義一個時間段,在這個時間段內(nèi),如果沒有任何連接相關(guān)的活動,TCP 保活機制會開始作用,每隔一個時間間隔,發(fā)送一個探測報文,該探測報文包含的數(shù)據(jù)非常少,如果連續(xù)幾個探測報文都沒有得到響應(yīng),則認(rèn)為當(dāng)前的 TCP 連接已經(jīng)死亡,系統(tǒng)內(nèi)核將錯誤信息通知給上層應(yīng)用程序。
在 Linux 內(nèi)核可以有對應(yīng)的參數(shù)可以設(shè)置保活時間、保活探測的次數(shù)、保活探測的時間間隔,以下都為默認(rèn)值:
?
net.ipv4.tcp_keepalive_time=7200 net.ipv4.tcp_keepalive_intvl=75 net.ipv4.tcp_keepalive_probes=9 # 表示保活時間是 7200 秒(2小時),也就 2 小時內(nèi)如果沒有任何連接相關(guān)的活動,則會啟動保活機制 tcp_keepalive_time=7200 # 表示每次檢測間隔 75 秒 tcp_keepalive_intvl=75 # 表示檢測 9 次無響應(yīng),認(rèn)為對方是不可達的,從而中斷本次的連接。 tcp_keepalive_probes=9:
?
也就是說在 Linux 系統(tǒng)中,最少需要經(jīng)過 2 小時 11 分 15 秒才可以發(fā)現(xiàn)一個「死亡」連接。
這個時間是有點長的,我們也可以根據(jù)實際的需求,對以上的保活相關(guān)的參數(shù)進行設(shè)置。
如果開啟了 TCP 保活,需要考慮以下幾種情況:
第一種,對端程序是正常工作的。當(dāng) TCP 保活的探測報文發(fā)送給對端, 對端會正常響應(yīng),這樣 TCP 保活時間會被重置,等待下一個 TCP 保活時間的到來。
第二種,對端程序崩潰并重啟。當(dāng) TCP 保活的探測報文發(fā)送給對端后,對端是可以響應(yīng)的,但由于沒有該連接的有效信息,會產(chǎn)生一個 RST 報文,這樣很快就會發(fā)現(xiàn) TCP 連接已經(jīng)被重置。
第三種,是對端程序崩潰,或?qū)Χ擞捎谄渌驅(qū)е聢笪牟豢蛇_。當(dāng) TCP 保活的探測報文發(fā)送給對端后,石沉大海,沒有響應(yīng),連續(xù)幾次,達到保活探測次數(shù)后,TCP 會報告該 TCP 連接已經(jīng)死亡。
初始序列號 ISN為什么不同?
主要原因是為了防止歷史報文被下一個相同四元組的連接接收。
如果一個已經(jīng)失效的連接被重用了,但是該舊連接的歷史報文還殘留在網(wǎng)絡(luò)中,如果序列號相同,那么就無法分辨出該報文是不是歷史報文,如果歷史報文被新的連接接收了,則會產(chǎn)生數(shù)據(jù)錯亂。所以,每次建立連接前重新初始化一個序列號主要是為了通信雙方能夠根據(jù)序號將不屬于本連接的報文段丟棄。
另一方面是為了安全性,防止黑客偽造的相同序列號的 TCP 報文被對方接收。
初始序列號 ISN 是如何隨機產(chǎn)生的?
起始 ISN 是基于時鐘的,每 4 毫秒 + 1,轉(zhuǎn)一圈要 4.55 個小時。
RFC1948 中提出了一個較好的初始化序列號 ISN 隨機生成算法。
ISN = M + F (localhost, localport, remotehost, remoteport)
M 是一個計時器,這個計時器每隔 4 毫秒加 1。
F 是一個 Hash 算法,根據(jù)源 IP、目的 IP、源端口、目的端口生成一個隨機數(shù)值。要保證 Hash 算法不能被外部輕易推算得出,用 MD5 算法是一個比較好的選擇。
TIME_WAIT 狀態(tài)不是會持續(xù) 2 MSL 時長,歷史報文不是早就在網(wǎng)絡(luò)中消失了嗎?
是的,如果能正常四次揮手,由于?TIME_WAIT?狀態(tài)會持續(xù) 2 MSL 時長,歷史報文會在下一個連接之前就會自然消失。
但是來了,我們并不能保證每次連接都能通過四次揮手來正常關(guān)閉連接。
假設(shè)每次建立連接,客戶端和服務(wù)端的初始化序列號都是從 0 開始:
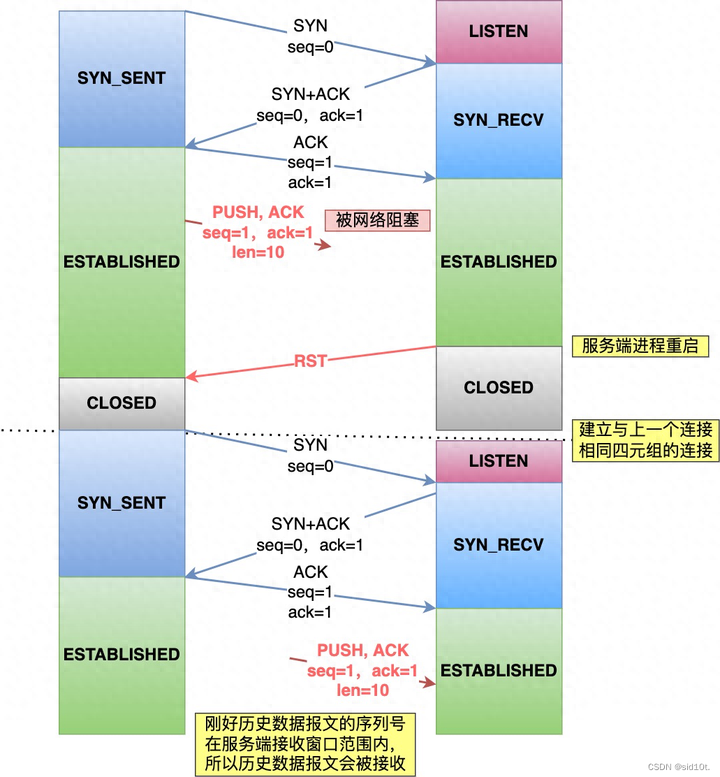
過程如下:
客戶端和服務(wù)端建立一個 TCP 連接,在客戶端發(fā)送數(shù)據(jù)包被網(wǎng)絡(luò)阻塞了,而此時服務(wù)端的進程重啟了,于是就會發(fā)送?RST?報文來斷開連接。
緊接著,客戶端又與服務(wù)端建立了與上一個連接相同四元組的連接;
在新連接建立完成后,上一個連接中被網(wǎng)絡(luò)阻塞的數(shù)據(jù)包正好抵達了服務(wù)端,剛好該數(shù)據(jù)包的序列號正好是在服務(wù)端的接收窗口內(nèi),所以該數(shù)據(jù)包會被服務(wù)端正常接收,就會造成數(shù)據(jù)錯亂。
可以看到,如果每次建立連接,客戶端和服務(wù)端的初始化序列號都是一樣的話,很容易出現(xiàn)歷史報文被下一個相同四元組的連接接收的問題。
客戶端和服務(wù)端的初始化序列號不一樣不是也會發(fā)生這樣的事情嗎?
是的,即使客戶端和服務(wù)端的初始化序列號不一樣,也會存在收到歷史報文的可能。
但是我們要清楚一點,歷史報文能否被對方接收,還要看該歷史報文的序列號是否正好在對方接收窗口內(nèi),如果不在就會丟棄,如果在才會接收。
如果每次建立連接客戶端和服務(wù)端的初始化序列號都「不一樣」,就有大概率因為歷史報文的序列號「不在」對方接收窗口,從而很大程度上避免了歷史報文,比如下圖:
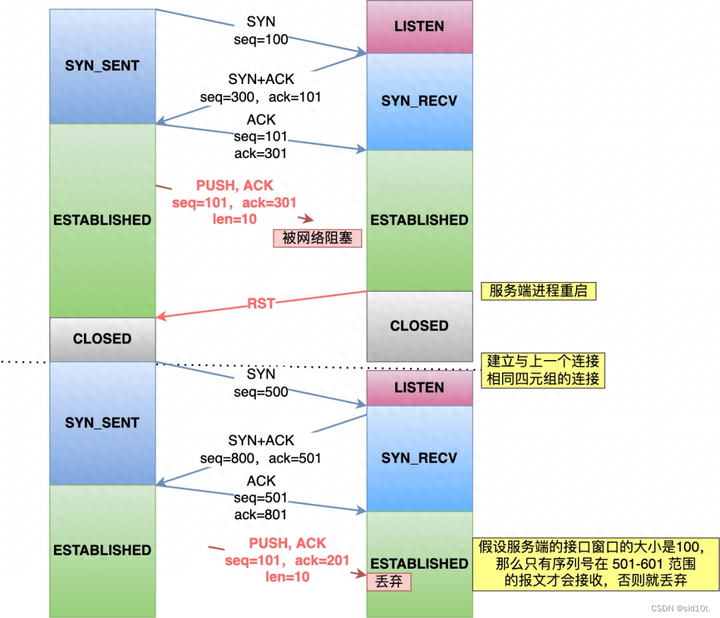
相反,如果每次建立連接客戶端和服務(wù)端的初始化序列號都「一樣」,就有大概率遇到歷史報文的序列號剛「好在」對方的接收窗口內(nèi),從而導(dǎo)致歷史報文被新連接成功接收。
所以,每次初始化序列號不一樣能夠很大程度上避免歷史報文被下一個相同四元組的連接接收,注意是很大程度上,并不是完全避免了。
客戶端和服務(wù)端的初始化序列號不一樣不是也會發(fā)生這樣的事情嗎?
是的,但是也不是完全避免了。
為了能更好的理解這個原因,我們先來了解序列號(SEQ)和初始序列號(ISN)。
序列號,是 TCP 一個頭部字段,標(biāo)識了 TCP 發(fā)送端到 TCP 接收端的數(shù)據(jù)流的一個字節(jié),因為 TCP 是面向字節(jié)流的可靠協(xié)議,為了保證消息的順序性和可靠性,TCP 為每個傳輸方向上的每個字節(jié)都賦予了一個編號,以便于傳輸成功后確認(rèn)、丟失后重傳以及在接收端保證不會亂序。序列號是一個 32 位的無符號數(shù),因此在到達 4G 之后再循環(huán)回到 0。
初始序列號,在 TCP 建立連接的時候,客戶端和服務(wù)端都會各自生成一個初始序列號,它是基于時鐘生成的一個隨機數(shù),來保證每個連接都擁有不同的初始序列號。初始化序列號可被視為一個 32 位的計數(shù)器,該計數(shù)器的數(shù)值每 4 微秒加 1,循環(huán)一次需要 4.55 小時。
通過前面我們知道,序列號和初始化序列號并不是無限遞增的,會發(fā)生回繞為初始值的情況,這意味著無法根據(jù)序列號來判斷新老數(shù)據(jù)。
不要以為序列號的上限值是 4GB,就以為很大,很難發(fā)生回繞。在一個速度足夠快的網(wǎng)絡(luò)中傳輸大量數(shù)據(jù)時,序列號的回繞時間就會變短。如果序列號回繞的時間極短,我們就會再次面臨之前延遲的報文抵達后序列號依然有效的問題。
為了解決這個問題,就需要有 TCP 時間戳。tcp_timestamps 參數(shù)是默認(rèn)開啟的,開啟了 tcp_timestamps 參數(shù),TCP 頭部就會使用時間戳選項,它有兩個好處,一個是便于精確計算 RTT ,另一個是能防止序列號回繞(PAWS)。
試看下面的示例,假設(shè) TCP 的發(fā)送窗口是 1 GB,并且使用了時間戳選項,發(fā)送方會為每個 TCP 報文分配時間戳數(shù)值,我們假設(shè)每個報文時間加 1,然后使用這個連接傳輸一個 6GB 大小的數(shù)據(jù)流。

32 位的序列號在時刻 D 和 E 之間回繞。假設(shè)在時刻B有一個報文丟失并被重傳,又假設(shè)這個報文段在網(wǎng)絡(luò)上繞了遠路并在時刻 F 重新出現(xiàn)。如果 TCP 無法識別這個繞回的報文,那么數(shù)據(jù)完整性就會遭到破壞。
使用時間戳選項能夠有效的防止上述問題,如果丟失的報文會在時刻 F 重新出現(xiàn),由于它的時間戳為 2,小于最近的有效時間戳(5 或 6),因此防回繞序列號算法(PAWS)會將其丟棄。
防回繞序列號算法要求連接雙方維護最近一次收到的數(shù)據(jù)包的時間戳(Recent TSval),每收到一個新數(shù)據(jù)包都會讀取數(shù)據(jù)包中的時間戳值跟 Recent TSval 值做比較,如果發(fā)現(xiàn)收到的數(shù)據(jù)包中時間戳不是遞增的,則表示該數(shù)據(jù)包是過期的,就會直接丟棄這個數(shù)據(jù)包。
客戶端和服務(wù)端的初始化序列號都是隨機生成,能很大程度上避免歷史報文被下一個相同四元組的連接接收,然后又引入時間戳的機制,從而完全避免了歷史報文被接收的問題。
你知道 TCP 的最大連接數(shù)嗎?
有一個 IP 的服務(wù)器監(jiān)聽了一個端口,它的 TCP 的最大連接數(shù)是多少?
服務(wù)器通常固定在某個本地端口上監(jiān)聽,等待客戶端的連接請求。因此,客戶端 IP 和 端口是可變的,其理論值計算公式如下:

對 IPv4,客戶端的 IP 數(shù)最多為 2的32次方,客戶端的端口數(shù)最多為 2的16次方,也就是服務(wù)端單機最大 TCP 連接數(shù),約為 2的48次方。
當(dāng)然,服務(wù)端最大并發(fā) TCP 連接數(shù)遠不能達到理論上限:
首先主要是文件描述符限制,Socket 是文件,所以首先要通過 ulimit 配置文件描述符的數(shù)目;
另一個是內(nèi)存限制,每個 TCP 連接都要占用一定內(nèi)存,操作系統(tǒng)的內(nèi)存是有限的。
編輯:黃飛
?


















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論