 電子發燒友App
電子發燒友App


自20世紀80年代以來,以太網一直是一項基礎技術。早期,工作站和個人電腦使用同軸電纜以10Mbps速率的共享局域網連接到現場服務器。此后,以太網不斷發展,不僅支持雙絞線和光纖布線,速率也從100Mbps發展到100Gbps,甚至是最新的1.6Tbps標準。
隨著以太網速度的提高,其應用越發多樣化,從音、視頻流到多房間音頻、工控網絡,甚至車載網絡。這一進展對數據傳輸提出了更高的安全可靠性要求。尤其是對丟失和延遲特別敏感的數據流來說,定義服務質量是至關重要的。
本文將深入探討為什么需要1.6T數據傳輸、IEEE802.3dj小組的標準化工作、對1.6T以太網子系統組件的概述以及處理所有這些數據所需的以太網控制器的FEC考慮因素等內容。
我們為什么需要如此高的傳輸速度?
以太網的發展主要有兩個維度:
1.
傳輸和存儲海量數據的性能得到了提升;
2.
網絡的可預測性和可靠性得到了提高,即使是要求最苛刻的控制系統也能被滿足。
如今,互聯網的帶寬估計可達到500Tbps,這對數據中心內的后端流量提出了驚人的要求。雖然數據中心內的總流量已經能夠達到每秒太比特的水平,但是單個服務器還無法達到這個速度。
單個設備的處理能力是有限的,即使使用了最先進的處理器或專為機器學習優化的加速器,其性能也會受限于芯片的實際制造尺寸。然而,一旦多個芯片聯合起來,我們便有可能極大地擴展計算能力。因此,太比特級速度和極低延遲的新一代以太網技術的出現,讓這一技術突破成為可能,處理器間通信成為了1.6T以太網的首個應用場景。繼這一代應用之后,預計數據中心將推出交換機間的直連技術,實現高性能處理器和內存資源的集中利用,大幅提升云計算的擴展性和運行效率。
802.3dj:為1.6T以太網標準化奠定基礎
要實現有效通信,網絡上的每個節點都必須遵守同一套標準所定義的規則。電氣和電子工程師協會(IEEE)自成立以來一直負責制定以太網標準。目前,802.3dj小組正在制定以太網標準的最新版本,其中概述了以每秒200G、400G、800G和1.6T速度運行的物理層和管理參數。
1.6Tbps的以太網MAC數據傳輸速率需滿足以下條件:
MAC層的最大誤碼率(BER)為10-13
可選16和8通道附件單元接口(AUI),適用于芯片到模塊(C2M)和芯片到芯片應用(C2C),使用112G和224G SerDes。
在物理層方面,1.6Tbps的傳輸規格包括:
在每個方向上傳輸8對銅雙軸電纜,傳輸范圍至少為1米;
在8對光纖上傳輸,最長可達500米
在8對光纖上傳輸,最長可達2千米
預計該標準將于2026年春季確定。不過,我們預計2024年底即可完成基線功能。
1.6T以太網子系統剖析
我們來深入了解下1.6Tbps以太網子系統的組件,尤其是一些用于在ASIC或ASSP硅芯片中實現以太網接口的元件。
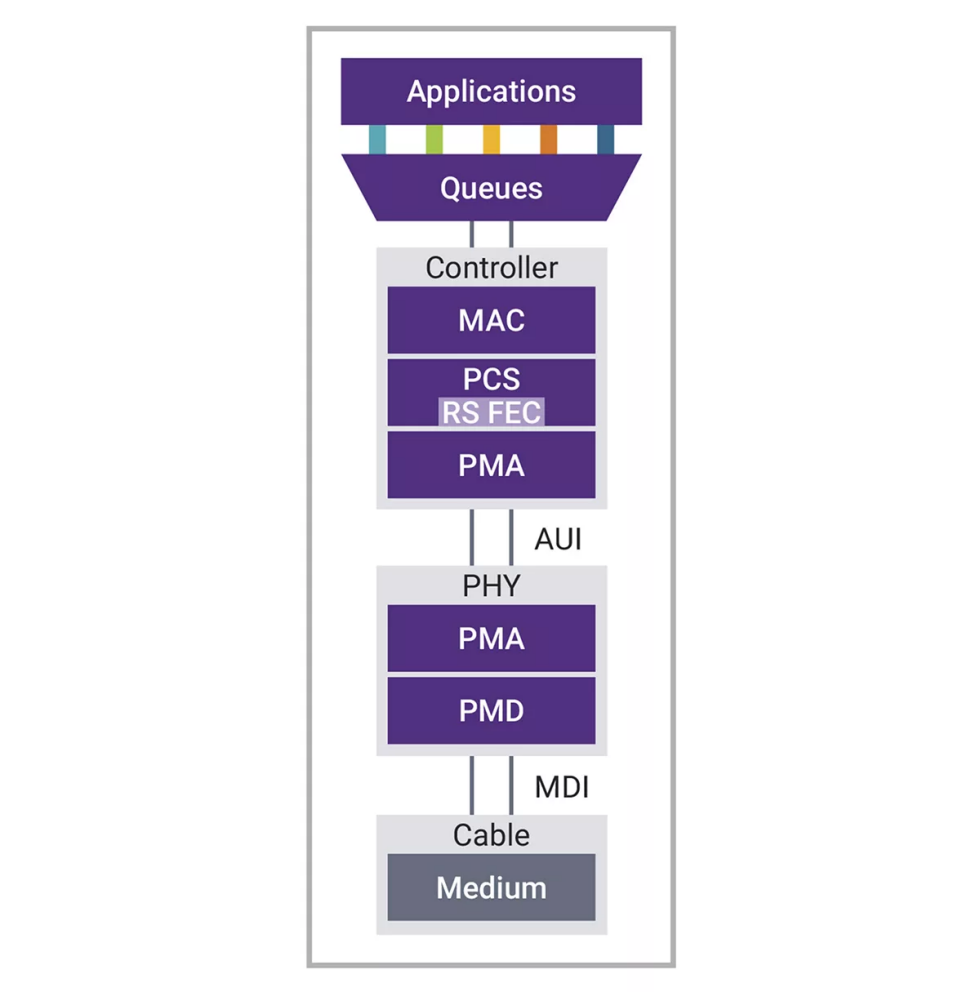
圖2:1.6T以太網子系統組件的示意圖
網絡應用
最頂層是網絡應用程序,既可以安裝在客戶端機器上,也可以安裝在電腦或文件服務器上。它們既是所有以太網流量的來源,也是其目的地。但以太網橋或第二層交換機比較特殊,按照802.1d的定義規則,它是轉發數據包的中間點。
隊列連接
各個應用程序或實例通過一個或多個隊列與以太網控制器相連接。隊列很可能正在緩沖與應用程序之間的流量,平衡客戶端與服務器端的網絡性能。為實現最高性能,網絡速度應與流量產生或消耗的速度相匹配。這樣,我們就能最大限度地減少數據包在應用程序之間端到端交換時的延遲。
控制器、物理層和布線
以太網控制器通常由一個MAC和一個PCS組成,但一般我們會稱之為“以太網MAC”。在PCS下方是附件單元接口(AUI)——有些讀者可能還記得工作站背面的D型連接器,AUI電纜就插在上面。在今天的以太網中,這種接口依然存在,并且速度更快了。最后,在堆棧的更下面,我們可以找到負責控制和管理網絡物理元素的模塊,這些模塊可能是光纖、銅纜或者背板。
1.6T以太網控制器:深入了解MAC、PCS和高級FEC機制
如圖3所示,在應用程序和隊列下面是介質訪問控制器(MAC)。MAC負責管理以太網成幀——查看源地址和目標地址、管理幀的長度、在必要時添加填充(在有效載荷很短的情況下)以及添加/檢查幀校驗序列(FCS),以確保幀的完整性。
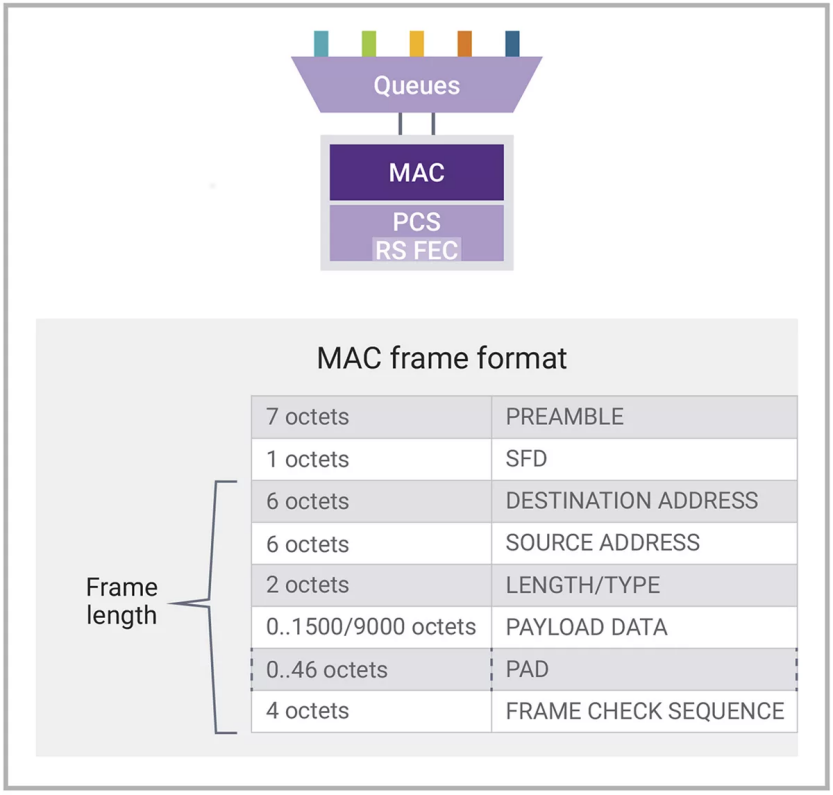
圖3:MAC幀格式和長度:八進制分解
MAC的變體可分為兩大類:
一、網絡接口卡(NIC)中的MAC
這種MAC位于客戶端、服務器或路由器中的網卡上。它們在有效載荷向下和向上傳遞堆棧時,通過添加和刪除以太網的特定任務來完成終止以太網層的重要任務。其中一個不可或缺的功能是添加和檢查幀校驗序列(FCS),以確保數據完整性。如果在接收時檢測到任何損壞,幀將被丟棄。此外,網卡中的MAC將檢查幀的目標地址,確保在網絡內準確傳輸。有效載荷很可能是一個IP(互聯網協議)數據包。
NIC以前是一種插入式網卡,因此被稱為"網絡接口卡"。網卡執行MAC、PCS和PHY,而隊列和任何其他智能功能則由主機處理器處理。如今,我們看到的智能網卡可以卸載許多網絡功能,但仍保持相同的MAC層。
二、交換/橋接MAC
交換或橋接MAC采用了不同的方法。在這里,整個以太網幀在MAC和上層之間傳遞。MAC負責添加和檢查FCS,并為支持遠程網絡監控(RMON)收集統計數據。從概念上講,以太網交換機可被視為為此目的而設計的專用應用程序。盡管以太網交換機主要由硬件實現,以保證最佳線速性能,但其每個端口都包含一個專用的MAC。盡管這些端口可能以不同的速度運行,但任何速率適應都是在MAC層以上的隊列中進行管理的。
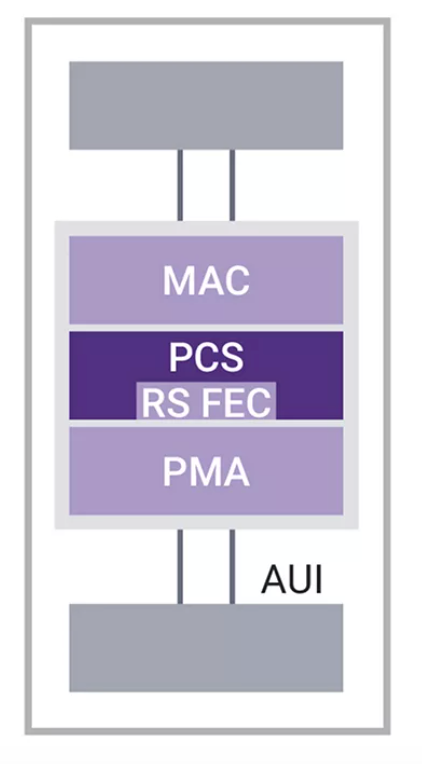
圖4:MAC、PCS和PMA與AUI連接示意圖
從基本編碼到RS-FEC
對于較低的以太網速率,物理編碼子層(PCS)只需對數據流進行編碼,即可開始檢測數據包,并確保信號平衡,即使在長的0或1數據流中也是如此。然而,隨著以太網速度的提高,PCS的復雜性也在增加。如今,由于每個物理鏈路上都有高速信號,因此有必要使用前向糾錯(FEC)來克服固有的信號衰減,即使在很短的鏈路上也會遇到這種情況。
與其他高速以太網變體的PCS一樣,1.6T以太網采用了里德-所羅門前向糾錯(RS-FEC)技術。這種方法建立的編碼字由514個10位符號組成,編碼成544個符號塊,因此帶寬開銷為6%。這些FEC編解碼字分布在AUI物理鏈路上,因此每個物理鏈路(1.6T以太網為8個)不會攜帶整個編解碼字。這種方法不僅能提供額外的錯誤突發保護,還能在遠端解碼器上實現并行化,從而減少延遲。
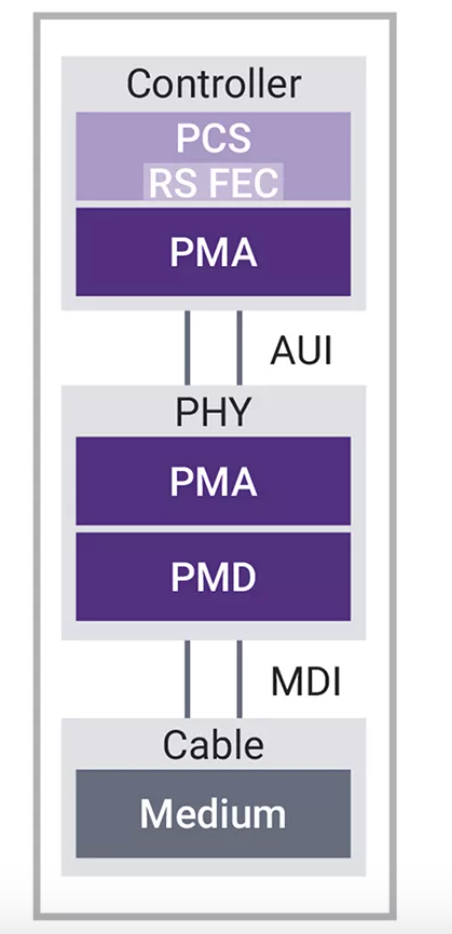
圖5:1.6T以太網子系統的控制器、物理層和電纜組件示意圖
在1.6T以太網中實現最佳比特誤碼率
雖然以太網PHY層包括PCS,但通常將PCS與以太網控制器內的MAC聯系起來。物理介質附件(PMA)具有齒輪箱和SerDes,可將以太網信號傳輸到傳輸通道上。對于1.6T以太網,8個通道以212Gbps的速度運行,FEC編碼擴展率為6%。值得注意的是,PMA的上半部分位于控制器內,然后將比特流交給AUI。PHY的每個物理鏈路都使用4級脈沖幅度調制(PAM-4)。這種方法為每個傳輸符號編碼兩個數據位,與傳統的非歸零(NRZ)傳輸相比,帶寬增加了一倍。發送器采用數模轉換器(DAC)對數據進行調制,而遠端接收器則使用模數轉換器(ADC)和DSP來提取原始信號。
以太網PCS在以太網鏈路端到端使用的數據流中增加了FEC,在長距離以太網鏈路中通常稱為"外部FEC"。IEEE正在為單個物理線路定義額外的糾錯級別,以實現更長的傳輸距離。在需要糾錯的地方,光收發器模塊將支持這種額外的糾錯(可能是一種漢明碼)。圖6顯示了使用串聯FEC擴展傳輸距離時增加的開銷。
讓我們看一下圖6中的系統示例,其中MAC和PCS的光發射器和接收器被一段光纖隔開:

圖6:用一段光纖分隔MAC和PCS光TX/RX的示意圖
在與光模塊相連的鏈路上,PCS的誤碼率為10^-5,加上在光鏈路上引入的額外誤碼。如果我們只在該系統中端對端實施單個RS-FEC,則產生的誤碼率將無法滿足10^-13以太網要求。該鏈路將被歸類為不可靠鏈路。另一種方法是在每一跳上實施單獨的RSFEC,RSFEC將進行三次編碼和解碼。一次在發送PCS,然后在光模塊,最后在從光模塊到遠程PCS的遠端鏈路。這樣做的成本很高,而且會增加端到端延遲。
將串聯漢明碼FEC集成到光鏈路中是一種最佳解決方案,既能滿足以太網要求,又能很好地處理光連接中遇到的隨機誤差。內部FEC層將線路速率從212Gbps提高到226Gbps,因此SerDes必須能夠支持這一線路速率。
從發送到接收:了解以太網應用中的延遲狀況
簡單地說,以太網延遲是指從一個應用程序通過以太網傳輸信息到另一個應用程序接收信息之間的延遲。往返延遲測量的是從發送信息到收到響應所需的時間。當然,這種延遲取決于遠端應用程序的響應時間,在考慮以太網延遲時,可以忽略這一點,因為它是以太網的外部延遲。以太網延遲的組成部分包括發送隊列、信息處理時間、傳輸持續時間、介質穿越時間、信息接收時間、結束處理時間和接收隊列中的時間。
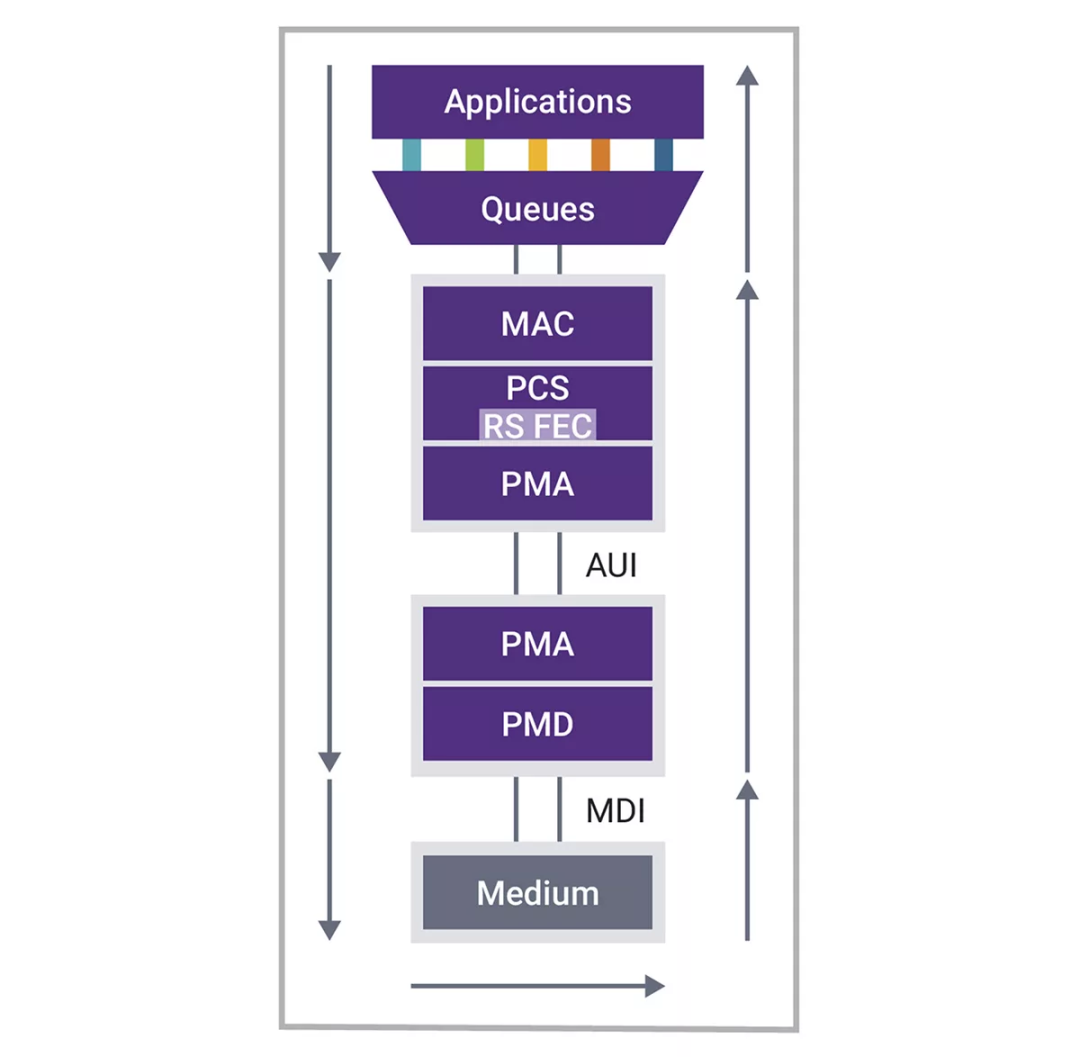
圖7:描述完整1.6T以太網子系統和延遲路徑的示意圖
在關注最大限度減少以太網子系統(特別是以太網接口級,而非整個網絡)中的延遲時,考慮具體情況至關重要,例如,當數據包源和數據包匯以匹配的高數據速率運行時。相反,在中繼連接(如交換機之間的連接)中,由于較慢的客戶端鏈路會產生較明顯的延遲,因此延遲就不那么重要了。同樣,在處理較長距離時,距離造成的固有延遲將占主導地位。
此外,值得注意的是,時間敏感網絡(TSN)解決的是確定性延遲問題。在這種情況下,關鍵任務應用的最大延遲上限已被確定,尤其是對于低速網絡或共享基礎設施網絡。當然,這并不意味著我們應該忽視其他情況下的延遲。最大限度地減少延遲仍然是一個不變的目標。首先,端到端的累計延遲會隨著每一次連續跳轉而增加。其次,延遲的增加往往表明控制器中增加了電路或處理功能,這可能會導致系統功耗增加。
延遲洞察:剖析以太網子系統層
首先,我們拋開任何隊列延遲不談,假設從應用程序到以太網控制器之間有一條清晰的路徑,沒有任何帶寬競爭。帶寬差異會導致數據包排隊延遲,當延遲至關重要時,應避免這種情況。當數據包通過傳輸控制器時,以太網幀會即時建立或修改。值得注意的是,線路編碼和傳輸FEC階段不需要大量存儲。
傳輸報文處理延遲取決于具體的實現方式,但可以通過良好的設計實踐將其最小化。傳輸信息所需的時間取決于以太網速率和幀大小。對于1.6T以太網,傳輸一個最小大小的數據包需要0.4ns-基本上是2.5GHz時鐘每跳動一下就傳輸一個以太網幀。標準最大以太網幀的傳輸時間為8ns,巨型幀的傳輸時間延長至48ns。
考慮到穿越介質的時間,光纖延遲大約為每米5ns,而銅纜稍快,為每米4ns。雖然信息接收時間與發送時間相同,但由于這兩個過程同時進行,因此通常會被忽略。
大部分延遲發生在接收器控制器上
即使是最優化的設計,RSFEC解碼器造成的延遲也是不可避免的。開始糾錯時,必須接收并存儲4個編碼字,以1.6Tbps的速率計算,這需要12.8ns的時間。隨后的流程,如執行FEC算法、糾錯(必要時)、緩沖和時鐘域管理,都會進一步增加控制器的接收延遲。雖然FEC編解碼存儲時間是一個恒定因素,但信息接收過程中的延遲與具體實施有關,但可以通過良好的數字設計實踐進行優化。
從本質上講,由于FEC機制和物理距離或電纜長度,存在固有的、不可避免的延遲。除了這些因素外,良好的設計實踐在最大限度地減少以太網控制器造成的延遲方面也發揮著關鍵作用。利用集成的完整解決方案(包括MAC、PCS和PHY)以及專業的設計團隊,可為最高效、低延遲的實施鋪平道路。
?總結?
1.6Tbps以太網可滿足帶寬最密集、時延最敏感的應用需求。隨著224GSerDes技術的出現以及MAC和PCSIP的開發,可提供符合不斷發展的1.6T以太網標準的完整現成解決方案。控制器延遲在1.6Tbps應用中至關重要。除了協議和糾錯機制造成的固有延遲外,IP數字設計還必須由專業設計團隊精心設計,以防止數據通路增加不必要的延遲。
經過硅驗證的解決方案需要優化的架構和精確的數字設計,強調能效并減少硅足跡,從而使1.6T數據速率成為現實。新思科技經過硅驗證的224G以太網PHYIP為1.6TMAC/PCS的實現奠定了基礎。利用領先的設計、分析、仿真和測量技術,新思科技將繼續提供卓越的信號完整性和抖動性能,以及包括MAC+PCS+PHY在內的完整以太網解決方案。
審核編輯:黃飛
?













 工商網監
工商網監
評論