 電子發燒友App
電子發燒友App


作者:李豪 ? ? 本文精讀《Congestion Control for Large-Scale RDMA Deployments》論文,就是在這篇論文中微軟和Mellanox提出DCQCN擁塞控制算法,打開了RDMA在數據中心規模化部署的大門。雖然距論文發表已有八、九年,經典仍值得回味,今天我們細細閱讀之。 ?

? 01 摘要和背景介紹
現代(2015年)數據中心應用需要網絡具備:1. 高吞吐量(40Gbps) ,2. 超低延遲(每跳 < 10 μs)、3. 低CPU開銷。標準TCP/IP協議棧不滿足這些要求,但是RDMA(Remote Direct Memory Access)技術可以。 ? 當前RDMA在數據中心部署主要使用RoCE v2協議,該協議依賴PFC(Priority-based Flow Control)來保證網絡的無損,即不發生丟包。但是PFC性能表現不佳,主要缺點包括:1. 對頭阻塞(head-of-line blocking) 2. 不公平。 ? 網絡無損是需要付出代價的! ? 為了解決這些問題,我們引入DCQCN算法,這是一個端到端的擁塞控制算法,專門為RoCE v2量身打造;同時我們對于如何調參給出一些建議,包括交換機buffer水線配置以及該算法的其他參數。 ? 端到端(end-to-end),從發送方到接收方,比如從client到server。點到點(point-to-point),網絡上相鄰的一跳,比如相鄰兩個交換機。 ? 雖然RDMA技術在HPC領域使用悠久且廣泛,但是在數據中心部署RDMA卻很有挑戰。,其中一個重要挑戰是擁塞控制,數據中心的RDMA對擁塞控制有如下要求: ?
在無損網絡環境下可以有效工作
簡單到可以實現在網卡上(而非操作系統里)
RDMA最早使用Infiniband技術實現,IB使用私有的協議棧、專用硬件。IB在數據鏈路層(L2)使用逐跳(hop-by-hop)的credit-based流控來避免丟包,基于這個不丟包的L2,IB的傳輸層(L4)可以非常簡單和高效。 ? 難就難在IB的這套協議棧和硬件設備不能直接照搬到數據中心,因為數據中心網絡是以太網,二者不兼容。如果同時在數據中心搭建兩套網絡又太貴,所以RoCE v2橫空出世,允許基于傳統以太網實現RDMA,具體做法是將IB的傳輸層作為UDP的payload,完全不使用IB的數據鏈路層。 ? IP頭用來做路由,UDP頭用來做ECMP。 ?
雖然RoCE v2不再依賴IB的數據鏈路層,但卻繼承了IB的無損網絡約束,因此提出了PFC(Priority-based Flow Control)。PFC通過讓直接上游暫停發送數據的方式來避免交換機buffer溢出。 ? 直接告訴上游端口,立即暫停發送任何數據!非常的粗暴。這里的上游可以是交換機或者網卡。 ? PFC是交換機端口級別的,不區分具體的流(flow,即連接),一旦暫停就會暫停端口上所有的連接。這種粒度顯然太粗了,會導致擁塞擴散,進而導顯著的致性能下降。雖然PFC可以區分交換機隊列(交換機的每個端口有8個隊列),但也于事無補,因為不可能給每個鏈接都是用一個單獨的隊列。 ? 解決 PFC 局限性的根本辦法是采用流級別的擁塞控制協議,協議需要滿足以下要求: ?
在無損、L3 路由(網絡層,即IP層)、數據中心網絡上運行。
主機端低CPU開銷。
起步速度要快,即無擁塞的時候流滿速啟動。
(2015年)當前常見的擁塞控制算法均無法滿足以上要求,比如QCN,DCTCP,iWarp, TCP-Bolt等。 ?
QCN不支持L3層網絡
DCTCP和iWarp起步速度太慢(slow start)
DCTCP和TCP-Bolt使用軟件實現,CPU占用太高
因此DCQCN橫空出世,該算法值依賴交換機的RED和ECN功能,算法其余的部分都是現在主機側的網卡上,該算法的特點為: ?
快速收斂到公平
高鏈路利用率
較低的隊列堆積
較低的隊列震蕩
02 DCQCN的必要性
傳統TCP堆棧性能不佳
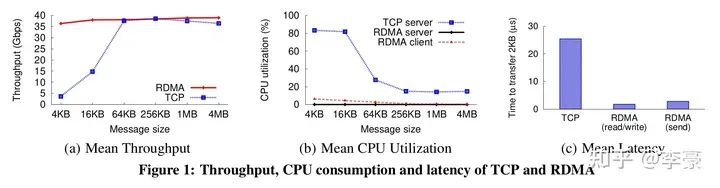
TCP協議棧在吞吐、CPU消耗、延遲等方面全面落后于RDMA。 ?
圖(a):吞吐方面,小包的時候TCP無法打滿帶寬,因為此刻CPU成為了瓶頸。而RDMA在小包時也可以打滿帶寬。
圖(b):CPU占用方面,為了打滿40G帶寬,TCP使用了16個線程,總共占用了整機20%的CPU時間。而RDMA的client側 CPU占用不超過3%,server側CPU幾乎沒有CPU占用。
圖(c):延遲方面,TCP的延遲為25.4微秒,而RDMA READ/WRITE延遲為1.7微秒,RDMA SEND延遲為2.8微秒。
PFC 有局限
RoCE v2依賴PFC來保障不發生丟包,PFC可以避免以太網交換機和網卡出現緩沖區溢出。具體做法是:交換機或者網卡監測自己的ingress隊列,一旦隊列超過特定閾值則發送一個PAUSE消息給相鄰上游,上游收到PAUSE消息之后會停止整個端口的報文發送,直到收到RESUME消息再重新開始。 ? PFC有八個隊列,每個隊列都可以獨立進行上述步驟。 ? 這里主要的問題是作用于端口(+優先級)而不是作用于流(flow,即鏈接),這可能會導致head-of-line blocking等問題,導致網絡性能變差。 ?
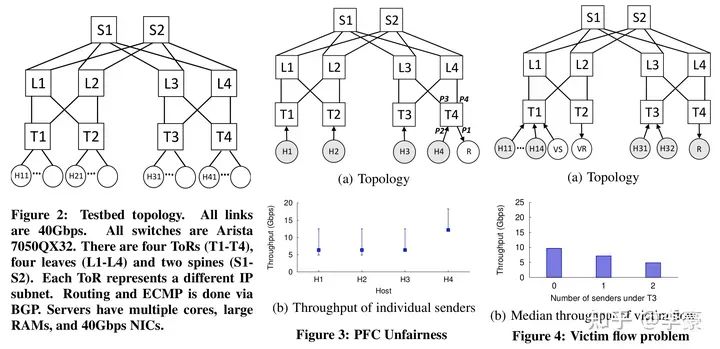
PFC的問題 ?
不公平問題(unfairness):因為PFC沒有區分具體的流,而是無腦的停掉整個端口流量,這會導致多個發送方之間的不公平問題。上圖中Figure 3展示的是4個發送方的吞吐情況,非常的不均衡。 ? 無辜流問題(victim flow):這個是指一組發送方-接收方之間(Figure4中的VS和VR)本沒有擁塞,但是由于受到另一組有擁塞的發送方-接收方(H1~H32和R)的干擾,進而導致VS發生降速。這主要是因為PFC有級聯效應,一個沒有擁塞的流可能被別的擁塞路徑波及到。 ? 而已有方案都不能解決上述PFC導致的問題,因此本文提出DCQCN算法。 ?
ECMP(Equal-cost multi-path routing)不足以解決上述問題:雖然ECMP會使得流在交換機鏈路上盡可能均勻分布,但不能保證沒有沖突。
PFC的多隊列機制也不夠:因為PFC只有8個隊列,單個隊列內的流仍然會遇到上述問題。
03 DCQCN算法
算法過程
DCQCN 是一種基于速率的端到端擁塞協議,它建立在 QCN 和 DCTCP 之上。DCQCN 的大部分功能是現在網卡上(而不是交換機上,或者操作系統上)。如前文所述,DCQCN有以下特點: ?
在無損、L3 路由(網絡層,即IP層)、數據中心網絡上運行。
主機端低CPU開銷。
起步速度要快,即無擁塞的時候流滿速啟動。
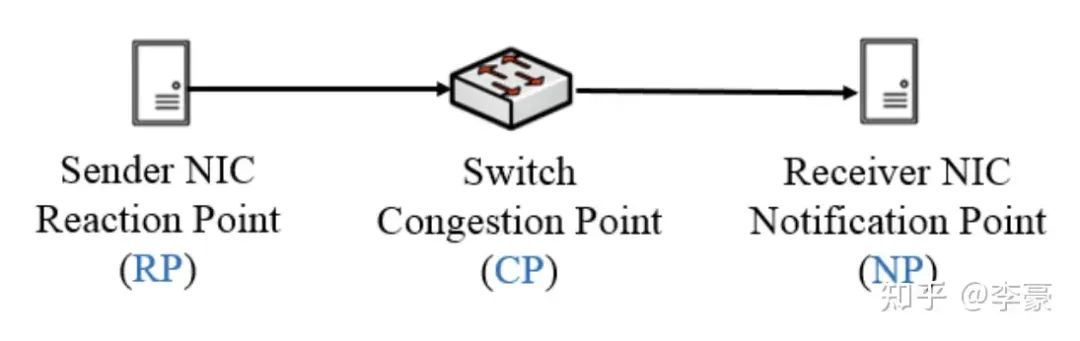
DCQCN中的三種角色 DCQCN中有三個角色,分別是:
RP(reaction point): 即發送方網卡
CP(congestion point): 即交換機
NP(notification point): 即接收方網卡
上述三種角色上的具體算法分別為: ? CP交換機上的算法:交換機上的算法和DCTCP一樣,當交換機的egress隊列超過特定閾值時開始對到來的報文(按照一定概率)標記ECN。這通過交換機的RED(Random early detection)功能完成,幾乎所有的交換機都支持該功能,因此DCQCN不需要對交換機做改動。
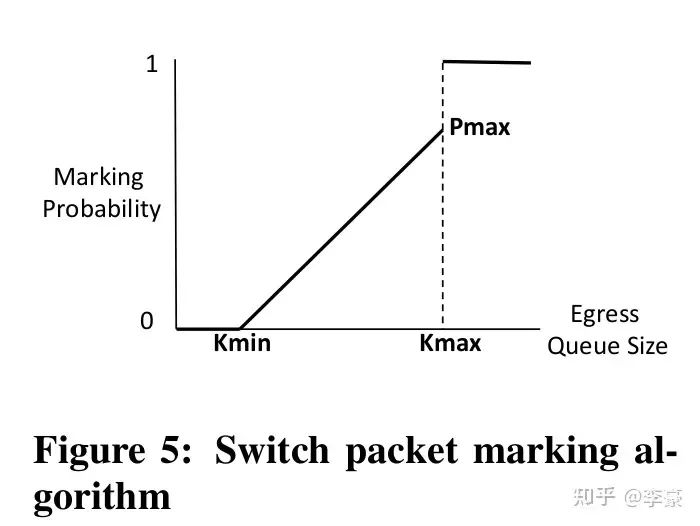
CP交換機上的算法 ? NP接收方網卡上的算法:當ECN標記后的報文到達接收方網卡,這表明網絡上發生了擁塞,接收方網卡將該信息轉換為CNP(Congestion Notification Packets)后反饋給發送方。CNP是RoCE v2規范中定義的擁塞通知方式。 ? NP上的算法主要用于決定CNP報生成的頻率,比如可以每收到一個ECN就反饋一個CNP,也可以規定50us內最多反饋一個CNP。 ? CNP是區分流的,對于每個流NP算法流程如下圖:
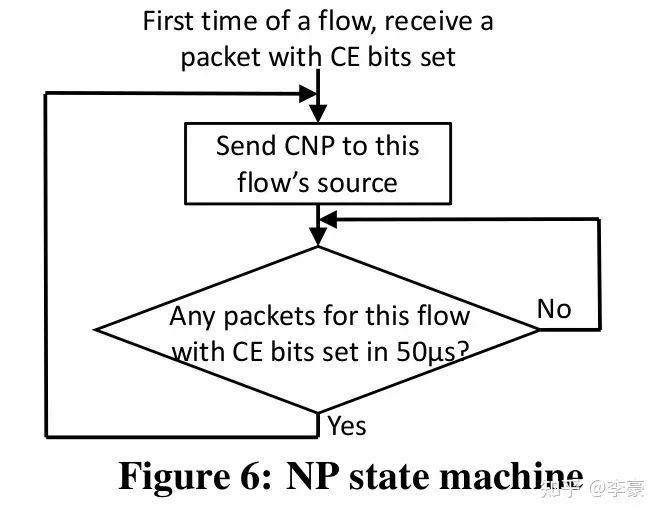
NP狀態機 ?
RP發送方網卡上的算法:這是DCQCN的重頭戲。分為降速過程,升速過程,更新alpha三個部分。 ? 降速過程:當RP上的一個流收到了CNP,該流會按照如下公式降速,并更新target rate和alpha值。
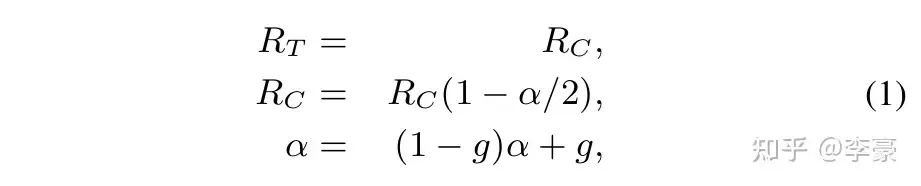
DCQCN降速過程 ?
alpha更新過程:如果RP經過K個時間單位之后沒有收到NP發來的CNP,則RP更新一次alpha值,更新公式如下。該公式的目的是在沒有擁塞的時候逐漸降低alpha值,alpha的值區間是0~1。
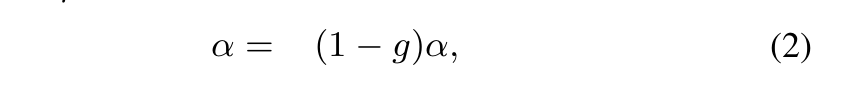
alpha更新過程 ? 注意K要比CNP生成的周期要長一些,本文中選擇K=55us ? 升速過程:RP采用和QCN相同的升速方式,即采用一個timer和一個byte counter決定升速的節奏。每收到B個字節之后byte counter觸發升速,每隔T個時間單位之后timer觸發升速。這兩個參數都是可調的,以便控制升速節奏。 ? 有三種升速方式,通常按照以下順序發生: ?
快速恢復(fast recover)
加性增(additive increase)
超快速增(hyper increase)
注意這里沒有slow start,一個新的流起速就按照全速發送,這么做是基于如下事實:大多數時候流傳輸的數據較少切網絡無擁塞,因此全速發送也不會造成網絡擁塞(如果真的擁塞了,最終還有PFC兜底)。 ?
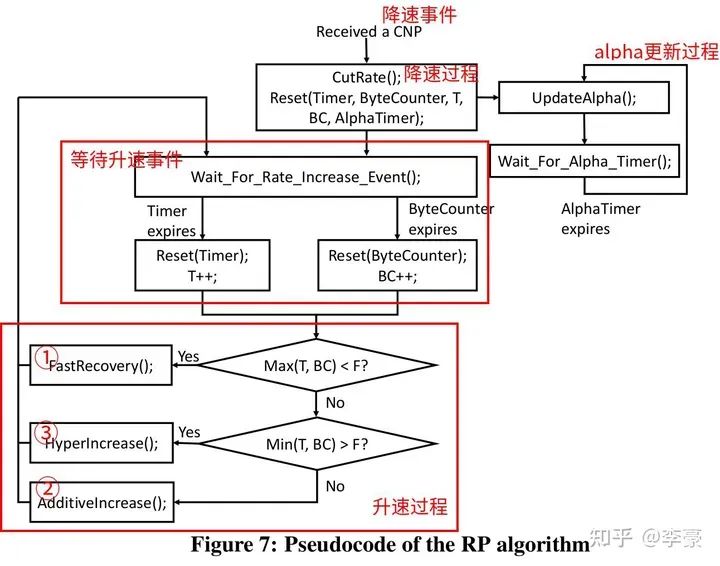
DCQCN 發送方算法 ? 不同于PFC作用于端口,DCQCN是作用于流的,即每個流都獨立進行上述的算法過程。下圖表明DCQCN很好的解決了公平性問題和無辜流問題(unfairness and victim flow)。
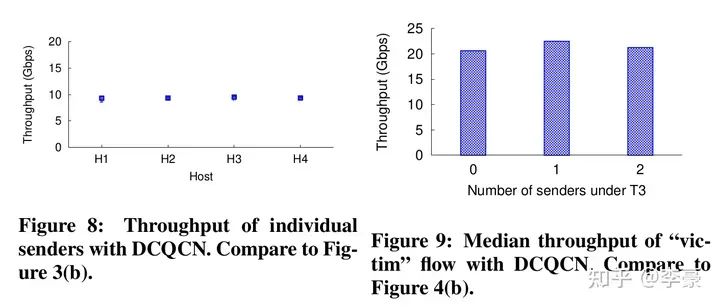
DCQCN實際表現 ?
一些關鍵點討論
CNP生成:我們以高優先級發送CNP以確保更快速的收斂。注意,通常在沒有擁塞的情況下不會生成CNP。 ? 基于速率的擁塞控制:DCQCN是一種基于速率的擁塞控制方案。我們采用基于速率的算法,因為它比基于窗口的算法更容易實現,并且允許更細粒度的控制。 ? 參數設置:DCQCN 基于 DCTCP 和 QCN,但在關鍵方面有所不同。因此DCTCP和QCN推薦的參數設置不能盲目地與DCQCN一起使用。 ? PFC仍然是必需的:DCQCN 并不能消除對 PFC 的依賴,仍需要使用PFC做兜底來避免丟包,只是DCQCN會大大降低PFC發生的頻率。 ? 硬件實現:NP和RP(分別指接收方和發送方)的狀態機都是現在網卡上(而非操作系統里),RP狀態機的實現需要為每個流維護以下資源: ?
一個定時器:即Timer
一個計數器:即ByteCounter
跟alpha值相關的狀態
RP上的限速是針對每個數據包粒度的。 ? NP主要用于產生CNP報文,在ConnectX-3 Pro每生成一個CNP需要花費1~5微秒。對于40Gbps網絡,1500B MTU下接收方每50微秒最多收到166個網絡報文,所以NP可以同時為10~20個流生成CNP,ConnectX-4可以同時為200個流生成CNP。 ? CNP生成是一個開銷比較大的動作。上面一段話的意思是,每個流在發生擁塞是至少要在50微秒內生成1個CNP報文,而每次生成一個CNP需要消耗5微秒,即50微秒內只能生成10個CNP,因此ConnectX-3網卡最多并發為10個流生成CNP。 ? ? 04 交換機緩沖區設置 ? DCQCN需要考慮以下兩個相互沖突的約束,并基于此設置交換機緩沖區的閾值: ?
PFC不能觸發的太早,至少不能早于ECN。
PFC不能觸發的太晚,否則會導致丟包。
PFC生成時機主要是由交換機buffer閾值控制,本節討論閾值設置問題。 ? Headroom buffer t_flight:發送到上游設備的PAUSE消息需要一段時間才能到達并生效。為了避免數據包丟失,PAUSE 發送方必須保留足夠的緩沖區來處理在此期間可能收到的任何數據包。這包括發送 PAUSE 時正在傳輸的數據包,以及上游設備在處理 PAUSE 消息時發送的數據包。 ? PFC閾值 t_PFC:這是在PAUSE消息發送到上游之前(即上游停止發送之前),交換機的ingress隊列可以增長的最大值,每個PFC優先級都有自己的ingress隊列(8個優先級隊列),因此如果交換機的總buffer大小為B,交換機的端口數量為n,則 : 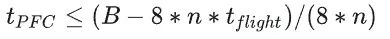 ? ECN閾值 t_ECN:一旦交換機的egress隊列超過這個閾值,則交換機開始按照一定概率標記ECN。顯然這個值要設置的比較合理,必須保證ECN先于PFC觸發。 ? 注意,PFC看的是ingress隊列,ECN看的是egress隊列!入口隊列和出口隊列的一個主要關系是:多個入口隊列可以將數據發往同一個出口隊列,這取決于實際流的目的地。 ? 為了確保ECN先于PFC觸發,必須考慮以下極端情況:全部egress隊列的消息都來自同一個ingress隊列,這種情況下出隊列的壓力最小,入隊列的壓力最大。因此需要保證:
? ECN閾值 t_ECN:一旦交換機的egress隊列超過這個閾值,則交換機開始按照一定概率標記ECN。顯然這個值要設置的比較合理,必須保證ECN先于PFC觸發。 ? 注意,PFC看的是ingress隊列,ECN看的是egress隊列!入口隊列和出口隊列的一個主要關系是:多個入口隊列可以將數據發往同一個出口隊列,這取決于實際流的目的地。 ? 為了確保ECN先于PFC觸發,必須考慮以下極端情況:全部egress隊列的消息都來自同一個ingress隊列,這種情況下出隊列的壓力最小,入隊列的壓力最大。因此需要保證: 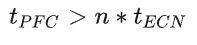 以上所有討論并不是為了避免觸發PFC,只是為了保證ECN先于PFC觸發。DCQCN仍然依賴PFC做兜底。 ? DCQCN算法只是基于ECN/CNP讓發送方降速而不是停止發送,而PFC的PAUSE消息比較狠,直接讓上游端口停止發送任何數據。因此PFC總是能快速消除擁塞。 ? ? 05 性能評測 ? DCQCN實際效果見下圖,論文中最多評測了10打1的incast流量: ?
以上所有討論并不是為了避免觸發PFC,只是為了保證ECN先于PFC觸發。DCQCN仍然依賴PFC做兜底。 ? DCQCN算法只是基于ECN/CNP讓發送方降速而不是停止發送,而PFC的PAUSE消息比較狠,直接讓上游端口停止發送任何數據。因此PFC總是能快速消除擁塞。 ? ? 05 性能評測 ? DCQCN實際效果見下圖,論文中最多評測了10打1的incast流量: ?
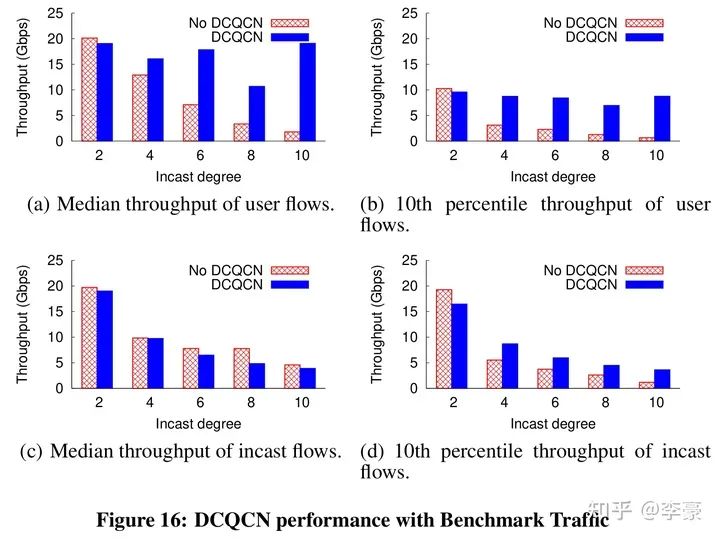
? ? 06 總? 結
本文詳細翻譯和介紹了DCQCN論文的關鍵章節。在有DCQCN之前,RoCE v2只能通過PFC做擁塞控制,有了DCQCN之后RDMA技術才開始在數據中心廣泛應用。 ?
審核編輯:黃飛
?





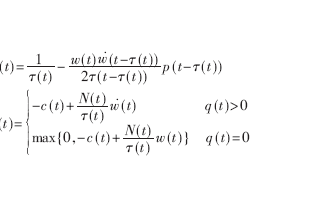







 工商網監
工商網監
評論