 電子發燒友App
電子發燒友App


? ? ? 高性能計算場景的流量關注靜態時延的同時需要支持超大規模組網。然而傳統的?CLOS?架構作為主流網絡架構,主要關注通用性,犧牲了時延和性價比。業界針對該問題開展了多樣的架構研究和新拓撲的設計,Fat-Tree、Dragonfly、Torus是幾種常見的網絡拓撲,Fat-Tree架構實現無阻塞轉發,Dragonfly架構網絡直徑小,Torus?具有較高的擴展性和性價比。
Fat-Tree胖樹架構
傳統的樹形網絡拓撲中,帶寬是逐層收斂的,樹根處的網絡帶寬要遠小于各個葉子處所有帶寬的總和。而Fat-Tree則更像是真實的樹,越到樹根,枝干越粗,即:從葉子到樹根,網絡帶寬不收斂,這是Fat-Tree能夠支撐無阻塞網絡的基礎。Fat-Tree是使用最廣泛的拓撲之一,它是各種應用程序的一個很好的選擇,因為它提供低延遲并支持各種吞吐量選項——從非阻塞連接到超額訂閱,這種拓撲類型最大限度地提高了各種流量模式的數據吞吐量。
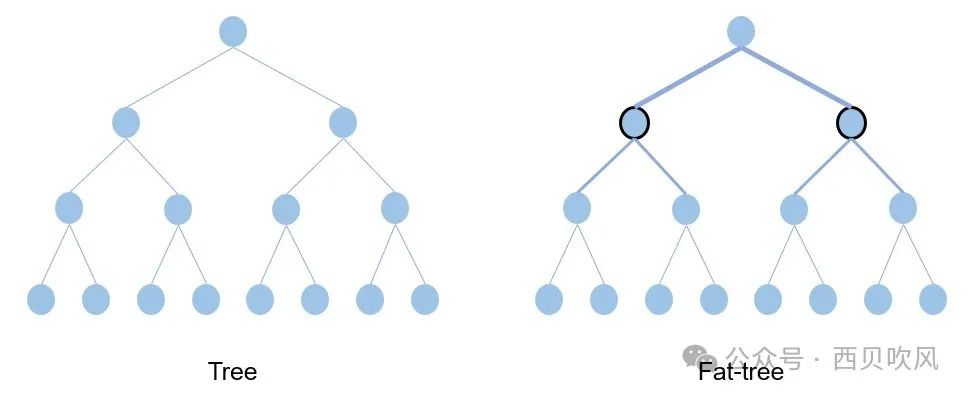
Fat-Tree架構采用1:1無收斂設計,Fat-Tree架構中交換機上聯端口與下聯端口帶寬、數量保持一致,同時交換機要采用無阻塞轉發的數據中心級交換機。Fat-Tree架構可以通過擴展網絡層次提升接入的GPU節點數量。
Fat-Tree架構的本質是無帶寬收斂,因此,云數據中心的Spine-leaf組網在無收斂的情況下,也可以認為是遵從了Fat-Tree架構理念。
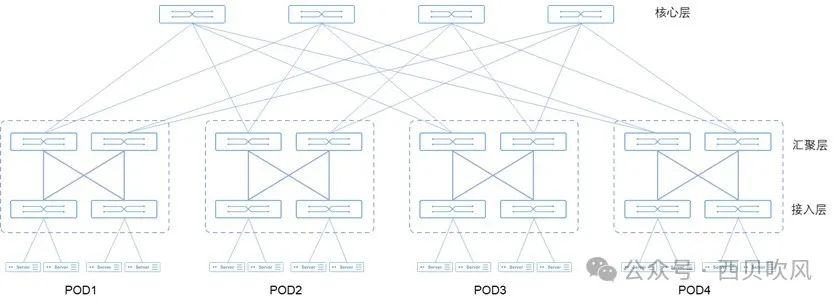
如果交換機的端口數量為n,則:兩層Fat-Tree架構能夠接入n2/2張GPU卡,以40端口的InfiniBand交換機為例,能夠接入的GPU數量最多可達800個。三層Fat-Tree架構能夠接入n(n/2)*(n/2)張GPU卡,以40端口的InfiniBand交換機為例,能夠接入的GPU數量最多可達16000個。
但是,Fat-Tree架構也存在明顯的缺陷:
網絡中交換機與服務器的比值較大,需要大量的交換機和鏈路,因此,在大規模情況下成本相對較高。構建Fat-Tree需要的交換機數量為5M/n(其中,M是服務器的數量,n是交換機的端口數量),當交換機的端口數量n較小時,連接Fat-Tree需要的交換機數量龐大,從而增加了布線和配置的復雜性;
拓撲結構的特點決定了網絡不能很好的支持One-to-All及All-to-All網絡通信模式,不利于部署?MapReduce、Dryad等高性能分布式應用;
擴展規模在理論上受限于核心層交換機的端口數目。
Fat-Tree架構的本質是CLOS架構網絡,主要關注通用性和無收斂,犧牲了時延和性價比。在構建大規模集群網絡時需要增加網絡層數,需要更多的互聯光纖和交換機,帶來成本的增加,同時隨著集群規模增大,網絡跳數增加,導致通信時延增加,也可能會無法滿足業務低時延需求。
Dragonfly架構
Dragonfly是當前應用最廣泛的直連拓撲網絡架構,它由John Kim等人在2008年的論文Technology-Driven, Highly-Scalable Dragonfly Topology中提出,它的特點是網絡直徑小、成本較低,已經在高性能計算網絡中被廣泛應用,也適用于多元化算力的數據中心網絡。
Dragonfly網絡如下圖所示:
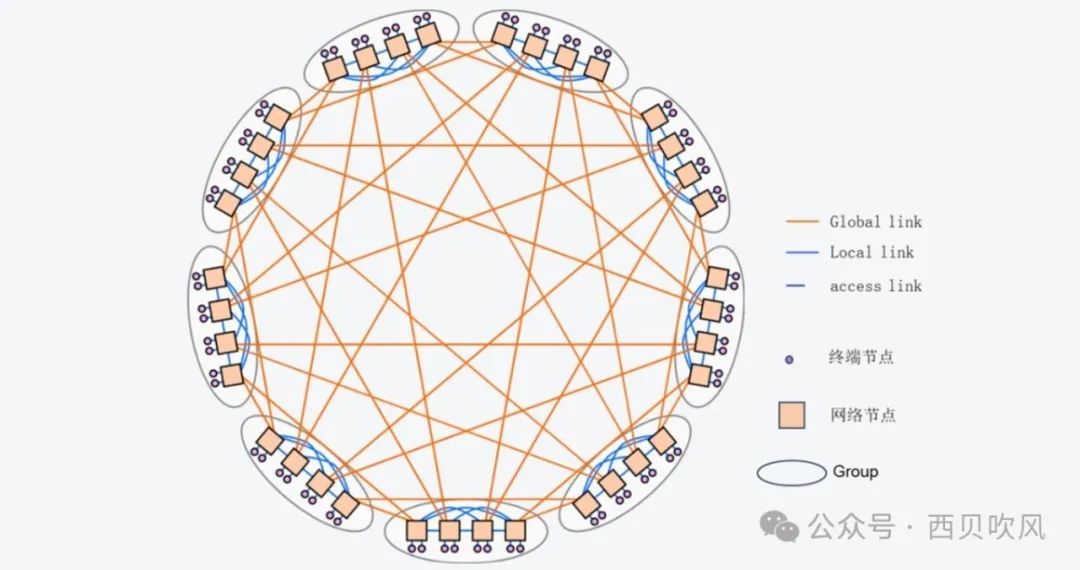
Dragonfly的拓撲結構分為三層:Switch層、Group層、System層。
Switch層:包括一個交換機及其相連的P個計算節點;
Group層:包含a個Switch層,這a個Switch層的a個交換機是全連接(All-to-all)的,換言之,每個交換機都有a-1條鏈路連接分別連接到其他的a-1臺交換機;
System層:包含g個Group層,這g個Group層也是全連接的。
對于單個Switch交換機,它有p個端口連接到了計算節點,a-1個端口連接到Group內其他交換機,h個端口連接到其他Group的交換機。因此,我們可以計算得到網絡中的如下屬性:
每個交換機的端口數為k=p+(a-1)+h
Group的數量為g=ah+1
網絡中一共有N=ap(ah+1)?個計算節點
如果我們把一個Group內的交換機都合成一個,將它們視為一個交換機,那么這個交換機的端口數為k‘=a(p+h)。
不難發現,在確定了?p、a、h、g四個參數之后,我們就可以確定一個Dragonfly的拓撲,因此,一個Dragonfly的拓撲可以用dfly(p,a,h,g)?來表示,一種推薦的較為平衡的配置是方法是:a=2p=2h。
Dragonfly的路由算法主要有以下幾種:
最小路由算法(Minimal Routing):由于拓撲的性質,Minimal Routing中最多只會有1條Global Link和2條Local Link,也就是說最多3跳即可到達。在任由兩個Group之間只有一條直連連接時(即g=ah+1時),最短路徑只有一條。
非最短路徑的路由算法(Non-Minimal Routing):有的地方叫Valiant algorithm,簡寫為VAL,還有的地方叫Valiant Load-balanced routing,簡寫為VLB。隨機選擇一個Group,先發到這個Group然后再發到目的地。由于拓撲的性質,VAL最多會經過2條Global Link和3條Local Link,最多5跳即可到達。
自適應路由(Adaptive Routing):當一個數據包到達交換機時,交換機根據網絡負載信息在最短路徑路由和非最短路徑路由路徑之間進行動態選路,優先采用最短路徑轉發,當最短路徑擁塞時,通過非最短路徑轉發。因為要獲取到全局網絡狀態信息比較困難,除了UGAL(全局自適應負載均衡路由),還提出了一系列變種自適應路由算法,如UGAL-L,UGAL-G等。
上述幾種路由,由于自適應路由能夠根據網絡鏈路狀態動態調整流量轉發路徑,因此會有更好的性能表現。
Dragonfly為各種應用程序(或通信模式)提供了良好的性能,與其他拓撲相比,它通過直連模式,縮短網絡路徑,減少中間節點數量。64端口交換機支持組網規模27萬節點,端到端交換機轉發跳數減至3跳。
Dragonfly拓撲在性能和性價比方面有顯著的優勢。然而,這種優勢的實現需要依賴于有效的擁塞控制和自適應路由策略。Dragonfly網絡在擴展性方面存在問題,每次需要增加網絡容量時,都必須對Dragonfly網絡進行重新布線,這增加了網絡的復雜性和管理難度。
Torus架構
隨著模型參數的增加和訓練數據的增加,單臺機器算力無法滿足,存儲無法滿足,所以要分布式機器學習,集合通信則是分布式機器學習的底層支撐,集合通信的難點在于需要在一定的網絡互聯結構的約束下進行高效的通信,需要在效率與成本、帶寬與時延、客戶要求與質量、創新與產品化等之間進行合理取舍。
Torus網絡架構是一種完全對稱的拓撲結構,具有很多優良特性,如網絡直徑小、結構簡單、路徑多以及可擴展性好等特點,非常適合集合通信使用。索尼公司提出2D-Torus算法,其主要思想就是組內satter-reduce->組間all-reduce->組內all-gather。?IBM提出了3D-Torus算法。
我們用k-ary n-cube來表示。k是排列的邊的長度,n是排列的維度。
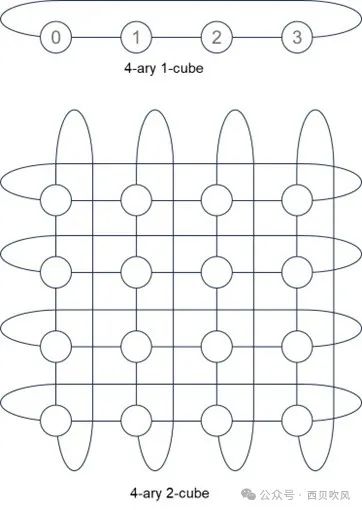
3-ary 3-cube拓撲如下:
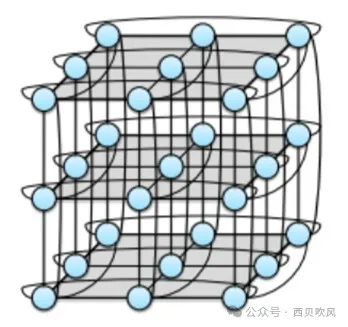
以2D-Torus拓撲為例,可以將網絡結構表達成如下的Torus結構。
橫向:每臺服務器X個GPU節點,每GPU節點通過私有協議網絡互聯(如NVLINK);
縱向:每臺服務器通過至少2張RDMA網卡NIC 0 /NIC 1通過交換機互聯。
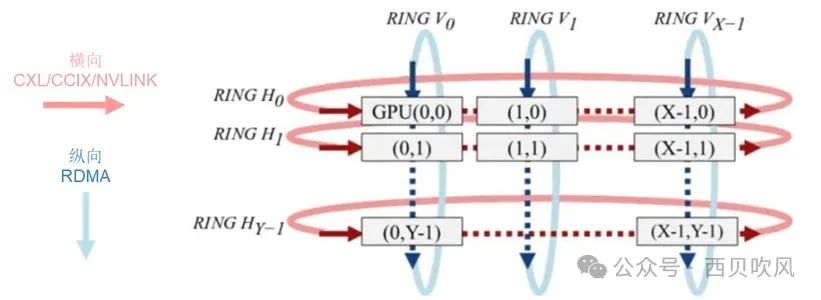
第1步,橫向,先進行主機內Ring Scatter Reduce,將主機內8張卡上的梯度進行拆分與規約,這樣經過迭代,到最后每個GPU將有一個完整的同維梯度,該塊梯度包含所有GPU中該塊所對應的所有梯度的總和;
第2步,縱向,進行主機間X個縱向的?Ring All Reduce,將每臺服務器的X個GPU上的數據進行集群內縱向全局規約;
第3步,橫向,進行主機內All Gather,將GPUi[i=0~(X-1)]上的梯度復制到服務器內的其他GPU上;
Torus網絡架構具有如下優勢:
更低的延遲:環面拓撲可以提供更低的延遲,因為它在相鄰節點之間有短而直接的鏈接;
更好的局部性:在環面網絡中,物理上彼此靠近的節點在邏輯上也很接近,這可以帶來更好的數據局部性并減少通信開銷,從而降低時延和功耗。
較低的網絡直徑:對于相同數量的節點,環面拓撲的網絡直徑低于CLOS網絡,需要更少的交換機,從而節省大量成本。
Torus網絡架構也存在一些不足:
可預測方面,環面網絡中是無法保證的;
易擴展方面:縮放環面網絡可能涉及重新配置整個拓撲,可能更加復雜和耗時;
負載平衡方面:環面網絡提供多條路徑,但相對Fat-tree備選路徑數量要少;
故障排查:對于突發故障的排查復雜性略高,不過動態可重配路由的靈活性可以大幅避免事故。
Torus網絡拓撲除了2D/3D結構外,也在向更高維度發展,Torus高維度網絡中的一個單元稱之為硅元,一個硅元內部采用3D-Torus拓撲結構,多個硅元可以構建更高維的4D/5D/6D-Torus直接網絡。
審核編輯:黃飛
?












 工商網監
工商網監
評論