 電子發燒友App
電子發燒友App


由騰訊云基礎產品中心、騰訊架構平臺部組成的騰訊云FPGA聯合團隊,在這里介紹國內首款FPGA云服務器的工程實現深度學習算法(AlexNet),討論深度學習算法FPGA硬件加速平臺的架構。
在1 月 20 日,騰訊云推出國內首款高性能異構計算基礎設施——FPGA 云服務器,將以云服務方式將大型公司才能長期支付使用的 FPGA 普及到更多企業,企業只需支付相當于通用CPU約40%的費用,性能可提升至通用CPU服務器的30倍以上。具體分享內容如下:
?
1. 綜述
2016年3月份AI圍棋程序AlphaGo戰勝人類棋手李世石,點燃了業界對人工智能發展的熱情,人工智能成為未來的趨勢越來越接近。
人工智能包括三個要素:算法,計算和數據。人工智能算法目前最主流的是深度學習。計算所對應的硬件平臺有:CPU、GPU、FPGA、ASIC。由于移動互聯網的到來,用戶每天產生大量的數據被入口應用收集:搜索、通訊。我們的QQ、微信業務,用戶每天產生的圖片數量都是數億級別,如果我們把這些用戶產生的數據看成礦藏的話,計算所對應的硬件平臺看成挖掘機,挖掘機的挖掘效率就是各個計算硬件平臺對比的標準。
最初深度學習算法的主要計算平臺是 CPU,因為 CPU 通用性好,硬件框架已經很成熟,對于程序員來說非常友好。然而,當深度學習算法對運算能力需求越來越大時,人們發現 CPU 執行深度學習的效率并不高。CPU 為了滿足通用性,芯片面積有很大一部分都用于復雜的控制流和Cache緩存,留給運算單元的面積并不多。這時候,GPU 進入了深度學習研究者的視野。GPU原本的目的是圖像渲染,圖像渲染算法又因為像素與像素之間相對獨立,GPU提供大量并行運算單元,可以同時對很多像素進行并行處理,而這個架構正好能用在深度學習算法上。
GPU 運行深度學習算法比 CPU 快很多,但是由于高昂的價格以及超大的功耗對于給其在IDC大規模部署帶來了諸多問題。有人就要問,如果做一個完全為深度學習設計的專用芯片(ASIC),會不會比 GPU 更有效率?事實上,要真的做一塊深度學習專用芯片面臨極大不確定性,首先為了性能必須使用最好的半導體制造工藝,而現在用最新的工藝制造芯片一次性成本就要幾百萬美元。去除資金問題,組織研發隊伍從頭開始設計,完整的設計周期時間往往要到一年以上,但當前深度學習算法又在不斷的更新,設計的專用芯片架構是否適合最新的深度學習算法,風險很大。可能有人會問Google不是做了深度學習設計的專用芯片TPU?從Google目前公布的性能功耗比提升量級(十倍以上的提升)上看,還遠未達到專用處理器的提升上限,因此很可能本質上采用是數據位寬更低的類GPU架構,可能還是具有較強的通用性。這幾年,FPGA 就吸引了大家的注意力,亞馬遜、facebook等互聯網公司在數據中心批量部署了FPGA來對自身的深度學習以云服務提供硬件平臺。
FPGA 全稱「可編輯門陣列」(Field Programmable Gate Array),其基本原理是在 FPGA 芯片內集成大量的數字電路基本門電路以及存儲器,而用戶可以通過燒寫 FPGA 配置文件來來定義這些門電路以及存儲器之間的連線。這種燒入不是一次性的,即用戶今天可以把 FPGA 配置成一個圖像編解碼器,明天可以編輯配置文件把同一個 FPGA 配置成一個音頻編解碼器,這個特性可以極大地提高數據中心彈性服務能力。所以說在 FPGA 可以快速實現為深度學習算法開發的芯片架構,而且成本比設計的專用芯片(ASIC)要便宜,當然性能也沒有專用芯片(ASIC)強。ASIC是一錘子買賣,設計出來要是發現哪里不對基本就沒機會改了,但是 FPGA 可以通過重新配置來不停地試錯知道獲得最佳方案,所以用 FPGA 開發的風險也遠遠小于 ASIC。
2. Alexnet 算法分析2.1 Alexnet模型結構
Alexnet模型結構如下圖2.1所示。

圖2.1 Alexnet模型
模型的輸入是3x224x224大小圖片,采用5(卷積層)+3(全連接層)層模型結構,部分層卷積后加入Relu,Pooling 和Normalization層,最后一層全連接層是輸出1000分類的softmax層。如表1所示,全部8層需要進行1.45GFLOP次乘加計算,計算方法參考下文。
層數
kernel個數
每個kernel進行卷積次數
每個kernel一次卷積運算量
浮點乘加次數
?
第1層
96
3025
(1x363)x(363x1)
96x3025x363=105M=210MFLOP
?
第2層
256
729
(1x1200)x(1200x1)
256x729x1200=224M=448MFLOP
?
第3層
384
169
(1x2304)x(2304x1)
384x169x2304=150M=300MFLOP
?
第4層
384
169
(1x1728)x(1728x1)
384x169x1728=112M=224MFLOP
?
第5層
256
169
(1x1728)x(1728x1)
256x169x1728=75M=150MFLOP
?
第6層
1
4096
(1x9216)x(9216x1)
4096x9216=38M=76MFLOP
?
第7層
1
4096
(1x4096)x(4096x1)
4096x4096=17M=34MFLOP
?
第8層
1
1000
(1x4096)x(4096x1)
1000x4096=4M=8MFLOP
?
總和
1.45GFLOP
?
表2.1 Alexnet浮點計算量
2.2 Alexnet 卷積運算特點
Alexnet的卷積運算是三維的,在神經網絡計算公式: y=f(wx+b) 中,對于每個輸出點都是三維矩陣w(kernel)和x乘加后加上bias(b)得到的。如下圖2.2所示,kernel的大小M=Dxkxk,矩陣乘加運算展開后 y = x[0]*w[0]+ x[1]*w[1]+…+x[M-1]*w[M-1],所以三維矩陣運算可以看成是一個1x[M-1]矩陣乘以[M-1]x1矩陣。

圖2.2 Alexnet三維卷積運算
每個三維矩陣kernel和NxN的平面上滑動得到的所有矩陣X進行y=f(wx+b)運算后就會得到一個二維平面(feature map)如圖2.3 所示。水平和垂直方向上滑動的次數可以由 (N+2xp-k)/s+1 得到(p為padding的大小),每次滑動運算后都會得到一個點。
a) N是NxN平面水平或者垂直方向上的大小;
b) K是kernel在NxN平面方向上的大小kernel_size;
c) S是滑塊每次滑動的步長stride;

圖2.3 kernel進行滑窗計算
Kernel_num 個 kernel 經過運算后就會得到一組特征圖,重新組成一個立方體,參數H = Kernel_num,如圖2.4所示。這個卷積立方體就是卷積所得到的的最終輸出結果。

圖2.4 多個kernel進行滑窗計算得到一組特征圖
3. AlexNet模型的FPGA實現3.1 FPGA異構平臺
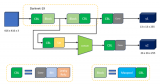
圖3.1為異構計算平臺的原理框圖,CPU通過PCIe接口對FPGA傳送數據和指令,FPGA根據CPU下達的數據和指令進行計算。在FPGA加速卡上還有DDR DRAM存儲資源,用于緩沖數據。

圖3.1 FPGA異構系統框圖
3.2 CNN在FPGA的實現3.2.1 將哪些東西offload到FPGA計算?
在實踐中并不是把所有的計算都offload到FPGA,而是只在FPGA中實現前5層卷積層,將全連接層和Softmax層交由CPU來完成,主要考慮原因:
全連接層的參數比較多,計算不夠密集,要是FPGA的計算單元發揮出最大的計算性能需要很大的DDR帶寬;
實際運用中分類的數目是不一定的,需要對全連階層和Softmax層進行修改,將這兩部分用軟件實現有利于修改。
3.2.2 實現模式
Alexnet的5個卷積層,如何分配資源去實現它們,主要layer并行模式和layer串行模式:
Layer并行模式:如圖3.2所示,按照每個layer的計算量分配不同的硬件資源,在FPGA內同時完成所有layer的計算,計算完成之后將計算結果返回CPU。優點是所有的計算在FPGA中一次完成,不需要再FPGA和DDR DRAM直接來回讀寫中間結果,節省了的DDR帶寬。缺點就是不同layer使用的資源比較難平衡,且layer之間的數據在FPGA內部進行緩沖和格式調整也比較難。另外,這種模式當模型參數稍微調整一下(比如說層數增加)就能重新設計,靈活性較差。

圖3.2 layer并行模式下資源和時間分配示意圖
Layer串行模式:如圖3.3所示,在FPGA中只實現完成單個layer的實現,不同layer通過時間上的復用來完成。優點是在實現時只要考慮一層的實現,數據都是從DDR讀出,計算結果都寫回DDR,數據控制比較簡單。缺點就是因為中間結果需要存儲在DDR中,提高了對DDR帶寬的要求。

圖3.3 layer并行模式下資源和時間分配示意圖
我們的設計采用了是Layer串行的模式,數據在CPU、FPGA和DDR直接的交互過程如圖3.4所示。

圖3.4 計算流程圖
3.2.3 計算單個Layer的PM(Processing Module)設計
如圖3.5所示,數據處理過程如下,所有過程都流水線進行:
Kernel和Data通過兩個獨立通道加載到CONV模塊中;
CONV完成計算,并將結果存在Reduce RAM中;
(可選)如果當前layer需要做ReLU/Norm,將ReLU/Norm做完之后寫回Reduce RAM中;
(可選)如果當前layer需要做Max Pooling,將Max做完之后寫回Reduce RAM中;
將計算結果進行格式重排之后寫回DDR中。

圖3.5 Processing Module的結構框圖
3.2.4 CONV模塊的設計
在整個PM模塊中,最主要的模塊是CONV模塊,CONV模塊完成數據的卷積。
由圖3.6所示,卷積計算可以分解成兩個過程:kernel及Data的展開和矩陣乘法。
Kernel可以預先將展開好的數據存在DDR中,因此不需要在FPGA內再對Kernel進行展開。Data展開模塊,主要是將輸入的feature map按照kernel的大小展開成可以同kernel進行求內積計算的矩陣。數據展開模塊的設計非常重要,不僅要減小從DDR讀取數據的數據量以減小DDR帶寬的要求,還要保證每次從DDR讀取數據時讀取的數據為地址連續的大段數據,以提高DDR帶寬的讀取效率。

圖3.6 卷積過程示意圖
圖3.7為矩陣乘法的實現結構,通過串聯乘加器來實現,一個周期可以完成一次兩個向量的內積,通過更新端口上的數據,可以實現矩陣乘法。

圖3.7 矩陣乘法實現結構
展開后的矩陣比較大,FPGA因為資源結構的限制,無法一次完成那么的向量內積,因此要將大矩陣的乘法劃分成幾個小矩陣的乘加運算。拆分過程如圖3.8所示。
假設大矩陣乘法為O= X*W,其中,輸入矩陣X為M*K個元素的矩陣;權重矩陣W為K*P個元素的矩陣;偏置矩陣O為M*P個元素的矩陣;

圖3.8 大矩陣乘法的拆分過程
R = K/L,如果不能整除輸入矩陣,權重矩陣和偏置通過補零的方式將矩陣處理成可以整除;
S = P/Q,如果不能整除將權重矩陣和偏置矩陣通過補零的方式將矩陣處理成可以整除;
3.2.5實現過程的關鍵點
決定系統性能的主要因素有:DSP計算能力,帶寬和片內存儲資源。好的設計是將這三者達到一個比較好的平衡。參考文獻[2]開發了roofline性能模型來將系統性能同片外存儲帶寬、峰值計算性能相關聯。
為了達到最好的計算性能就是要盡可能地讓FPGA內的在每一個時鐘周期都進行有效地工作。為了達到這個目標,CONV模塊和后面的ReLU/Norm/Pooling必須能異步流水線進行。Kernel的存儲也要有兩個存儲空間,能對系數進行乒乓加載。另外,由于計算是下一層的輸入依賴于上一層的輸出,而數據計算完成寫回DDR時需要一定時間,依次應該通過交疊計算兩張圖片的方式(Batch=2)將這段時間通過流水迭掉。
要選擇合適的架構,是計算過程中Data和Kernel只要從DDR讀取一次,否則對DDR帶寬的要求會提高。
3.3 性能及效益
如圖3.9所示采用FPGA異構計算之后,FPGA異構平臺處理性能是純CPU計算的性能4倍,而TCO成本只是純CPU計算的三分之一。本方案對比中CPU為2顆E5-2620,FPGA為Virtex-7 VX690T,這是一個28nm器件,如果采用20nm或16nm的器件會得到更好的性能。

圖3.9 計算性能對比

圖3.10 歸一化單位成本對比
圖3.11為實際業務中利用FPGA進行加速的情況,由圖中數據可知FPGA加速可以有效降低成本。

圖3.11 某實際業務中的性能和成本對比
參考文獻
[1] Alex Krizhevsky. ImageNet Classification with Deep Convolutional Neural Networks
[2] C. Zhang, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks. In ACM ISFPGA 2015.
[3] P Gysel, M Motamedi, S Ghiasi. Hardware-oriented Approximation of Convolutional Neural Networks. 2016.
[4] Song Han,Huizi Mao,William J. Dally.DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING. Conference paper at ICLR,2016





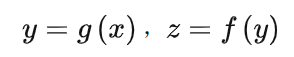






 工商網監
工商網監
評論