 電子發燒友App
電子發燒友App


Amazon Alexa、Apple Siri 和 Google Home 等語音控制界面依靠始終在線的語音捕獲功能來檢測用于啟動復雜語音處理算法的喚醒詞或短語,這些算法通常需要基于云的資源。然而,隨著基于語音的控制轉移到電池供電的設備并增加了其他消費設備(如電視)的待機功率預算,這種始終開啟的功能代表了顯著的功耗,并增加了設計挑戰。然而,使用一些低功耗設備,開發人員可以更輕松地實現語音控制接口,而不會影響功率預算。
本文介紹了開發人員如何將聲控微機電系統 (MEMS) 麥克風與低功耗處理器或編解碼器結合使用,以創建超低功耗、始終在線的聲控設計。以舉例的方式,介紹和描述Vesper Technologies的VM1010 MEMS 麥克風和 Ambiq Micro 的 Apollo3 AMA3B1KK 微控制器在本應用中的使用。
從低功耗到超低功耗麥克風
設計聲控電路本身并不是一項重大挑戰。使用麥克風和運算放大器,工程師可以輕松創建能夠檢測環境聲音何時超過某個預設閾值的電路(例如,請參閱“使用 LaunchPad 激活開關聲音”)。在以低功耗為關鍵要求的設計中應用這些簡單的方法進行始終在線檢測時會出現挑戰。對于這些設備,即使是有源麥克風和放大器的相對適度的電流要求也可能超過功率預算,特別是在電池供電設計和待機功率必須符合能源之星指南的消費類設備中。
多年來,設計人員一直在低功率電子設備中利用微型、低功率駐極體電容麥克風。例如,Knowles FG 系列等超小型駐極體麥克風 在 1.3 伏電源下消耗最多 50 微安 (μA)。
MEMS 技術的出現使制造商能夠創建超低功耗單端輸出麥克風,將緩沖放大器和其他支持電路結合在同一封裝中(圖 1)。
?
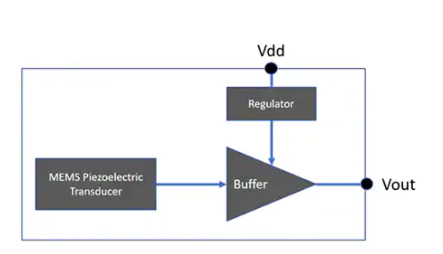
圖 1:制造商已經集成了一個 MEMS 傳感器、一個緩沖放大器和一個穩壓器,以提供一個生成單端電壓輸出 Vout 的完整麥克風。(圖片來源:Vesper Technologies)
結果是一個集成的 MEMS 麥克風設備,有助于降低音頻前端設計的總體成本、復雜性和功耗。然而,需要為這些堅固、省電的麥克風保持全功率,這意味著即使是最節能的聲控產品也會不斷消耗電流,并且在長時間安靜時這樣做會導致效率低下。
該問題已通過使用一種特殊的聲控 MEMS 麥克風得到解決,例如 Vesper Technologies 的 VM1010。使用這些設備,開發人員可以進一步降低非活動期間的功耗。此外,通過將此麥克風與超低功耗微控制器或編解碼器一起使用,開發人員可以在對低功耗有嚴格要求的產品中設計復雜的始終開啟的聲控語音接口。
聲控麥克風
在其正常的全功率運行模式下,VM1010 麥克風作為傳統的高性能單端麥克風運行。它在其模擬輸出引腳 Vout 上提供捕獲的聲音信號時消耗 85 μA。在此模式下,麥克風將聲音轉換為 20 赫茲 (Hz) 至 20 千赫茲 (KHz) 的整個頻率范圍,在 94 dB 的聲壓級 (SPL) 下靈敏度為 -38 電壓分貝 (dBV)。與一些早期的 MEMS 麥克風不同,Vesper VM1010 只需幾毫秒即可從非常高 SPL 的聲音沖擊中恢復。
與傳統的 MEMS 麥克風不同,VM1010 提供了第二種低功耗的聲音喚醒模式。在這種模式下,VM1010 利用 Vesper ZeroPower 監聽子系統(圖 2)。這是 Vesper 對傳統 MEMS 麥克風架構的獨特擴展。
?
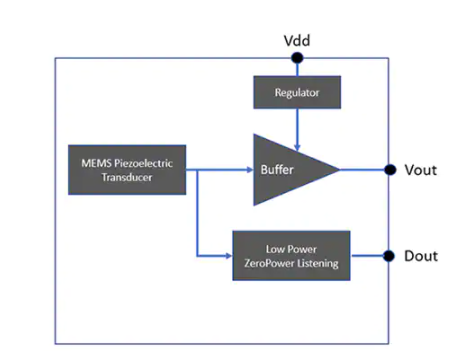
圖 2:Vesper Technologies VM1010 MEMS 麥克風擴展了傳統的 MEMS 麥克風架構,具有專門的 ZeroPower Listening 子系統,可監控傳感器輸出并在檢測到的聲音超過可配置閾值時在其 Dout 數字輸出上生成信號。(圖片來源:Vesper Technologies)
在聲音喚醒模式下,VM1010 僅消耗 10 μA 電流,這通常低于便攜式揚聲器、甚至智能手表或健身可穿戴設備中電池的自放電電流。在這種模式下,設備以更有限的頻率響應運行,從 250 Hz 到 6 KHz。使用這個縮小的范圍,VM1010 可以更可靠地捕捉人聲范圍的主要頻率,同時減少來自環境中不同噪聲源的誤報。
VM1010 在聲音喚醒模式下禁用其 Vout 模擬輸出,但麥克風會繼續監控外部環境的聲音。當聲音發生時,MEMS 麥克風的壓電元件會發生響應偏轉,從而在內部產生一個小的電壓電平。當聲壓將此內部電壓電平增加到可配置閾值以上時,器件的集成比較器電路通過將 VM1010 Dout 輸出設置為數字“高”電平來做出響應。
開發者可以調整VM1010的喚醒聲音閾值。如果 VM1010 的 GA1 和 GA2 聲音喚醒聲學閾值引腳處于開路狀態,則該器件以 89 dB SPL 的最大聲學閾值運行。然而,通過在 GA1 和 GA2 之間連接一個電阻器,可以將閾值調整到最低 65 dB SPL(圖 3)。
?
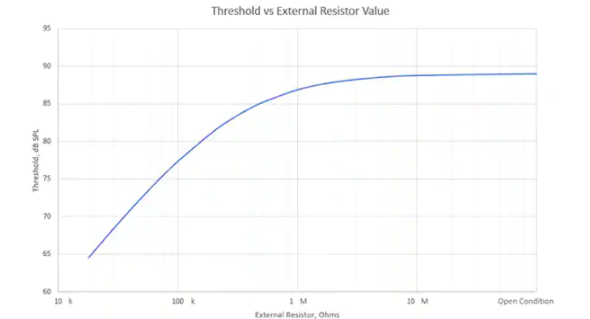
圖 3:開發人員可以通過在設備的 GA1 和 GA2 引腳之間放置一個電阻器來降低 VM1010 的默認聲音檢測閾值。(圖片來源:Vesper Technologies)
VM1010 麥克風能夠在檢測到高于預設閾值的聲音時發出信號,這為在更大設計的完整語音處理鏈中降低功耗奠定了基礎。
喚醒信號
在使用 VM1010 進行設計時,開發人員可以將該器件用作傳統的單端模擬麥克風,將 VM1010 的 Vout 模擬信號輸出連接到處理器的內部模數轉換器 (ADC)。然而,在典型的節能設計中,開發人員會在 VM1010 的數字引腳和處理器的 GPIO 引腳之間建立兩個額外的連接(圖 4)。
?
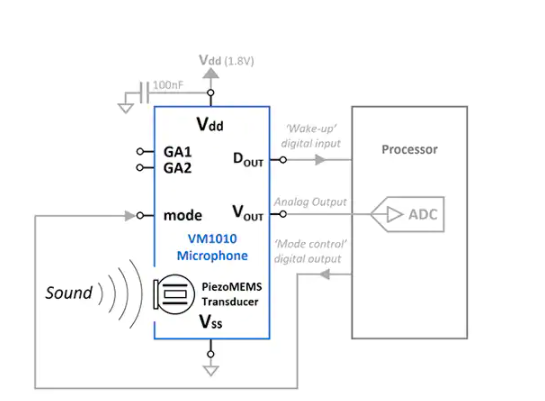
圖 4:開發人員可以使用一個簡單的接口來實現 VM1010 MEMS 麥克風的聲音喚醒功能,除了麥克風的模擬輸出和 MCU 的 ADC 之間的通常模擬連接之外,該接口只需要兩個額外的數字連接。(圖片來源:Digi-Key,來自 Vesper Technologies 源材料)
要使用 VM1010 的聲音喚醒檢測功能,其 Dout 數字輸出需要連接到啟用中斷的 GPIO,其模式輸入端口需要連接到單獨的 GPIO。
使用這個簡單的接口,開發人員可以通過限制處于完全活動狀態的時間來顯著降低整體系統功耗。要將 VM1010 切換到其低功耗聲音喚醒模式,處理器 GPIO 用于將模式引腳設置為高電平。通常,切換到聲音喚醒模式與處理器中向低功率睡眠狀態的轉換一起執行。
當 VM1010 檢測到聲音并將 Dout 設置為高電平時,產生的信號轉換將處理器從其睡眠狀態中喚醒。作為返回活動模式的一部分,連接到模式引腳的 GPIO 設置為低電平,導致 VM1010 在 200 μs 內返回到其全功率模式 - 恰好在捕獲輸入音頻波形所需的時間內。在處理接收到的音頻后,處理器可以將 VM1010 返回到聲音喚醒模式并返回低功耗睡眠狀態,直到 VM1010 發出下一個喚醒信號。
在設計用于檢測喚醒詞的系統中,開發人員可以通過處理器執行的一系列測試來簡單地擴展這個聲音喚醒序列。在 VM1010 檢測到聲音并使用其 Dout 信號喚醒處理器后,處理器首先測試語音活動的跡象。在這里,處理器可能會執行代碼來尋找諸如聲音的頻率范圍和持續時間之類的指標。如果這些指示符提示語音信號,則處理器將使用檢測喚醒詞所需的更重要的處理序列。
在檢測到喚醒詞后,處理器將通過低功耗藍牙 (BLE) 或其他無線接口與移動主機通信來啟動高級語音處理序列,以利用云資源進行完整的語音識別。隨著該序列的每個階段完成(或由于某種原因失敗),開發人員可以通過將 VM1010 返回到聲音喚醒模式并將處理器置于低功耗睡眠狀態來優化功耗(圖 5)。
?
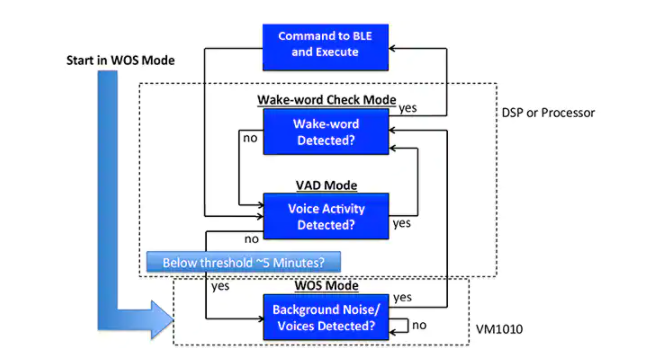
圖 5:開發人員可以通過在喚醒詞檢測序列中的每個操作階段之后將 VM1010 MEMS 麥克風和處理器返回到低功耗狀態來降低喚醒詞檢測設計中的功耗。(圖片來源:Vesper Technologies)
降低系統功耗
盡管聲音喚醒功能可以在較長的安靜期間降低系統功耗,但總體系統功耗通常取決于處理器的節能特性。具有集成連接選項的超低功耗處理器的出現為開發人員提供了高效的解決方案。例如,Ambiq Micro Apollo3 AMA3B1KK 微控制器在主動模式下的功耗僅為 6 μA/兆赫 (MHz),同時在 3.3 伏電源軌下從閃存或隨機存取存儲器 (RAM) 執行。
使用 Apollo3,開發人員可以輕松實現前面描述的那種節能序列。例如,在使用 Apollo3 GPIO 將 VM1010 設置為聲音喚醒模式后,開發人員可以發出等待中斷 (WFI) 指令,使微控制器進入深度睡眠模式。在深度睡眠模式下,微控制器在保留 384 千字節 (Kbytes) 靜態 RAM 的情況下僅消耗 3 μA 電流,或者在沒有靜態 RAM 保留的情況下(全部采用 1.8 伏電源)消耗電流小于 1 μA。無線電操作通常是無線設計中的主要功耗來源,使用 Apollo3 的集成無線電子系統接收 (Rx) 和發送 (Tx) 僅需大約 3 毫安 (mA)。
同樣重要的是,集成在 Apollo3 等高級微控制器中的大量功能有助于簡化設計、減小封裝尺寸并縮短材料清單。例如,除了集成無線電子系統外,Apollo3 微控制器還包括一個高度集成的電源管理單元 (PMU),其中包含多個低壓差 (LDO) 穩壓器和降壓轉換器。
使用這些集成功能,開發人員通常可以使用 Vesper VM1010 MEMS 麥克風、Ambiq Micro Apollo3 微控制器和一組最少的外部無源組件來創建完整的設計。事實上,開發人員可以在 LDO 模式下使用 Apollo3 的集成 PMU,甚至可以消除降壓轉換器所需的外部電容器和電感器。
Apollo3 的集成 14 位 ADC 子系統進一步提高了設計效率和功耗優化。例如,可以通過將 ADC 子系統置于不同的低功耗模式來降低 ADC 功耗。例如,在 ADC 的低功耗模式 1 中,ADC 控制器關閉其時鐘和緩沖器,同時保留 ADC 校準數據。在此模式下運行時,Apollo3 ADC 需要不到 70 μs 的時間來啟動來自 VM1010 麥克風等模擬源的信號轉換。值得注意的是,ADC可以在這種模式下完成轉換,而處理器內核仍處于深度睡眠狀態。
如前所述,喚醒字的識別通常需要一個完全活動的處理器。因此,有必要將微控制器從深度睡眠模式轉換為運行模式。對于這種過渡,Apollo3 的集成 PMU 與設備的喚醒中斷控制器一起工作,以恢復電源和系統狀態。
深度睡眠的喚醒時間僅為 15 μs。結合將 VM1010 轉換到全功率模式所需的 200 μs,轉換到活動模式的總時間仍在使用 VM1010 麥克風捕獲音頻輸入信號所需的時間內。
增強的音頻設計
對于具有更復雜音頻處理要求的應用,設計人員可以將 VM1010 與 Vesper VM3000等數字 MEMS 麥克風結合使用。該器件使用集成 ADC 生成捕獲信號的脈沖密度調制 (PDM) 表示(圖 6)。
?
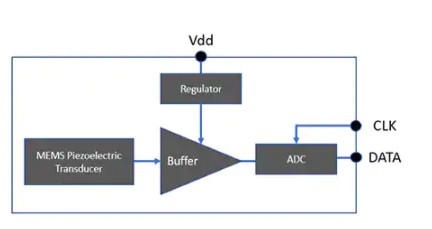
圖 6:Vesper 的 VM3000 MEMS 麥克風集成了一個 ADC,以提供時鐘啟用的數字數據輸出流。(圖片來源:Vesper Technologies)
使用 VM3000 的時鐘輸出,開發人員可以在一條數據線上多路復用一對這樣的麥克風,以更輕松地實現用于提高語音拾取靈敏度的波束成形陣列。在安靜期間,開發人員可以通過關閉 VM3000 的時鐘來節省電力,從而將設備置于電流消耗降至 2.5 μA 的睡眠模式。
增強的音頻設計將擴展包含 VM1010 和處理器的基本設計。使用處理器 GPIO,開發人員可以組合使用 VM1010 和 VM3000 麥克風,前者用于喚醒系統,后者陣列用于錄音。
啟動聲控設計
要開始試驗聲控設計,開發人員可以使用 Vesper 和 Ambiq Micro 的評估板。Vesper S-VM1010-C和S-VM3000-C MEMS 全向麥克風音頻評估板分別引出了 VM1010 和 VM3000 的引腳。要對基于 VM1010 聲音喚醒功能的音頻處理設計進行原型設計,可以使用CW Industries的CWR-170-10-0000等卡邊緣連接器,通過 Ambiq Micro AMA3BEVB Apollo3 為 MEMS 麥克風評估板提供面包板評估板。
結論
永遠在線的語音界面為使用語音控制產品或與基于云的服務交互提供了便利。將專用 MEMS 麥克風與超低功耗處理器結合使用,開發人員可以實現始終在線功能,同時滿足功耗要求。









 工商網監
工商網監
評論