 電子發燒友App
電子發燒友App


編者按:相較于前兩年,2023年音視頻行業的使用量增長緩慢,整個音視頻行業遇到瓶頸。音視頻的行業從業者面臨著相互競爭、不得不“卷”的狀態。我們需要進行怎樣的創新,才能從這種“卷”的狀態中脫離出來?LiveVideoStack 2023上海站邀請到了PPIO邊緣云的創始人王聞宇,和我們分享了他針對這一問題進行的思考。本次分享包括近年音視頻行業的分析、國外4款AIGC應用工具介紹、最新論文情況介紹,以及王聞宇對行業的看法和展望,以期為音視頻從業者提供更具廣度的行業視角。
文/王聞宇
大家好,今天有幸再次來到LVS的講臺給大家做分享。今天主要分享國外比較出名的音視頻工具及理論依據,以及一些視頻AIGC相關最新論文的情況,還有我對行業情況的思考。
我是王聞宇,現任PPIO邊緣云聯合創始人和CTO。從業音視頻行業多年、之前PPTV網絡電視創業團隊成員,也是架構師。現在在做PPIO邊緣云,是以提供算力為核心的服務,主要服務音視頻傳輸,轉碼,云端渲染和AIGC等業務。下面這張圖片是我用AIGC做的照片。
-01-
發生了什么
首先,2023年發生了什么事?
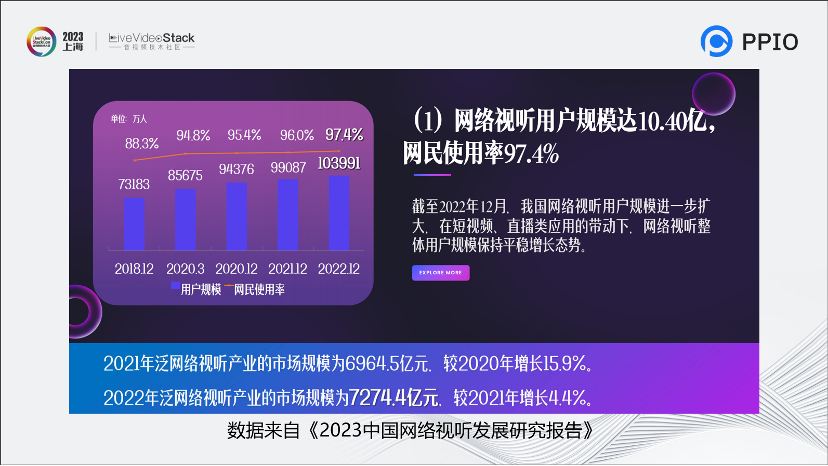
這張圖摘自《2023中國網絡視聽發展研究報告》。可以明顯看到,整個音視頻行業的使用量已經達到了增長緩慢的極限。比起22年底,21年底用戶人數只增加了一個百分點。22年產業的市場規模的增長速度也只有4.4個百分點。整個音視頻行業遇到了瓶頸,開始進入一個很緩慢的時代。
這是我們音視頻行業的從業者面臨著“卷”的根源,大家都在相互競爭。我們怎么樣創新才能從這種“卷”中出來?
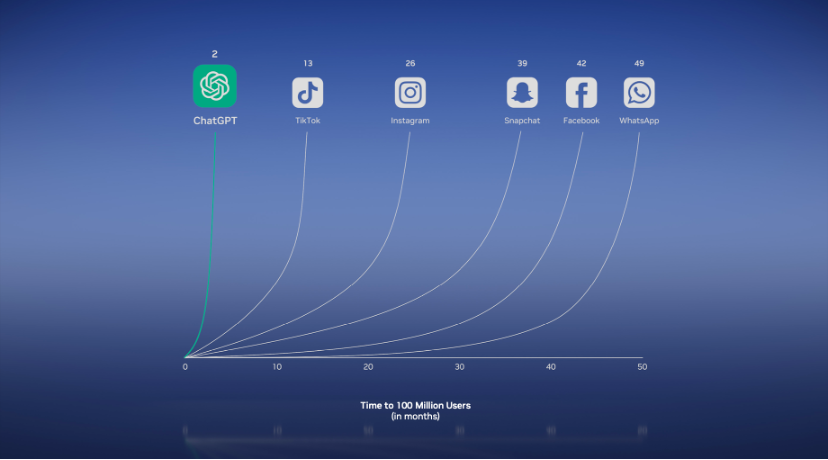
過去一年,世界發生了什么?請看下圖,這是ChatGPT,它達到一個億的用戶只用了兩天的時間,超過了歷史上所有的APP,甚至包括Tiktok,Instagram,Snapchat,Facebook等。
再看下圖,Stable Diffusion成為歷史上增速最快的項目。和它對標的項目是比特幣、以太坊、kafka、spark等知名項目。而且,Stable Diffusion基本上是垂直的線,一天時間就達到了幾萬關注。
這就是這次的十倍變化要素,AI的魅力。
這里回溯一下AI的發展過程:①在20世紀50年代,就有了基于規則的少量數據處理;后來80年代,基于統計學發展出了機器學習;②21世紀后,伴隨顯卡的性能提升,神經網絡,深度學習逐步得到應用;③特別是2014-2017年,神經網絡得到一系列的發展,包括CNN卷積神經網絡RNN、循環神經網絡、VAE、GAN生成對抗網絡等,AI在很多領域有了落地的應用。④直到2017年,Transfarmer的偉大發明,帶領我們進入了今天大語言模型的時代。⑤后來在2020年,Diffusion的發明,非常驚艷的生成圖片效果,點燃了AIGC繪畫的的浪潮。
那么視頻在什么時代呢?我的看法是視頻可能離走過這個鴻溝還有一定距離,這是在我分析過國外的APP后得出的想法。
接下來我給大家分享4款AIGC的應用。
-02-
音視頻應用AIGC在萌芽
第一款應用是D-ID,它的核心是實現面部的動畫。

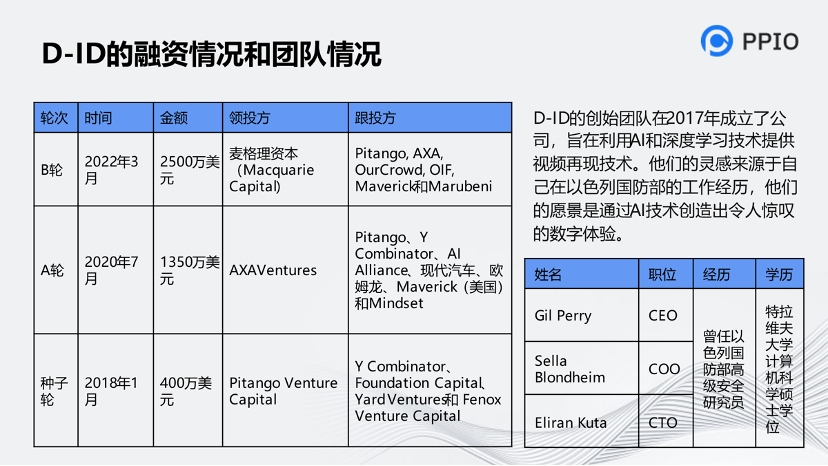
這是對他們公司做的分析,包括融資和創始人的經歷。國外音視頻的創業者并不都是名校畢業生。中國人只要再努力一下,是很容易超越國外的產品的。
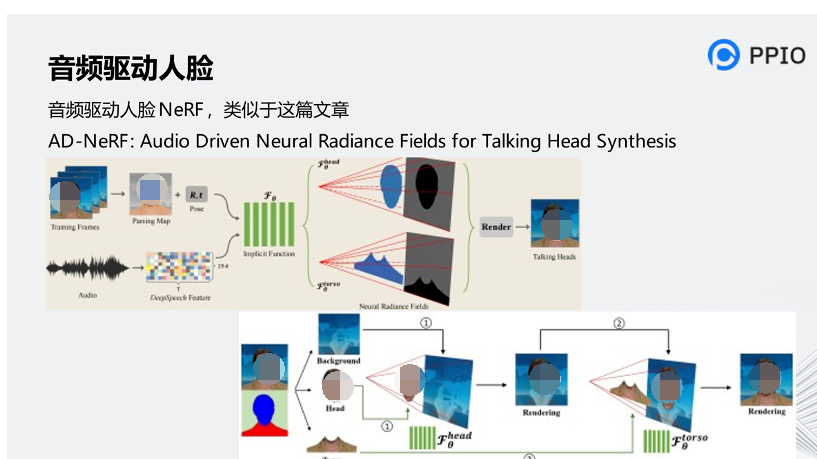
關于技術的實現,在他們CEO的一篇演講中有提到如何將聲音和嘴型進行對齊的內容,還提到了一種音頻驅動人臉的全神經輻射的技術。
它的本質是把一個圖像從2D生成3D的建模過程,但是文章中沒有提到具體是怎么做的,我們根據AD-NeRF進行相關的假設。
AD-NeRF這篇資料講述了音頻驅動人臉的技術原理。AD-NeRF是一種由語音信號直接生成說話人視頻的算法,僅需要目標人物幾分鐘的說話視頻,該方法即可實現對該人物超級逼真的形象復刻和語音驅動。首先利用人臉解析方法將整個訓練畫面分為三部分,分別是背景、頭部和軀干。其次,通過頭部的前景和背景的后景去訓練頭部部分模型。然后,通過頭部部分隱函數生產的圖像和背景作為后景,再把軀干作為前景,去訓練軀干部分的模型。
同時,聲音部分也作為AD-NeRF模型的一個新的特征輸入,通過DeepSpeech的方法,將聲音轉化成29維的特征數據,輸入到AD-NeRF模型當中。
在生成圖像的時候,通過對頭部模型和軀干模型輸入相同的特征,其中包括音頻特征和姿態特征,來完成AD-NeRF模型的推理。在最終立體渲染圖像的過程當中,首先采用頭部模型積累像素的采樣密度和RGB值,把渲染好的頭部圖像貼到靜態背景上,然后軀干模型通過預測軀干區域的前景像素來填充缺失的軀干部分。通過以上的方法,AD-NeRF實現了音頻驅動人臉當中頭部與上身運動一致,并讓產生動作與表情非常自然。
第二個分享的是Wonder Studio AI。它的兩位創始人不是計算機工程師,一個是藝術家,一個是《頭號玩家》的演員。它是在電影中或視頻中,把一個真實的人換成另一個真實的人或數字人。

這個項目的融資不多,但做的東西非常驚艷。兩位創始人都是電影制片人,還有一些顧問共同實現這個體系。有兩篇文章提到他們項目的實現方法,一篇是他們的官方文章,另一篇是國內一位博主對他們進行的分析。
要做到視頻內CG角色的實時替換,首先利用Opnepose等人體姿態估計算法對人物的3D姿態進行捕捉,并將其與建模好的CG模型進行綁定。其次,由于選定人物與CG模型在視頻中所占的空間環境不同,因此需要對選定人物的輪廓進行精準識別,并經過一定的處理讓選定人物仿佛在原視頻中沒有出現過一般,這里需要采用人物擦除算法。

目前,由清華團隊提出的Inpaint Anything能夠輕松實現這一需求。該算法基于Meta開源語義分割算法Segment Anything Model(SAM)對目標人物輪廓進行精準識別,生成Mask,再利用圖像生成算法LaMa或stable Diffusion能夠實現對Mask的圖像內容進行自定義填充。 但Wonder Studio官方沒有提到他們的方案具體是怎么實現的,以上是我就這個技術本身做的想法。

第三個工具是AIGC的官方應用,叫做Runway,它的定位是新一代的藝術,也是一個2c的產品。它提供了一個平臺,可以對視頻進行風格編輯,還有一系列的工具。它分為兩代:Gen1和Gen2。Gen1只能視頻轉化成視頻,視頻加上文字最后轉化為視頻。
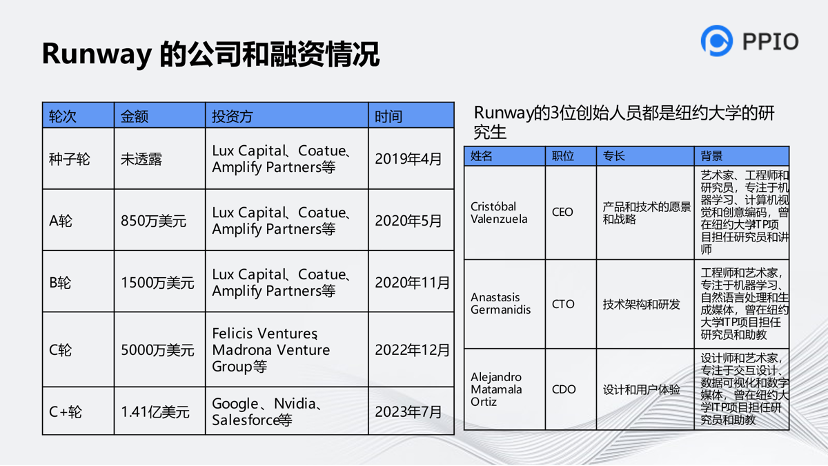
這家公司的融資背景非常深厚,在過去幾年緊跟AIGC的浪潮及爆發性場景的應用。值得注意的是,它的三位創始人員都是藝術家。而我們國內創業或公司創新的人都是工程師或者學術方面的人員。這家公司都是藝術家創業,可見他們更注重做出來的東西的感受。這也體現了東西方文化上的差異。
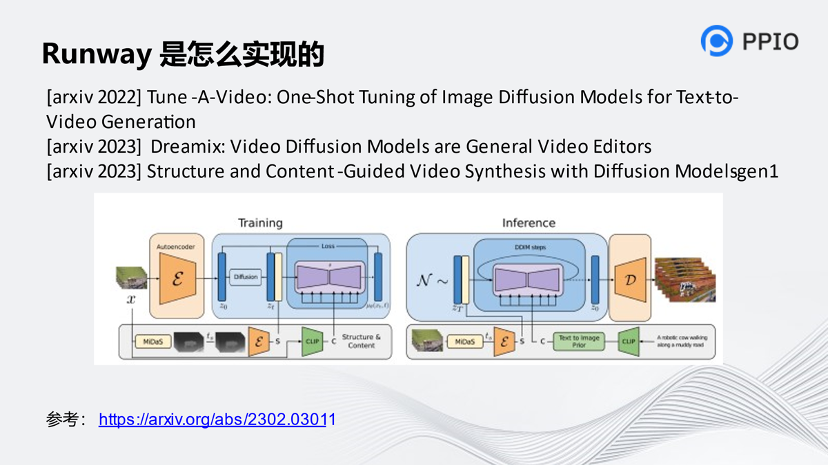
已有的研究中表明CLIP的圖像embedding對圖像內容在圖像中的位置和形態不敏感,而更關注內容本身,因此它是與深度這一結構信息較為“正交”的,使得Gen-1可以將圖像解耦為彼此干擾較小的結構信息和內容信息。
Gen-1和Stable Diffusion路徑很像,把中間的豎線去掉,基本上就是Stable Diffusion的架構。它把一個原始的視頻形成畫面,圖像的深度圖作為結構信息、CLIP編碼器的圖像embedding作為內容信息,在隱空間進行擴散模型的訓練。生成的時候也是把輸入的文本通過CLIP方式轉化回去,最后再進行干預,就能呈現視頻的結果。不同的是,它還運用了圖片的模式轉化,即MiDaS,把圖片生成一個框架,再干預這個環節。大概的技術原理是用文本干預視頻的過程,從而得出最后的效果。
https://arxiv.org/abs/2302.03011這篇論文是他們的官方論文。這個應用思路其實比較簡單,如果大家要做也不會很困難。
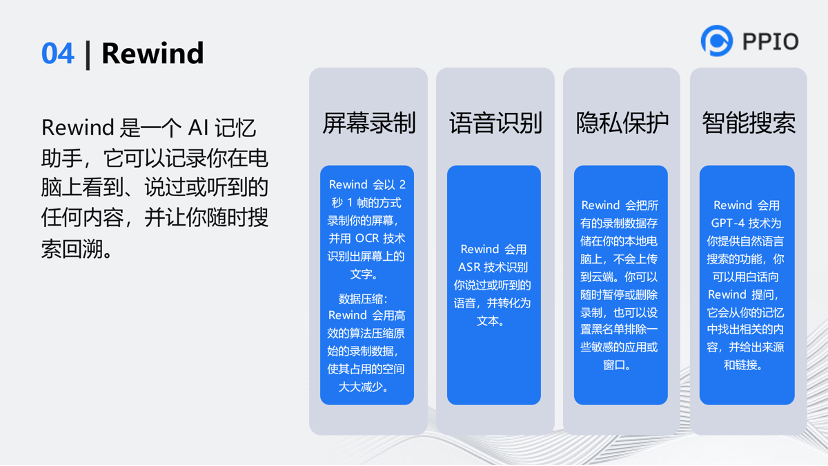
第四個工具是Rewind。這個工具特別厲害,很遺憾的是它只能在蘋果電腦上使用。它把大家日常工作的內容全部錄下來,整理后再通過GTP進行對接。這個工具嚴格來說不是完整的視頻應用,但它是個類視頻應用,我是它的重度用戶。可以通過回拉里面的進度條得知自己今天做的任何事,里面的文本也是可以摘出來的。
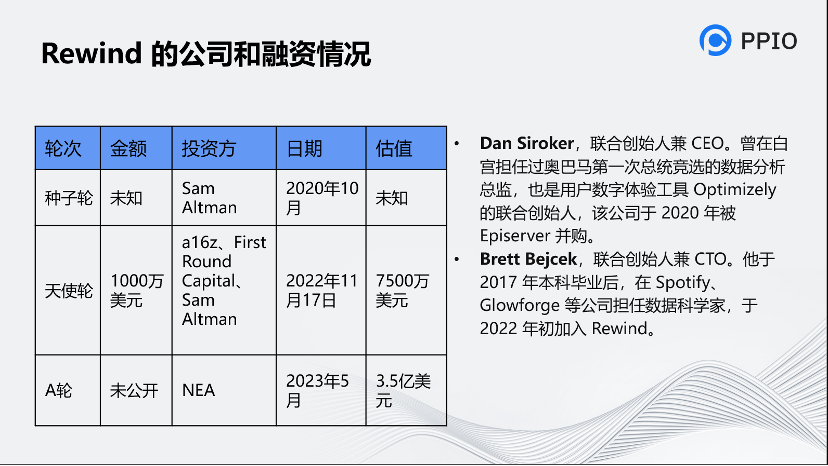
這個公司很有意思,Altman投了2輪,種子輪和天使輪,另外還拿到了很多知名的投資。
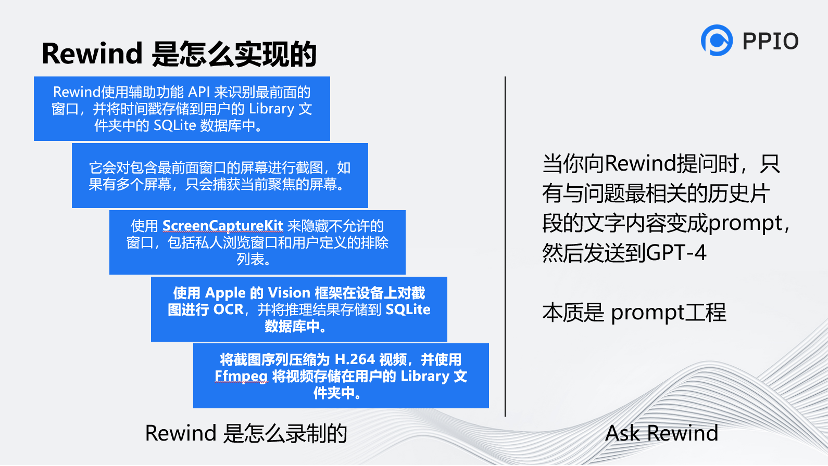
這個工具很有創意,它和音視頻技術關系不大。核心點是調用了蘋果的M1和M2芯片的接口,對顯示的內容做OCR,再把OCR后的內容用文本方式存起來,
另外,官方宣稱它用了H.264技術進行壓縮,來同時把視頻錄制了下來。(但是這里我是持懷疑的,能把視頻大小壓縮到70倍,但我覺得H.264的技術還有些挑戰)
最后,再把OCR的文本通過向量工程的方式和Chatgpt對接,從而具備了智能能力。當你問它(Rewind)你做了什么,它通過向量工程向Chatgpt調API來完成這一過程,所以它基本可以幫你總結出你每天都做了什么,你之前遇到了什么問題。它能夠對你的日常工作進行歸類,這是我用這個工具的原因。
其實AIGC視頻工具還有很多,我這里講的4個是比較典型的使用場景。
-03-
視頻生成研究最新趨勢
另外談談我對視頻生成技術的學習和研究。
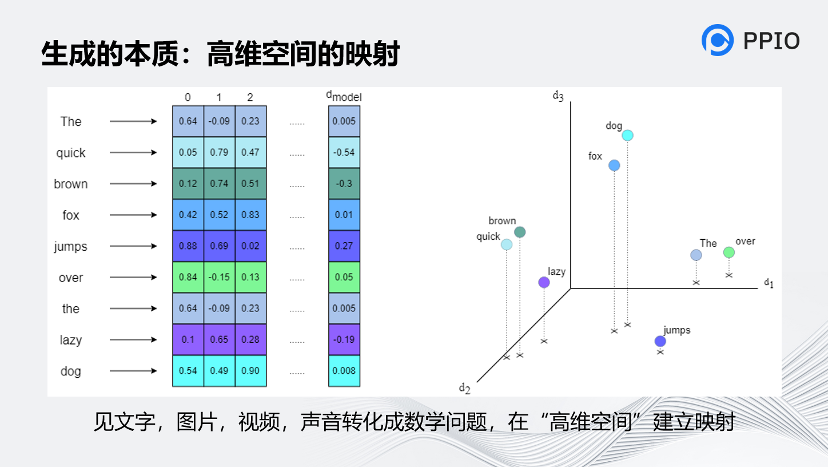
生成的本質是什么?我認為生成的本質是高維空間建立映射,不論是文字、圖片,還是視頻、音頻,最終都會轉化為數學問題,并在高維空間中建立起映射。而人腦正是因為能夠建立起這種高維的映射,才能形成一定的智能。
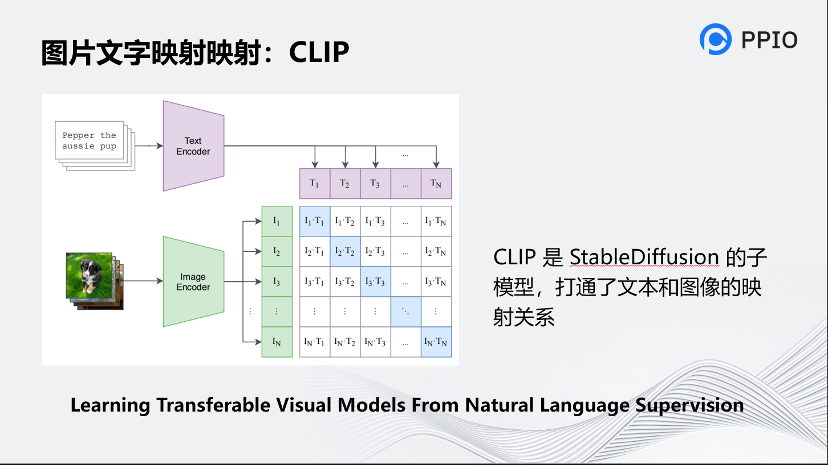
前面也提到的,CLIP是非常關鍵的技術,是StableDiffusion的子模型,打通了文本和圖像的映射關系。CLIP的原理是對文本和圖片分別通過Text Encoder和Image Encoder輸出對應的特征,然后在這些輸出的文字特征和圖片特征上進行對比學習,再將它進行映射。
為了訓練CLIP,OpenAI從互聯網收集了共4個億的文本-圖像對,論文稱之為WIT(Web Image Text)。WIT質量很高,而且清理得非常好,其規模相當于JFT-300M,這也是CLIP如此強大的原因之一。

這是谷歌的一篇論文,講的是視頻的Diffusion Model,它可以理解為是StabDiffusion的變種,它在StableDiffusion的每個過程中都引入了一個時間維度t,以實現時間注意力機制,使得它生成的畫面之間有一定的聯系。
為了使擴散模型適用于視頻生成任務,這篇論文提出了3D UNet,該架構使用到了space-only 3D卷積和時空分離注意力。具體來說,該架構將原UNet中的2D卷積替換成了space-only 3D卷積(space-only 3D convolution)。隨后的空間注意塊仍然保留,但只針對空間維度進行注意力操作,也就是把時間維度flatten為batch維度。在每個空間注意塊之后,新插入一個時間注意塊(temporal attention block),該時間注意塊在第一個維度即時間維度上執行注意力,并將空間維度flatten為batch維度。論文在每個時間注意力塊中使用相對位置嵌入(relative position embeddings),以便讓網絡能夠不依賴具體的視頻幀時間也能夠區分視頻幀的順序。這種先進行空間注意力,再進行時間注意力的方式,就是時空分離注意力。
這種時空分離注意力的UNet可以應用在可變序列長度上,這種時空分離注意力的方式有一個好處是可以對視頻和圖片生成進行聯合建模訓練。就是說可以在每個視頻的最后一幀后面添加隨機的多張圖片,然后通過掩碼的方式來將視頻以及各圖片進行隔離,從而讓視頻和圖片生成能夠聯合訓練起來。
但是這個機制其實比較弱,只能生成一些非常簡單的畫面。
近期有兩篇論文值得一提,一個是Diffusion over Diffusion,這篇論文的定位是關于生成長視頻的思考。Diffusion over Diffusion主要解決的問題是長視頻之間前后關聯的問題。之前的視頻基本都是自回歸的架構,生成得比較慢,因為它是串行的。
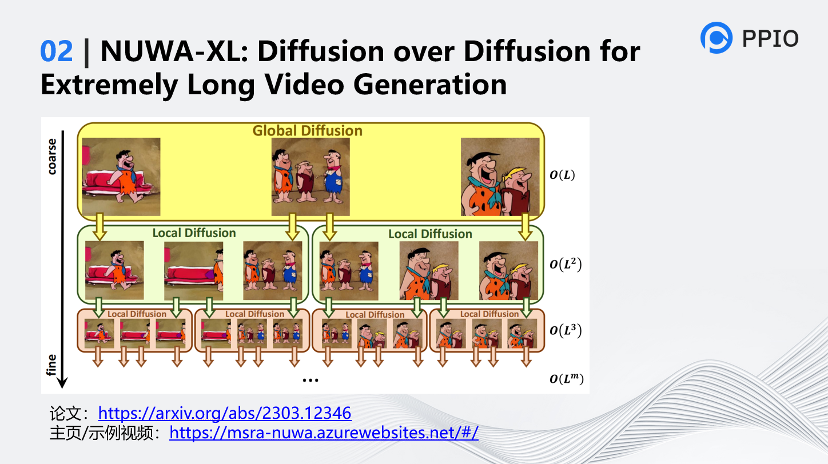
它的特點是什么?它為什么要Diffusion over Diffusion?因為它是一種分層結構的擴散模型,通過一層層擴散生成視頻。
Diffusion over Diffusion的視頻生成過程是一個“從粗到細”的視頻生成過程,先通過在全局擴散模型(Global Diffusion)中輸入文字來生成整個時間范圍內的關鍵幀,然后在局部擴散模型(Local Diffusion)中輸入文字和上一層Diffusion生成的兩張圖片,遞歸地生成填充附近幀之間的內容,最終生成長視頻。
這種分層結構的設計使模型能夠直接在長視頻上進行訓練,不僅消除了視頻生成領域中訓練短視頻與推理長視頻之間差距,也確保了視頻情節的連續性,同時也能極大的提升了生成效率。 ?
通過官網的演示資料可以看到,它下面寫的是一個prompt演講,根據prompt生成一個稍微長一點的視頻內容。在prompt換了之后,它又能生成一個稍微更長點的、更多樣化的(內容)。
下面這篇論文的名字叫Any-to-Any,這是一篇綜合圖像、語音、視頻和文本的多模態論文。其中Any to any的含義是,你能將上述模態數據進行任意組合的輸入,得到任意組合的輸出。例如輸入的時候可以根據圖片、文本、聲音,最后生成一個帶語音的視頻。
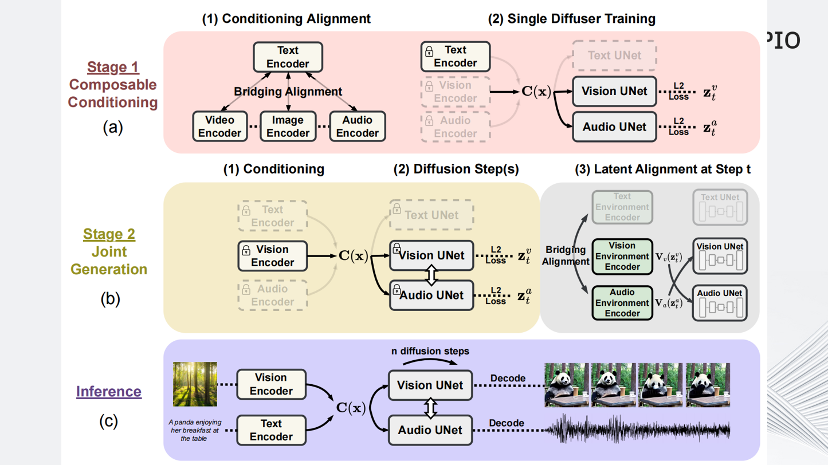
這篇論文提出了模型可組合擴散(Composable Diffusion,CoDi),這是第一個能夠同時處理和生成任意組合模態的模型。它具體是怎么做的?
首先這篇論文為了對齊不同模態之間的特征,設計了Bridging Alignment(特征橋接對齊)方式,采用CLIP為基準,凍結CLIP文本編碼器權重,再使用對比學習在文本-音頻、文本-視頻數據集上進行訓練,使得音頻、視頻編碼器提取的特征能對齊CLIP預訓練模型中文本編碼器提取的文本特征。
第二步,為每種模態(例如文本、圖像、視頻和音頻)訓練一個潛變擴散模型(Latent Diffusion Model,LDM)。這些模型可以獨立并行訓練,利用廣泛可用的特定模態訓練數據(即具有一個或多個模態作為輸入和一個模態作為輸出的數據)確保出色的單模態生成質量。
最后,通過為每個擴散器添加交叉注意力模塊和一個環境編碼器V來實現的,將不同LDM的潛變量投影到共享的潛空間。之后再固定LDM的參數,只訓練交叉注意力參數和V。由于不同模態的環境編碼器是對齊的,LDM可以通過插值表示的V與任何組合的共同生成模態進行交叉注意力。這使得CoDi能夠無縫地生成任何模態組合,而無需對所有可能的生成組合進行訓練。
這三個分別是文本、圖片、下雨的聲音。這三個結合起來,就生成了一個泰迪熊在雨中過街的畫面。網上有一些評論,說這篇論文真正運用的時候差距很大,因為多模態需要大量的數據支持才可能做好。它還是學術級,離跨越鴻溝還有很遠的距離。
-04-
未來音視頻創新機會在哪
我接下來的思考是,未來音視頻AIGC成熟且能大規模應用在什么時候?

這個圖摘自紅杉的報告。紅色部分屬于很不成熟的,黃色部分屬于正在發展的,綠色部分就是成熟的。在這個預測里可以看到,文本和code在2023年能夠做到很成熟,但是圖片可能要到25年才能做到非常可控、可產品化,3D和視頻預測要到2030年才能成熟。
不管是應用還是論文,基本上都是基于Diffusion的改良,甚至很多模型都是基于Diffusion模型的一種擴散,今天的很多更高級的視頻、3D的生成框架,也離不開擴散。如果某天視頻真的要參與化的時候,是不是需要有一種更原生的底層邏輯的突破、比擴散還高一個維度的突破才能做到?但是今天我們基于已有的技術,加上一些工程化的努力,我相信應該可以做很多東西了。
關于音視頻的應用,如果和行業數據相關,我認為用好開源,加上一些工程上的產品級創新,再結合大模型,把向量工程、提示工程做好,基本就能解決大量的需求了。
-05-
關于PPIO邊緣云
最后介紹一下我們的PPIO邊緣云。PPIO 于 2018年由 PPTV 創始人姚欣和我聯合創立,作為中國領先的獨立邊緣云服務提供商,PPIO在全國30多個省,超過1000多個縣市及區域,為客戶提供符合低時延、高帶寬、海量數據分布處理需求的邊緣云計算服務和解決方案。
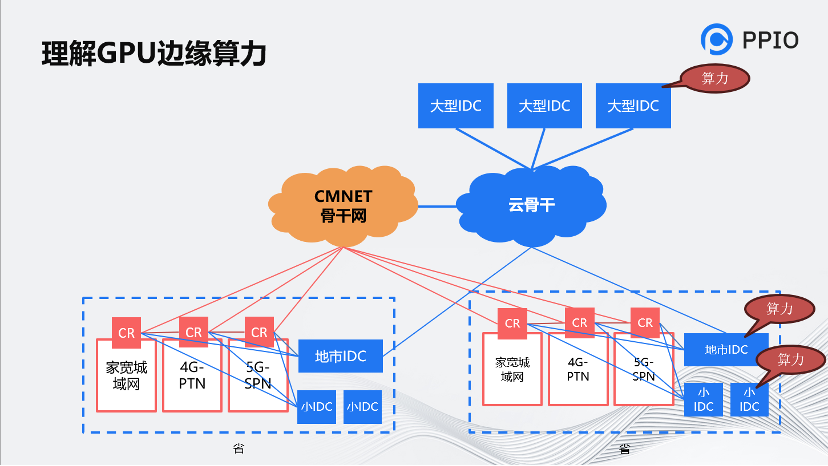
PPIO的核心是以算力為本。這個圖是運營商的骨干圖,能夠幫助理解邊緣帶寬。圖中拿移動來舉例,我們覆蓋的范圍并不是很大很多,而是相對分散的一些節點,但是這種節點的SOA也是可保證的。
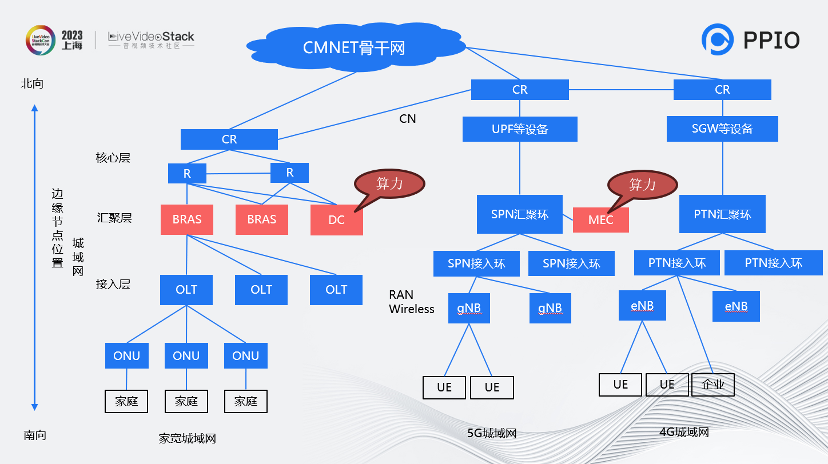
從城域網的角度看,備用節點覆蓋在BRAS這一層,甚至會放置在MEC。 把算力資源放下后,就能做一些邊緣的推理服務。我們可以提供基于裸金屬和GPU容器的的服務,同時也能提供上面調度的邏輯。另外我們還可以支持推理加速的框架,例如Oneflow、AITemplate、TensorRT等。
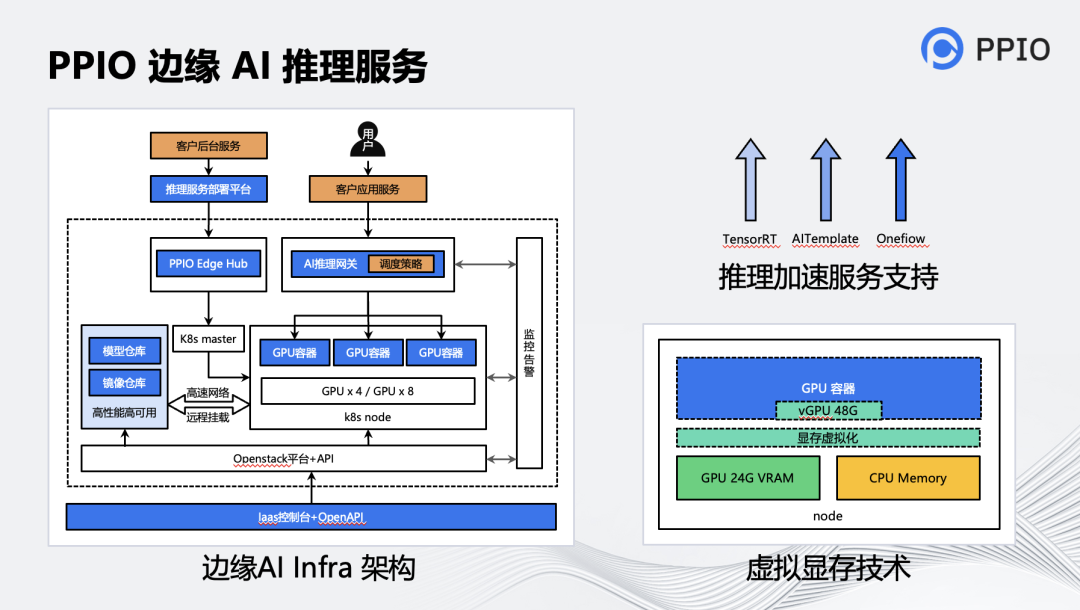
基于 PPIO 在邊緣算力上的優勢,我們構建了專門適用于 AI 推理場景的架構。它主要包含三個層面的服務:裸金屬,容器,推理網關。
? 裸金屬服務,主要適用于大模型的場景,例如:一個大語言模型的推理服務需要占用 4~10 張顯卡,甚至要多機聯合推理的情形。客戶可以直接通過 IaaS 控制臺或 OpenAPI 來申請、啟動、停止和釋放裸金屬機。
? 容器服務,主要適用于可以靈活調度的場景,一般這類模型相對較小,一個推理服務實例只需要 1 張左右顯卡,例如 StableDiffusion 的推理。容器服務實例由 PPIO k8s@Edge 系統管理,該系統保持與原生 k8s 兼容,可以滿足客戶按需彈性調度的需求。
? 推理網關服務,是上層用戶請求層的智能調度服務,它可以根據后端推理實例的負載情況,動態地將用戶的請求調度到最合適的實例上,并且它支持客戶設置個性化的調度策略。另外當部分節點或實例故障時,該網關也可以智能地將其剔除,避免用戶請求打到該實例上,對于已經調度到這些實例上的請求,網關將自動將這些請求重新轉發到其他健康實例上去處理,整個過程對于請求方完全無感。
此外,在服務客戶的過程中,我們發現有些時候顯卡在接受較大的用戶請求時,偶爾會出現顯存不足的情況。比如 在 3090 24G 上,剛好有一個模型要跑 30G 多一些怎么辦?這時候很容易想到,將一部分內存來“充當”那顯存使用,臨時性地將顯存的內容搬運到內存里,當這些顯存的內容需要被訪問時再搬回去,這樣可以讓上層的應用勉強能跑起來。為此我們基于 Nvidia 的 Unifed Memory 和 Cuda 劫持技術,構建了用戶態的虛擬 GPU,實現了這一功能。該項技術使得推理服務在處理用戶的較大請求過程中,顯存的問題得到了極大的緩解。但是該技術也會使得顯存和內存之間的 swap 操作變多,從而影響性能,因此在對性能有較高要求的場景,不建議設置太大的虛擬顯存。
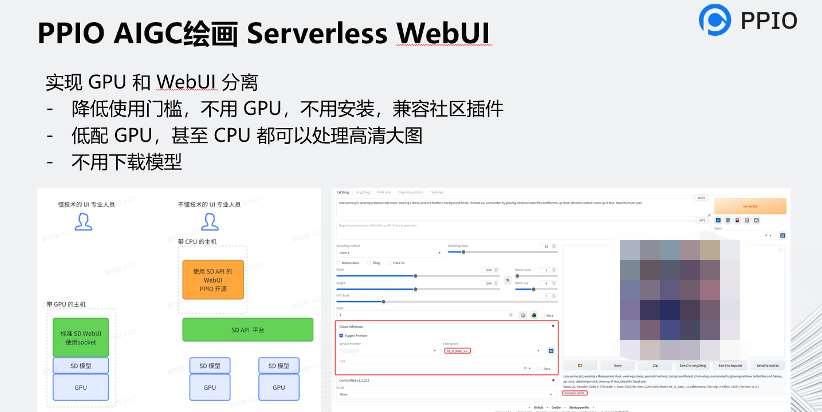
我們也有基于 Stable Diffusion WebUI 的一些應用,采用界面和算力分離的架構,不用 GPU,不用安裝 WebUI,入門門檻低,也容易整合到用戶自有的工作流中。用戶也不用下載和維護模型,一方面我們已經集成了很多模型了,另一方面用戶還可以添加自己的模型。
我們還提供了基于 Stable Diffusion 的 AI 圖片生成和圖片編輯的 API 平臺,基本上從工程階段已經做到了快、便宜,同樣也能夠支持各種模型,也能實現 文生圖,圖生圖,ControlNet,Upscaling,Inpainting,Outpainting,摳圖,和擦除等系列功能,可以滿足游戲素材生成,電商圖片的修改等場景。
另外,我們也針對一些場景實現了主體固定的解決方案,就是能生成一系列圖片,但保持主體不變、背景變換,特別適合當前流行的兒童插畫,小說配圖生成等場景。 最后,我最近經常也在思考,我們人類為什么有智能。再看看 AI 的高速發展,距離我們人類越來越近了,現在AI的原理越來越和我們的大腦近似,也是類似的矩陣、向量的計算,所以我頓時感覺人類的智慧沒有想象中那么偉大。
或者再過十年,計算機超越人類是完全有可能的。而我們作為音視頻行業從業者,需要積極擁抱新的技術創造更大的價值。
編輯:黃飛
?
















 工商網監
工商網監
評論