 電子發燒友App
電子發燒友App


電子發燒友網訊:最近聽到不少用戶詢問cpu是什么?cpu是什么意思?cpu其實是中央處理器的簡稱,cpu是計算機控制的核心。
什么是CPU
CPU是電腦系統的心臟,電腦特別是微型電腦的快速發展過程,實質上就是CPU從低級向高級、從簡單向復雜發展的過程。
一、CPU的概念
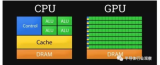
CPU(Central Processing Unit)又叫中央處理器,其主要功能是進行運算和邏輯運算,內部結構大概可以分為控制單元、算術邏輯單元和存儲單元等幾個部分。按照其處理信息的字長可以分為:八位微處理器、十六位微處理器、三十二位微處理器以及六十四位微處理器等等。
二、CPU主要的性能指標
主頻:
? ? ? ? 即CPU內部核心工作的時鐘頻率,單位一般是兆赫茲(MHz)。這是我們平時無論是使用還是購買計算機都最關心的一個參數,我們通常所說的133、166、450等就是指它。對于同種類的CPU,主頻越高,CPU的速度就越快,整機的性能就越高。
外頻和倍頻數:
? ? ? ? 外頻即CPU的外部時鐘頻率。外頻是由電腦主板提供的,CPU的主頻與外頻的關系是:CPU主頻=外頻×倍頻數。
前端總線(FSB)頻率
前端總線(FSB)頻率(即總線頻率)是直接影響CPU與內存直接數據交換速度。有一條公式可以計算,即數據帶寬=(總線頻率×數據位寬)/8,數據傳輸最大帶寬取決于所有同時傳輸的數據的寬度和傳輸頻率。比方,現在的支持64位的至強Nocona,前端總線是800MHz,按照公式,它的數據傳輸最大帶寬是6.4GB/秒。
外頻與前端總線(FSB)頻率的區別:前端總線的速度指的是數據傳輸的速度,外頻是CPU與主板之間同步運行的速度。也就是說,100MHz外頻特指數字脈沖信號在每秒鐘震蕩一億次;而100MHz前端總線指的是每秒鐘CPU可接受的數據傳輸量是100MHz×64bit÷8bit/Byte=800MB/s。
其實現在“HyperTransport”構架的出現,讓這種實際意義上的前端總線(FSB)頻率發生了變化。IA-32架構必須有三大重要的構件:內存控制器Hub (MCH),I/O控制器Hub和PCI Hub,像Intel很典型的芯片組Intel 7501.Intel7505芯片組,為雙至強處理器量身定做的,它們所包含的MCH為CPU提供了頻率為533MHz的前端總線,配合DDR內存,前端總線帶寬可達到4.3GB/秒。但隨著處理器性能不斷提高同時給系統架構帶來了很多問題。而“HyperTransport”構架不但解決了問題,而且更有效地提高了總線帶寬,比方AMD Opteron處理器,靈活的HyperTransport I/O總線體系結構讓它整合了內存控制器,使處理器不通過系統總線傳給芯片組而直接和內存交換數據。這樣的話,前端總線(FSB)頻率在AMD Opteron處理器就不知道從何談起了。
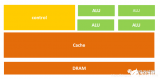
緩存
緩存大小也是CPU的重要指標之一,而且緩存的結構和大小對CPU速度的影響非常大,CPU內緩存的運行頻率極高,一般是和處理器同頻運作,工作效率遠遠大于系統內存和硬盤。實際工作時,CPU往往需要重復讀取同樣的數據塊,而緩存容量的增大,可以大幅度提升CPU內部讀取數據的命中率,而不用再到內存或者硬盤上尋找,以此提高系統性能。但是由于CPU芯片面積和成本的因素來考慮,緩存都很小。
L1 Cache(一級緩存)是CPU第一層高速緩存,分為數據緩存和指令緩存。內置的L1高速緩存的容量和結構對CPU的性能影響較大,不過高速緩沖存儲器均由靜態RAM組成,結構較復雜,在CPU管芯面積不能太大的情況下,L1級高速緩存的容量不可能做得太大。一般服務器CPU的L1緩存的容量通常在32-256KB。
L2 Cache(二級緩存)是CPU的第二層高速緩存,分內部和外部兩種芯片。內部的芯片二級緩存運行速度與主頻相同,而外部的二級緩存則只有主頻的一半。L2高速緩存容量也會影響CPU的性能,原則是越大越好,以前家庭用CPU容量最大的是512KB,現在筆記本電腦中也可以達到2M,而服務器和工作站上用CPU的L2高速緩存更高,可以達到8M以上。
L3 Cache(三級緩存),分為兩種,早期的是外置,現在的都是內置的。而它的實際作用即是,L3緩存的應用可以進一步降低內存延遲,同時提升大數據量計算時處理器的性能。降低內存延遲和提升大數據量計算能力對游戲都很有幫助。而在服務器領域增加L3緩存在性能方面仍然有顯著的提升。比方具有較大L3緩存的配置利用物理內存會更有效,故它比較慢的磁盤I/O子系統可以處理更多的數據請求。具有較大L3緩存的處理器提供更有效的文件系統緩存行為及較短消息和處理器隊列長度。
其實最早的L3緩存被應用在AMD發布的K6-III處理器上,當時的L3緩存受限于制造工藝,并沒有被集成進芯片內部,而是集成在主板上。在只能夠和系統總線頻率同步的L3緩存同主內存其實差不了多少。后來使用L3緩存的是英特爾為服務器市場所推出的Itanium處理器。接著就是P4EE和至強MP。Intel還打算推出一款9MB L3緩存的Itanium2處理器,和以后24MB L3緩存的雙核心Itanium2處理器。
但基本上L3緩存對處理器的性能提高顯得不是很重要,比方配備1MB L3緩存的Xeon MP處理器卻仍然不是Opteron的對手,由此可見前端總線的增加,要比緩存增加帶來更有效的性能提升。
CPU擴展指令集
CPU依靠指令來自計算和控制系統,每款CPU在設計時就規定了一系列與其硬件電路相配合的指令系統。指令的強弱也是CPU的重要指標,指令集是提高微處理器效率的最有效工具之一。
從現階段的主流體系結構講,指令集可分為復雜指令集和精簡指令集兩部分(指令集共有四個種類),而從具體運用看,如Intel的MMX(Multi Media Extended,此為AMD猜測的全稱,Intel并沒有說明詞源)、SSE、SSE2(Streaming-Single instruction multiple data-Extensions 2)、SSE3、SSE4系列和AMD的3DNow!等都是CPU的擴展指令集,分別增強了CPU的多媒體、圖形圖象和Internet等的處理能力。
通常會把CPU的擴展指令集稱為”CPU的指令集”。SSE3指令集也是目前規模最小的指令集,此前MMX包含有57條命令,SSE包含有50條命令,SSE2包含有144條命令,SSE3包含有13條命令。
CPU內核和I/O工作電壓
從586CPU開始,CPU的工作電壓分為內核電壓和I/O電壓兩種,通常CPU的核心電壓小于等于I/O電壓。其中內核電壓的大小是根據CPU的生產工藝而定,一般制作工藝越小,內核工作電壓越低;I/O電壓一般都在1.6~5V。低電壓能解決耗電過大和發熱過高的問題。
內部緩存:
? ? ? ?采用速度極快的SRAM制作,用于暫時存儲CPU運算時的最近的部分指令和數據,存取速度與CPU主頻相同,內部緩存的容量一般以KB為單位。當它全速工作時,其容量越大,使用頻率最高的數據和結果就越容易盡快進入CPU進行運算,CPU工作時與存取速度較慢的外部緩存和內存間交換數據的次數越少,相對電腦的運算速度可以提高。
地址總線寬度:
? ? ? ? 地址總線寬度決定了CPU可以訪問的物理地址空間,簡單地說就是CPU到底能夠使用多大容量的內存。
多媒體擴展指令集(MMX)技術:MMX是Intel公司為增強Pentium CPU 在音像、圖形和通信應用方面而采取的新技術。這一技術為CPU增加了全新的57條MMX指令,這些加了MMX指令的 CPU比普通CPU在運行含有MMX指令的程序時,處理多媒體的能力上提高了60%左右。即使不使用MMX指令的程序,也能獲得15%左右的性能提升。
微處理器在多方面改變了我們的生活,現在認為理所當然的事,在以前卻是難以想象的。六十年代計算機大得可充滿整個房間,只有很少的人能使用它們。六十年代中期集成電路的發明使電路的小型化得以在一塊單一的硅片上實現,為微處理器的發展奠定了基礎。在可預見的未來,CPU的處理能力將繼續保持高速增長,小型化、集成化永遠是發展趨勢,同時會形成不同層次的產品,也包括專用處理器。
CPU的功能
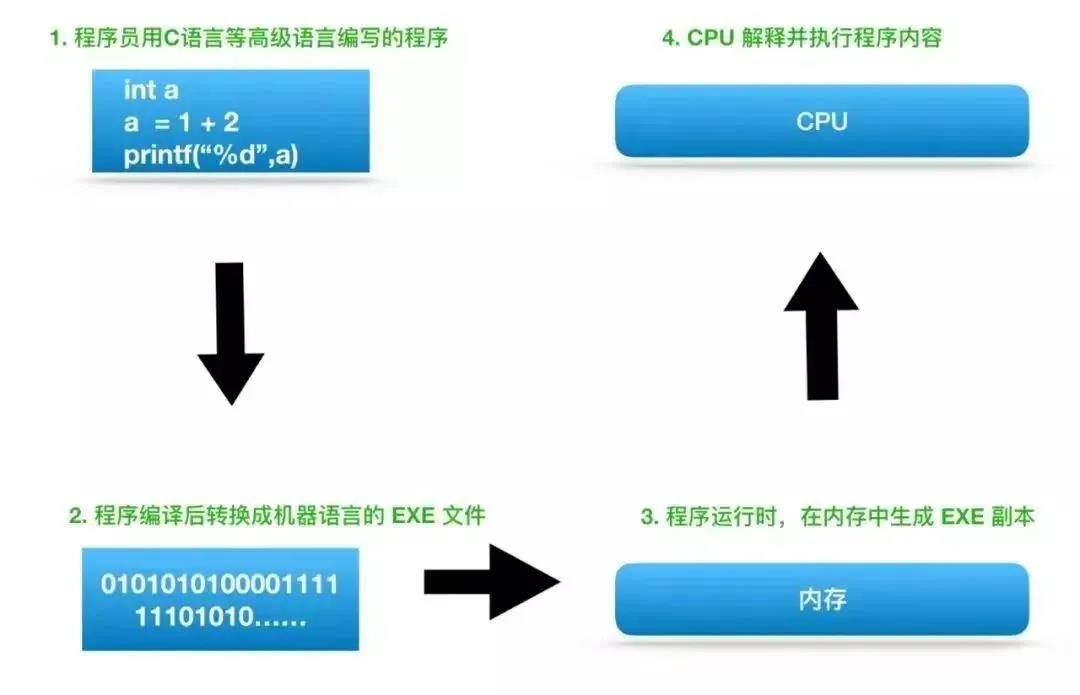
計算機求解問題是通過執行程序來實現的。程序是由指令構成的序列,執行程序就是按指令序列逐條執行指令。一旦把程序裝入主存儲器(簡稱主存)中,就可以由CPU自動地完成從主存取指令和執行指令的任務。
CPU具有以下4個方面的基本功能:
1. 指令順序控制
這是指控制程序中指令的執行順序。程序中的各指令之間是有嚴格順序的,必須嚴格按程序規定的順序執行,才能保證計算機工作的正確性。
2. 操作控制
一條指令的功能往往是由計算機中的部件執行一序列的操作來實現的。CPU要根據指令的功能,產生相應的操作控制信號,發給相應的部件,從而控制這些部件按指令的要求進行動作。
3. 時間控制
時間控制就是對各種操作實施時間上的定時。在一條指令的執行過程中,在什么時間做什么操作均應受到嚴格的控制。只有這樣,計算機才能有條不紊地自動工作。
4. 數據加工
即對數據進行算術運算和邏輯運算,或進行其他的信息處理。
工作原理
? ? CPU從存儲器或高速緩沖存儲器中取出指令,放入指令寄存器,并對指令譯碼。它把指令分解成一系列的微操作,然后發出各種控制命令,執行微操作系列,從而完成一條指令的執行。
指令是計算機規定執行操作的類型和操作數的基本命令。指令是由一個字節或者多個字節組成,其中包括操作碼字段、一個或多個有關操作數地址的字段以及一些表征機器狀態的狀態字以及特征碼。有的指令中也直接包含操作數本身。
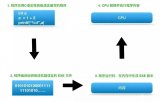
提取
第一階段,提取,從存儲器或高速緩沖存儲器中檢索指令(為數值或一系列數值)。由程序計數器(Program Counter)指定存儲器的位置,程序計數器保存供識別目前程序位置的數值。換言之,程序計數器記錄了CPU在目前程序里的蹤跡。
提取指令之后,程序計數器根據指令長度增加存儲器單元。指令的提取必須常常從相對較慢的存儲器尋找,因此導致CPU等候指令的送入。這個問題主要被論及在現代處理器的快取和管線化架構。
解碼
CPU根據存儲器提取到的指令來決定其執行行為。在解碼階段,指令被拆解為有意義的片斷。根據CPU的指令集架構(ISA)定義將數值解譯為指令。一部分的指令數值為運算碼(Opcode),其指示要進行哪些運算。其它的數值通常供給指令必要的信息,諸如一個加法(Addition)運算的運算目標。這樣的運算目標也許提供一個常數值(即立即值),或是一個空間的定址值:暫存器或存儲器位址,以定址模式決定。在舊的設計中,CPU里的指令解碼部分是無法改變的硬件設備。不過在眾多抽象且復雜的CPU和指令集架構中,一個微程序時常用來幫助轉換指令為各種形態的訊號。這些微程序在已成品的CPU中往往可以重寫,方便變更解碼指令。
執行
在提取和解碼階段之后,接著進入執行階段。該階段中,連接到各種能夠進行所需運算的CPU部件。
例如,要求一個加法運算,算術邏輯單元(ALU,Arithmetic Logic Unit)將會連接到一組輸入和一組輸出。輸入提供了要相加的數值,而輸出將含有總和的結果。ALU內含電路系統,易于輸出端完成簡單的普通運算和邏輯運算(比如加法和位元運算)。如果加法運算產生一個對該CPU處理而言過大的結果,在標志暫存器里,運算溢出(Arithmetic Overflow)標志可能會被設置。
寫回
最終階段,寫回,以一定格式將執行階段的結果簡單的寫回。運算結果經常被寫進CPU內部的暫存器,以供隨后指令快速存取。在其它案例中,運算結果可能寫進速度較慢,但容量較大且較便宜的主記憶體中。某些類型的指令會操作程序計數器,而不直接產生結果。這些一般稱作“跳轉”(Jumps),并在程式中帶來循環行為、條件性執行(透過條件跳轉)和函式。許多指令會改變標志暫存器的狀態位元。這些標志可用來影響程式行為,緣由于它們時常顯出各種運算結果。例如,以一個“比較”指令判斷兩個值大小,根據比較結果在標志暫存器上設置一個數值。這個標志可藉由隨后跳轉指令來決定程式動向。在執行指令并寫回結果之后,程序計數器值會遞增,反覆整個過程,下一個指令周期正常的提取下一個順序指令。如果完成的是跳轉指令,程序計數器將會修改成跳轉到的指令位址,且程序繼續正常執行。許多復雜的CPU可以一次提取多個指令、解碼,并且同時執行。這個部分一般涉及“經典RISC管線”,那些實際上是在眾多使用簡單CPU的電子裝置中快速普及(常稱為微控制(Microcontrollers))。
基本結構
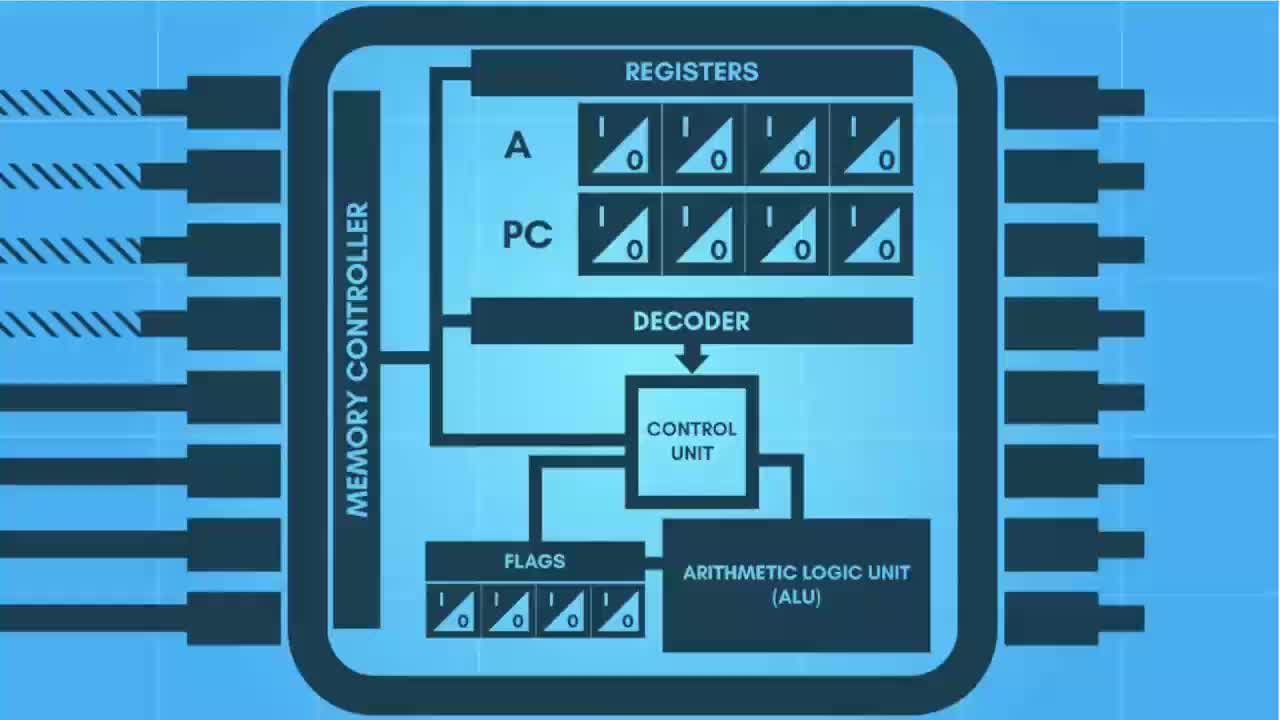
? ? ? ? CPU包括運算邏輯部件、寄存器部件和控制部件等。
運算邏輯部件
運算邏輯部件,可以執行定點或浮點算術運算操作、移位操作以及邏輯操作,也可執行地址運算和轉換。
寄存器部件
寄存器部件,包括通用寄存器、專用寄存器和控制寄存器。
32位CPU的寄存器
? ? ? ? 通用寄存器又可分定點數和浮點數兩類,它們用來保存指令中的寄存器操作數和操作結果。
通用寄存器是中央處理器的重要組成部分,大多數指令都要訪問到通用寄存器。通用寄存器的寬度決定計算機內部的數據通路寬度,其端口數目往往可影響內部操作的并行性。
專用寄存器是為了執行一些特殊操作所需用的寄存器。
控制寄存器通常用來指示機器執行的狀態,或者保持某些指針,有處理狀態寄存器、地址轉換目錄的基地址寄存器、特權狀態寄存器、條件碼寄存器、處理異常事故寄存器以及檢錯寄存器等。
有的時候,中央處理器中還有一些緩存,用來暫時存放一些數據指令,緩存越大,說明CPU的運算速度越快,目前市場上的中高端中央處理器都有2M左右的二級緩存,高端中央處理器有4M左右的二級緩存。
控制部件
控制部件,主要負責對指令譯碼,并且發出為完成每條指令所要執行的各個操作的控制信號。
其結構有兩種:一種是以微存儲為核心的微程序控制方式;一種是以邏輯硬布線結構為主的控制方式。
微存儲中保持微碼,每一個微碼對應于一個最基本的微操作,又稱微指令;各條指令是由不同序列的微碼組成,這種微碼序列構成微程序。中央處理器在對指令譯碼以后,即發出一定時序的控制信號,按給定序列的順序以微周期為節拍執行由這些微碼確定的若干個微操作,即可完成某條指令的執行。
簡單指令是由(3~5)個微操作組成,復雜指令則要由幾十個微操作甚至幾百個微操作組成。
邏輯硬布線控制器則完全是由隨機邏輯組成。指令譯碼后,控制器通過不同的邏輯門的組合,發出不同序列的控制時序信號,直接去執行一條指令中的各個操作。
技術架構制造工藝
制造工藝的微米是指IC內電路與電路之間的距離。制造工藝的趨勢是向密集度愈高的方向發展。密度愈高的IC電路設計,意味著在同樣大小面積的IC中,可以擁有密度更高、功能更復雜的電路設計。現在主要的180nm、130nm、90nm、65nm、45納米。intel已經于2010年發布32納米的制造工藝的酷睿i3/酷睿i5/酷睿i7系列。并且已有發布22nm與15nm產品的計劃。而AMD則表示、自己的產品將會直接跳過32nm工藝(2010年第三季度生產少許32nm產品、如Orochi、Llano)于2011年中期初發布28nm的產品(APU)
指令集
⑴CISC指令集
CISC指令集,也稱為復雜指令集,英文名是CISC,(Complex Instruction Set Computer的縮寫)。在CISC微處理器中,程序的各條指令是按順序串行執行的,每條指令中的各個操作也是按順序串行執行的。順序執行的優點是控制簡單,但計算機各部分的利用率不高,執行速度慢。其實它是英特爾生產的x86系列(也就是IA-32架構)CPU及其兼容CPU,如AMD、VIA的。即使是現在新起的X86-64(也說成AMD64)都是屬于CISC的范疇。
要知道什么是指令集還要從當今的X86架構的CPU說起。X86指令集是Intel為其第一塊16位CPU(i8086)專門開發的,IBM1981年推出的世界第一臺PC機中的CPU-i8088(i8086簡化版)使用的也是X86指令,同時電腦中為提高浮點數據處理能力而增加了X87芯片,以后就將X86指令集和X87指令集統稱為X86指令集。
雖然隨著CPU技術的不斷發展,Intel陸續研制出更新型的i80386.i80486直到過去的PII至強、PIII至強、Pentium 3,Pentium 4系列,最后到今天的酷睿2系列、至強(不包括至強Nocona),但為了保證電腦能繼續運行以往開發的各類應用程序以保護和繼承豐富的軟件資源,所以Intel公司所生產的所有CPU仍然繼續使用X86指令集,所以它的CPU仍屬于X86系列。由于Intel X86系列及其兼容CPU(如AMD Athlon MP、)都使用X86指令集,所以就形成了今天龐大的X86系列及兼容CPU陣容。x86CPU目前主要有intel的服務器CPU和AMD的服務器CPU兩類。
⑵RISC指令集
RISC是英文“Reduced Instruction Set Computing ”的縮寫,中文意思是“精簡指令集”。它是在CISC指令系統基礎上發展起來的,有人對CISC機進行測試表明,各種指令的使用頻度相當懸殊,最常使用的是一些比較簡單的指令,它們僅占指令總數的20%,但在程序中出現的頻度卻占80%。復雜的指令系統必然增加微處理器的復雜性,使處理器的研制時間長,成本高。并且復雜指令需要復雜的操作,必然會降低計算機的速度。基于上述原因,20世紀80年代RISC型CPU誕生了,相對于CISC型CPU,RISC型CPU不僅精簡了指令系統,還采用了一種叫做“超標量和超流水線結構”,大大增加了并行處理能力。RISC指令集是高性能CPU的發展方向。它與傳統的CISC(復雜指令集)相對。相比而言,RISC的指令格式統一,種類比較少,尋址方式也比復雜指令集少。當然處理速度就提高很多了。目前在中高檔服務器中普遍采用這一指令系統的CPU,特別是高檔服務器全都采用RISC指令系統的CPU。RISC指令系統更加適合高檔服務器的操作系統UNIX,現在Linux也屬于類似UNIX的操作系統。RISC型CPU與Intel和AMD的CPU在軟件和硬件上都不兼容。
目前,在中高檔服務器中采用RISC指令的CPU主要有以下幾類:PowerPC處理器、SPARC處理器、PA-RISC處理器、MIPS處理器、Alpha處理器。
⑶IA-64
EPIC(Explicitly Parallel Instruction Computers,精確并行指令計算機)是否是RISC和CISC體系的繼承者的爭論已經有很多,單以EPIC體系來說,它更像Intel的處理器邁向RISC體系的重要步驟。從理論上說,EPIC體系設計的CPU,在相同的主機配置下,處理Windows的應用軟件比基于Unix下的應用軟件要好得多。
Intel采用EPIC技術的服務器CPU是安騰Itanium(開發代號即Merced)。它是64位處理器,也是IA-64系列中的第一款。微軟也已開發了代號為Win64的操作系統,在軟件上加以支持。在Intel采用了X86指令集之后,它又轉而尋求更先進的64-bit微處理器,Intel這樣做的原因是,它們想擺脫容量巨大的x86架構,從而引入精力充沛而又功能強大的指令集,于是采用EPIC指令集的IA-64架構便誕生了。IA-64 在很多方面來說,都比x86有了長足的進步。突破了傳統IA32架構的許多限制,在數據的處理能力,系統的穩定性、安全性、可用性、可觀理性等方面獲得了突破性的提高。
IA-64微處理器最大的缺陷是它們缺乏與x86的兼容,而Intel為了IA-64處理器能夠更好地運行兩個朝代的軟件,它在IA-64處理器上(Itanium、Itanium2 ……)引入了x86-to-IA-64的解碼器,這樣就能夠把x86指令翻譯為IA-64指令。這個解碼器并不是最有效率的解碼器,也不是運行x86代碼的最好途徑(最好的途徑是直接在x86處理器上運行x86代碼),因此Itanium 和Itanium2在運行x86應用程序時候的性能非常糟糕。這也成為X86-64產生的根本原因。
超流水線與超標量
在解釋超流水線與超標量前,先了解流水線(Pipeline)。流水線是Intel首次在486芯片中開始使用的。流水線的工作方式就象工業生產上的裝配流水線。在CPU中由5-6個不同功能的電路單元組成一條指令處理流水線,然后將一條X86指令分成5-6步后再由這些電路單元分別執行,這樣就能實現在一個CPU時鐘周期完成一條指令,因此提高CPU的運算速度。經典奔騰每條整數流水線都分為四級流水,即指令預取、譯碼、執行、寫回結果,浮點流水又分為八級流水。超標量是通過內置多條流水線來同時執行多個處理器,其實質是以空間換取時間。而超流水線是通過細化流水、提高主頻,使得在一個機器周期內完成一個甚至多個操作,其實質是以時間換取空間。例如Pentium 4的流水線就長達20級。將流水線設計的步(級)越長,其完成一條指令的速度越快,因此才能適應工作主頻更高的CPU。但是流水線過長也帶來了一定副作用,很可能會出現主頻較高的CPU實際運算速度較低的現象,Intel的奔騰4就出現了這種情況,雖然它的主頻可以高達1.4G以上,但其運算性能卻遠遠比不上AMD 1.2G的速龍甚至奔騰III。
封裝形式
CPU封裝是采用特定的材料將CPU芯片或CPU模塊固化在其中以防損壞的保護措施,一般必須在封裝后CPU才能交付用戶使用。CPU的封裝方式取決于CPU安裝形式和器件集成設計,從大的分類來看通常采用Socket插座進行安裝的CPU使用PGA(柵格陣列)方式封裝,而采用Slot x槽安裝的CPU則全部采用SEC(單邊接插盒)的形式封裝。現在還有PLGA(Plastic Land Grid Array)、OLGA(Organic Land Grid Array)等封裝技術。由于市場競爭日益激烈,目前CPU封裝技術的發展方向以節約成本為主。
多線程
同時多線程Simultaneous Multithreading,簡稱SMT。SMT可通過復制處理器上的結構狀態,讓同一個處理器上的多個線程同步執行并共享處理器的執行資源,可最大限度地實現寬發射、亂序的超標量處理,提高處理器運算部件的利用率,緩和由于數據相關或Cache未命中帶來的訪問內存延時。當沒有多個線程可用時,SMT處理器幾乎和傳統的寬發射超標量處理器一樣。SMT最具吸引力的是只需小規模改變處理器核心的設計,幾乎不用增加額外的成本就可以顯著地提升效能。多線程技術則可以為高速的運算核心準備更多的待處理數據,減少運算核心的閑置時間。這對于桌面低端系統來說無疑十分具有吸引力。Intel從3.06GHz Pentium 4開始,所有處理器都將支持SMT技術。
多核心
多核心,也指單芯片多處理器(Chip Multiprocessors,簡稱CMP)。CMP是由美國斯坦福大學提出的,其思想是將大規模并行處理器中的SMP(對稱多處理器)集成到同一芯片內,各個處理器并行執行不同的進程。與CMP比較,SMT處理器結構的靈活性比較突出。但是,當半導體工藝進入0.18微米以后,線延時已經超過了門延遲,要求微處理器的設計通過劃分許多規模更小、局部性更好的基本單元結構來進行。相比之下,由于CMP結構已經被劃分成多個處理器核來設計,每個核都比較簡單,有利于優化設計,因此更有發展前途。目前,IBM 的Power 4芯片和Sun的MAJC5200芯片都采用了CMP結構。多核處理器可以在處理器內部共享緩存,提高緩存利用率,同時簡化多處理器系統設計的復雜度。但這并不是說明,核心越多,性能越高,比如說16核的CPU就沒有8核的CPU運算速度快,因為核心太多,而不能合理進行分配,所以導致運算速度減慢。在買電腦時請酌情選擇。2005年下半年,Intel和AMD的新型處理器也將融入CMP結構。新安騰處理器開發代碼為Montecito,采用雙核心設計,擁有最少18MB片內緩存,采取90nm工藝制造。它的每個單獨的核心都擁有獨立的L1,L2和L3 cache,包含大約10億支晶體管。
SMP
SMP(Symmetric Multi-Processing),對稱多處理結構的簡稱,是指在一個計算機上匯集了一組處理器(多CPU),各CPU之間共享內存子系統以及總線結構。在這種技術的支持下,一個服務器系統可以同時運行多個處理器,并共享內存和其他的主機資源。像雙至強,也就是所說的二路,這是在對稱處理器系統中最常見的一種(至強MP可以支持到四路,AMD Opteron可以支持1-8路)。也有少數是16路的。但是一般來講,SMP結構的機器可擴展性較差,很難做到100個以上多處理器,常規的一般是8個到16個,不過這對于多數的用戶來說已經夠用了。在高性能服務器和工作站級主板架構中最為常見,像UNIX服務器可支持最多256個CPU的系統。
構建一套SMP系統的必要條件是:支持SMP的硬件包括主板和CPU;支持SMP的系統平臺,再就是支持SMP的應用軟件。為了能夠使得SMP系統發揮高效的性能,操作系統必須支持SMP系統,如WINNT、LINUX、以及UNIX等等32位操作系統。即能夠進行多任務和多線程處理。多任務是指操作系統能夠在同一時間讓不同的CPU完成不同的任務;多線程是指操作系統能夠使得不同的CPU并行的完成同一個任務。
要組建SMP系統,對所選的CPU有很高的要求,首先、CPU內部必須內置APIC(Advanced Programmable Interrupt Controllers)單元。Intel 多處理規范的核心就是高級可編程中斷控制器(Advanced Programmable Interrupt Controllers–APICs)的使用;再次,相同的產品型號,同樣類型的CPU核心,完全相同的運行頻率;最后,盡可能保持相同的產品序列編號,因為兩個生產批次的CPU作為雙處理器運行的時候,有可能會發生一顆CPU負擔過高,而另一顆負擔很少的情況,無法發揮最大性能,更糟糕的是可能導致死機。
NUMA技術
NUMA即非一致訪問分布共享存儲技術,它是由若干通過高速專用網絡連接起來的獨立節點構成的系統,各個節點可以是單個的CPU或是SMP系統。在NUMA中,Cache 的一致性有多種解決方案,一般采用硬件技術實現對cache的一致性維護,通常需要操作系統針對NUMA訪存不一致的特性(本地內存和遠端內存訪存延遲和帶寬的不同)進行特殊優化以提高效率,或采用特殊軟件編程方法提高效率。NUMA系統的例子。這里有3個SMP模塊用高速專用網絡聯起來,組成一個節點,每個節點可以有12個CPU。像Sequent的系統最多可以達到64個CPU甚至256個CPU。顯然,這是在SMP的基礎上,再用NUMA的技術加以擴展,是這兩種技術的結合。
亂序執行技術
亂序執行(out-of-orderexecution),是指CPU允許將多條指令不按程序規定的順序分開發送給各相應電路單元處理的技術。這樣將根據個電路單元的狀態和各指令能否提前執行的具體情況分析后,將能提前執行的指令立即發送給相應電路單元執行,在這期間不按規定順序執行指令,然后由重新排列單元將各執行單元結果按指令順序重新排列。采用亂序執行技術的目的是為了使CPU內部電路滿負荷運轉并相應提高了CPU的運行程序的速度。
分枝技術
(branch)指令進行運算時需要等待結果,一般無條件分枝只需要按指令順序執行,而條件分枝必須根據處理后的結果,再決定是否按原先順序進行。
CPU內部的內存控制器
許多應用程序擁有更為復雜的讀取模式(幾乎是隨機地,特別是當cache hit不可預測的時候),并且沒有有效地利用帶寬。典型的這類應用程序就是業務處理軟件,即使擁有如亂序執行(out of order execution)這樣的CPU特性,也會受內存延遲的限制。這樣CPU必須得等到運算所需數據被除數裝載完成才能執行指令(無論這些數據來自CPU cache還是主內存系統)。當前低段系統的內存延遲大約是120-150ns,而CPU速度則達到了3GHz以上,一次單獨的內存請求可能會浪費200-300次CPU循環。即使在緩存命中率(cache hit rate)達到99%的情況下,CPU也可能會花50%的時間來等待內存請求的結束-比如因為內存延遲的緣故。
在處理器內部整合內存控制器,使得北橋芯片將變得不那么重要,改變了處理器訪問主存的方式,有助于提高帶寬、降低內存延時和提升處理器性制造工藝:Intel的I5可以達到32納米,在將來的CPU制造工藝可以達到22納米。



















 工商網監
工商網監
評論