 電子發(fā)燒友App
電子發(fā)燒友App


蜂巢式網(wǎng)絡(luò)服務(wù)供應(yīng)商對降低營運成本的需求愈來愈迫切,因此現(xiàn)場可編程門陣列(FPGA)業(yè)者推出整合嵌入式處理器的SoC FPGA方案,并導(dǎo)入效能更高的數(shù)字預(yù)失真(DPD)演算法,協(xié)助網(wǎng)絡(luò)設(shè)備制造商以更低功耗及成本,打造更高生產(chǎn)力的產(chǎn)品。
蜂巢式網(wǎng)絡(luò)業(yè)者設(shè)法透過全新傳輸界面、傳輸頻率、更高頻寬以及增加天線的數(shù)量和更多無線基地臺提升網(wǎng)絡(luò)密度,因此須要大幅降低設(shè)備的成本。另外,這些業(yè)者為降低營運成本,也需要更高運作效率和網(wǎng)絡(luò)整合度的設(shè)備。無線基礎(chǔ)設(shè)備制造商為提供可以符合不同要求的設(shè)備,皆在尋求更高整合度、更佳效能和靈活度高的解決方案,并且同時降低功耗和成本。
整合度是降低整體設(shè)備成本的關(guān)鍵,然而這必須依賴可提升功率放大器效率的高階數(shù)字演算法來降低各項運作成本,其中一項最常用的演算法是數(shù)字預(yù)失真 (DPD)。由于設(shè)備的配置愈來愈復(fù)雜,因此提升設(shè)備運作效率是一項很大的挑戰(zhàn)。藉由先進長程演進計劃(LTE-Advanced)傳輸技術(shù),無線傳輸頻寬可達(dá)到100MHz,如果廠商試圖用連續(xù)頻譜配置結(jié)合多種傳輸界面,頻寬甚至可以更高。主動天線陣列(AAA)和支援多重輸入/輸出(MIMO)技術(shù)的遠(yuǎn)端無線單元(RRU)所需的演算法對頻寬的要求愈來愈高。本文將探討業(yè)界完全可編程系統(tǒng)單芯片(All Programmable SoC)元件如何為目前和未來的數(shù)字預(yù)失真系統(tǒng)提升效能增益,同時也可為設(shè)備廠商提供充裕的可編程能力、低成本和低功耗,并加快產(chǎn)品上市時程。
建置蜂巢式無線網(wǎng)絡(luò)
業(yè)界完全可編程SoC元件結(jié)合高效能可編程邏輯(PL)架構(gòu),其中包含序列式收發(fā)器(SERDES)和整合硬件處理子系統(tǒng)(PS)的數(shù)字訊號處理器 (DSP)模塊。這個硬件處理子系統(tǒng)內(nèi)含一個雙核心安謀國際(ARM)Cortex-A9處理器、浮點運算單元(FPU)和NEON多媒體加速器及一系列豐富的周邊功能,包括通用異步收發(fā)器(UART)、串列周邊界面(SPI)、內(nèi)部整合電路(I2C)、以太網(wǎng)絡(luò)(Ethernet)和記憶體控制器等完整無線傳輸所需的周邊功能。有別于外部通用處理器或DSP,可編程邏輯和硬件處理子系統(tǒng)間的界面有大量連結(jié),因此其頻寬可以非常高;但如要用獨立式解決方案處理這些連結(jié),卻不可行。此外,完全可編程SoC元件還包含硬件和軟件陣列,因此可在單一芯片內(nèi)建置遠(yuǎn)端無線單元所需的功能,如圖1所示。

圖1 在這個典型的無線架構(gòu)中,所有數(shù)字功能可整合在單一元件中。
可編程邏輯中豐富的DSP資源可用于建置數(shù)字上行轉(zhuǎn)換(DUC)、數(shù)字下行轉(zhuǎn)換(DDC)、峰波因數(shù)抑制(CFR)與數(shù)字預(yù)失真(DPD)等數(shù)字訊號處理功能。此外,SERDES可支援9.8bit/s的通用型公共射頻界面(CPRI)和12.5bit/s JESD204B,分別用于連接基頻和資料轉(zhuǎn)換器。
硬件處理子系統(tǒng)同時支援對稱式多重處理技術(shù)(SMP)和非對稱式多重處理技術(shù) (AMP)。在這個案例中預(yù)定會采用非對稱式多重處理模式,因為其中一顆ARM Cortex-A9處理器被用于建置基板層級的控制功能,例如訊息終止、排程、設(shè)定等級以及警示執(zhí)行(裸機或更有可能是如Linux等作業(yè)系統(tǒng))。而另一顆ARM Cortex-A9處理器則用以建置部分?jǐn)?shù)字預(yù)失真演算法,因為數(shù)字預(yù)失真演算法并不保證整體都是硬件的解決方案。
數(shù)字預(yù)失真可藉由擴大其線性范圍提升功率放大器效率;當(dāng)驅(qū)動放大器進一步增加輸出功率時,即可提升運作效率,而靜態(tài)功耗會相對維持正常。數(shù)字預(yù)失真為擴充其線性范圍,會使用放大器中的類比反饋路徑和大量數(shù)字處理功能計算放大器的逆向非線性系數(shù)。然后利用這些系數(shù)預(yù)先校正與驅(qū)動功率放大器的傳輸訊號,最終可增加放大器的線性范圍。
數(shù)字預(yù)失真是一個封閉回路系統(tǒng),其會擷取先前的傳輸訊號來決定放大器與這些傳輸訊號的傳輸方法。數(shù)字預(yù)失真的第一個任務(wù)是要讓放大器與先前的傳輸訊號達(dá)成一致,這個過程會在一個校準(zhǔn)模塊中進行。在執(zhí)行任何演算法運算前,系統(tǒng)會用記憶體來校準(zhǔn)資料;資料一旦妥善校準(zhǔn)后即可運用自動相關(guān)矩陣運算(AMC)和系數(shù)運算(CC)演算法,建立代表功率放大器逆向非線性系數(shù)的最近值。一旦產(chǎn)出系數(shù)后,資料路徑前置失真器即運用資料預(yù)校準(zhǔn)被傳輸?shù)焦β史糯笃鞯挠嵦枴?/p>
加速估計數(shù)字預(yù)失真系數(shù)
當(dāng)然,這些功能可以透過許多不同的方法建立。有些比較適合用軟件的方法,而有些則適用硬件,同時也有是軟硬件皆適用;然而,最終還是要以所需的效能決定建置的方法。采用完全可編程SoC元件可讓系統(tǒng)設(shè)計人員自由支配硬件和軟件的最適度使用情況。就數(shù)字預(yù)失真的情況而言,由于需要非常高的采樣率,因此內(nèi)含高速過濾功能的資料路徑預(yù)失真器通常會建置在可編程邏輯中,而產(chǎn)生數(shù)字預(yù)失真系數(shù)的校準(zhǔn)和估算引擎則可于硬件處理子系統(tǒng)中的ARM Cortex-A9處理器中執(zhí)行。
為決定什么須要采用硬件或軟件建置方法,首先必須設(shè)定哪些部分需要軟件。圖3展示數(shù)字預(yù)失真演算法中設(shè)定需要軟件的部分,以期達(dá)到圖2所示的三種功能。根據(jù)圖3設(shè)定,不難理解數(shù)字預(yù)失真演算法有97%的時間用在執(zhí)行自動相關(guān)矩陣運算,所以很自然地加速這項過程成為首要任務(wù)。
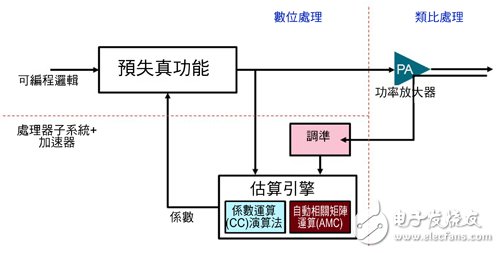
圖2 細(xì)分成不同功能區(qū)間的數(shù)字預(yù)失真系統(tǒng)
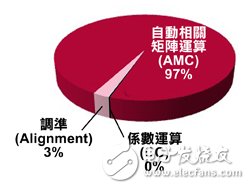
圖3 數(shù)字預(yù)失真處理當(dāng)中的指定軟件運算作業(yè)之軟件設(shè)定
ARM Cortex-A9處理器藉由豐富的運算資源可執(zhí)行更多功能,而這些資源有助提升效能。舉例而言,在硬件處理子系統(tǒng)中,每個ARM Cortex-A9處理器都內(nèi)含一個浮點運算單元和一個NEON多媒體加速器。NEON單元是一個128位元的單一指令多重資料(SIMD)向量協(xié)同處理器,可同時執(zhí)行兩個32×32b乘法指令;由于NEON單元皆用于乘法累積(MAC)運算,因此非常符合自動相關(guān)矩陣運算功能所需。透過NEON模組可運用軟件Intrinsics,這可以在系統(tǒng)組裝時免除編寫低階程式的需求。因此,運用硬件處理子系統(tǒng)中更多的功能,可以比Microblaze等軟件處理器或外接式DSP處理器大幅提升效能。
為提升數(shù)字預(yù)失真效能,設(shè)計人員須進一步利用可編程邏輯將這些功能移到硬件上。然而,由于軟件是以C/C++編寫,工程師需要一些時間將C/C++語言轉(zhuǎn)換成可在可編程邏輯中運用VHDL或Verilog執(zhí)行的硬件。
這個問題現(xiàn)在已可藉由各種高階合成(HLS)工具(例如C語言至?xí)捍嫫鬓D(zhuǎn)移層級工具,C-to-RTL工具)得以解決。這些工具讓具備C/C++程式經(jīng)驗的程式設(shè)計人員透過現(xiàn)場可編程門陣列(FPGA)擁有硬件能力。業(yè)界高階合成工具可讓軟件和系統(tǒng)設(shè)計人員更容易將C/C++程式碼對應(yīng)到可編程邏輯,讓程式碼得以重用,并提供最佳可攜性和自由設(shè)計空間,最終達(dá)成最高生產(chǎn)力。
圖4展示運用高階合成工具的典型C/C++設(shè)計流程。這工具的輸出是暫存器轉(zhuǎn)移層級(RTL),可輕松與資料路徑預(yù)失真器或上游制程等既有的硬件設(shè)計進行整合,當(dāng)然也可連至資料轉(zhuǎn)換器。運用這項工具,演算法可快速轉(zhuǎn)移至硬件,其中這項工具會使用AXI界面連至硬件處理子系統(tǒng),如圖5所示。

圖4 高階合成設(shè)計流程
在可編程邏輯中以高時脈執(zhí)行自動相關(guān)矩陣運算演算法,可對效能產(chǎn)生重大的效益,僅針對這項功能而言,其效能增益就可比軟件建置的功能多七十倍,而且僅用完全可編程SoC元件中3%的邏輯。
從原來參考的C/C++程式碼進行基本最佳化,并運用ARM Cortex-A9處理器更有效地執(zhí)行運算,結(jié)果顯示僅用軟件進行最佳化所得的效能則比沒有變動的程式碼高出二至三倍。再使用NEON多媒體協(xié)同處理器就能產(chǎn)生更多的效能增益。圖5為自動相關(guān)矩陣運算架構(gòu)。其中針對相關(guān)矩陣運算功能,其整體效能增益比軟件建置的功能多七十倍。

圖5 整合可編程邏輯的自動相關(guān)矩陣運算硬件加速器演算法與處理系統(tǒng)
最終,無線傳輸效能決定硬件和軟件間所需的數(shù)字預(yù)失真功能分區(qū)。藉由調(diào)高頻譜校準(zhǔn)程度以達(dá)到更佳效率的做法可能影響效能,原因在于要達(dá)到這種校準(zhǔn)程度需要更高的處理效能。其他影響效能的因素也可能是更多的傳輸頻寬或是多個天線共用預(yù)測引擎。這只能針對單一的處理器節(jié)省空間和成本,加上采用另外的硬件加速器為許多資料路徑預(yù)失真器計算系數(shù)。
在一些情況中,用ARM Cortex-A9處理器配合NEON單元執(zhí)行的軟件效能可能已足夠,例如頻寬較窄的傳輸配置或只有一或兩個天線路徑處理資料的設(shè)計,可以為那些無線傳輸配置降低元件占用面積和物料成本。
為將效能提升至更高的水準(zhǔn),設(shè)計人員可在建置自動相關(guān)矩陣運算功能時加入更多平行運算機制,只要增加支援邏輯的建置則可達(dá)到更快的更新時間。進一步的軟件設(shè)定也可顯示從硬件加速受惠的演算法的其他面向。無論有任何需求,現(xiàn)在的工具和芯片都可讓設(shè)計人員去探索在效能、面積和功耗間的各種取舍方法,在不受限于特定獨立型元件或程式設(shè)計方式的情況下,可用最少的力氣達(dá)成更高的運作效率。
無線傳輸基礎(chǔ)設(shè)備需要低成本、低功耗和高可靠性。整合是達(dá)到這些目標(biāo)的關(guān)鍵,但時至今日業(yè)界仍須在靈活度或產(chǎn)品上市時程方面做某種程度的讓步。此外,在處理效能方面仍持續(xù)對寬頻無線傳輸和更高作業(yè)效率有更多的要求。完全可編程SoC元件具備雙核心處理器子系統(tǒng)、高效能和低功耗的可編程邏輯,可為目前和未來的無線傳輸需求提供可行解決方案。
無論是遠(yuǎn)端無線設(shè)備或者是主動式天線陣列,設(shè)計人員可以打造具備更高生產(chǎn)力的產(chǎn)品,同時提供比現(xiàn)有的特定應(yīng)用標(biāo)準(zhǔn)產(chǎn)品(ASSP)或特定應(yīng)用集成電路(ASIC)方案更高的靈活度和效能。
(本文作者為賽靈思無線產(chǎn)品行銷總監(jiān))
















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論