 電子發燒友App
電子發燒友App


1、引言
信息化已經成為社會發展的大趨勢。信息化是以數字化為背景的,而DSP技術則是數字化最重要的基本技術之一。DSP處理器是專門設計用來進行高速數字信號處理的微處理器。與許多通用的CPU和微控制器(MCU)相比,DSP處理器在結構上采用了許多的專門技術和措施來提高處理速度。DSP處理器與通用微處理器不同,它沒有采用將程序代碼和數據公用一個公共的存儲空間和單一的地址與數據總線的馮諾依曼結構(Von Neumann Architecture),而是毫無例外的將程序代碼和數據的存儲空間分開,各有自己的地址與數據總線,即所謂的哈佛結構(Harvard Architecture),增大了處理器的數據交換能力。
OFDM(正交頻分復用),是直接利用離散傅里葉變換(DFT),實現的一種多載波調制技術,它采用并行傳輸,將所傳送的高速數據分解并調制到多個相互交疊并且正交的子信道中,使得每個子通道的碼元寬度大于擴展延時,若在碼元之間增加一定長度的保護間隔,則多徑傳輸引起的碼間串擾基本被消除。OFDM的上述特點使其特別適于在存在多徑傳播和有多普勒頻移的移動無線傳輸信道中傳輸高速數據。目前應用于電力線通信,數字聲廣播(DAB)和歐洲高清晰度電視傳輸標準(DVB-T), 無線局域網(WLAN)等業務中。
論文在TMS320C5509DSP上根據系統的總體框圖,實現OFDM基帶系統的設計,并給出了具體的性能指標。
2、OFDM系統的設計實現
2.1 實現系統的任務流程圖
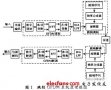
系統每幀可以傳送56bits的有效信息,數據的傳輸速率將達到100kbit/s,并且為了減小傳輸過程中的信道的不理想,用了BSPK對信源進行編碼映射,在傳輸過程中,傳輸的是時域的信號,但是實際有用的是這些時域信號的頻譜,這些信號在時域中是無規則的隨機信號,但在其頻譜上的各個子載波攜帶著需傳輸的信息。現工作框圖如圖1:
?
圖1.?? 系統的任務框圖
整個系統由DSP和FPGA、D/A、A/D以及一些其他的硬件共同完成。任務流程是由DSP接受由串/并轉換過后的并行數據,在DSP內進行BPSK信源編碼,將0和1分別映射為0xbffd 和0x3fff兩個十六進制的數,再送入IFFT單元將數據變到時域進行處理,然后把數據加上循環前綴,串行送給FPGA進行處理,由FPGA將數據發送給接收板。接收板上由FPGA接到數據進行一系列處理后,將數據又串行傳給接收板的DSP。在接收板的DSP上將接受到的數據移走循環前綴,送入FFT單元將數據還原到頻域,然后以0為門限進行判決,映射后得到最早的原始數據。
2.1? 任務流程詳解
原始數據每幀攜帶56bit的二進制信息(即只有0和1兩種取值),在框圖中D/A和A/D部分都是由專門的硬件來完成,項目選用的是ADS828e,和DAC902u。
發送部分:
信源編碼部分我們采用的是BPSK,為的是進一步增大信號間的歐式距離,通過計算,我們決定選用0xbffd 和0x3fff兩個16進制的數來分別代表0和1。由于FFT變換要求數據是2N個數據,所以將數據插入若干個零來補足。具體做法是,將映射后的第28個數據位置開始插入7個零。由于零頻時不能有信號(為了無直流分量),在幀的開始不傳信息,將第一個數插入零(不是0xbffd),把56個數變為64個數,在接收板上將把同樣位置的16個數去掉。
將編碼映射后的16位數進行64點的IFFT,把數據由頻域變換到時域,等候下一步處理。
在OFDM系統中,為了防止多徑延遲,必須加上循環前綴,而這些循環前綴又不能破壞子信道間的正交性,于是將最后16位數提到前面來形成80個數。具體做法是,在IFFT完成后,要加上循環前綴才能將數據發送給FPGA,將數據的最后16位復制到數據開頭(原來的16個數不動),把數據變為80個,送給串口發送給FPGA。
? 在FPGA上進行FIR濾波,和一系列處理后,發送板的任務完成,接下來就將數據送給接收板。
接收部分:
由接收板上的FPGA接收到發送板送來的數據,經過一系列處理后將數據串行送給DSP等待進一步處理。
接收板的DSP接收到FPGA發過來的80個串行數據后,先將循環前綴去掉,即去掉前16位數,將80位的數據變為64位,交給下一步處理。
在把數據變回為64位后,將數據進行FFT變換,由時域變回頻域,交由下一步處理。
在進行判決之前,先要把插入的16個數去掉,將64位數變為56位,然后進行判決,BPSK有一個好處就是判決時可以直接以零為門限。經過判決后,將數據還原成原來的初試值。
綜上所述,在DSP部分,共有10項任務,
發送端
1.BPSK編碼和插入數據(數據個數由56變為64個)
2.作N=64的IFFT變換,將頻域的數據變到時域。
3.加入循環前綴(數據個數由64個變為80個),防止多徑延遲。
4.通過DMA將數據送到Mcbsp發給FPGA。
接收端
5.由Mcbsp接到數據通過DMA存入數據空間(此時數據應該與第四步結束時相同)。
6.去掉循環前綴(數據個數又由80個變為64個,此時數據應該與第三步結束時相同)
7.作64點FFT變換(此時結果應該與第一步結束時相同)
8.去掉插入的數據,反映射(數據個數由64個變為56個,此時結果應該與第一步開始時相同)并解碼。
2.3? DSP串口的接發配置和DMA的設置
??? 系統實現關鍵在FFT的實現和DSP串口的接發配置和DMA的設置。這里詳細說明串口和DMA的設計方法。
系統用Mcbsp1發送數據,用Mcbsp2來接收數據,為了不占用過多的CPU資源,用DMA的4通道來傳送數據給串口,用5通道來接收數據。對于DMA和Mcbsp的使用主要是寄存器的配置問題,在這些配置當中可以對工作模式等一系列東西進行設置。現分別介紹如下:
對于Mcbsp來說,接收和發送可以配置在一起,采用了DSP自身帶有的CSL庫函數,它對寄存器的配置是通過結構體來定義的,可以方便的修改成自己所需要的模式。
在進行將DSP片內數據地址賦DMA中的地址時要注意,DMA中數據是以byte為單位存儲的,存儲的最小數據單位上byte,而片內存儲區間是以word為單位的,所以將地址交過去時,要將地址右依、移1位。如:
srcAddrHi = (Uint16)(((Uint32)(dmaXmtConfig.dmacssal)) >> 15) & 0xFFFFu;
srcAddrLo = (Uint16)(((Uint32)(dmaXmtConfig.dmacssal)) << 1) & 0xFFFFu;
dstAddrHi = (Uint16)(((Uint32)(dmaXmtConfig.dmacdsal)) >> 15) &0xFFFFu;
dstAddrLo = (Uint16)(((Uint32)(dmaXmtConfig.dmacdsal)) << 1) & 0xFFFFu;
在進行中斷處理是時,要注意執行的順序,首先要保存原來的中斷向量表,再清除原來的中斷,然后將局部中斷允許位開放(即關屏蔽位),開全局中斷,最后將中斷服務程序填入中斷向量表。
old_intm = IRQ_globalDisable();
IRQ_clear(xmtEventId);
IRQ_enable(xmtEventId);
IRQ_setVecs(0x10000);
IRQ_plug(xmtEventId,&dmaXmtIsr);
在程序任務完成之后,還要記得還原中斷,關掉Mcbsp和DMA。
??? MCBSP_close(hMcbspr);
??? DMA_close(hDmaRcv);
DMA_close(hDmaXmt);
DMA_stop(hDmaXmt);
? IRQ_disable(xmtEventId);
DMA_stop(hDmaRcv);
? IRQ_disable(rcvEventId);
在設定的控制字下,串口1將以CPU時鐘頻率的1/70發出幀定位信號,寬度為一個碼元長度,上升沿有效,以幀定位信號的1/80發出時鐘定位信號(因為一幀有80個元素),也是上升沿有效,發送元素是32bit的數,這是因為發散的數據是復數,分為虛部和實部,先放實部后放虛部,所以一個元素是32個bit。
串口2是接收端,接收外部幀同步信號和時鐘同步信號用來同步。外部傳來的各種信號和數據格式和串口1發送的相同,不過收的時鐘定位信號是下降沿有效。
??? 在DMA方面,通道4是發送通道,通道5是接收通道,同步事件分別是發送串口和接收串口,在一個數據串口接收到了后會發中斷給DMA,使其接收數據或傳下一個數據,所以在發端,需要手工先送一個數據過去。
3? 性能分析
可靠性以外,速度是一個通信系統最重要的評估因素,而數據的處理速度在很大程度上限制了傳輸速度,成為了提高系統速度的瓶頸。在設計中對系統傳輸由于是用DMA和Mcbsp的結合使用,速度超出了其他程序的執行速度,只要傳輸在主函數的執行時間內完成就不會造成系統的阻塞,所以這部分只測試和評估各程序的執行速度,傳輸的時鐘定位脈沖是對CPU時鐘的35分頻遠遠快于處理速度,忽略它的測試不會對整個測試有很大影響。
系統數據的傳輸速度達到100kbit/s,傳輸只要在上次數據處理完前完成就可以不計算傳輸的速度,所以按照我們的預期速度,和我們DSP的CPU時鐘140MHz,可以算出所有的數據要在多少條指令周期內完成才不會對下一階段的任務產生影響,而CCS就有專門的測試工具幫助我們測試執行的指令周期。期望的最大執行周期為140÷125×64=71680條指令周期。
由CCS自帶的時間測試是以執行周期為單位的,在程序沒有進行編譯優化時,我們測試得各部分和主函數的執行速度如圖2所示:
?
圖2 未優化前的程序執行時間測試結果
在此結果中,我們可以看到main函數的執行時間是39786個指令周期,完全可以滿足前面算出的最大指令執行周期。順便一提,在這個測試工具中還可以看到所編譯的程序代碼的大小。
在由CCS自帶的優化工具進行調試的優化后(即o2優化),程序代碼的長度和執行時間還可以大大的縮短。其結果見圖3所示:
?
圖3 用參數o2優化后的程序測試
比較圖2和圖3,可以看出經過優化后的程序不僅在代碼長度上減少了進40%,在執行速度上更是提高了2倍以上,有的子程序甚至提高了4-5倍。系統效率有了很大的提高,并且有較大的余量來實現其他任務。
4? 結論
實現了OFDM系統基帶系統的DSP實現,實現基帶信號的發送與接收。考慮到物理層的時延要求和實現的復雜度,本系統采用串口和DMA結合的方法,對信號幀進行處理,將DSP核心處理單元解放出來,能完成復雜的信號處理任務。我們設計的系統數據的傳輸速度達到100kbit/s,如果要達到更高的傳輸速率,可以改用更先進的DSP型號。









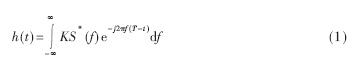





 工商網監
工商網監
評論